
变基
在 Git 中整合来自不同分支的修改主要有两种方法:merge 以及 rebase。 在本节中我们将学习什么是“变基”,怎样使用“变基”,并将展示该操作的惊艳之处,以及指出在何种情况下你应避免使用它。
变基的基本操作
请回顾之前在 分支的合并 中的一个例子,你会看到开发任务分叉到两个不同分支,又各自提交了更新。
Figure 35. 分叉的提交历史
之前介绍过,整合分支最容易的方法是 merge 命令。 它会把两个分支的最新快照(C3 和 C4)以及二者最近的共同祖先(C2)进行三方合并,合并的结果是生成一个新的快照(并提交)。
Figure 36. 通过合并操作来整合分叉的历史
其实,还有一种方法:你可以提取在 C4 中引入的补丁和修改,然后在 C3 的基础上应用一次。 在 Git 中,这种操作就叫做 变基(rebase)。 你可以使用 rebase 命令将提交到某一分支上的所有修改都移至另一分支上,就好像“重新播放”一样。
在这个例子中,你可以检出 experiment 分支,然后将它变基到 master 分支上:
1 | git checkout experiment |
它的原理是首先找到这两个分支(即当前分支 experiment、变基操作的目标基底分支 master) 的最近共同祖先 C2,然后对比当前分支相对于该祖先的历次提交,提取相应的修改并存为临时文件, 然后将当前分支指向目标基底 C3, 最后以此将之前另存为临时文件的修改依序应用。 (译注:写明了 commit id,以便理解,下同)
Figure 37. 将 C4 中的修改变基到 C3 上
现在回到 master 分支,进行一次快进合并。
1 | git checkout master |
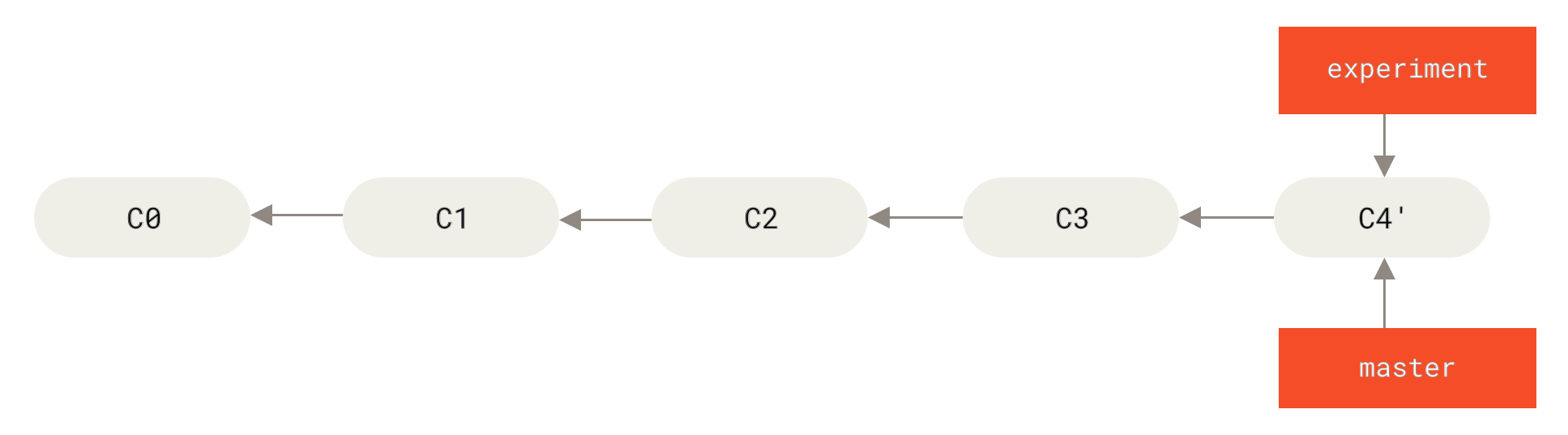
Figure 38. master 分支的快进合并
此时,C4' 指向的快照就和 the merge example 中 C5 指向的快照一模一样了。 这两种整合方法的最终结果没有任何区别,但是变基使得提交历史更加整洁。 你在查看一个经过变基的分支的历史记录时会发现,尽管实际的开发工作是并行的, 但它们看上去就像是串行的一样,提交历史是一条直线没有分叉。
一般我们这样做的目的是为了确保在向远程分支推送时能保持提交历史的整洁——例如向某个其他人维护的项目贡献代码时。 在这种情况下,你首先在自己的分支里进行开发,当开发完成时你需要先将你的代码变基到 origin/master 上,然后再向主项目提交修改。 这样的话,该项目的维护者就不再需要进行整合工作,只需要快进合并便可。
请注意,无论是通过变基,还是通过三方合并,整合的最终结果所指向的快照始终是一样的,只不过提交历史不同罢了。 变基是将一系列提交按照原有次序依次应用到另一分支上,而合并是把最终结果合在一起。
更有趣的变基例子
在对两个分支进行变基时,所生成的“重放”并不一定要在目标分支上应用,你也可以指定另外的一个分支进行应用。 就像 从一个主题分支里再分出一个主题分支的提交历史 中的例子那样。 你创建了一个主题分支 server,为服务端添加了一些功能,提交了 C3 和 C4。 然后从 C3 上创建了主题分支 client,为客户端添加了一些功能,提交了 C8 和 C9。 最后,你回到 server 分支,又提交了 C10。
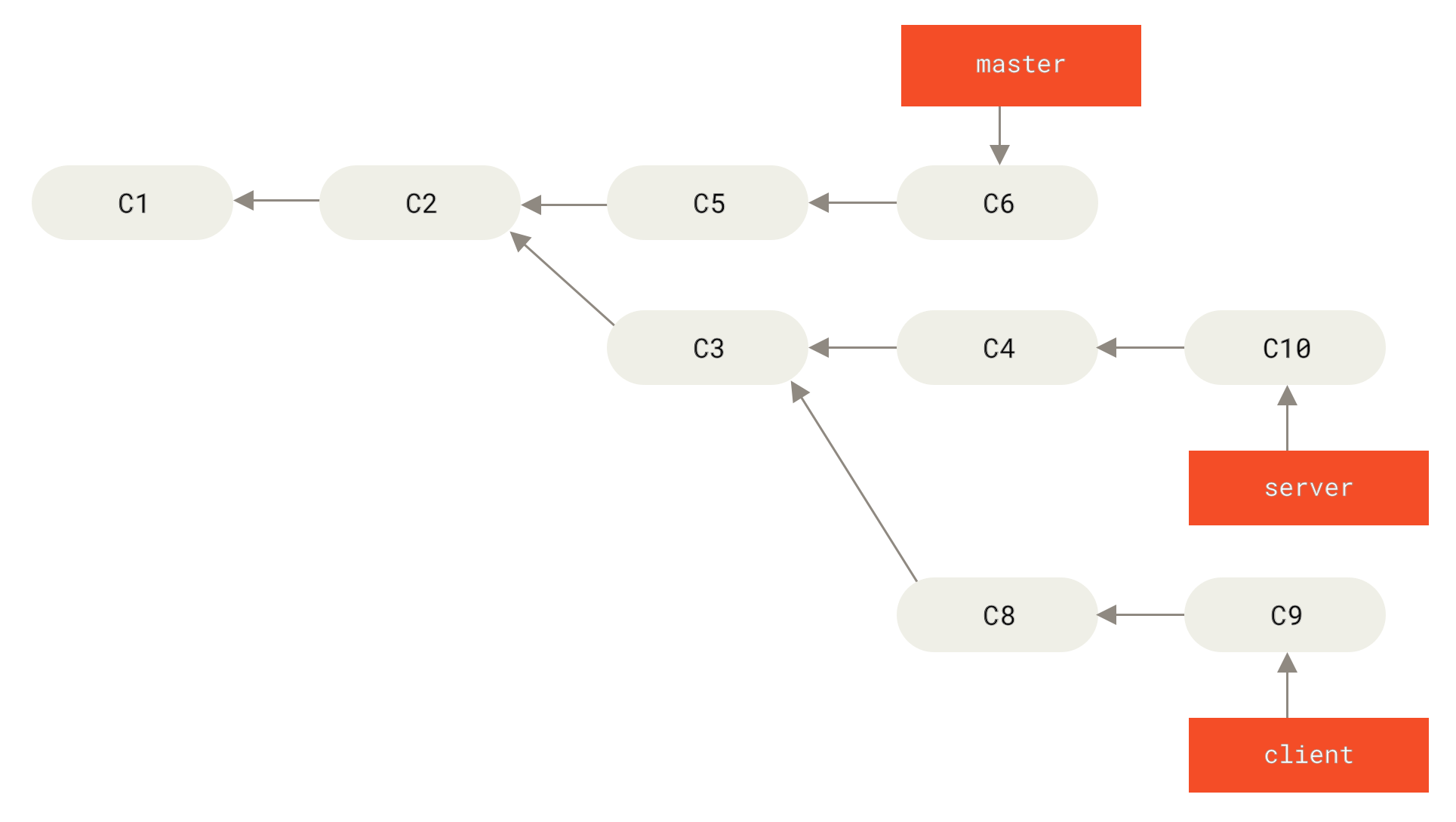
Figure 39. 从一个主题分支里再分出一个主题分支的提交历史
假设你希望将 client 中的修改合并到主分支并发布,但暂时并不想合并 server 中的修改, 因为它们还需要经过更全面的测试。这时,你就可以使用 git rebase 命令的 --onto 选项, 选中在 client 分支里但不在 server 分支里的修改(即 C8 和 C9),将它们在 master 分支上重放:
1 | git rebase --onto master server client |
以上命令的意思是:“取出 client 分支,找出它从 server 分支分歧之后的补丁, 然后把这些补丁在 master 分支上重放一遍,让 client 看起来像直接基于 master 修改一样”。这理解起来有一点复杂,不过效果非常酷。
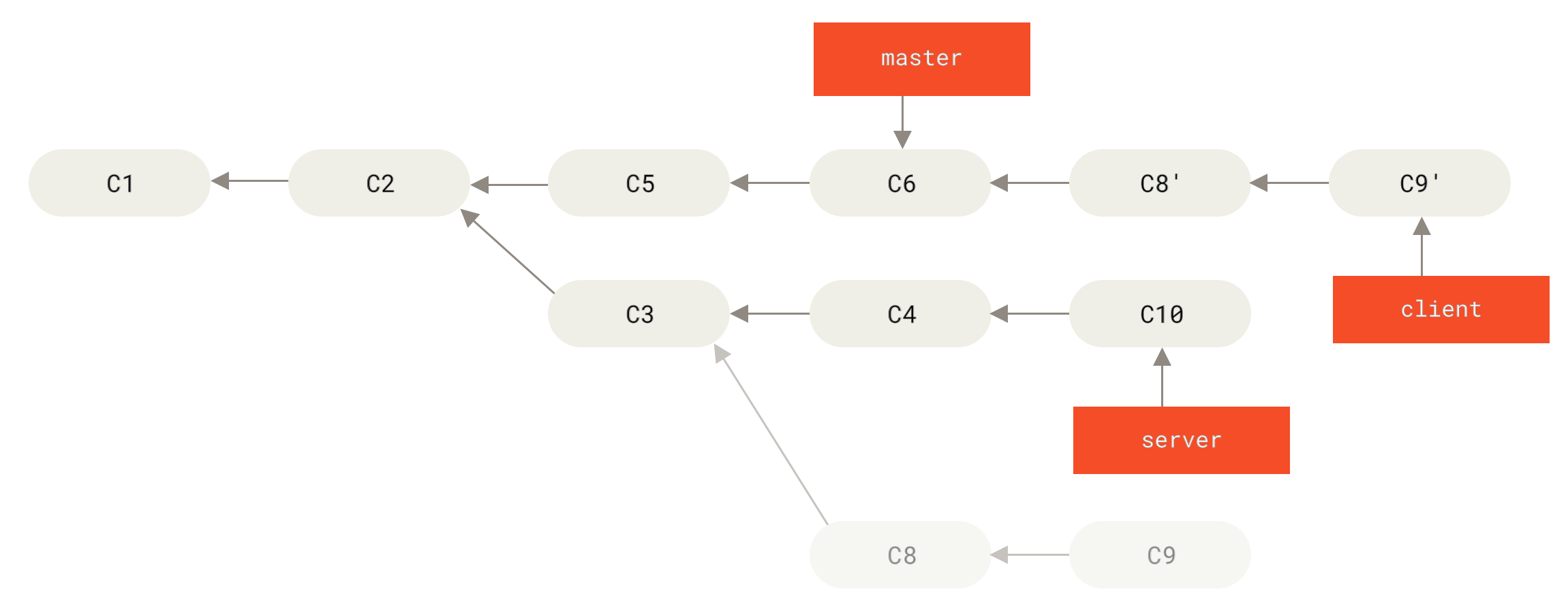
Figure 40. 截取主题分支上的另一个主题分支,然后变基到其他分支
1 | git checkout master |
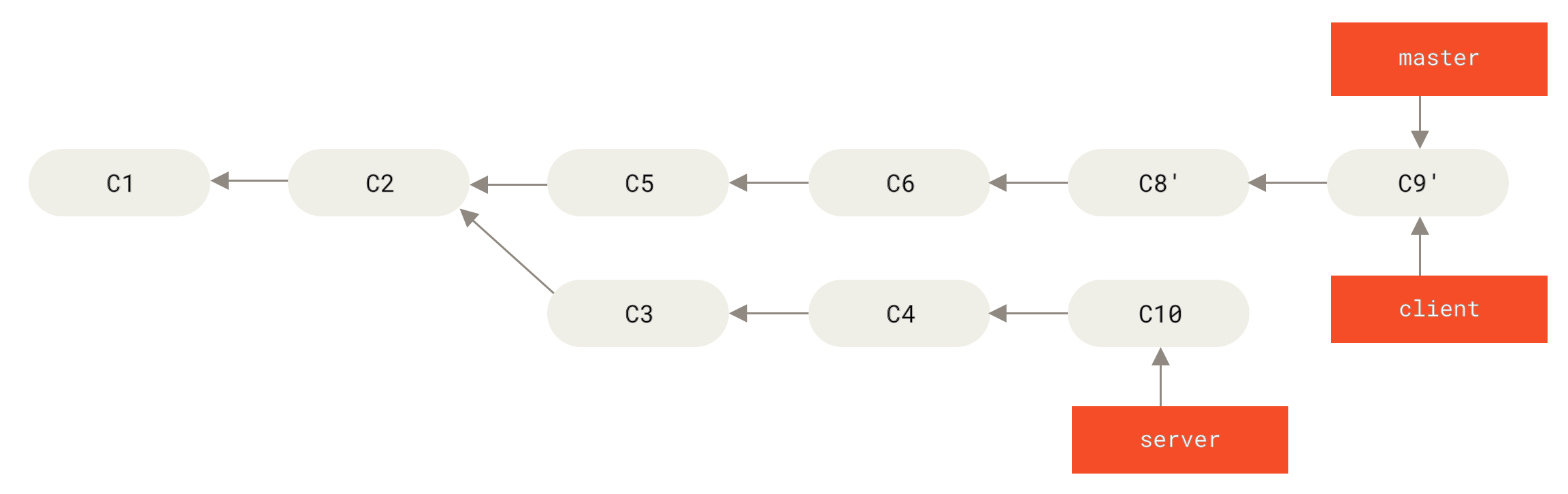
Figure 41. 快进合并 master 分支,使之包含来自 client 分支的修改
接下来你决定将 server 分支中的修改也整合进来。 使用 git rebase <basebranch> <topicbranch> 命令可以直接将主题分支 (即本例中的 server)变基到目标分支(即 master)上。 这样做能省去你先切换到 server 分支,再对其执行变基命令的多个步骤。
1 | git rebase master server |

Figure 42. 将 server 中的修改变基到 master 上
然后就可以快进合并主分支 master 了:
1 | git checkout master |
至此,client 和 server 分支中的修改都已经整合到主分支里了, 你可以删除这两个分支,最终提交历史会变成图 最终的提交历史 中的样子:
1 | git branch -d client |

Figure 43. 最终的提交历史
变基的风险
呃,奇妙的变基也并非完美无缺,要用它得遵守一条准则:
如果提交存在于你的仓库之外,而别人可能基于这些提交进行开发,那么不要执行变基。
如果你遵循这条金科玉律,就不会出差错。 否则,人民群众会仇恨你,你的朋友和家人也会嘲笑你,唾弃你。
变基操作的实质是丢弃一些现有的提交,然后相应地新建一些内容一样但实际上不同的提交。 如果你已经将提交推送至某个仓库,而其他人也已经从该仓库拉取提交并进行了后续工作,此时,如果你用 git rebase 命令重新整理了提交并再次推送,你的同伴因此将不得不再次将他们手头的工作与你的提交进行整合,如果接下来你还要拉取并整合他们修改过的提交,事情就会变得一团糟。
让我们来看一个在公开的仓库上执行变基操作所带来的问题。 假设你从一个中央服务器克隆然后在它的基础上进行了一些开发。 你的提交历史如图所示:
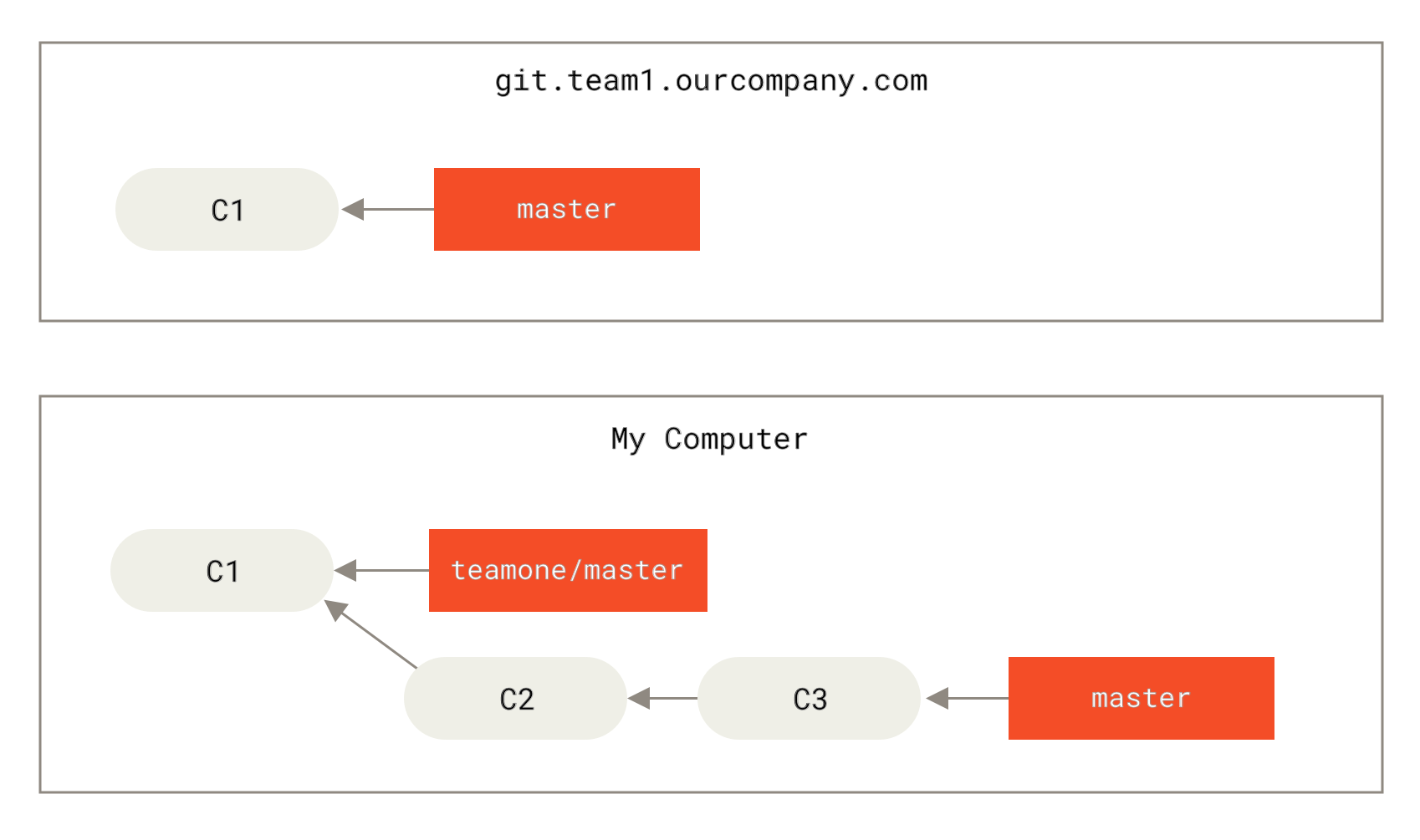
Figure 44. 克隆一个仓库,然后在它的基础上进行了一些开发
然后,某人又向中央服务器提交了一些修改,其中还包括一次合并。 你抓取了这些在远程分支上的修改,并将其合并到你本地的开发分支,然后你的提交历史就会变成这样:
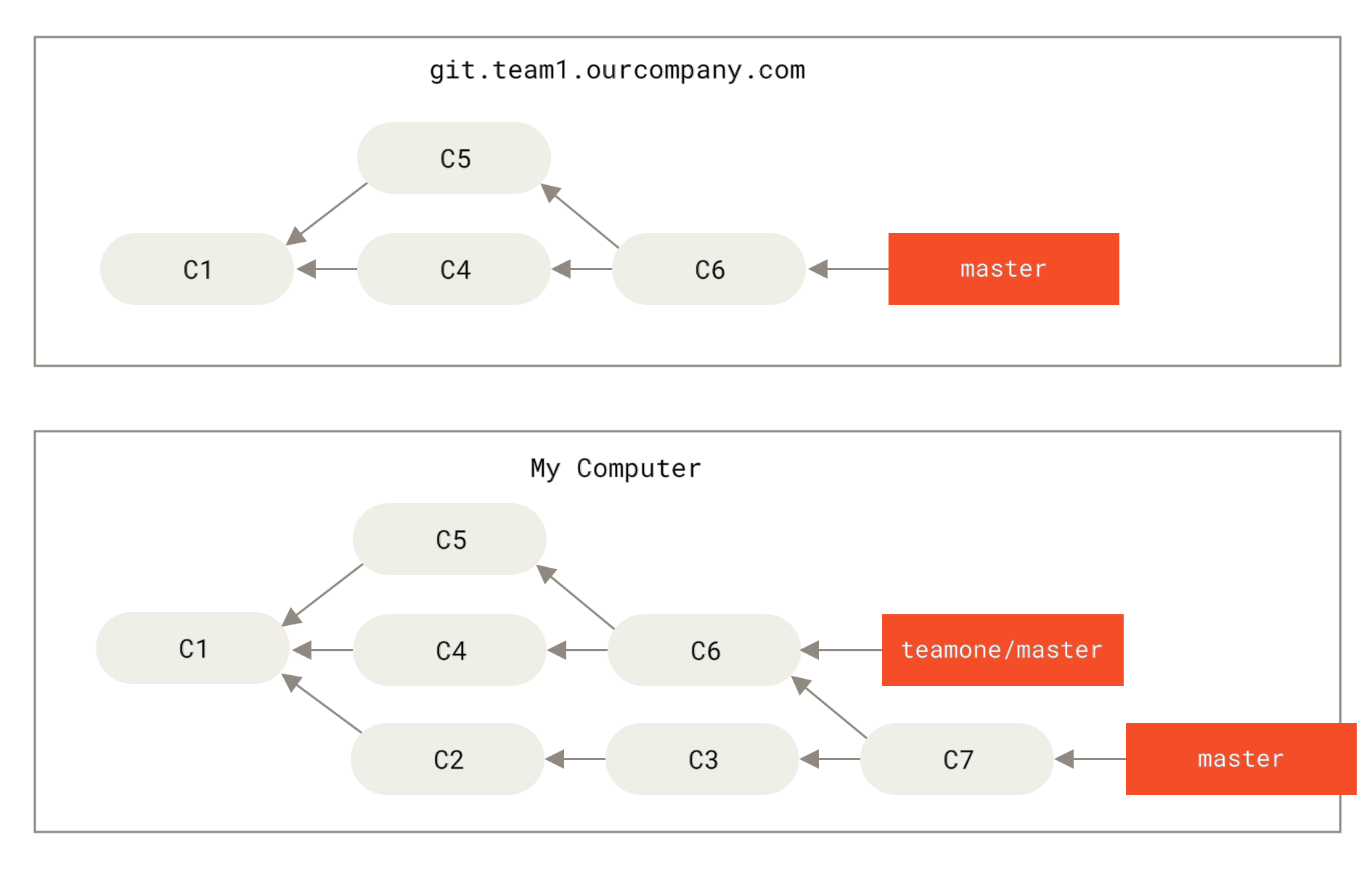
Figure 45. 抓取别人的提交,合并到自己的开发分支
接下来,这个人又决定把合并操作回滚,改用变基;继而又用 git push --force 命令覆盖了服务器上的提交历史。 之后你从服务器抓取更新,会发现多出来一些新的提交。
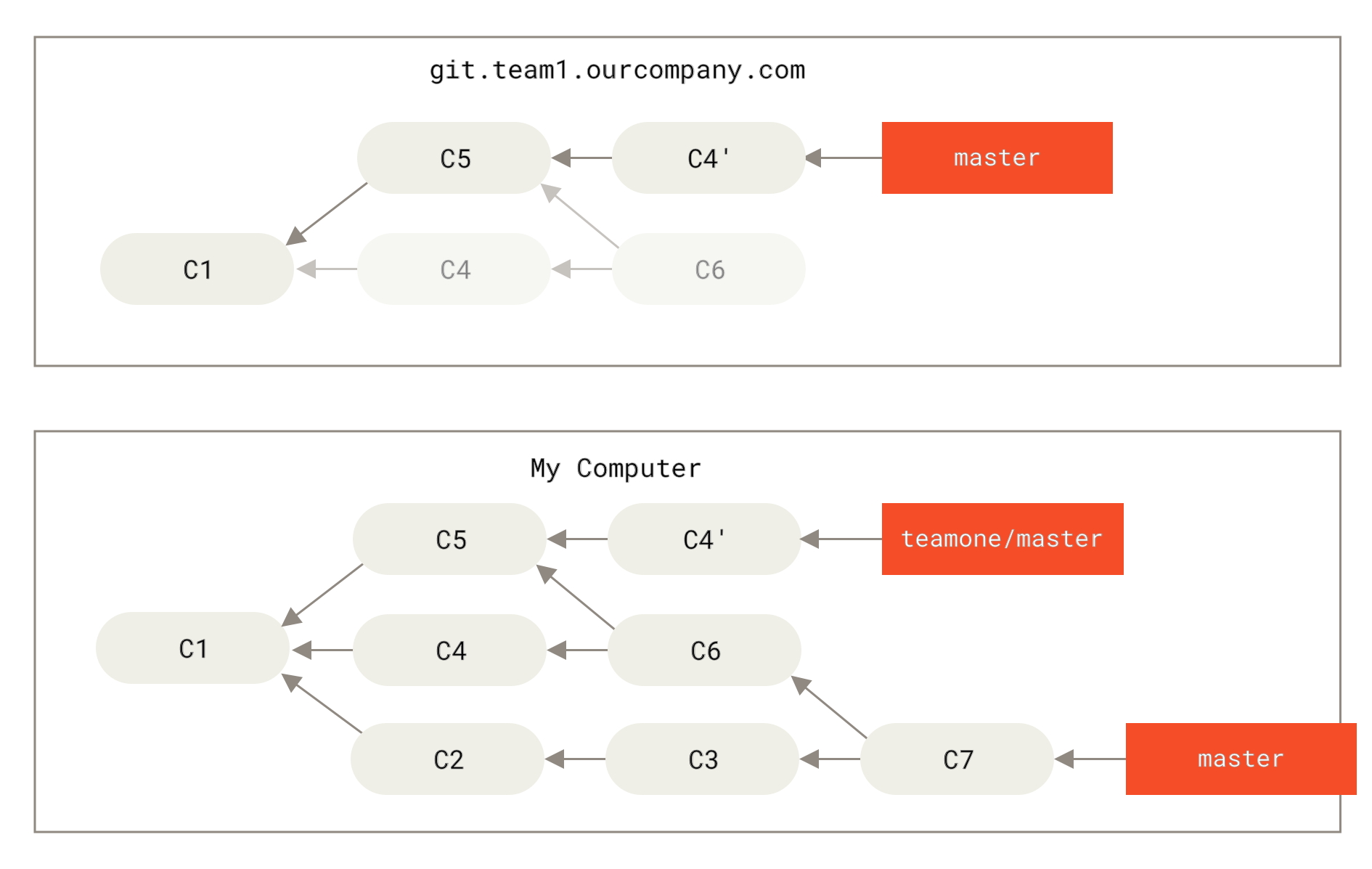
Figure 46. 有人推送了经过变基的提交,并丢弃了你的本地开发所基于的一些提交
结果就是你们两人的处境都十分尴尬。 如果你执行 git pull 命令,你将合并来自两条提交历史的内容,生成一个新的合并提交,最终仓库会如图所示:
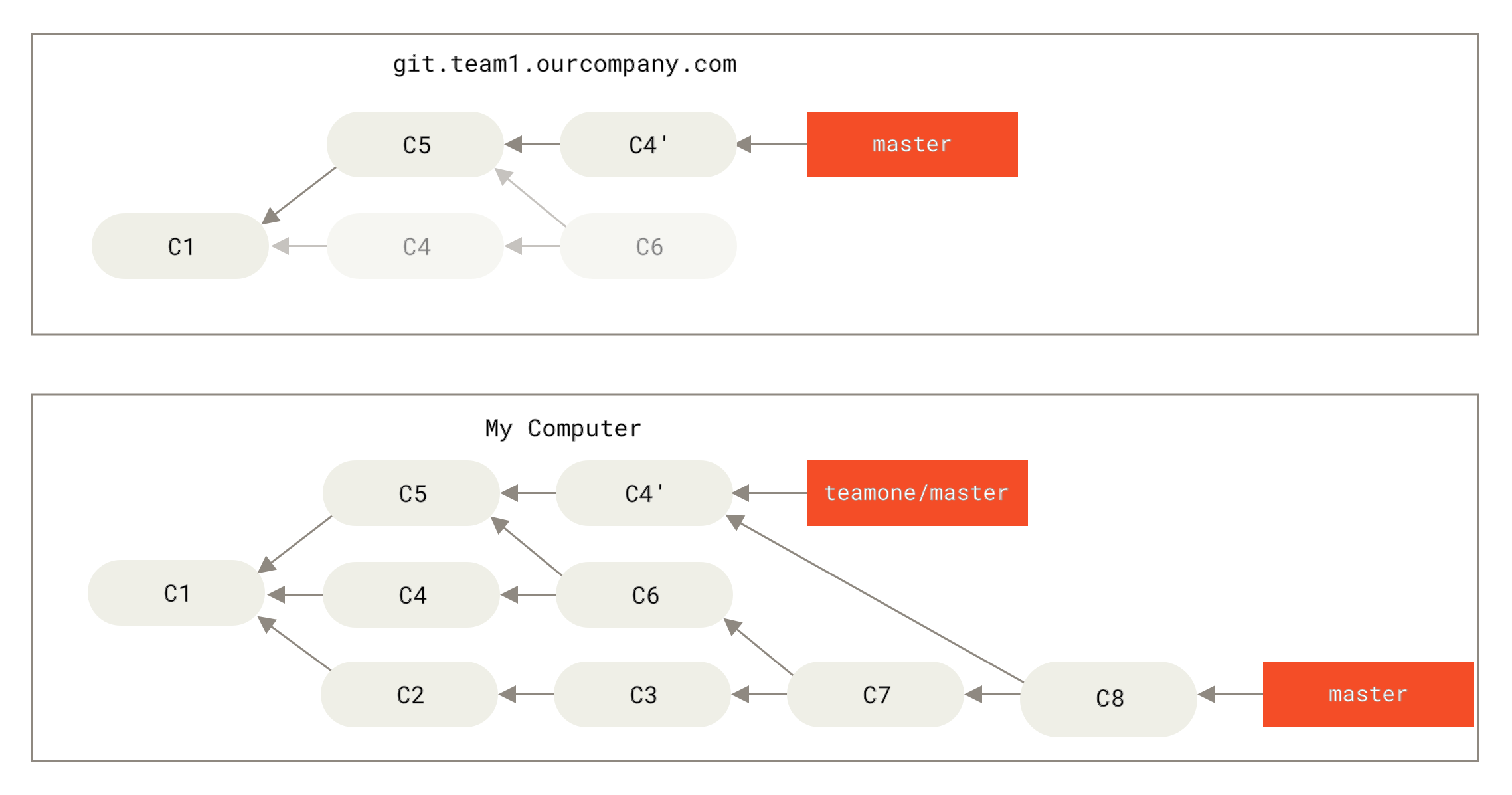
Figure 47. 你将相同的内容又合并了一次,生成了一个新的提交
此时如果你执行 git log 命令,你会发现有两个提交的作者、日期、日志居然是一样的,这会令人感到混乱。 此外,如果你将这一堆又推送到服务器上,你实际上是将那些已经被变基抛弃的提交又找了回来,这会令人感到更加混乱。 很明显对方并不想在提交历史中看到 C4 和 C6,因为之前就是他把这两个提交通过变基丢弃的。
用变基解决变基
如果你 真的 遭遇了类似的处境,Git 还有一些高级魔法可以帮到你。 如果团队中的某人强制推送并覆盖了一些你所基于的提交,你需要做的就是检查你做了哪些修改,以及他们覆盖了哪些修改。
实际上,Git 除了对整个提交计算 SHA-1 校验和以外,也对本次提交所引入的修改计算了校验和——即 “patch-id”。
如果你拉取被覆盖过的更新并将你手头的工作基于此进行变基的话,一般情况下 Git 都能成功分辨出哪些是你的修改,并把它们应用到新分支上。
-
检查哪些提交是我们的分支上独有的(C2,C3,C4,C6,C7)
-
检查其中哪些提交不是合并操作的结果(C2,C3,C4)
-
检查哪些提交在对方覆盖更新时并没有被纳入目标分支(只有 C2 和 C3,因为 C4 其实就是 C4’)
-
把查到的这些提交应用在
teamone/master上面
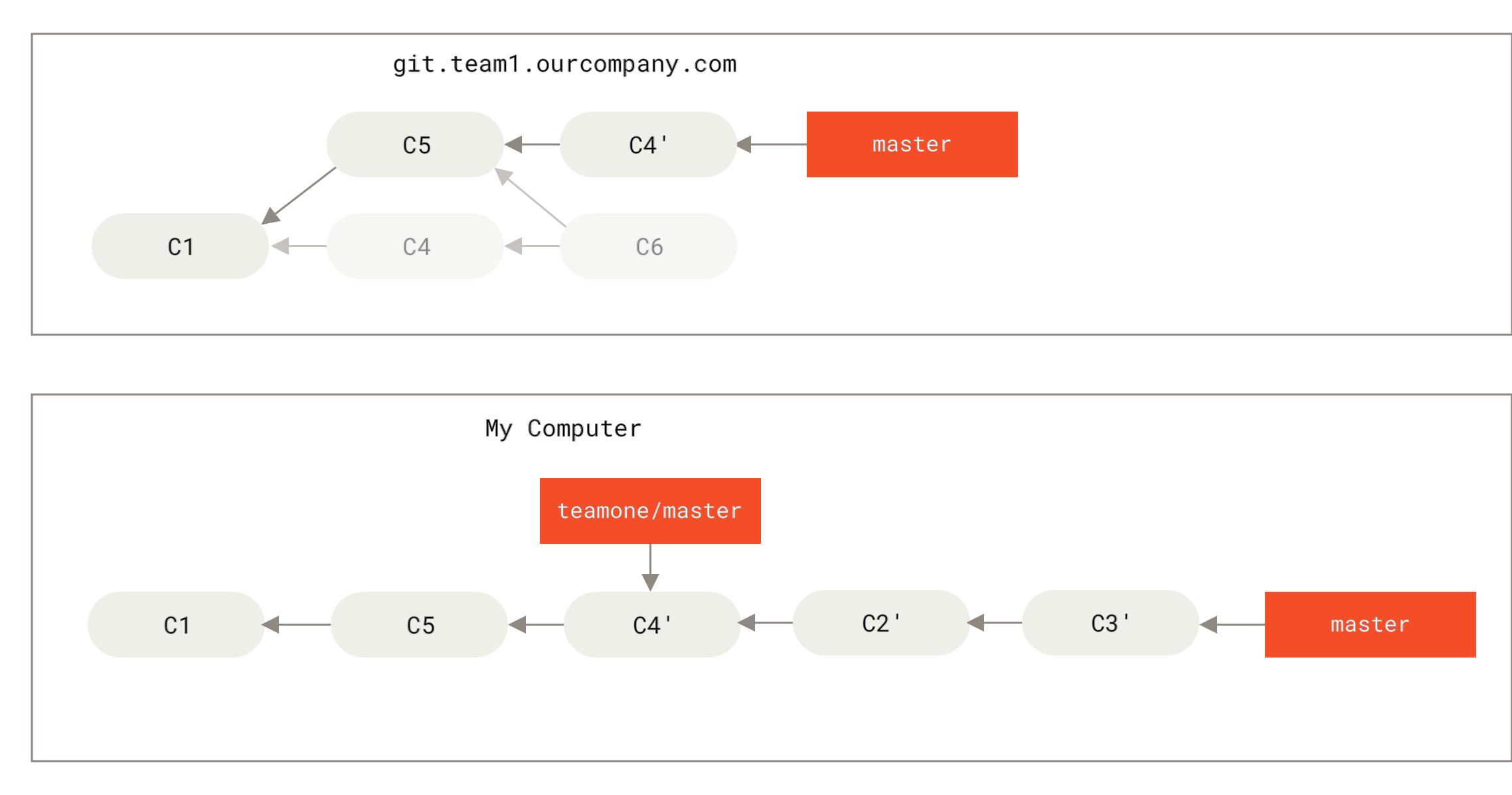
Figure 48. 在一个被变基然后强制推送的分支上再次执行变基
要想上述方案有效,还需要对方在变基时确保 C4' 和 C4 是几乎一样的。 否则变基操作将无法识别,并新建另一个类似 C4 的补丁(而这个补丁很可能无法整洁的整合入历史,因为补丁中的修改已经存在于某个地方了)。
在本例中另一种简单的方法是使用 git pull --rebase 命令而不是直接 git pull。 又或者你可以自己手动完成这个过程,先 git fetch,再 git rebase teamone/master。
如果你习惯使用 git pull ,同时又希望默认使用选项 --rebase,你可以执行这条语句 git config --global pull.rebase true 来更改 pull.rebase 的默认配置。
如果你只对不会离开你电脑的提交执行变基,那就不会有事。 如果你对已经推送过的提交执行变基,但别人没有基于它的提交,那么也不会有事。 如果你对已经推送至共用仓库的提交上执行变基命令,并因此丢失了一些别人的开发所基于的提交, 那你就有大麻烦了,你的同事也会因此鄙视你。
如果你或你的同事在某些情形下决意要这么做,请一定要通知每个人执行 git pull --rebase 命令,这样尽管不能避免伤痛,但能有所缓解。
变基 vs. 合并
至此,你已在实战中学习了变基和合并的用法,你一定会想问,到底哪种方式更好。 在回答这个问题之前,让我们退后一步,想讨论一下提交历史到底意味着什么。
有一种观点认为,仓库的提交历史即是 记录实际发生过什么。 它是针对历史的文档,本身就有价值,不能乱改。 从这个角度看来,改变提交历史是一种亵渎,你使用 谎言 掩盖了实际发生过的事情。 如果由合并产生的提交历史是一团糟怎么办? 既然事实就是如此,那么这些痕迹就应该被保留下来,让后人能够查阅。
另一种观点则正好相反,他们认为提交历史是 项目过程中发生的事。 没人会出版一本书的第一版草稿,软件维护手册也是需要反复修订才能方便使用。 持这一观点的人会使用 rebase 及 filter-branch 等工具来编写故事,怎么方便后来的读者就怎么写。
现在,让我们回到之前的问题上来,到底合并还是变基好?希望你能明白,这并没有一个简单的答案。 Git 是一个非常强大的工具,它允许你对提交历史做许多事情,但每个团队、每个项目对此的需求并不相同。 既然你已经分别学习了两者的用法,相信你能够根据实际情况作出明智的选择。
总的原则是,只对尚未推送或分享给别人的本地修改执行变基操作清理历史, 从不对已推送至别处的提交执行变基操作,这样,你才能享受到两种方式带来的便利。
Git Flow
Git Flow 是一种基于 Git 的分支模型,旨在帮助团队更好地管理和发布软件。
Git Flow 由 Vincent Driessen 在 2010 年提出,并通过一套标准的分支命名和工作流程,使开发、测试和发布过程更加有序和高效。
Git Flow 主要由以下几类分支组成:master、develop、feature、release、hotfix。
Git Flow 安装
Linux
Debian/Ubuntu:
1 | sudo apt-get install git-flow |
Fedora:
1 | sudo dnf install gitflow |
macOS
在 macOS 上,你可以使用 Homebrew 来安装 Git Flow:
1 | brew install git-flow |
源码安装
如果你的发行版的包管理器中没有 Git Flow,你也可以从源代码进行安装:
1 | git clone https://github.com/nvie/gitflow.git |
安装完成后,你可以通过以下命令验证 Git Flow 是否成功安装:
1 | git flow version |
Windows
在 Windows 上,你可以通过以下方式安装 Git Flow:
-
使用 Git for Windows: Git for Windows 包含了 Git Flow。你可以从 Git for Windows 安装 Git,然后使用 Git Bash 来使用 Git Flow。
-
使用 Scoop: 如果你使用 Scoop 包管理工具,可以通过以下命令安装 Git Flow:
1
scoop install git-flow
-
使用 Chocolatey: 如果你使用 Chocolatey 包管理工具,可以通过以下命令安装 Git Flow:
1
choco install gitflow
Git Flow 分支模型
master 分支:
- 永远保持稳定和可发布的状态。
- 每次发布一个新的版本时,都会从
develop分支合并到master分支。
develop 分支:
- 用于集成所有的开发分支。
- 代表了最新的开发进度。
- 功能分支、发布分支和修复分支都从这里分支出去,最终合并回这里。
feature 分支:
- 用于开发新功能。
- 从
develop分支创建,开发完成后合并回develop分支。 - 命名规范:
feature/feature-name。
release 分支:
- 用于准备新版本的发布。
- 从
develop分支创建,进行最后的测试和修复,然后合并回develop和master分支,并打上版本标签。 - 命名规范:
release/release-name。
hotfix 分支:
- 用于修复紧急问题。
- 从
master分支创建,修复完成后合并回master和develop分支,并打上版本标签。 - 命名规范:
hotfix/hotfix-name。
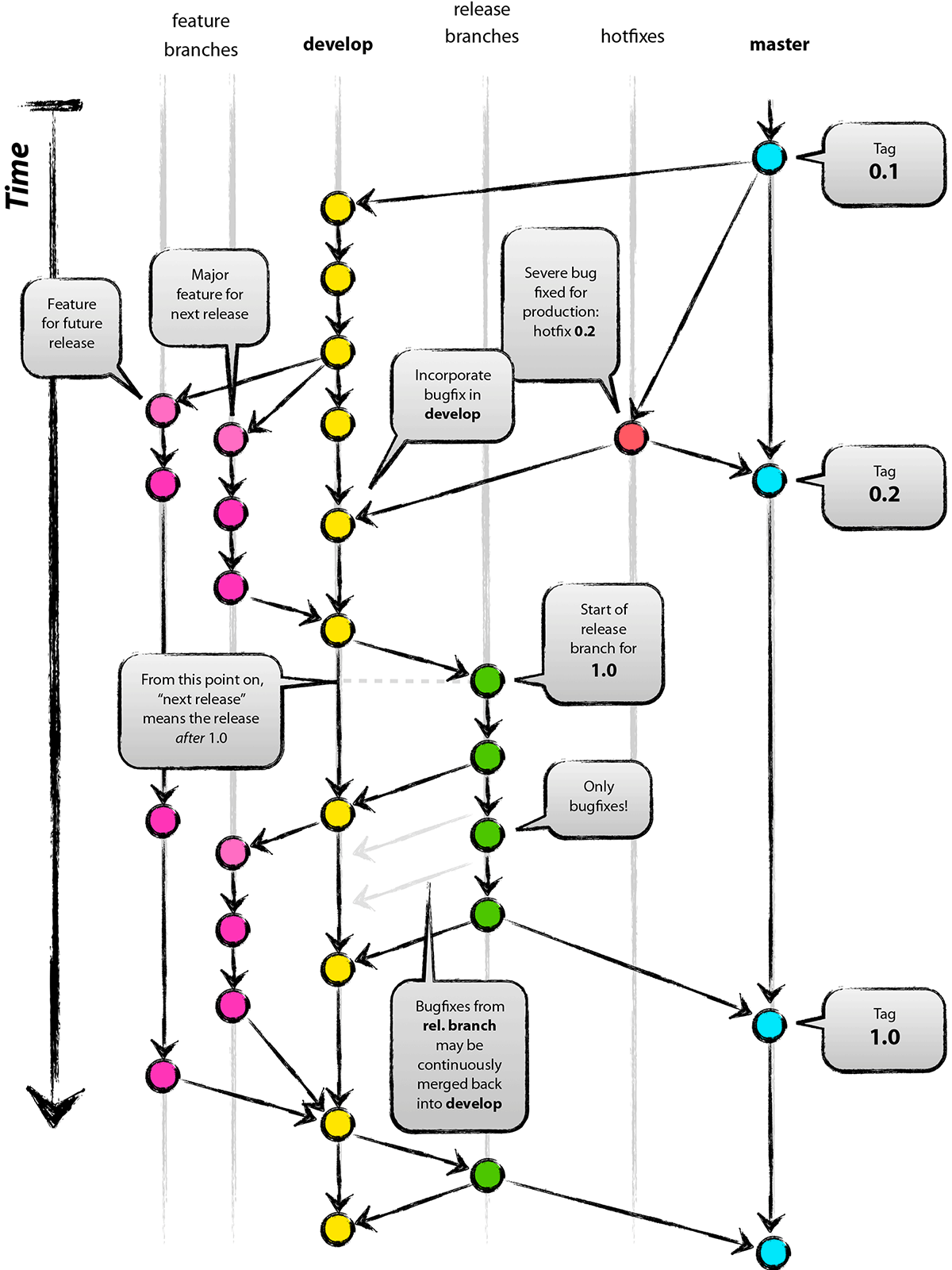
分支操作原理
- Master 分支上的每个 Commit 应打上 Tag,Develop 分支基于 Master 创建。
- Feature 分支完成后合并回 Develop 分支,并通常删除该分支。
- Release 分支基于 Develop 创建,用于测试和修复 Bug,发布后合并回 Master 和 Develop,并打 Tag 标记版本号。
- Hotfix 分支基于 Master 创建,完成后合并回 Master 和 Develop,并打 Tag 1。
Git Flow 命令示例
- 开始 Feature 分支:
git flow feature start MYFEATURE - 完成 Feature 分支:
git flow feature finish MYFEATURE - 开始 Release 分支:
git flow release start RELEASE [BASE] - 完成 Release 分支:合并到 Master 和 Develop,打 Tag,删除 Release 分支。
- 开始 Hotfix 分支:
git flow hotfix start HOTFIX [BASE] - 完成 Hotfix 分支:合并到 Master 和 Develop,打 Tag,删除 Hotfix 分支。
Git Flow 工作流程
1. 初始化 Git Flow
首先,在项目中初始化 Git Flow。可以使用 Git Flow 插件(例如 git-flow)来简化操作。
1 | git flow init |
初始化时,你需要设置分支命名规则和默认分支。
2. 创建功能分支
当开始开发一个新功能时,从 develop 分支创建一个功能分支。
1 | git flow feature start feature-name |
完成开发后,将功能分支合并回 develop 分支,并删除功能分支。
1 | git flow feature finish feature-name |
3. 创建发布分支
当准备发布一个新版本时,从 develop 分支创建一个发布分支。
1 | git flow release start release-name |
在发布分支上进行最后的测试和修复,准备好发布后,将发布分支合并回 develop 和 master 分支,并打上版本标签。
1 | git flow release finish release-name |
4. 创建修复分支
当发现需要紧急修复的问题时,从 master 分支创建一个修复分支。
1 | git flow hotfix start hotfix-name |
修复完成后,将修复分支合并回 master 和 develop 分支,并打上版本标签。
1 | git flow hotfix finish hotfix-name |
实例操作
以下是一个实际使用 Git Flow 的综合实例。
初始化 Git Flow:
1 | git flow init |
创建和完成功能分支:
1 | git flow feature start new-feature # 开发新功能 |
创建和完成发布分支:
1 | git flow release start v1.0.0 # 测试和修复 |
创建和完成修复分支:
1 | git flow hotfix start hotfix-1.0.1. # 修复紧急问题 |
优点和缺点
优点
- 明确的分支模型:清晰的分支命名和使用规则,使得开发过程井然有序。
- 隔离开发和发布:开发和发布过程分离,减少了开发中的不确定性对发布的影响。
- 版本管理:每次发布和修复都会打上版本标签,方便回溯和管理。
缺点
- 复杂性:对于小型团队或简单项目,Git Flow 的分支模型可能显得过于复杂。
- 频繁的合并:在大型团队中,频繁的分支合并可能导致合并冲突增加。
Git Flow 是一种结构化的分支管理模型,通过定义明确的分支和工作流程,帮助团队更好地管理软件开发和发布过程。虽然它增加了一定的复杂性,但对于大型项目和团队协作,Git Flow 提供了强大的支持和管理能力。
初始化仓库:
1 | git init |
如果当前目录下有几个文件想要纳入版本控制,需要先用 git add 命令告诉 Git 开始对这些文件进行跟踪,然后提交:
1 | $ git add *.c |
忽略某些文件
我们可以创建一个名为 .gitignore 的文件,列出要忽略的文件模式。
文件 .gitignore 的格式规范如下:
- 所有空行或者以注释符号 # 开头的行都会被 Git 忽略。
- 可以使用标准的 glob 模式匹配。
- 匹配模式最后跟反斜杠(/)说明要忽略的是目录。
- 要忽略指定模式以外的文件或目录,可以在模式前加上惊叹号(!)取反。
所谓的 glob 模式是指 shell 所使用的简化了的正则表达式。星号(*)匹配零个或多个任意字符;[abc] 匹配任何一个列在方括号中的字符(这个例子要么匹配一个 a,要么匹配一个 b,要么匹配一个 c);问号(?)只匹配一个任意字符;如果在方括号中使用短划线分隔两个字符,表示所有在这两个字符范围内的都可以匹配(比如 [0-9] 表示匹配所有 0 到 9 的数字)。
我们再看一个 .gitignore 文件的例子:
1 | # 此为注释 – 将被 Git 忽略 |
跟踪新文件
使用命令 git add 开始跟踪一个新文件。所以,要跟踪 README 文件,运行:
1 | $ git add README |
提交更新
每次准备提交前,先用 git status 看下,是不是都已暂存起来了,然后再运行提交命令 git commit:
1 | $ git commit |
这种方式会启动文本编辑器以便输入本次提交的说明。(默认会启用 shell 的环境变量 $EDITOR 所指定的软件,一般都是 vim 或 emacs。当然也可以按照第一章介绍的方式,使用 ++git config --global core.editor++ 命令设定你喜欢的编辑软件。)
默认的提交消息包含最后一次运行 git status 的输出,放在注释行里,另外开头还有一空行,供你输入提交说明。你完全可以去掉这些注释行,不过留着也没关系,多少能帮你回想起这次更新的内容有哪些。(如果觉得这还不够,可以用 -v 选项将修改差异的每一行都包含到注释中来。)退出编辑器时,Git 会丢掉注释行,将说明内容和本次更新提交到仓库。
另外也可以用 +±m++ 参数后跟提交说明的方式,在一行命令中提交更新:
跳过使用暂存区域
Git 提供了一个跳过使用暂存区域的方式,只要在提交的时候,给 git commit 加上 -a 选项,Git 就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过 git add 步骤
移除文件
要从 Git 中移除某个文件,就必须要从已跟踪文件清单中移除(确切地说,是从暂存区域移除),然后提交。可以用 git rm 命令完成此项工作,并连带从工作目录中删除指定的文件,这样以后就不会出现在未跟踪文件清单中了。
移动文件
要在 Git 中对文件改名,可以这么做:
1 | $ git mv file_from file_to |
运行 git mv 就相当于运行了下面三条命令:
1 | $ mv README.txt README |
查看提交历史
默认不用任何参数的话,git log 会按提交时间列出所有的更新,最近的更新排在最上面。看到了吗,每次更新都有一个 SHA-1 校验和、作者的名字和电子邮件地址、提交时间,最后缩进一个段落显示提交说明。
git log 有许多选项可以帮助你搜寻感兴趣的提交,接下来我们介绍些最常用的。
我们常用 -p 选项展开显示每次提交的内容差异,用 -2 则仅显示最近的两次更新
某些时候,单词层面的对比,比行层面的对比,更加容易观察。Git 提供了 +±-word-diff++ 选项。我们可以将其添加到 ++git log -p++ 命令的后面,从而获取单词层面上的对比。在程序代码中进行单词层面的对比常常是没什么用的。不过当你需要在书籍、论文这种很大的文本文件上进行对比的时候,这个功能就显出用武之地了。
另外,git log 还提供了许多摘要选项可以用,比如 --stat,仅显示简要的增改行数统计
用 oneline 或 format 时结合 --graph 选项,可以看到开头多出一些 ASCII 字符串表示的简单图形,形象地展示了每个提交所在的分支及其分化衍合情况。
另外还有按照时间作限制的选项,比如 --since 和 --until。
撤消操作
有时候我们提交完了才发现漏掉了几个文件没有加,或者提交信息写错了。想要撤消刚才的提交操作,可以使用 --amend 选项重新提交:
1 | $ git commit --amend |
远程仓库的使用
查看当前的远程库
要查看当前配置有哪些远程仓库,可以用 git remote 命令,它会列出每个远程库的简短名字。
也可以加上 -v 选项(译注:此为 --verbose 的简写,取首字母),显示对应的克隆地址
添加远程仓库
要添加一个新的远程仓库,可以指定一个简单的名字,以便将来引用,运行
1 | git remote add [shortname] [url]: |
现在可以用字符串 pb 指代对应的仓库地址了。比如说,要抓取所有 Paul 有的,但本地仓库没有的信息,可以运行 git fetch pb
从远程仓库抓取数据
正如之前所看到的,可以用下面的命令从远程仓库抓取数据到本地:
1 | $ git fetch [remote-name] |
推送数据到远程仓库
目进行到一个阶段,要同别人分享目前的成果,可以将本地仓库中的数据推送到远程仓库。实现这个任务的命令很简单:
1 | git push [remote-name] [branch-name]。 |
如果要把本地的 master 分支推送到 origin 服务器上(再次说明下,克隆操作会自动使用默认的 master 和 origin 名字),可以运行下面的命令:
1 | $ git push origin master |
查看远程仓库信息
我们可以通过命令
1 | git remote show [remote-name] |
查看某个远程仓库的详细信息
远程仓库的删除和重命名
在新版 Git 中可以用 git remote rename 命令修改某个远程仓库在本地的简称,比如想把 pb 改成 paul,可以这么运行:
1 | $ git remote rename pb paul |
碰到远端仓库服务器迁移,或者原来的克隆镜像不再使用,又或者某个参与者不再贡献代码,那么需要移除对应的远端仓库,可以运行 git remote rm 命令:
1 | $ git remote rm paul |
打标签
Git 命令别名
Git 并不会推断你输入的几个字符将会是哪条命令,不过如果想偷懒,少敲几个命令的字符,可以用 git config 为命令设置别名。来看看下面的例子:
1 | $ git config --global alias.co checkout |
取消暂存文件时的输入比较繁琐,可以自己设置一下:
1 | $ git config --global alias.unstage 'reset HEAD --' |
这样一来,下面的两条命令完全等同:
1 | $ git unstage fileA |
显然,使用别名的方式看起来更清楚。另外,我们还经常设置 last 命令:
1 | $ git config --global alias.last 'log -1 HEAD' |
然后要看最后一次的提交信息,就变得简单多了
分支的新建与切换
要新建并切换到该分支,运行 git checkout 并加上 -b 参数:
1 | $ git checkout -b iss53 |
回到 master 分支并把它合并进来,然后发布到生产服务器。用 git merge 命令来进行合并:
1 | $ git checkout master |
这相当于执行下面这两条命令:
1 | $ git branch iss53 |
如果顺着一个分支走下去可以到达另一个分支的话,那么 Git 在合并两者时,只会简单地把指针右移,因为这种单线的历史分支不存在任何需要解决的分歧,所以这种合并过程可以称为快进(Fast forward)。
合并之后,master 分支和 hotfix 分支指向同一位置。
由于当前 hotfix 分支和 master 都指向相同的提交对象,所以 hotfix 已经完成了历史使命,可以删掉了。使用 git branch 的 -d 选项执行删除操作:
1 | $ git branch -d hotfix |
遇到冲突时的分支合并
有时候合并操作并不会如此顺利。如果在不同的分支中都修改了同一个文件的同一部分,Git 就无法干净地把两者合到一起(译注:逻辑上说,这种问题只能由人来裁决。)。
Git 作了合并,但没有提交,它会停下来等你解决冲突。要看看哪些文件在合并时发生冲突,可以用 git status 查阅
任何包含未解决冲突的文件都会以未合并(unmerged)的状态列出。Git 会在有冲突的文件里加入标准的冲突解决标记,可以通过它们来手工定位并解决这些冲突。可以看到此文件包含类似下面这样的部分:
1 | <<<<<<< HEAD |
可以看到 ======= 隔开的上半部分,是 HEAD(即 master 分支,在运行 merge 命令时所切换到的分支)中的内容,下半部分是在 iss53 分支中的内容。解决冲突的办法无非是二者选其一或者由你亲自整合到一起。比如你可以通过把这段内容替换为下面这样来解决:
1 | <div id="footer"> |
这个解决方案各采纳了两个分支中的一部分内容,而且我还删除了 <<<<<<<,======= 和 >>>>>>> 这些行。在解决了所有文件里的所有冲突后,运行 git add 将把它们标记为已解决状态(译注:实际上就是来一次快照保存到暂存区域。)。
再运行一次 git status 来确认所有冲突都已解决:
1 | $ git status |
如果觉得满意了,并且确认所有冲突都已解决,也就是进入了暂存区,就可以用 git commit 来完成这次合并提交。提交的记录差不多是这样:
1 | Merge branch 'iss53' |
查看当前的远程库
要查看当前配置有哪些远程仓库,可以用 git remote 命令,它会列出每个远程库的简短名字。
可以加上 -v 选项(译注:此为 --verbose 的简写,取首字母),显示对应的克隆地址
添加远程仓库
要添加一个新的远程仓库,可以指定一个简单的名字,以便将来引用,运行
1 | git remote add [shortname] [url]: |
从远程仓库抓取数据
正如之前所看到的,可以用下面的命令从远程仓库抓取数据到本地:
1 | $ git fetch [remote-name] |
推送数据到远程仓库
项目进行到一个阶段,要同别人分享目前的成果,可以将本地仓库中的数据推送到远程仓库。实现这个任务的命令很简单: git push [remote-name] [branch-name]。如果要把本地的 master 分支推送到 origin 服务器上(再次说明下,克隆操作会自动使用默认的 master 和 origin 名字),可以运行下面的命令:
1 | $ git push origin master |
只有在所克隆的服务器上有写权限,或者同一时刻没有其他人在推数据,这条命令才会如期完成任务。如果在你推数据前,已经有其他人推送了若干更新,那你的推送操作就会被驳回。你必须先把他们的更新抓取到本地,合并到自己的项目中,然后才可以再次推送。
查看远程仓库信息
我们可以通过命令
1 | git remote show [remote-name] |
查看某个远程仓库的详细信息
远程仓库的删除和重命名
在新版 Git 中可以用 git remote rename 命令修改某个远程仓库在本地的简称,比如想把 pb 改成 paul,可以这么运行:
1 | $ git remote rename pb paul |
注意,对远程仓库的重命名,也会使对应的分支名称发生变化,原来的 pb/master 分支现在成了 paul/master。
碰到远端仓库服务器迁移,或者原来的克隆镜像不再使用,又或者某个参与者不再贡献代码,那么需要移除对应的远端仓库,可以运行 git remote rm 命令:
1 | $ git remote rm paul |
远程分支
我们用 ==(远程仓库名)/(分支名)== 这样的形式表示远程分支。比如我们想看看上次同 origin 仓库通讯时 master 分支的样子,就应该查看 origin/master 分支。如果你和同伴一起修复某个问题,但他们先推送了一个 iss53 分支到远程仓库,虽然你可能也有一个本地的 iss53 分支,但指向服务器上最新更新的却应该是 origin/iss53 分支。
可以运行 git fetch origin 来同步远程服务器上的数据到本地。该命令首先找到 origin 是哪个服务器(本例为 git.ourcompany.com),从上面获取你尚未拥有的数据,更新你本地的数据库,然后把 origin/master 的指针移到它最新的位置上
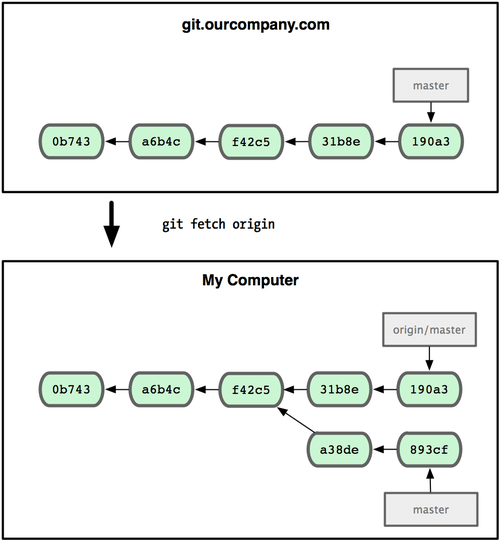
为了演示拥有多个远程分支(在不同的远程服务器上)的项目是如何工作的,我们假设你还有另一个仅供你的敏捷开发小组使用的内部服务器 git.team1.ourcompany.com。可以用第二章中提到的 git remote add 命令把它加为当前项目的远程分支之一。我们把它命名为 teamone,以便代替完整的 Git URL 以方便使用
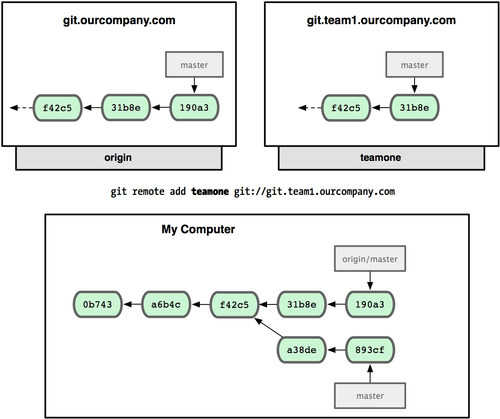
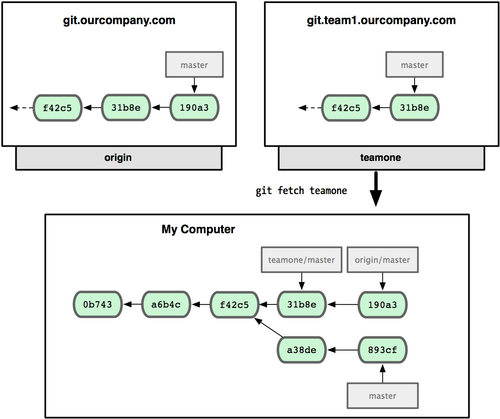
现在你可以用 git fetch teamone 来获取小组服务器上你还没有的数据了。由于当前该服务器上的内容是你 origin 服务器上的子集,Git 不会下载任何数据,而只是简单地创建一个名为 teamone/master 的远程分支,指向 teamone 服务器上 master 分支所在的提交对象 31b8e(见图 3-26)。
推送本地分支
要想和其他人分享某个本地分支,你需要把它推送到一个你拥有写权限的远程仓库。你创建的本地分支不会因为你的写入操作而被自动同步到你引入的远程服务器上,你需要明确地执行推送分支的操作。
如果你有个叫 serverfix 的分支需要和他人一起开发,可以运行 git push (远程仓库名) (分支名):
1 | $ git push origin serverfix |
这里其实走了一点捷径。Git 自动把 serverfix 分支名扩展为 refs/heads/serverfix:refs/heads/serverfix,意为“取出我在本地的 serverfix 分支,推送到远程仓库的 serverfix 分支中去”。
也可以运行 ==git push origin serverfix:serverfix== 来实现相同的效果,它的意思是“上传我本地的 serverfix 分支到远程仓库中去,仍旧称它为 serverfix 分支”。通过此语法,你可以把本地分支推送到某个命名不同的远程分支:若想把远程分支叫作 awesomebranch,可以用 git push origin serverfix:awesomebranch 来推送数据。
跟踪远程分支
从远程分支 checkout 出来的本地分支,称为 跟踪分支 (tracking branch)。跟踪分支是一种和某个远程分支有直接联系的本地分支。在跟踪分支里输入 git push,Git 会自行推断应该向哪个服务器的哪个分支推送数据。同样,在这些分支里运行 git pull 会获取所有远程索引,并把它们的数据都合并到本地分支中来。
在克隆仓库时,Git 通常会自动创建一个名为 master 的分支来跟踪 origin/master。这正是 git push 和 git pull 一开始就能正常工作的原因。当然,你可以随心所欲地设定为其它跟踪分支,比如 origin 上除了 master 之外的其它分支。刚才我们已经看到了这样的一个例子:git checkout -b [分支名] [远程名]/[分支名]。如果你有 1.6.2 以上版本的 Git,还可以用 --track 选项简化:
1 | $ git checkout --track origin/serverfix |
要为本地分支设定不同于远程分支的名字,只需在第一个版本的命令里换个名字:
1 | $ git checkout -b sf origin/serverfix |
现在你的本地分支 sf 会自动将推送和抓取数据的位置定位到 origin/serverfix 了
删除远程分支
如果不再需要某个远程分支了,比如搞定了某个特性并把它合并进了远程的 master 分支(或任何其他存放稳定代码的分支),可以用这个非常无厘头的语法来删除它:git push [远程名] :[分支名]。如果想在服务器上删除 serverfix 分支,运行下面的命令:
1 | $ git push origin :serverfix |
咚!服务器上的分支没了。你最好特别留心这一页,因为你一定会用到那个命令,而且你很可能会忘掉它的语法。有种方便记忆这条命令的方法:==记住我们不久前见过的 git push [远程名] [本地分支]:[远程分支] 语法,如果省略 [本地分支],那就等于是在说“在这里提取空白然后把它变成[远程分支]”==。
解决远程分支和本地冲突
1.先将本地修改储存起来
1 | git stash |
2.pull内容
1 | git pull |
3.还原暂存内容
1 | git stash pop stash@{0} |
4.解决冲突
5.提交
1 | git commit -m '' |
- 打标签
1 | git tag v1.1 -m '' |
7.列标签
1 | git tag -l |
8.获取标签代码
1 | git checkout |
9.提交标签到远程端
1 | git push tag |
拉取本地没有的远程分支
1 | git checkout -b 本地分支名 origin/远程分支名 |