数据库基本上是现代应用程序的标准存储,绝大多数程序都把自己的业务数据存储在关系数据库中,可见,访问数据库几乎是所有应用程序必备能力。
我们在前面已经介绍了Java程序访问数据库的标准接口JDBC,它的实现方式非常简洁,即:Java标准库定义接口,各数据库厂商以“驱动”的形式实现接口。应用程序要使用哪个数据库,就把该数据库厂商的驱动以jar包形式引入进来,同时自身仅使用JDBC接口,编译期并不需要特定厂商的驱动。
使用JDBC虽然简单,但代码比较繁琐。Spring为了简化数据库访问,主要做了以下几点工作:
提供了简化的访问JDBC的模板类,不必手动释放资源;
提供了一个统一的DAO类以实现Data Access Object模式;
把SQLException封装为DataAccessException,这个异常是一个RuntimeException,并且让我们能区分SQL异常的原因,例如,DuplicateKeyException表示违反了一个唯一约束;
能方便地集成Hibernate、JPA和MyBatis这些数据库访问框架。
本章我们将详细讲解在Spring中访问数据库的最佳实践。
我们在前面介绍JDBC编程 时已经讲过,Java程序使用JDBC接口访问关系数据库的时候,需要以下几步:
创建全局DataSource实例,表示数据库连接池;
在需要读写数据库的方法内部,按如下步骤访问数据库:
从全局DataSource实例获取Connection实例;
通过Connection实例创建PreparedStatement实例;
执行SQL语句,如果是查询,则通过ResultSet读取结果集,如果是修改,则获得int结果。
正确编写JDBC代码的关键是使用try ... finally释放资源,涉及到事务的代码需要正确提交或回滚事务。
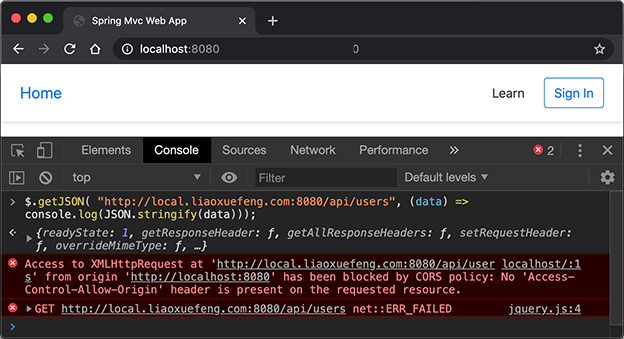
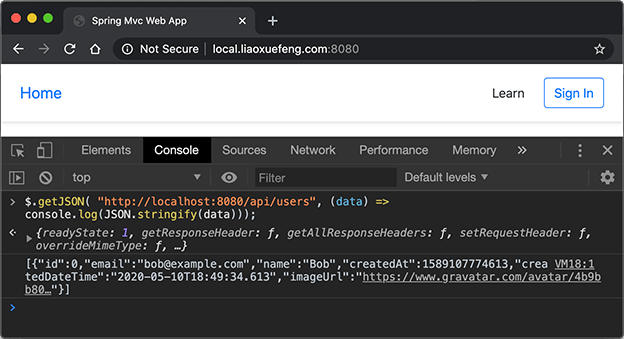
在Spring使用JDBC,首先我们通过IoC容器创建并管理一个DataSource实例,然后,Spring提供了一个JdbcTemplate,可以方便地让我们操作JDBC,因此,通常情况下,我们会实例化一个JdbcTemplate。顾名思义,这个类主要使用了Template模式 。
编写示例代码或者测试代码时,我们强烈推荐使用HSQLDB 这个数据库,它是一个用Java编写的关系数据库,可以以内存模式或者文件模式运行,本身只有一个jar包,非常适合演示代码或者测试代码。
我们以实际工程为例,先创建Maven工程spring-data-jdbc,然后引入以下依赖:
org.springframework:spring-context:6.0.0
org.springframework:spring-jdbc:6.0.0
jakarta.annotation:jakarta.annotation-api:2.1.1
com.zaxxer:HikariCP:5.0.1
org.hsqldb:hsqldb:2.7.1
在AppConfig中,我们需要创建以下几个必须的Bean:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Configuration @ComponentScan @PropertySource("jdbc.properties") public class AppConfig { @Value("${jdbc.url}") String jdbcUrl; @Value("${jdbc.username}") String jdbcUsername; @Value("${jdbc.password}") String jdbcPassword; @Bean DataSource createDataSource () { HikariConfig config = new HikariConfig (); config.setJdbcUrl(jdbcUrl); config.setUsername(jdbcUsername); config.setPassword(jdbcPassword); config.addDataSourceProperty("autoCommit" , "true" ); config.addDataSourceProperty("connectionTimeout" , "5" ); config.addDataSourceProperty("idleTimeout" , "60" ); return new HikariDataSource (config); } @Bean JdbcTemplate createJdbcTemplate (@Autowired DataSource dataSource) { return new JdbcTemplate (dataSource); } }
在上述配置中:
通过@PropertySource("jdbc.properties")读取数据库配置文件;
通过@Value("${jdbc.url}")注入配置文件的相关配置;
创建一个DataSource实例,它的实际类型是HikariDataSource,创建时需要用到注入的配置;
创建一个JdbcTemplate实例,它需要注入DataSource,这是通过方法参数完成注入的。
最后,针对HSQLDB写一个配置文件jdbc.properties:
1 2 3 4 5 6 # 数据库文件名为testdb: jdbc.url=jdbc:hsqldb:file:testdb # Hsqldb默认的用户名是sa,口令是空字符串: jdbc.username=sa jdbc.password=
可以通过HSQLDB自带的工具来初始化数据库表,这里我们写一个Bean,在Spring容器启动时自动创建一个users表:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Component public class DatabaseInitializer { @Autowired JdbcTemplate jdbcTemplate; @PostConstruct public void init () { jdbcTemplate.update("CREATE TABLE IF NOT EXISTS users (" + "id BIGINT IDENTITY NOT NULL PRIMARY KEY, " + "email VARCHAR(100) NOT NULL, " + "password VARCHAR(100) NOT NULL, " + "name VARCHAR(100) NOT NULL, " + "UNIQUE (email))" ); } }
现在,所有准备工作都已完毕。我们只需要在需要访问数据库的Bean中,注入JdbcTemplate即可:
1 2 3 4 5 6 @Component public class UserService { @Autowired JdbcTemplate jdbcTemplate; ... }
JdbcTemplate用法
Spring提供的JdbcTemplate采用Template模式,提供了一系列以回调为特点的工具方法,目的是避免繁琐的try...catch语句。
我们以具体的示例来说明JdbcTemplate的用法。
首先我们看T execute(ConnectionCallback<T> action)方法,它提供了Jdbc的Connection供我们使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public User getUserById (long id) { return jdbcTemplate.execute((Connection conn) -> { try (var ps = conn.prepareStatement("SELECT * FROM users WHERE id = ?" )) { ps.setObject(1 , id); try (var rs = ps.executeQuery()) { if (rs.next()) { return new User ( rs.getLong("id" ), rs.getString("email" ), rs.getString("password" ), rs.getString("name" )); } throw new RuntimeException ("user not found by id." ); } } }); }
也就是说,上述回调方法允许获取Connection,然后做任何基于Connection的操作。
我们再看T execute(String sql, PreparedStatementCallback<T> action)的用法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public User getUserByName (String name) { return jdbcTemplate.execute("SELECT * FROM users WHERE name = ?" , (PreparedStatement ps) -> { ps.setObject(1 , name); try (var rs = ps.executeQuery()) { if (rs.next()) { return new User ( rs.getLong("id" ), rs.getString("email" ), rs.getString("password" ), rs.getString("name" )); } throw new RuntimeException ("user not found by id." ); } }); }
最后,我们看T queryForObject(String sql, RowMapper<T> rowMapper, Object... args)方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 public User getUserByEmail (String email) { return jdbcTemplate.queryForObject("SELECT * FROM users WHERE email = ?" , (ResultSet rs, int rowNum) -> { return new User ( rs.getLong("id" ), rs.getString("email" ), rs.getString("password" ), rs.getString("name" )); }, email); }
在queryForObject()方法中,传入SQL以及SQL参数后,JdbcTemplate会自动创建PreparedStatement,自动执行查询并返回ResultSet,我们提供的RowMapper需要做的事情就是把ResultSet的当前行映射成一个JavaBean并返回。整个过程中,使用Connection、PreparedStatement和ResultSet都不需要我们手动管理。
RowMapper不一定返回JavaBean,实际上它可以返回任何Java对象。例如,使用SELECT COUNT(*)查询时,可以返回Long:
1 2 3 4 5 6 public long getUsers () { return jdbcTemplate.queryForObject("SELECT COUNT(*) FROM users" , (ResultSet rs, int rowNum) -> { return rs.getLong(1 ); }); }
如果我们期望返回多行记录,而不是一行,可以用query()方法:
1 2 3 4 5 6 7 public List<User> getUsers (int pageIndex) { int limit = 100 ; int offset = limit * (pageIndex - 1 ); return jdbcTemplate.query("SELECT * FROM users LIMIT ? OFFSET ?" , new BeanPropertyRowMapper <>(User.class), limit, offset); }
上述query()方法传入的参数仍然是SQL、SQL参数以及RowMapper实例。这里我们直接使用Spring提供的BeanPropertyRowMapper。如果数据库表的结构恰好和JavaBean的属性名称一致,那么BeanPropertyRowMapper就可以直接把一行记录按列名转换为JavaBean。
如果我们执行的不是查询,而是插入、更新和删除操作,那么需要使用update()方法:
1 2 3 4 5 6 public void updateUser (User user) { if (1 != jdbcTemplate.update("UPDATE users SET name = ? WHERE id = ?" , user.getName(), user.getId())) { throw new RuntimeException ("User not found by id" ); } }
只有一种INSERT操作比较特殊,那就是如果某一列是自增列(例如自增主键),通常,我们需要获取插入后的自增值。JdbcTemplate提供了一个KeyHolder来简化这一操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public User register (String email, String password, String name) { KeyHolder holder = new GeneratedKeyHolder (); if (1 != jdbcTemplate.update( (conn) -> { var ps = conn.prepareStatement("INSERT INTO users(email, password, name) VALUES(?, ?, ?)" , Statement.RETURN_GENERATED_KEYS); ps.setObject(1 , email); ps.setObject(2 , password); ps.setObject(3 , name); return ps; }, holder) ) { throw new RuntimeException ("Insert failed." ); } return new User (holder.getKey().longValue(), email, password, name); }
JdbcTemplate还有许多重载方法,这里我们不一一介绍。需要强调的是,JdbcTemplate只是对JDBC操作的一个简单封装,它的目的是尽量减少手动编写try(resource) {...}的代码,对于查询,主要通过RowMapper实现了JDBC结果集到Java对象的转换。
我们总结一下JdbcTemplate的用法,那就是:
针对简单查询,优选query()和queryForObject(),因为只需提供SQL语句、参数和RowMapper;
针对更新操作,优选update(),因为只需提供SQL语句和参数;
任何复杂的操作,最终也可以通过execute(ConnectionCallback)实现,因为拿到Connection就可以做任何JDBC操作。
实际上我们使用最多的仍然是各种查询。如果在设计表结构的时候,能够和JavaBean的属性一一对应,那么直接使用BeanPropertyRowMapper就很方便。如果表结构和JavaBean不一致怎么办?那就需要稍微改写一下查询,使结果集的结构和JavaBean保持一致。
例如,表的列名是office_address,而JavaBean属性是workAddress,就需要指定别名,改写查询如下:
1 SELECT id, email, office_address AS workAddress, name FROM users WHERE email = ?
练习
使用JdbcTemplate。
下载练习
小结
Spring提供了JdbcTemplate来简化JDBC操作;
使用JdbcTemplate时,根据需要优先选择高级方法;
任何JDBC操作都可以使用保底的execute(ConnectionCallback)方法。
使用Spring操作JDBC虽然方便,但是我们在前面讨论JDBC的时候,讲到过JDBC事务 ,如果要在Spring中操作事务,没必要手写JDBC事务,可以使用Spring提供的高级接口来操作事务。
Spring提供了一个PlatformTransactionManager来表示事务管理器,所有的事务都由它负责管理。而事务由TransactionStatus表示。如果手写事务代码,使用try...catch如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 TransactionStatus tx = null ;try { tx = txManager.getTransaction(new DefaultTransactionDefinition ()); jdbcTemplate.update("..." ); jdbcTemplate.update("..." ); txManager.commit(tx); } catch (RuntimeException e) { txManager.rollback(tx); throw e; }
Spring为啥要抽象出PlatformTransactionManager和TransactionStatus?原因是JavaEE除了提供JDBC事务外,它还支持分布式事务JTA(Java Transaction API)。分布式事务是指多个数据源(比如多个数据库,多个消息系统)要在分布式环境下实现事务的时候,应该怎么实现。分布式事务实现起来非常复杂,简单地说就是通过一个分布式事务管理器实现两阶段提交,但本身数据库事务就不快,基于数据库事务实现的分布式事务就慢得难以忍受,所以使用率不高。
Spring为了同时支持JDBC和JTA两种事务模型,就抽象出PlatformTransactionManager。因为我们的代码只需要JDBC事务,因此,在AppConfig中,需要再定义一个PlatformTransactionManager对应的Bean,它的实际类型是DataSourceTransactionManager:
1 2 3 4 5 6 7 8 9 10 @Configuration @ComponentScan @PropertySource("jdbc.properties") public class AppConfig { ... @Bean PlatformTransactionManager createTxManager (@Autowired DataSource dataSource) { return new DataSourceTransactionManager (dataSource); } }
使用编程的方式使用Spring事务仍然比较繁琐,更好的方式是通过声明式事务来实现。使用声明式事务非常简单,除了在AppConfig中追加一个上述定义的PlatformTransactionManager外,再加一个@EnableTransactionManagement就可以启用声明式事务:
1 2 3 4 5 6 7 @Configuration @ComponentScan @EnableTransactionManagement @PropertySource("jdbc.properties") public class AppConfig { ... }
然后,对需要事务支持的方法,加一个@Transactional注解:
1 2 3 4 5 6 7 8 @Component public class UserService { @Transactional public User register (String email, String password, String name) { ... } }
或者更简单一点,直接在Bean的class处加上,表示所有public方法都具有事务支持:
1 2 3 4 5 @Component @Transactional public class UserService { ... }
Spring对一个声明式事务的方法,如何开启事务支持?原理仍然是AOP代理,即通过自动创建Bean的Proxy实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class UserService$$EnhancerBySpringCGLIB extends UserService { UserService target = ... PlatformTransactionManager txManager = ... public User register (String email, String password, String name) { TransactionStatus tx = null ; try { tx = txManager.getTransaction(new DefaultTransactionDefinition ()); target.register(email, password, name); txManager.commit(tx); } catch (RuntimeException e) { txManager.rollback(tx); throw e; } } ... }
注意:声明了@EnableTransactionManagement后,不必额外添加@EnableAspectJAutoProxy。
回滚事务
默认情况下,如果发生了RuntimeException,Spring的声明式事务将自动回滚。在一个事务方法中,如果程序判断需要回滚事务,只需抛出RuntimeException,例如:
1 2 3 4 5 6 7 8 9 @Transactional public buyProducts (long productId, int num) { ... if (store < num) { throw new IllegalArgumentException ("No enough products" ); } ... }
如果要针对Checked Exception回滚事务,需要在@Transactional注解中写出来:
1 2 3 4 @Transactional(rollbackFor = {RuntimeException.class, IOException.class}) public buyProducts (long productId, int num) throws IOException { ... }
上述代码表示在抛出RuntimeException或IOException时,事务将回滚。
为了简化代码,我们强烈建议业务异常体系从RuntimeException派生,这样就不必声明任何特殊异常即可让Spring的声明式事务正常工作:
1 2 3 4 5 6 7 8 9 10 11 public class BusinessException extends RuntimeException { ... } public class LoginException extends BusinessException { ... } public class PaymentException extends BusinessException { ... }
事务边界
在使用事务的时候,明确事务边界非常重要。对于声明式事务,例如,下面的register()方法:
1 2 3 4 5 6 7 @Component public class UserService { @Transactional public User register (String email, String password, String name) { ... } }
它的事务边界就是register()方法开始和结束。
类似的,一个负责给用户增加积分的addBonus()方法:
1 2 3 4 5 6 7 @Component public class BonusService { @Transactional public void addBonus (long userId, int bonus) { ... } }
它的事务边界就是addBonus()方法开始和结束。
在现实世界中,问题总是要复杂一点点。用户注册后,能自动获得100积分,因此,实际代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Component public class UserService { @Autowired BonusService bonusService; @Transactional public User register (String email, String password, String name) { User user = jdbcTemplate.insert("..." ); bonusService.addBonus(user.id, 100 ); } }
现在问题来了:调用方(比如RegisterController)调用UserService.register()这个事务方法,它在内部又调用了BonusService.addBonus()这个事务方法,一共有几个事务?如果addBonus()抛出了异常需要回滚事务,register()方法的事务是否也要回滚?
问题的复杂度是不是一下子提高了10倍?
事务传播
要解决上面的问题,我们首先要定义事务的传播模型。
假设用户注册的入口是RegisterController,它本身没有事务,仅仅是调用UserService.register()这个事务方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Controller public class RegisterController { @Autowired UserService userService; @PostMapping("/register") public ModelAndView doRegister (HttpServletRequest req) { String email = req.getParameter("email" ); String password = req.getParameter("password" ); String name = req.getParameter("name" ); User user = userService.register(email, password, name); return ... } }
因此,UserService.register()这个事务方法的起始和结束,就是事务的范围。
我们需要关心的问题是,在UserService.register()这个事务方法内,调用BonusService.addBonus(),我们期待的事务行为是什么:
1 2 3 4 5 6 7 @Transactional public User register (String email, String password, String name) { User user = jdbcTemplate.insert("..." ); bonusService.addBonus(user.id, 100 ); }
对于大多数业务来说,我们期待BonusService.addBonus()的调用,和UserService.register()应当融合在一起,它的行为应该如下:
UserService.register()已经开启了一个事务,那么在内部调用BonusService.addBonus()时,BonusService.addBonus()方法就没必要再开启一个新事务,直接加入到BonusService.register()的事务里就好了。
其实就相当于:
UserService.register()先执行了一条INSERT语句:INSERT INTO users ...BonusService.addBonus()再执行一条INSERT语句:INSERT INTO bonus ...
因此,Spring的声明式事务为事务传播定义了几个级别,默认传播级别就是REQUIRED,它的意思是,如果当前没有事务,就创建一个新事务,如果当前有事务,就加入到当前事务中执行。
我们观察UserService.register()方法,它在RegisterController中执行,因为RegisterController没有事务,因此,UserService.register()方法会自动创建一个新事务。
在UserService.register()方法内部,调用BonusService.addBonus()方法时,因为BonusService.addBonus()检测到当前已经有事务了,因此,它会加入到当前事务中执行。
因此,整个业务流程的事务边界就清晰了:它只有一个事务,并且范围就是UserService.register()方法。
有的童鞋会问:把BonusService.addBonus()方法的@Transactional去掉,变成一个普通方法,那不就规避了复杂的传播模型吗?
去掉BonusService.addBonus()方法的@Transactional,会引来另一个问题,即其他地方如果调用BonusService.addBonus()方法,那就没法保证事务了。例如,规定用户登录时积分+5:
1 2 3 4 5 6 7 8 9 10 11 @Controller public class LoginController { @Autowired BonusService bonusService; @PostMapping("/login") public ModelAndView doLogin (HttpServletRequest req) { User user = ... bonusService.addBonus(user.id, 5 ); } }
可见,BonusService.addBonus()方法必须要有@Transactional,否则,登录后积分就无法添加了。
默认的事务传播级别是REQUIRED,它满足绝大部分的需求。还有一些其他的传播级别:
SUPPORTS:表示如果有事务,就加入到当前事务,如果没有,那也不开启事务执行。这种传播级别可用于查询方法,因为SELECT语句既可以在事务内执行,也可以不需要事务;
MANDATORY:表示必须要存在当前事务并加入执行,否则将抛出异常。这种传播级别可用于核心更新逻辑,比如用户余额变更,它总是被其他事务方法调用,不能直接由非事务方法调用;
REQUIRES_NEW:表示不管当前有没有事务,都必须开启一个新的事务执行。如果当前已经有事务,那么当前事务会挂起,等新事务完成后,再恢复执行;
NOT_SUPPORTED:表示不支持事务,如果当前有事务,那么当前事务会挂起,等这个方法执行完成后,再恢复执行;
NEVER:和NOT_SUPPORTED相比,它不但不支持事务,而且在监测到当前有事务时,会抛出异常拒绝执行;
NESTED:表示如果当前有事务,则开启一个嵌套级别事务,如果当前没有事务,则开启一个新事务。
上面这么多种事务的传播级别,其实默认的REQUIRED已经满足绝大部分需求,SUPPORTS和REQUIRES_NEW在少数情况下会用到,其他基本不会用到,因为把事务搞得越复杂,不仅逻辑跟着复杂,而且速度也会越慢。
定义事务的传播级别也是写在@Transactional注解里的:
1 2 3 4 @Transactional(propagation = Propagation.REQUIRES_NEW) public Product createProduct () { ... }
现在只剩最后一个问题了:Spring是如何传播事务的?
我们在JDBC中使用事务 的时候,是这么个写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Connection conn = openConnection();try { conn.setAutoCommit(false ); insert(); update(); delete(); conn.commit(); } catch (SQLException e) { conn.rollback(); } finally { conn.setAutoCommit(true ); conn.close(); }
Spring使用声明式事务,最终也是通过执行JDBC事务来实现功能的,那么,一个事务方法,如何获知当前是否存在事务?
答案是使用ThreadLocal 。Spring总是把JDBC相关的Connection和TransactionStatus实例绑定到ThreadLocal。如果一个事务方法从ThreadLocal未取到事务,那么它会打开一个新的JDBC连接,同时开启一个新的事务,否则,它就直接使用从ThreadLocal获取的JDBC连接以及TransactionStatus。
因此,事务能正确传播的前提是,方法调用是在一个线程内才行。如果像下面这样写:
1 2 3 4 5 6 7 8 9 @Transactional public User register (String email, String password, String name) { User user = jdbcTemplate.insert("..." ); new Thread (() -> { bonusService.addBonus(user.id, 100 ); }).start(); }
在另一个线程中调用BonusService.addBonus(),它根本获取不到当前事务,因此,UserService.register()和BonusService.addBonus()两个方法,将分别开启两个完全独立的事务。
换句话说,事务只能在当前线程传播,无法跨线程传播。
那如果我们想实现跨线程传播事务呢?原理很简单,就是要想办法把当前线程绑定到ThreadLocal的Connection和TransactionStatus实例传递给新线程,但实现起来非常复杂,根据异常回滚更加复杂,不推荐自己去实现。
练习
使用声明式事务。
下载练习
小结
Spring提供的声明式事务极大地方便了在数据库中使用事务,正确使用声明式事务的关键在于确定好事务边界,理解事务传播级别。
在传统的多层应用程序中,通常是Web层调用业务层,业务层调用数据访问层。业务层负责处理各种业务逻辑,而数据访问层只负责对数据进行增删改查。因此,实现数据访问层就是用JdbcTemplate实现对数据库的操作。
编写数据访问层的时候,可以使用DAO模式。DAO即Data Access Object的缩写,它没有什么神秘之处,实现起来基本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class UserDao { @Autowired JdbcTemplate jdbcTemplate; User getById (long id) { ... } List<User> getUsers (int page) { ... } User createUser (User user) { ... } User updateUser (User user) { ... } void deleteUser (User user) { ... } }
Spring提供了一个JdbcDaoSupport类,用于简化DAO的实现。这个JdbcDaoSupport没什么复杂的,核心代码就是持有一个JdbcTemplate:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public abstract class JdbcDaoSupport extends DaoSupport { private JdbcTemplate jdbcTemplate; public final void setJdbcTemplate (JdbcTemplate jdbcTemplate) { this .jdbcTemplate = jdbcTemplate; initTemplateConfig(); } public final JdbcTemplate getJdbcTemplate () { return this .jdbcTemplate; } ... }
它的意图是子类直接从JdbcDaoSupport继承后,可以随时调用getJdbcTemplate()获得JdbcTemplate的实例。那么问题来了:因为JdbcDaoSupport的jdbcTemplate字段没有标记@Autowired,所以,子类想要注入JdbcTemplate,还得自己想个办法:
1 2 3 4 5 6 7 8 9 10 11 @Component @Transactional public class UserDao extends JdbcDaoSupport { @Autowired JdbcTemplate jdbcTemplate; @PostConstruct public void init () { super .setJdbcTemplate(jdbcTemplate); } }
有的童鞋可能看出来了:既然UserDao都已经注入了JdbcTemplate,那再把它放到父类里,通过getJdbcTemplate()访问岂不是多此一举?
如果使用传统的XML配置,并不需要编写@Autowired JdbcTemplate jdbcTemplate,但是考虑到现在基本上是使用注解的方式,我们可以编写一个AbstractDao,专门负责注入JdbcTemplate:
1 2 3 4 5 6 7 8 9 public abstract class AbstractDao extends JdbcDaoSupport { @Autowired private JdbcTemplate jdbcTemplate; @PostConstruct public void init () { super .setJdbcTemplate(jdbcTemplate); } }
这样,子类的代码就非常干净,可以直接调用getJdbcTemplate():
1 2 3 4 5 6 7 8 9 10 11 12 @Component @Transactional public class UserDao extends AbstractDao { public User getById (long id) { return getJdbcTemplate().queryForObject( "SELECT * FROM users WHERE id = ?" , new BeanPropertyRowMapper <>(User.class), id ); } ... }
倘若肯再多写一点样板代码,就可以把AbstractDao改成泛型,并实现getById(),getAll(),deleteById()这样的通用方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public abstract class AbstractDao <T> extends JdbcDaoSupport { private String table; private Class<T> entityClass; private RowMapper<T> rowMapper; public AbstractDao () { this .entityClass = getParameterizedType(); this .table = this .entityClass.getSimpleName().toLowerCase() + "s" ; this .rowMapper = new BeanPropertyRowMapper <>(entityClass); } public T getById (long id) { return getJdbcTemplate().queryForObject("SELECT * FROM " + table + " WHERE id = ?" , this .rowMapper, id); } public List<T> getAll (int pageIndex) { int limit = 100 ; int offset = limit * (pageIndex - 1 ); return getJdbcTemplate().query("SELECT * FROM " + table + " LIMIT ? OFFSET ?" , new Object [] { limit, offset }, this .rowMapper); } public void deleteById (long id) { getJdbcTemplate().update("DELETE FROM " + table + " WHERE id = ?" , id); } ... }
这样,每个子类就自动获得了这些通用方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Component @Transactional public class UserDao extends AbstractDao <User> { } @Component @Transactional public class BookDao extends AbstractDao <Book> { }
可见,DAO模式就是一个简单的数据访问模式,是否使用DAO,根据实际情况决定,因为很多时候,直接在Service层操作数据库也是完全没有问题的。
练习
使用DAO模式访问数据库。
下载练习
小结
Spring提供了JdbcDaoSupport来便于我们实现DAO模式;
可以基于泛型实现更通用、更简洁的DAO模式。
使用JdbcTemplate的时候,我们用得最多的方法就是List<T> query(String, RowMapper, Object...)。这个RowMapper的作用就是把ResultSet的一行记录映射为Java Bean。
这种把关系数据库的表记录映射为Java对象的过程就是ORM:Object-Relational Mapping。ORM既可以把记录转换成Java对象,也可以把Java对象转换为行记录。
使用JdbcTemplate配合RowMapper可以看作是最原始的ORM。如果要实现更自动化的ORM,可以选择成熟的ORM框架,例如Hibernate 。
我们来看看如何在Spring中集成Hibernate。
Hibernate作为ORM框架,它可以替代JdbcTemplate,但Hibernate仍然需要JDBC驱动,所以,我们需要引入JDBC驱动、连接池,以及Hibernate本身。在Maven中,我们加入以下依赖项:
org.springframework:spring-context:6.0.0
org.springframework:spring-orm:6.0.0
jakarta.annotation:jakarta.annotation-api:2.1.1
jakarta.persistence:jakarta.persistence-api:3.1.0
org.hibernate:hibernate-core:6.1.4.Final
com.zaxxer:HikariCP:5.0.1
org.hsqldb:hsqldb:2.7.1
在AppConfig中,我们仍然需要创建DataSource、引入JDBC配置文件,以及启用声明式事务:
1 2 3 4 5 6 7 8 9 10 @Configuration @ComponentScan @EnableTransactionManagement @PropertySource("jdbc.properties") public class AppConfig { @Bean DataSource createDataSource () { ... } }
为了启用Hibernate,我们需要创建一个LocalSessionFactoryBean:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class AppConfig { @Bean LocalSessionFactoryBean createSessionFactory (@Autowired DataSource dataSource) { var props = new Properties (); props.setProperty("hibernate.hbm2ddl.auto" , "update" ); props.setProperty("hibernate.dialect" , "org.hibernate.dialect.HSQLDialect" ); props.setProperty("hibernate.show_sql" , "true" ); var sessionFactoryBean = new LocalSessionFactoryBean (); sessionFactoryBean.setDataSource(dataSource); sessionFactoryBean.setPackagesToScan("com.itranswarp.learnjava.entity" ); sessionFactoryBean.setHibernateProperties(props); return sessionFactoryBean; } }
注意我们在定制Bean 中讲到过FactoryBean,LocalSessionFactoryBean是一个FactoryBean,它会再自动创建一个SessionFactory,在Hibernate中,Session是封装了一个JDBC Connection的实例,而SessionFactory是封装了JDBC DataSource的实例,即SessionFactory持有连接池,每次需要操作数据库的时候,SessionFactory创建一个新的Session,相当于从连接池获取到一个新的Connection。SessionFactory就是Hibernate提供的最核心的一个对象,但LocalSessionFactoryBean是Spring提供的为了让我们方便创建SessionFactory的类。
注意到上面创建LocalSessionFactoryBean的代码,首先用Properties持有Hibernate初始化SessionFactory时用到的所有设置,常用的设置请参考Hibernate文档 ,这里我们只定义了3个设置:
hibernate.hbm2ddl.auto=update:表示自动创建数据库的表结构,注意不要在生产环境中启用;hibernate.dialect=org.hibernate.dialect.HSQLDialect:指示Hibernate使用的数据库是HSQLDB。Hibernate使用一种HQL的查询语句,它和SQL类似,但真正在“翻译”成SQL时,会根据设定的数据库“方言”来生成针对数据库优化的SQL;hibernate.show_sql=true:让Hibernate打印执行的SQL,这对于调试非常有用,我们可以方便地看到Hibernate生成的SQL语句是否符合我们的预期。
除了设置DataSource和Properties之外,注意到setPackagesToScan()我们传入了一个package名称,它指示Hibernate扫描这个包下面的所有Java类,自动找出能映射为数据库表记录的JavaBean。后面我们会仔细讨论如何编写符合Hibernate要求的JavaBean。
紧接着,我们还需要创建HibernateTransactionManager:
1 2 3 4 5 6 public class AppConfig { @Bean PlatformTransactionManager createTxManager (@Autowired SessionFactory sessionFactory) { return new HibernateTransactionManager (sessionFactory); } }
HibernateTransactionManager是配合Hibernate使用声明式事务所必须的。到此为止,所有的配置都定义完毕,我们来看看如何将数据库表结构映射为Java对象。
考察如下的数据库表:
1 2 3 4 5 6 7 8 9 CREATE TABLE user id BIGINT NOT NULL AUTO_INCREMENT, email VARCHAR (100 ) NOT NULL , password VARCHAR (100 ) NOT NULL , name VARCHAR (100 ) NOT NULL , createdAt BIGINT NOT NULL , PRIMARY KEY (`id`), UNIQUE KEY `email` (`email`) );
其中,id是自增主键,email、password、name是VARCHAR类型,email带唯一索引以确保唯一性,createdAt存储整型类型的时间戳。用JavaBean表示如下:
1 2 3 4 5 6 7 8 9 10 public class User { private Long id; private String email; private String password; private String name; private Long createdAt; ... }
这种映射关系十分易懂,但我们需要添加一些注解来告诉Hibernate如何把User类映射到表记录:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Entity public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(nullable = false, updatable = false) public Long getId () { ... } @Column(nullable = false, unique = true, length = 100) public String getEmail () { ... } @Column(nullable = false, length = 100) public String getPassword () { ... } @Column(nullable = false, length = 100) public String getName () { ... } @Column(nullable = false, updatable = false) public Long getCreatedAt () { ... } }
如果一个JavaBean被用于映射,我们就标记一个@Entity。默认情况下,映射的表名是user,如果实际的表名不同,例如实际表名是users,可以追加一个@Table(name="users")表示:
1 2 3 4 5 @Entity @Table(name="users") public class User { ... }
每个属性到数据库列的映射用@Column()标识,nullable指示列是否允许为NULL,updatable指示该列是否允许被用在UPDATE语句,length指示String类型的列的长度(如果没有指定,默认是255)。
对于主键,还需要用@Id标识,自增主键再追加一个@GeneratedValue,以便Hibernate能读取到自增主键的值。
细心的童鞋可能还注意到,主键id定义的类型不是long,而是Long。这是因为Hibernate如果检测到主键为null,就不会在INSERT语句中指定主键的值,而是返回由数据库生成的自增值,否则,Hibernate认为我们的程序指定了主键的值,会在INSERT语句中直接列出。long型字段总是具有默认值0,因此,每次插入的主键值总是0,导致除第一次外后续插入都将失败。
createdAt虽然是整型,但我们并没有使用long,而是Long,这是因为使用基本类型会导致findByExample查询会添加意外的条件,这里只需牢记,作为映射使用的JavaBean,所有属性都使用包装类型而不是基本类型。
注意
使用Hibernate时,不要使用基本类型的属性,总是使用包装类型,如Long或Integer。
类似的,我们再定义一个Book类:
1 2 3 4 5 6 7 8 9 10 11 12 13 @Entity public class Book { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(nullable = false, updatable = false) public Long getId () { ... } @Column(nullable = false, length = 100) public String getTitle () { ... } @Column(nullable = false, updatable = false) public Long getCreatedAt () { ... } }
如果仔细观察User和Book,会发现它们定义的id、createdAt属性是一样的,这在数据库表结构的设计中很常见:对于每个表,通常我们会统一使用一种主键生成机制,并添加createdAt表示创建时间,updatedAt表示修改时间等通用字段。
不必在User和Book中重复定义这些通用字段,我们可以把它们提到一个抽象类中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @MappedSuperclass public abstract class AbstractEntity { private Long id; private Long createdAt; @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(nullable = false, updatable = false) public Long getId () { ... } @Column(nullable = false, updatable = false) public Long getCreatedAt () { ... } @Transient public ZonedDateTime getCreatedDateTime () { return Instant.ofEpochMilli(this .createdAt).atZone(ZoneId.systemDefault()); } @PrePersist public void preInsert () { setCreatedAt(System.currentTimeMillis()); } }
对于AbstractEntity来说,我们要标注一个@MappedSuperclass表示它用于继承。此外,注意到我们定义了一个@Transient方法,它返回一个“虚拟”的属性。因为getCreatedDateTime()是计算得出的属性,而不是从数据库表读出的值,因此必须要标注@Transient,否则Hibernate会尝试从数据库读取名为createdDateTime这个不存在的字段从而出错。
再注意到@PrePersist标识的方法,它表示在我们将一个JavaBean持久化到数据库之前(即执行INSERT语句),Hibernate会先执行该方法,这样我们就可以自动设置好createdAt属性。
有了AbstractEntity,我们就可以大幅简化User和Book:
1 2 3 4 5 6 7 8 9 10 11 12 @Entity public class User extends AbstractEntity { @Column(nullable = false, unique = true, length = 100) public String getEmail () { ... } @Column(nullable = false, length = 100) public String getPassword () { ... } @Column(nullable = false, length = 100) public String getName () { ... } }
注意到使用的所有注解均来自jakarta.persistence,它是JPA规范的一部分。这里我们只介绍使用注解的方式配置Hibernate映射关系,不再介绍传统的比较繁琐的XML配置。通过Spring集成Hibernate时,也不再需要hibernate.cfg.xml配置文件,用一句话总结:
提示
使用Spring集成Hibernate,配合JPA注解,无需任何额外的XML配置。
类似User、Book这样的用于ORM的Java Bean,我们通常称之为Entity Bean。
最后,我们来看看如果对user表进行增删改查。因为使用了Hibernate,因此,我们要做的,实际上是对User这个JavaBean进行“增删改查”。我们编写一个UserService,注入SessionFactory:
1 2 3 4 5 6 @Component @Transactional public class UserService { @Autowired SessionFactory sessionFactory; }
Insert操作
要持久化一个User实例,我们只需调用persist()方法。以register()方法为例,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public User register (String email, String password, String name) { User user = new User (); user.setEmail(email); user.setPassword(password); user.setName(name); sessionFactory.getCurrentSession().persist(user); System.out.println(user.getId()); return user; }
Delete操作
删除一个User相当于从表中删除对应的记录。注意Hibernate总是用id来删除记录,因此,要正确设置User的id属性才能正常删除记录:
1 2 3 4 5 6 7 8 public boolean deleteUser (Long id) { User user = sessionFactory.getCurrentSession().byId(User.class).load(id); if (user != null ) { sessionFactory.getCurrentSession().remove(user); return true ; } return false ; }
通过主键删除记录时,一个常见的用法是先根据主键加载该记录,再删除。注意到当记录不存在时,load()返回null。
Update操作
更新记录相当于先更新User的指定属性,然后调用merge()方法:
1 2 3 4 5 public void updateUser (Long id, String name) { User user = sessionFactory.getCurrentSession().byId(User.class).load(id); user.setName(name); sessionFactory.getCurrentSession().merge(user); }
前面我们在定义User时,对有的属性标注了@Column(updatable=false)。Hibernate在更新记录时,它只会把@Column(updatable=true)的属性加入到UPDATE语句中,这样可以提供一层额外的安全性,即如果不小心修改了User的email、createdAt等属性,执行update()时并不会更新对应的数据库列。但也必须牢记:这个功能是Hibernate提供的,如果绕过Hibernate直接通过JDBC执行UPDATE语句仍然可以更新数据库的任意列的值。
最后,我们编写的大部分方法都是各种各样的查询。根据id查询我们可以直接调用load(),如果要使用条件查询,例如,假设我们想执行以下查询:
1 SELECT * FROM user WHERE email = ? AND password = ?
我们来看看可以使用什么查询。
使用HQL查询
一种常用的查询是直接编写Hibernate内置的HQL查询:
1 2 3 4 List<User> list = sessionFactory.getCurrentSession() .createQuery("from User u where u.email = ?1 and u.password = ?2" , User.class) .setParameter(1 , email).setParameter(2 , password) .list();
和SQL相比,HQL使用类名和属性名,由Hibernate自动转换为实际的表名和列名。详细的HQL语法可以参考Hibernate文档 。
除了可以直接传入HQL字符串外,Hibernate还可以使用一种NamedQuery,它给查询起个名字,然后保存在注解中。使用NamedQuery时,我们要先在User类标注:
1 2 3 4 5 6 7 8 9 10 11 12 @NamedQueries( @NamedQuery( // 查询名称: name = "login", // 查询语句: query = "SELECT u FROM User u WHERE u.email = :e AND u.password = :pwd" ) ) @Entity public class User extends AbstractEntity { ... }
注意到引入的NamedQuery是jakarta.persistence.NamedQuery,它和直接传入HQL有点不同的是,占位符使用:e和:pwd。
使用NamedQuery只需要引入查询名和参数:
1 2 3 4 5 6 7 8 public User login (String email, String password) { List<User> list = sessionFactory.getCurrentSession() .createNamedQuery("login" , User.class) .setParameter("e" , email) .setParameter("pwd" , password) .list(); return list.isEmpty() ? null : list.get(0 ); }
直接写HQL和使用NamedQuery各有优劣。前者可以在代码中直观地看到查询语句,后者可以在User类统一管理所有相关查询。
练习
集成Hibernate操作数据库。
下载练习
小结
在Spring中集成Hibernate需要配置的Bean如下:
DataSource;
LocalSessionFactory;
HibernateTransactionManager。
推荐使用Annotation配置所有的Entity Bean。
上一节我们讲了在Spring中集成Hibernate。Hibernate是第一个被广泛使用的ORM框架,但是很多小伙伴还听说过JPA:Java Persistence API,这又是啥?
在讨论JPA之前,我们要注意到JavaEE早在1999年就发布了,并且有Servlet、JMS等诸多标准。和其他平台不同,Java世界早期非常热衷于标准先行,各家跟进:大家先坐下来把接口定了,然后,各自回家干活去实现接口,这样,用户就可以在不同的厂家提供的产品进行选择,还可以随意切换,因为用户编写代码的时候只需要引用接口,并不需要引用具体的底层实现(想想JDBC)。
JPA就是JavaEE的一个ORM标准,它的实现其实和Hibernate没啥本质区别,但是用户如果使用JPA,那么引用的就是jakarta.persistence这个“标准”包,而不是org.hibernate这样的第三方包。因为JPA只是接口,所以,还需要选择一个实现产品,跟JDBC接口和MySQL驱动一个道理。
我们使用JPA时也完全可以选择Hibernate作为底层实现,但也可以选择其它的JPA提供方,比如EclipseLink 。Spring内置了JPA的集成,并支持选择Hibernate或EclipseLink作为实现。这里我们仍然以主流的Hibernate作为JPA实现为例子,演示JPA的基本用法。
和使用Hibernate一样,我们只需要引入如下依赖:
org.springframework:spring-context:6.0.0
org.springframework:spring-orm:6.0.0
jakarta.annotation:jakarta.annotation-api:2.1.1
jakarta.persistence:jakarta.persistence-api:3.1.0
org.hibernate:hibernate-core:6.1.4.Final
com.zaxxer:HikariCP:5.0.1
org.hsqldb:hsqldb:2.7.1
实际上我们这里引入的依赖和上一节集成Hibernate引入的依赖完全一样,因为Hibernate既提供了它自己的接口,也提供了JPA接口,我们用JPA接口就相当于通过JPA操作Hibernate。
然后,在AppConfig中启用声明式事务管理,创建DataSource:
1 2 3 4 5 6 7 8 @Configuration @ComponentScan @EnableTransactionManagement @PropertySource("jdbc.properties") public class AppConfig { @Bean DataSource createDataSource () { ... } }
使用Hibernate时,我们需要创建一个LocalSessionFactoryBean,并让它再自动创建一个SessionFactory。使用JPA也是类似的,我们也创建一个LocalContainerEntityManagerFactoryBean,并让它再自动创建一个EntityManagerFactory:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Bean public LocalContainerEntityManagerFactoryBean createEntityManagerFactory (@Autowired DataSource dataSource) { var emFactory = new LocalContainerEntityManagerFactoryBean (); emFactory.setDataSource(dataSource); emFactory.setPackagesToScan(AbstractEntity.class.getPackageName()); emFactory.setJpaVendorAdapter(new HibernateJpaVendorAdapter ()); var props = new Properties (); props.setProperty("hibernate.hbm2ddl.auto" , "update" ); props.setProperty("hibernate.dialect" , "org.hibernate.dialect.HSQLDialect" ); props.setProperty("hibernate.show_sql" , "true" ); emFactory.setJpaProperties(props); return emFactory; }
观察上述代码,除了需要注入DataSource和设定自动扫描的package外,还需要指定JPA的提供商,这里使用Spring提供的一个HibernateJpaVendorAdapter,最后,针对Hibernate自己需要的配置,以Properties的形式注入。
最后,我们还需要实例化一个JpaTransactionManager,以实现声明式事务:
1 2 3 4 @Bean PlatformTransactionManager createTxManager (@Autowired EntityManagerFactory entityManagerFactory) { return new JpaTransactionManager (entityManagerFactory); }
这样,我们就完成了JPA的全部初始化工作。有些童鞋可能从网上搜索得知JPA需要persistence.xml配置文件,以及复杂的orm.xml文件。这里我们负责地告诉大家,使用Spring+Hibernate作为JPA实现,无需任何配置文件。
所有Entity Bean的配置和上一节完全相同,全部采用Annotation标注。我们现在只需关心具体的业务类如何通过JPA接口操作数据库。
还是以UserService为例,除了标注@Component和@Transactional外,我们需要注入一个EntityManager,但是不要使用Autowired,而是@PersistenceContext:
1 2 3 4 5 6 @Component @Transactional public class UserService { @PersistenceContext EntityManager em; }
我们回顾一下JDBC、Hibernate和JPA提供的接口,实际上,它们的关系如下:
JDBC
Hibernate
JPA
DataSource
SessionFactory
EntityManagerFactory
Connection
Session
EntityManager
SessionFactory和EntityManagerFactory相当于DataSource,Session和EntityManager相当于Connection。每次需要访问数据库的时候,需要获取新的Session和EntityManager,用完后再关闭。
但是,注意到UserService注入的不是EntityManagerFactory,而是EntityManager,并且标注了@PersistenceContext。难道使用JPA可以允许多线程操作同一个EntityManager?
实际上这里注入的并不是真正的EntityManager,而是一个EntityManager的代理类,相当于:
1 2 3 public class EntityManagerProxy implements EntityManager { private EntityManagerFactory emf; }
Spring遇到标注了@PersistenceContext的EntityManager会自动注入代理,该代理会在必要的时候自动打开EntityManager。换句话说,多线程引用的EntityManager虽然是同一个代理类,但该代理类内部针对不同线程会创建不同的EntityManager实例。
简单总结一下,标注了@PersistenceContext的EntityManager可以被多线程安全地共享。
因此,在UserService的每个业务方法里,直接使用EntityManager就很方便。以主键查询为例:
1 2 3 4 5 6 7 public User getUserById (long id) { User user = this .em.find(User.class, id); if (user == null ) { throw new RuntimeException ("User not found by id: " + id); } return user; }
与HQL查询类似,JPA使用JPQL查询,它的语法和HQL基本差不多:
1 2 3 4 5 6 7 8 9 10 public User fetchUserByEmail (String email) { TypedQuery<User> query = em.createQuery("SELECT u FROM User u WHERE u.email = :e" , User.class); query.setParameter("e" , email); List<User> list = query.getResultList(); if (list.isEmpty()) { return null ; } return list.get(0 ); }
同样的,JPA也支持NamedQuery,即先给查询起个名字,再按名字创建查询:
1 2 3 4 5 6 7 public User login (String email, String password) { TypedQuery<User> query = em.createNamedQuery("login" , User.class); query.setParameter("e" , email); query.setParameter("pwd" , password); List<User> list = query.getResultList(); return list.isEmpty() ? null : list.get(0 ); }
NamedQuery通过注解标注在User类上,它的定义和上一节的User类一样:
1 2 3 4 5 6 7 8 9 10 @NamedQueries( @NamedQuery( name = "login", query = "SELECT u FROM User u WHERE u.email=:e AND u.password=:pwd" ) ) @Entity public class User { ... }
对数据库进行增删改的操作,可以分别使用persist()、remove()和merge()方法,参数均为Entity Bean本身,使用非常简单,这里不再多述。
练习
使用JPA操作数据库。
下载练习
小结
在Spring中集成JPA要选择一个实现,可以选择Hibernate或EclipseLink;
使用JPA与Hibernate类似,但注入的核心资源是带有@PersistenceContext注解的EntityManager代理类。
使用Hibernate或JPA操作数据库时,这类ORM干的主要工作就是把ResultSet的每一行变成Java Bean,或者把Java Bean自动转换到INSERT或UPDATE语句的参数中,从而实现ORM。
而ORM框架之所以知道如何把行数据映射到Java Bean,是因为我们在Java Bean的属性上给了足够的注解作为元数据,ORM框架获取Java Bean的注解后,就知道如何进行双向映射。
那么,ORM框架是如何跟踪Java Bean的修改,以便在update()操作中更新必要的属性?
答案是使用Proxy模式 ,从ORM框架读取的User实例实际上并不是User类,而是代理类,代理类继承自User类,但针对每个setter方法做了覆写:
1 2 3 4 5 6 7 8 public class UserProxy extends User { boolean _isNameChanged; public void setName (String name) { super .setName(name); _isNameChanged = true ; } }
这样,代理类可以跟踪到每个属性的变化。
针对一对多或多对一关系时,代理类可以直接通过getter方法查询数据库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class UserProxy extends User { Session _session; boolean _isNameChanged; public void setName (String name) { super .setName(name); _isNameChanged = true ; } public Address getAddress () { Query q = _session.createQuery("from Address where userId = :userId" ); q.setParameter("userId" , this .getId()); List<Address> list = query.list(); return list.isEmpty() ? null : list(0 ); } }
为了实现这样的查询,UserProxy必须保存Hibernate的当前Session。但是,当事务提交后,Session自动关闭,此时再获取getAddress()将无法访问数据库,或者获取的不是事务一致的数据。因此,ORM框架总是引入了Attached/Detached状态,表示当前此Java Bean到底是在Session的范围内,还是脱离了Session变成了一个“游离”对象。很多初学者无法正确理解状态变化和事务边界,就会造成大量的PersistentObjectException异常。这种隐式状态使得普通Java Bean的生命周期变得复杂。
此外,Hibernate和JPA为了实现兼容多种数据库,它使用HQL或JPQL查询,经过一道转换,变成特定数据库的SQL,理论上这样可以做到无缝切换数据库,但这一层自动转换除了少许的性能开销外,给SQL级别的优化带来了麻烦。
最后,ORM框架通常提供了缓存,并且还分为一级缓存和二级缓存。一级缓存是指在一个Session范围内的缓存,常见的情景是根据主键查询时,两次查询可以返回同一实例:
1 2 User user1 = session.load(User.class, 123 );User user2 = session.load(User.class, 123 );
二级缓存是指跨Session的缓存,一般默认关闭,需要手动配置。二级缓存极大的增加了数据的不一致性,原因在于SQL非常灵活,常常会导致意外的更新。例如:
1 2 3 4 5 User user1 = session1.load(User.class, 123 );... User user2 = session2.load(User.class, 123 );
当二级缓存生效的时候,两个线程读取的User实例是一样的,但是,数据库对应的行记录完全可能被修改,例如:
1 2 UPDATE users SET bonus = bonus + 100 WHERE createdAt <= ?
ORM无法判断id=123的用户是否受该UPDATE语句影响。考虑到数据库通常会支持多个应用程序,此UPDATE语句可能由其他进程执行,ORM框架就更不知道了。
我们把这种ORM框架称之为全自动ORM框架。
对比Spring提供的JdbcTemplate,它和ORM框架相比,主要有几点差别:
查询后需要手动提供Mapper实例以便把ResultSet的每一行变为Java对象;
增删改操作所需的参数列表,需要手动传入,即把User实例变为[user.id, user.name , user.email]这样的列表,比较麻烦。
但是JdbcTemplate的优势在于它的确定性:即每次读取操作一定是数据库操作而不是缓存,所执行的SQL是完全确定的,缺点就是代码比较繁琐,构造INSERT INTO users VALUES (?,?,?)更是复杂。
所以,介于全自动ORM如Hibernate和手写全部如JdbcTemplate之间,还有一种半自动的ORM,它只负责把ResultSet自动映射到Java Bean,或者自动填充Java Bean参数,但仍需自己写出SQL。MyBatis 就是这样一种半自动化ORM框架。
我们来看看如何在Spring中集成MyBatis。
首先,我们要引入MyBatis本身,其次,由于Spring并没有像Hibernate那样内置对MyBatis的集成,所以,我们需要再引入MyBatis官方自己开发的一个与Spring集成的库:
org.mybatis:mybatis:3.5.11
org.mybatis:mybatis-spring:3.0.0
和前面一样,先创建DataSource是必不可少的:
1 2 3 4 5 6 7 8 @Configuration @ComponentScan @EnableTransactionManagement @PropertySource("jdbc.properties") public class AppConfig { @Bean DataSource createDataSource () { ... } }
再回顾一下Hibernate和JPA的SessionFactory与EntityManagerFactory,MyBatis与之对应的是SqlSessionFactory和SqlSession:
JDBC
Hibernate
JPA
MyBatis
DataSource
SessionFactory
EntityManagerFactory
SqlSessionFactory
Connection
Session
EntityManager
SqlSession
可见,ORM的设计套路都是类似的。使用MyBatis的核心就是创建SqlSessionFactory,这里我们需要创建的是SqlSessionFactoryBean:
1 2 3 4 5 6 @Bean SqlSessionFactoryBean createSqlSessionFactoryBean (@Autowired DataSource dataSource) { var sqlSessionFactoryBean = new SqlSessionFactoryBean (); sqlSessionFactoryBean.setDataSource(dataSource); return sqlSessionFactoryBean; }
因为MyBatis可以直接使用Spring管理的声明式事务,因此,创建事务管理器和使用JDBC是一样的:
1 2 3 4 @Bean PlatformTransactionManager createTxManager (@Autowired DataSource dataSource) { return new DataSourceTransactionManager (dataSource); }
和Hibernate不同的是,MyBatis使用Mapper来实现映射,而且Mapper必须是接口。我们以User类为例,在User类和users表之间映射的UserMapper编写如下:
1 2 3 4 public interface UserMapper { @Select("SELECT * FROM users WHERE id = #{id}") User getById (@Param("id") long id) ; }
注意:这里的Mapper不是JdbcTemplate的RowMapper的概念,它是定义访问users表的接口方法。比如我们定义了一个User getById(long)的主键查询方法,不仅要定义接口方法本身,还要明确写出查询的SQL,这里用注解@Select标记。SQL语句的任何参数,都与方法参数按名称对应。例如,方法参数id的名字通过注解@Param()标记为id,则SQL语句里将来替换的占位符就是#{id}。
如果有多个参数,那么每个参数命名后直接在SQL中写出对应的占位符即可:
1 2 @Select("SELECT * FROM users LIMIT #{offset}, #{maxResults}") List<User> getAll (@Param("offset") int offset, @Param("maxResults") int maxResults) ;
注意:MyBatis执行查询后,将根据方法的返回类型自动把ResultSet的每一行转换为User实例,转换规则当然是按列名和属性名对应。如果列名和属性名不同,最简单的方式是编写SELECT语句的别名:
1 2 SELECT id, name, email, created_time AS createdAt FROM users
执行INSERT语句就稍微麻烦点,因为我们希望传入User实例,因此,定义的方法接口与@Insert注解如下:
1 2 @Insert("INSERT INTO users (email, password, name, createdAt) VALUES (#{user.email}, #{user.password}, #{user.name}, #{user.createdAt})") void insert (@Param("user") User user) ;
上述方法传入的参数名称是user,参数类型是User类,在SQL中引用的时候,以#{obj.property}的方式写占位符。和Hibernate这样的全自动化ORM相比,MyBatis必须写出完整的INSERT语句。
如果users表的id是自增主键,那么,我们在SQL中不传入id,但希望获取插入后的主键,需要再加一个@Options注解:
1 2 3 @Options(useGeneratedKeys = true, keyProperty = "id", keyColumn = "id") @Insert("INSERT INTO users (email, password, name, createdAt) VALUES (#{user.email}, #{user.password}, #{user.name}, #{user.createdAt})") void insert (@Param("user") User user) ;
keyProperty和keyColumn分别指出JavaBean的属性和数据库的主键列名。
执行UPDATE和DELETE语句相对比较简单,我们定义方法如下:
1 2 3 4 5 @Update("UPDATE users SET name = #{user.name}, createdAt = #{user.createdAt} WHERE id = #{user.id}") void update (@Param("user") User user) ;@Delete("DELETE FROM users WHERE id = #{id}") void deleteById (@Param("id") long id) ;
有了UserMapper接口,还需要对应的实现类才能真正执行这些数据库操作的方法。虽然可以自己写实现类,但我们除了编写UserMapper接口外,还有BookMapper、BonusMapper……一个一个写太麻烦,因此,MyBatis提供了一个MapperFactoryBean来自动创建所有Mapper的实现类。可以用一个简单的注解来启用它:
1 2 3 4 5 @MapperScan("com.itranswarp.learnjava.mapper") ...其他注解... public class AppConfig { ... }
有了@MapperScan,就可以让MyBatis自动扫描指定包的所有Mapper并创建实现类。在真正的业务逻辑中,我们可以直接注入:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Component @Transactional public class UserService { @Autowired UserMapper userMapper; public User getUserById (long id) { User user = userMapper.getById(id); if (user == null ) { throw new RuntimeException ("User not found by id." ); } return user; } }
可见,业务逻辑主要就是通过XxxMapper定义的数据库方法来访问数据库。
XML配置
上述在Spring中集成MyBatis的方式,我们只需要用到注解,并没有任何XML配置文件。MyBatis也允许使用XML配置映射关系和SQL语句,例如,更新User时根据属性值构造动态SQL:
1 2 3 4 5 6 7 8 9 <update id ="updateUser" > UPDATE users SET <set > <if test ="user.name != null" > name = #{user.name} </if > <if test ="user.hobby != null" > hobby = #{user.hobby} </if > <if test ="user.summary != null" > summary = #{user.summary} </if > </set > WHERE id = #{user.id} </update >
编写XML配置的优点是可以组装出动态SQL,并且把所有SQL操作集中在一起。缺点是配置起来太繁琐,调用方法时如果想查看SQL还需要定位到XML配置中。这里我们不介绍XML的配置方式,需要了解的童鞋请自行阅读官方文档 。
使用MyBatis最大的问题是所有SQL都需要全部手写,优点是执行的SQL就是我们自己写的SQL,对SQL进行优化非常简单,也可以编写任意复杂的SQL,或者使用数据库的特定语法,但切换数据库可能就不太容易。好消息是大部分项目并没有切换数据库的需求,完全可以针对某个数据库编写尽可能优化的SQL。
练习
集成MyBatis操作数据库。
下载练习
小结
MyBatis是一个半自动化的ORM框架,需要手写SQL语句,没有自动加载一对多或多对一关系的功能。
我们从前几节可以看到,所谓ORM,也是建立在JDBC的基础上,通过ResultSet到JavaBean的映射,实现各种查询。有自动跟踪Entity修改的全自动化ORM如Hibernate和JPA,需要为每个Entity创建代理,也有完全自己映射,连INSERT和UPDATE语句都需要手动编写的MyBatis,但没有任何透明的Proxy。
而查询是涉及到数据库使用最广泛的操作,需要最大的灵活性。各种ORM解决方案各不相同,Hibernate和JPA自己实现了HQL和JPQL查询语法,用以生成最终的SQL,而MyBatis则完全手写,每增加一个查询都需要先编写SQL并增加接口方法。
还有一种Hibernate和JPA支持的Criteria查询,用Hibernate写出来类似:
1 2 3 4 DetachedCriteria criteria = DetachedCriteria.forClass(User.class);criteria.add(Restrictions.eq("email" , email)) .add(Restrictions.eq("password" , password)); List<User> list = (List<User>) hibernateTemplate.findByCriteria(criteria);
上述Criteria查询写法复杂,但和JPA相比,还是小巫见大巫了:
1 2 3 4 5 6 7 var cb = em.getCriteriaBuilder();CriteriaQuery<User> q = cb.createQuery(User.class); Root<User> r = q.from(User.class); q.where(cb.equal(r.get("email" ), cb.parameter(String.class, "e" ))); TypedQuery<User> query = em.createQuery(q); query.setParameter("e" , email); List<User> list = query.getResultList();
此外,是否支持自动读取一对多和多对一关系也是全自动化ORM框架的一个重要功能。
如果我们自己来设计并实现一个ORM,应该吸取这些ORM的哪些特色,然后高效实现呢?
设计ORM接口
任何设计,都必须明确设计目标。这里我们准备实现的ORM并不想要全自动ORM那种自动读取一对多和多对一关系的功能,也不想给Entity加上复杂的状态,因此,对于Entity来说,它就是纯粹的JavaBean,没有任何Proxy。
此外,ORM要兼顾易用性和适用性。易用性是指能覆盖95%的应用场景,但总有一些复杂的SQL,很难用ORM去自动生成,因此,也要给出原生的JDBC接口,能支持5%的特殊需求。
最后,我们希望设计的接口要易于编写,并使用流式API便于阅读。为了配合编译器检查,还应该支持泛型,避免强制转型。
以User类为例,我们设计的查询接口如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 User u = db.get(User.class, 123 );User u = db.from(User.class) .where("email=? AND password=?" , "bob@example.com" , "bob123" ) .unique(); List<User> us = db.from(User.class) .where("id < ?" , 1000 ) .orderBy("email" ) .limit(0 , 10 ) .list(); User u = db.select("id" , "name" ) .from(User.class) .where("email = ?" , "bob@example.com" ) .unique();
这样的流式API便于阅读,也非常容易推导出最终生成的SQL。
对于插入、更新和删除操作,就相对比较简单:
1 2 3 4 5 6 7 8 db.insert(user); db.update(user); db.delete(User.class, 123 );
对于Entity来说,通常一个表对应一个。手动列出所有Entity是非常麻烦的,一定要传入package自动扫描。
最后,ORM总是需要元数据才能知道如何映射。我们不想编写复杂的XML配置,也没必要自己去定义一套规则,直接使用JPA的注解就行。
实现ORM
我们并不需要从JDBC底层开始编写,并且,还要考虑到事务,最好能直接使用Spring的声明式事务。实际上,我们可以设计一个全局DbTemplate,它注入了Spring的JdbcTemplate,涉及到数据库操作时,全部通过JdbcTemplate完成,自然天生支持Spring的声明式事务,因为这个ORM只是在JdbcTemplate的基础上做了一层封装。
在AppConfig中,我们初始化所有Bean如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @Configuration @ComponentScan @EnableTransactionManagement @PropertySource("jdbc.properties") public class AppConfig { @Bean DataSource createDataSource () { ... } @Bean JdbcTemplate createJdbcTemplate (@Autowired DataSource dataSource) { return new JdbcTemplate (dataSource); } @Bean DbTemplate createDbTemplate (@Autowired JdbcTemplate jdbcTemplate) { return new DbTemplate (jdbcTemplate, "com.itranswarp.learnjava.entity" ); } @Bean PlatformTransactionManager createTxManager (@Autowired DataSource dataSource) { return new DataSourceTransactionManager (dataSource); } }
以上就是我们所需的所有配置。
编写业务逻辑,例如UserService,写出来像这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @Component @Transactional public class UserService { @Autowired DbTemplate db; public User getUserById (long id) { return db.get(User.class, id); } public User getUserByEmail (String email) { return db.from(User.class) .where("email = ?" , email) .unique(); } public List<User> getUsers (int pageIndex) { int pageSize = 100 ; return db.from(User.class) .orderBy("id" ) .limit((pageIndex - 1 ) * pageSize, pageSize) .list(); } public User register (String email, String password, String name) { User user = new User (); user.setEmail(email); user.setPassword(password); user.setName(name); user.setCreatedAt(System.currentTimeMillis()); db.insert(user); return user; } ... }
上述代码给出了ORM的接口,以及如何在业务逻辑中使用ORM。下一步,就是如何实现这个DbTemplate。这里我们只给出框架代码,有兴趣的童鞋可以自己实现核心代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class DbTemplate { private JdbcTemplate jdbcTemplate; private Map<Class<?>, Mapper<?>> classMapping; public <T> T fetch (Class<T> clazz, Object id) { Mapper<T> mapper = getMapper(clazz); List<T> list = (List<T>) jdbcTemplate.query(mapper.selectSQL, new Object [] { id }, mapper.rowMapper); if (list.isEmpty()) { return null ; } return list.get(0 ); } public <T> T get (Class<T> clazz, Object id) { ... } public <T> void insert (T bean) { ... } public <T> void update (T bean) { ... } public <T> void delete (Class<T> clazz, Object id) { ... } }
实现链式API的核心代码是第一步从DbTemplate调用select()或from()时实例化一个CriteriaQuery实例,并在后续的链式调用中设置它的字段:
1 2 3 4 5 6 7 8 9 10 11 public class DbTemplate { ... public Select select (String... selectFields) { return new Select (new Criteria (this ), selectFields); } public <T> From<T> from (Class<T> entityClass) { Mapper<T> mapper = getMapper(entityClass); return new From <>(new Criteria <>(this ), mapper); } }
然后以此定义Select、From、Where、OrderBy、Limit等。在From中可以设置Class类型、表名等:
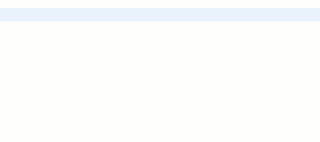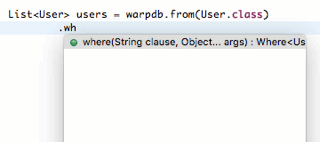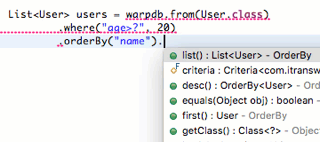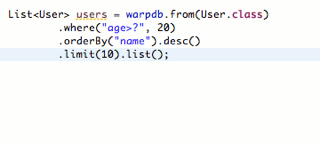
1 2 3 4 5 6 7 8 9 10 11 12 13 public final class From <T> extends CriteriaQuery <T> { From(Criteria<T> criteria, Mapper<T> mapper) { super (criteria); this .criteria.mapper = mapper; this .criteria.clazz = mapper.entityClass; this .criteria.table = mapper.tableName; } public Where<T> where (String clause, Object... args) { return new Where <>(this .criteria, clause, args); } }
在Where中可以设置条件参数:
1 2 3 4 5 6 7 8 9 10 11 public final class Where <T> extends CriteriaQuery <T> { Where(Criteria<T> criteria, String clause, Object... params) { super (criteria); this .criteria.where = clause; this .criteria.whereParams = new ArrayList <>(); for (Object param : params) { this .criteria.whereParams.add(param); } } }
最后,链式调用的尽头是调用list()返回一组结果,调用unique()返回唯一结果,调用first()返回首个结果。
在IDE中,可以非常方便地实现链式调用:
需要复杂查询的时候,总是可以使用JdbcTemplate执行任意复杂的SQL。
练习
设计并实现一个微型ORM。
下载练习
小结
ORM框架就是自动映射数据库表结构到JavaBean的工具,设计并实现一个简单高效的ORM框架并不困难。
留言與分享