
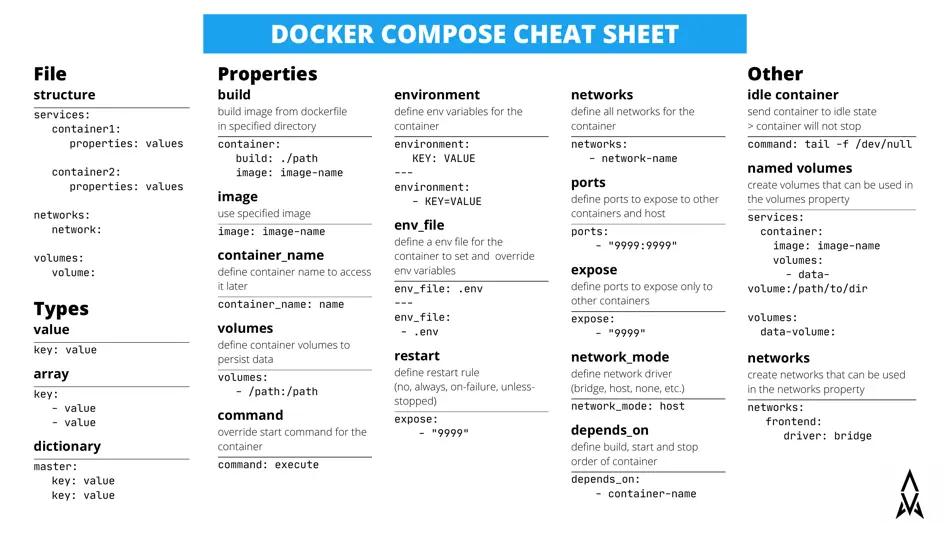
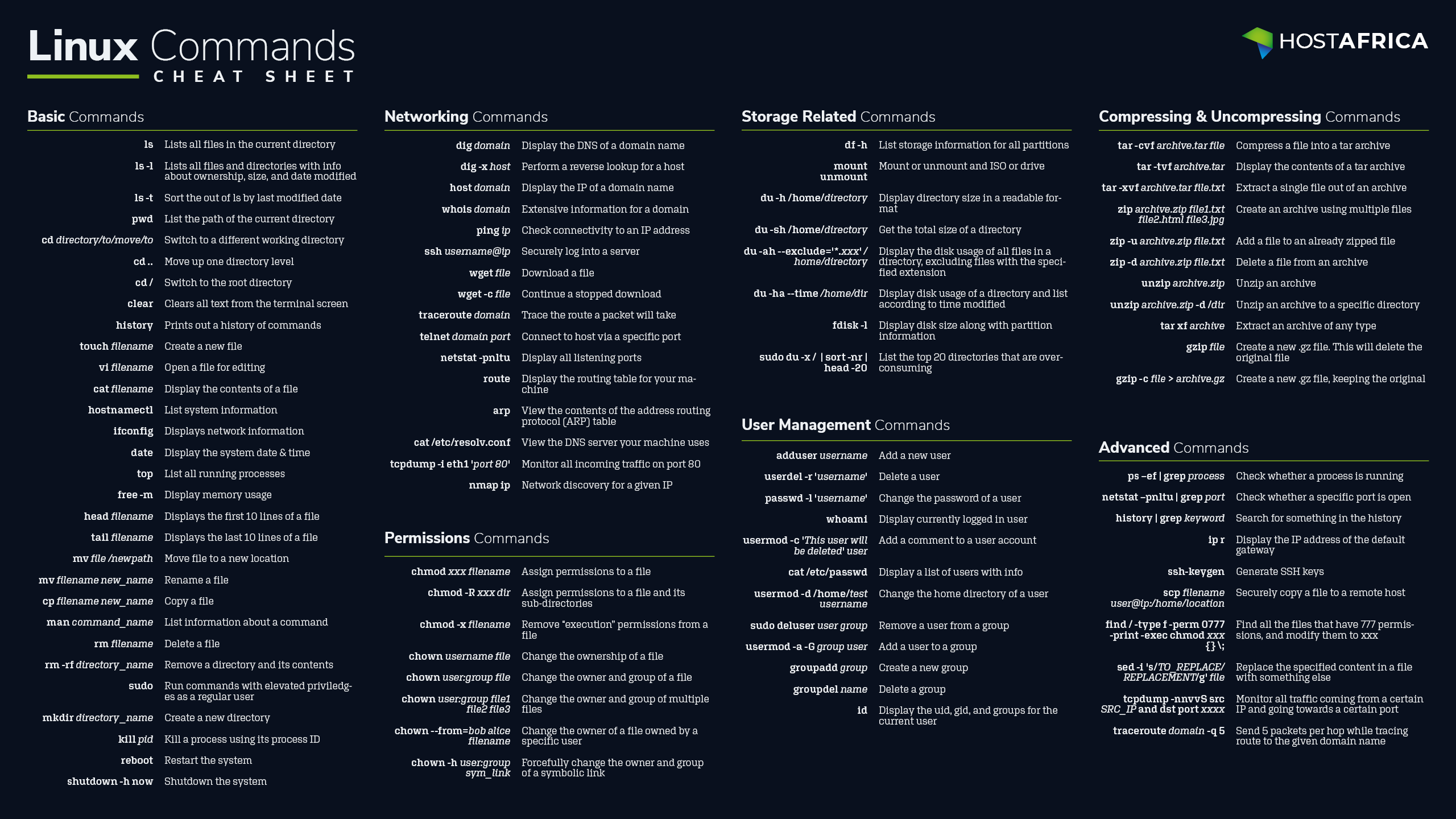
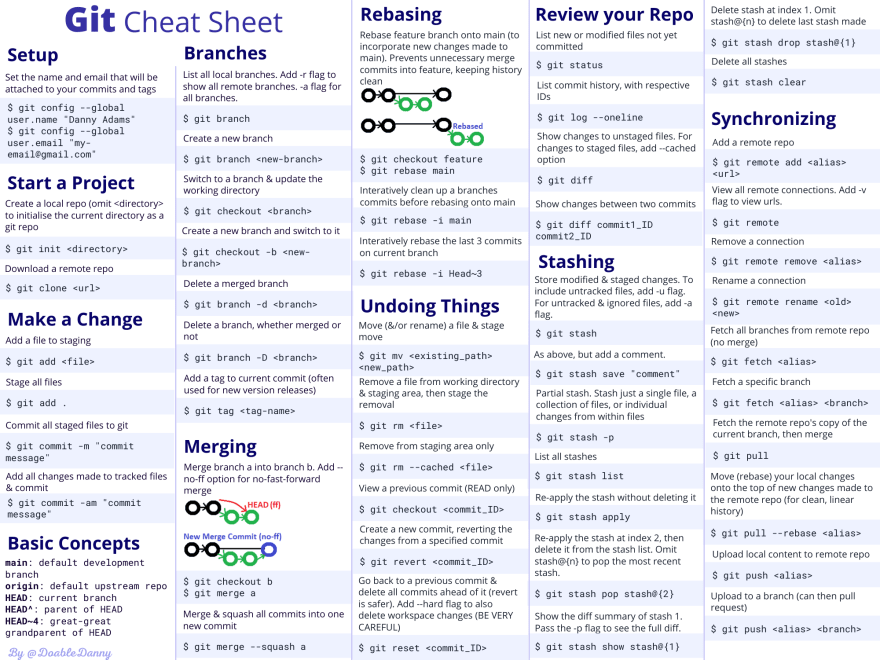
使用React我们首先要知道如何传递数据,组件如何沟通,才能展示我们想要的数据。下面的列子都是使用ES6语法,不懂的同学需要先学习ES6语法。
数据流
React是单向数据流,从父节点传递到子节点(通过props)。如果顶层的某个props改变了,React会重渲染所有的子节点(未做性能优化)。严格意义上React只提供,也强烈建议使用这种数据交流方式。
Props
props是property的缩写,可以理解为HTML标签的attribute。请把props当做只读的(不可以使用this.props直接修改props),props是用于整个组件树中传递数据和配置。在当前组件访问props,使用this.props。在什么情况下可以使用props,请看组件生命周期
1 | class Component { |
PropTypes
PropsTypes是React中用来定义props的类型,不符合定义好的类型会报错。建议可复用组件要使用prop验证!接着上面的列子设置PropsTypes如下:
1 | class Component { |
React.PropTypes 提供很多验证器 (validator) 来验证传入数据的有效性。官方定义的验证器如下,不是使用ES6语法。
1 | React.createClass({ |
defaultProps
如何设置组件默认的props?
1 | //React提供的crateClass创建方式 |
state
每个组件都有属于自己的state,state和props的区别在于前者之只存在于组件内部,只能从当前组件调用this.setState修改state值(不可以直接修改this.state)。一般我们更新子组件都是通过改变state值,更新新子组件的props值从而达到更新。
那如何设置默认state?
1 | //React提供的crateClass创建方式 |
props和state使用方式
尽可能使用props当做数据源,state用来存放状态值(简单的数据),如复选框、下拉菜单等。
组件沟通
组件沟通因为React的单向数据流方式会有所限制,下面述说组件之间的沟通方式。
父子组件沟通
这种方式是最常见的,也是最简单的。
- 父组件更新组件状态
父组件更新子组件状态,通过传递props,就可以了。
- 子组件更新父组件状态
这种情况需要父组件传递回调函数给子组件,子组件调用触发即可。
代码示例:
1 | class Child extends React.Component{ |
codepen例子React组件之父子组件沟通 。
兄弟组件沟通
当两个组件有相同的父组件时,就称为兄弟组件(堂兄也算的)。按照React单向数据流方式,我们需要借助父组件进行传递,通过父组件回调函数改变兄弟组件的props。
方式一
通过props传递父组件回调函数。
1 | class Brother1 extends React.Component{ |
codepen例子:React组件之兄弟组件沟通。
方式二
但是如果组件层次太深(如下图),上面的兄弟组件沟通方式就效率低了(不建议组件层次太深)。
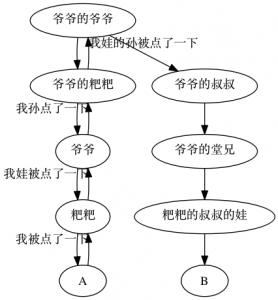
React提供了一种上下文方式(挺方便的),可以让子组件直接访问祖先的数据或函数,无需从祖先组件一层层地传递数据到子组件中。
1 | class Brother1 extends React.Component{ |
codepen例子:React组件之兄弟组件沟通2
全局事件
For communication between two components that don’t have a parent-child relationship, you can set up your own global event system. Subscribe to events in
componentDidMount(), unsubscribe incomponentWillUnmount(), and callsetState()when you receive an event.Flux pattern is one of the possible ways to arrange this.
官网中提到可以使用全局事件来进行组件间的通信,官网推荐Flux(Facebook官方出的),还有Relay、Redux、trandux等第三方类库。这些框架思想都一致,都是统一管理组件state变化情况,达到数据可控目的。本人使用了Redux,建议要会其中一种。对于EventEmitter或PostalJS这类的第三方库是不建议使用的,这类全局事件框架并没有统一管理组件数据变化,用多了会导致数据流不可控。
这里就不细说,请选择其中一种类库,深入学习下。
总结
简单的组件交流我们可以使用上面非全局事件的简单方式,但是当项目复杂,组件间层次越来越深,上面的交流方式就不太合适(当然还是要用到的,简单的交流)。强烈建议使用Flux、Relay、Redux、trandux等类库其中一种,这些类库不只适合React,像Angular等都可以使用。
此文章适合 React@17 之前的版本,React@16.3.0,添加了一些新的生命周期函数,同时准备废弃一些会造成困扰的生命周期函数。所有如果在React@17 发布之前,这篇文章还是适用的。
新的生命周期请看官网 blog 文章 React v16.3.0: New lifecycles and context API。
前言
组件会随着组件的 props 和 state 改变而发生变化,它的 DOM 也会有相应的变化。
一个组件就是一个状态机:对于特定的输入,它总会返回一致的输出。
React组件提供了生命周期的钩子函数去响应组件不同时刻的状态,组件的生命周期如下:
- 实例化
- 存在期
- 销毁期
钩子函数是我们重点关注的地方,下面来详细了解下生命周期下的钩子函数调用顺序和作用。每个生命周期阶段调用的钩子函数会略有不同。下面的图片或许对你有帮助。

可以查看 CodePen 在线 Demo React 生命周期
实例化
首次调用组件时,有以下方法会被调用(注意顺序,从上到下先后执行):
-
getDefaultProps这个方法是用来设置组件默认的
props,组件生命周期只会调用一次。但是只适合React.createClass直接创建的组件,使用 ES6/ES7 创建的这个方法不可使用, ES6/ES7 可以使用下面方式:1
2
3
4
5
6// es7
class Component {
static defaultProps = {}
}
// 或者也可以在外面定义es6
// Compnent.defaultProps -
getInitialState设置state初始值,在这个方法中你已经可以访问到
this.props。getInitialState只适合React.createClass使用。使用 ES6 初始化state方法如下:1
2
3
4
5
6
7
8class Component extends React.Component{
constructor(props){
super(props);
this.state = {
render: true,
}
}
}或者这样
1
2
3
4
5
6class Component extends React.Component{
state = {
render: true
}
render(){return false;}
} -
componentWillMount改方法会在组件首次渲染之前调用,这个是在 render 方法调用前可修改 state 的最后一次机会。这个方法很少用到。
-
render这个方法以后大家都应该会很熟悉,JSX 通过这里,解析成对应的
虚拟 DOM,渲染成最终效果。格式大致如下:1
2
3
4
5
6
7class Component extends React.Component{
render(){
return (
<div></div>
)
}
}
-
componentDidMount这个方法在首次真实的 DOM 渲染后调用(仅此一次)当我们需要访问真实的 DOM 时,这个方法就经常用到。如何访问真实的 DOM 这里就不想说了。当我们需要请求外部接口数据,一般都在这里处理。
存在期
实例化后,当props或者state发生变化时,下面方法依次被调用:
-
componentWillReceiveProps
没当我们通过父组件更新子组件 props 时(这个也是唯一途径),这个方法就会被调用。
1
componentWillReceiveProps(nextProps){}
-
shouldComponentUpdate
字面意思,是否应该更新组件,默认返回 true。当返回 false 时,后期函数就不会调用,组件不会在次渲染。
1
shouldComponentUpdate(nextProps,nextState){}
-
componentWillUpdate
字面意思组件将会更新,
props和state改变后必调用。 -
render
跟实例化时的render一样,不多说
-
componentDidUpdate
这个方法在更新真实的 DOM 成功后调用,当我们需要访问真实的 DOM 时,这个方法就也经常用到。
销毁期
销毁阶段,只有一个函数被调用:
-
componentWillUnmount
没当组件使用完成,这个组件就必须从DOM中销毁,此时该方法就会被调用。当我们在组件中使用了 setInterval,那我们就需要在这个方法中调用 clearInterval。如果手动使用了 addEventListener 绑定了事件,也需要解绑事件。
react - JSX
React 背景介绍
React 起源于 Facebook 的内部项目,因为该公司对市场上所有 JavaScript MVC 框架,都不满意,就决定自己写一套,用来架设 Instagram 的网站。做出来以后,发现这套东西很好用,就在2013年5月开源了。
什么是React
-
A JAVASCRIPT LIBRARY FOR BUILDING USER INTERFACES
- 用来构建UI的 JavaScript库
- React 不是一个 MVC 框架,仅仅是视图(V)层的库
特点
- 1 使用 JSX语法 创建组件,实现组件化开发,为函数式的 UI 编程方式打开了大门
- 2 性能高的让人称赞:通过
diff算法和虚拟DOM实现视图的高效更新 - 3 HTML仅仅是个开始
1 | > JSX --TO--> EveryThing |
为什么要用React
- 1 使用
组件化开发方式,符合现代Web开发的趋势 - 2 技术成熟,社区完善,配件齐全,适用于大型Web项目(生态系统健全)
- 3 由Facebook专门的团队维护,技术支持可靠
- 4 ReactNative - Learn once, write anywhere: Build mobile apps with React
- 5 使用方式简单,性能非常高,支持服务端渲染
- 6 React非常火,从技术角度,可以满足好奇心,提高技术水平;从职业角度,有利于求职和晋升,有利于参与潜力大的项目
React中的核心概念
- 1 虚拟DOM(Virtual DOM)
- 2 Diff算法(虚拟DOM的加速器,提升React性能的法宝)
虚拟DOM(Vitural DOM)
React将DOM抽象为虚拟DOM,虚拟DOM其实就是用一个对象来描述DOM,通过对比前后两个对象的差异,最终只把变化的部分重新渲染,提高渲染的效率
为什么用虚拟dom,当dom反生更改时需要遍历 而原生dom可遍历属性多大231个 且大部分与渲染无关 更新页面代价太大
VituralDOM的处理方式
- 1 用 JavaScript 对象结构表示 DOM 树的结构,然后用这个树构建一个真正的 DOM 树,插到文档当中
- 2 当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异
- 3 把2所记录的差异应用到步骤1所构建的真正的DOM树上,视图就更新了
Diff算法
当你使用React的时候,在某个时间点 render() 函数创建了一棵React元素树,
在下一个state或者props更新的时候,render() 函数将创建一棵新的React元素树,
React将对比这两棵树的不同之处,计算出如何高效的更新UI(只更新变化的地方)
1 | <!-- 了解: |
-
React中有两种假定:
- 1 两个不同类型的元素会产生不同的树(根元素不同结构树一定不同)
- 2 开发者可以通过key属性指定不同树中没有发生改变的子元素
Diff算法的说明 - 1
- 如果两棵树的根元素类型不同,React会销毁旧树,创建新树
1 | // 旧树 |
Diff算法的说明 - 2
- 对于类型相同的React DOM 元素,React会对比两者的属性是否相同,只更新不同的属性
- 当处理完这个DOM节点,React就会递归处理子节点。
1 | // 旧 |
Diff算法的说明 - 3
- 1 当在子节点的后面添加一个节点,这时候两棵树的转化工作执行的很好
1 | // 旧 |
- 2 但是如果你在开始位置插入一个元素,那么问题就来了:
1 | // 旧 |
key 属性
为了解决以上问题,React提供了一个 key 属性。当子节点带有key属性,React会通过key来匹配原始树和后来的树。
1 | // 旧 |
- 说明:key属性在React内部使用,但不会传递给你的组件
- 推荐:在遍历数据时,推荐在组件中使用 key 属性:
<li key={item.id}>{item.name}</li> - 注意:key只需要保持与他的兄弟节点唯一即可,不需要全局唯一
- 注意:尽可能的减少数组index作为key,数组中插入元素的等操作时,会使得效率底下
React的基本使用
- 安装:
npm i -S react react-dom react:react 是React库的入口点react-dom:提供了针对DOM的方法,比如:把创建的虚拟DOM,渲染到页面上
1 | // 1. 导入 react |
createElement()的问题
- 说明:
createElement()方式,代码编写不友好,太复杂
1 | var dv = React.createElement( |
JSX 的基本使用
- 注意:JSX语法,最终会被编译为 createElement() 方法
- 推荐:使用 JSX 的方式创建组件
- JSX - JavaScript XML
- 安装:
npm i -D babel-preset-react(依赖与:babel-core/babel-loader)
注意:JSX的语法需要通过 babel-preset-react 编译后,才能被解析执行
1 | /* 1 在 .babelrc 开启babel对 JSX 的转换 */ |
JSX的注意点
-
注意 1: 如果在 JSX 中给元素添加类, 需要使用
className代替 class- 类似:label 的 for属性,使用
htmlFor代替
- 类似:label 的 for属性,使用
-
注意 2:在 JSX 中可以直接使用 JS代码,直接在 JSX 中通过 {} 中间写 JS代码即可
-
注意 3:在 JSX 中只能使用表达式,但是不能出现 语句!!!
-
注意 4:在 JSX 中注释语法:
{/* 中间是注释的内容 */}
React组件
React 组件可以让你把UI分割为独立、可复用的片段,并将每一片段视为相互独立的部分。
- 组件是由一个个的HTML元素组成的
- 概念上来讲, 组件就像JS中的函数。它们接受用户输入(
props),并且返回一个React对象,用来描述展示在页面中的内容
React创建组件的两种方式
- 1 通过 JS函数 创建(无状态组件)
- 2 通过 class 创建(有状态组件)
1 | 函数式组件 和 class 组件的使用场景说明: |
JavaScript函数创建
- 注意:1 函数名称必须为大写字母开头,React通过这个特点来判断是不是一个组件
- 注意:2 函数必须有返回值,返回值可以是:JSX对象或
null - 注意:3 返回的JSX,必须有一个根元素
- 注意:4 组件的返回值使用
()包裹,避免换行问题
1 | function Welcome(props) { |
class创建
在es6中class仅仅是一个语法糖,不是真正的类,本质上还是构造函数+原型 实现继承
1 | // ES6中class关键字的简单使用 |
给组件传递数据 - 父子组件传递数据
- 组件中有一个
只读的对象叫做props,无法给props添加属性 - 获取方式:函数参数
props - 作用:将传递给组件的属性转化为
props对象中的属性
1 | function Welcome(props){ |
封装组件到独立的文件中
1 | // 创建Hello2.js组件文件 |
props和state
props
-
作用:给组件传递数据,一般用在父子组件之间
-
说明:React把传递给组件的属性转化为一个对象并交给
props -
特点:
props是只读的,无法给props添加或修改属性 -
props.children:获取组件的内容,比如:<Hello>组件内容</Hello>中的组件内容
1 | // props 是一个包含数据的对象参数,不要试图修改 props 参数 |
state
状态即数据
-
作用:用来给组件提供
组件内部使用的数据 -
注意:只有通过
class创建的组件才具有状态 -
注意:状态是私有的,完全由组件来控制
-
注意:不要在
state中添加render()方法中不需要的数据,会影响渲染性能!- 可以将组件内部使用但是不渲染在视图中的内容,直接添加给 this
-
注意:不要在
render()方法中调用 setState() 方法来修改state的值- 但是可以通过
this.state.name = 'rose'方式设置state(不推荐!!!)
- 但是可以通过
1 | // 例: |
JSX语法转化过程
1 | // 1、JSX |
评论列表案例
- 巩固有状态组件和无状态组件的使用
- 两个组件:
<CommentList></CommentList>和<Comment></Comment>
1 | [ |
style样式
1 | // 1. 直接写行内样式: |
相关文章
组件的生命周期
- 简单说:一个组件从开始到最后消亡所经历的各种状态,就是一个组件的生命周期
组件生命周期函数的定义:从组件被创建,到组件挂载到页面上运行,再到页面关闭组件被卸载,这三个阶段总是伴随着组件各种各样的事件,那么这些事件,统称为组件的生命周期函数!
- 通过这个函数,能够让开发人员的代码,参与到组件的生命周期中。也就是说,通过钩子函数,就可以控制组件的行为
- React 生命周期的管理艺术
组件生命周期函数总览
- 组件的生命周期包含三个阶段:创建阶段(Mounting)、运行和交互阶段(Updating)、卸载阶段(Unmounting)
- Mounting:
constructor()
componentWillMount()
render()
componentDidMount()
- Updating
componentWillReceiveProps()
shouldComponentUpdate()
componentWillUpdate()
render()
componentDidUpdate()
- Unmounting
componentWillUnmount()
组件生命周期 - 创建阶段(Mounting)
- 特点:该阶段的函数只执行一次
constructor()
- 作用:1 获取props 2 初始化state
- 说明:通过
constructor()的参数props获取
1 | class Greeting extends React.Component { |
componentWillMount()
- 说明:组件被挂载到页面之前调用,其在render()之前被调用,因此在这方法里
同步地设置状态将不会触发重渲染 - 注意:无法获取页面中的DOM对象
- 注意:可以调用
setState()方法来改变状态值 - 用途:发送ajax请求获取数据
1 | componentWillMount() { |
render()
-
作用:渲染组件到页面中,无法获取页面中的DOM对象
-
注意:不要在render方法中调用
setState()方法,否则会递归渲染- 原因说明:状态改变会重新调用
render(),render()又重新改变状态
- 原因说明:状态改变会重新调用
1 | render() { |
componentDidMount()
- 1 组件已经挂载到页面中
- 2 可以进行DOM操作,比如:获取到组件内部的DOM对象
- 3 可以发送请求获取数据
- 4 可以通过
setState()修改状态的值 - 注意:在这里修改状态会重新渲染
1 | componentDidMount() { |
组件生命周期 - 运行阶段(Updating)
- 特点:该阶段的函数执行多次
- 说明:每当组件的
props或者state改变的时候,都会触发运行阶段的函数
componentWillReceiveProps()
- 说明:组件接受到新的
props前触发这个方法 - 参数:当前组件
props值 - 可以通过
this.props获取到上一次的值 - 使用:若你需要响应属性的改变,可以通过对比
this.props和nextProps并在该方法中使用this.setState()处理状态改变 - 注意:修改
state不会触发该方法
1 | componentWillReceiveProps(nextProps) { |
shouldComponentUpdate()
- 作用:根据这个方法的返回值决定是否重新渲染组件,返回
true重新渲染,否则不渲染 - 优势:通过某个条件渲染组件,降低组件渲染频率,提升组件性能
- 说明:如果返回值为
false,那么,后续render()方法不会被调用 - 注意:这个方法必须返回布尔值!!!
- 场景:根据随机数决定是否渲染组件
1 | // - 参数: |
componentWillUpdate()
- 作用:组件将要更新
- 参数:最新的属性和状态对象
- 注意:不能修改状态 否则会循环渲染
1 | componentWillUpdate(nextProps, nextState) { |
render() 渲染
- 作用:重新渲染组件,与
Mounting阶段的render是同一个函数 - 注意:这个函数能够执行多次,只要组件的属性或状态改变了,这个方法就会重新执行
componentDidUpdate()
- 作用:组件已经被更新
- 参数:旧的属性和状态对象
1 | componentDidUpdate(prevProps, prevState) { |
组件生命周期 - 卸载阶段(Unmounting)
- 组件销毁阶段:组件卸载期间,函数比较单一,只有一个函数,这个函数也有一个显著的特点:组件一辈子只能执行依次!
- 使用说明:只要组件不再被渲染到页面中,那么这个方法就会被调用( 渲染到页面中 -> 不再渲染到页面中 )
componentWillUnmount()
-
作用:在卸载组件的时候,执行清理工作,比如
- 1 清除定时器
- 2 清除
componentDidMount创建的DOM对象
React - createClass(不推荐)
React.createClass({})方式,创建有状态组件,该方式已经被废弃!!!- 通过导入
require('create-react-class'),可以在不适用ES6的情况下,创建有状态组件 - getDefaultProps() 和 getInitialState() 方法:是
createReactClass()方式创建组件中的两个函数 - React without ES6
1 | var createReactClass = require('create-react-class'); |
state和setState
- 注意:使用
setState()方法修改状态,状态改变后,React会重新渲染组件 - 注意:不要直接修改state属性的值,这样不会重新渲染组件!!!
- 使用:1 初始化state 2 setState修改state
1 | // 修改state(不推荐使用) |
1 | constructor(props) { |
组件绑定事件
-
1 通过React事件机制
onClick绑定 -
2 JS原生方式绑定(通过
ref获取元素)- 注意:
ref是React提供的一个特殊属性 ref的使用说明
- 注意:
React中的事件机制 - 推荐
- 注意:事件名称采用驼峰命名法
- 例如:
onClick用来绑定单击事件
1 | <input type="button" value="触发单击事件" |
JS原生方式 - 知道即可
- 说明:给元素添加
ref属性,然后,获取元素绑定事件
1 | // JSX |
事件绑定中的this
- 1 通过
bind绑定 - 2 通过
箭头函数绑定
通过bind绑定
- 原理:
bind能够调用函数,改变函数内部this的指向,并返回一个新函数 - 说明:
bind第一个参数为返回函数中this的指向,后面的参数为传给返回函数的参数
1 | // 自定义方法: |
- 在构造函数中使用
bind
1 | constructor() { |
通过箭头函数绑定
- 原理:
箭头函数中的this由所处的环境决定,自身不绑定this
1 | <input type="button" value="在构造函数中绑定this并传参" onClick={ |
受控组件
- 表单和受控组件
- 非受控组件
在HTML当中,像
input,textarea和select这类表单元素会维持自身状态,并根据用户输入进行更新。
在React中,可变的状态通常保存在组件的state中,并且只能用setState()方法进行更新.
React根据初始状态渲染表单组件,接受用户后续输入,改变表单组件内部的状态。
因此,将那些值由React控制的表单元素称为:受控组件。
-
受控组件的特点:
- 1 表单元素
- 2 由React通过JSX渲染出来
- 3 由React控制值的改变,也就是说想要改变元素的值,只能通过React提供的方法来修改
-
注意:只能通过setState来设置受控组件的值
1 | // 模拟实现文本框数据的双向绑定 |
评论列表案例
1 | [ |
props校验
- 作用:通过类型检查,提高程序的稳定性
- 命令:
npm i -S prop-types - 使用:给类提供一个静态属性
propTypes(对象),来约束props
1 | // 引入模块 |
React 单向数据流
- React 中采用单项数据流
- 数据流动方向:自上而下,也就是只能由父组件传递到子组件
- 数据都是由父组件提供的,子组件想要使用数据,都是从父组件中获取的
- 如果多个组件都要使用某个数据,最好将这部分共享的状态提升至他们最近的父组件当中进行管理
- 单向数据流
- 状态提升
1 | react中的单向数据流动: |
组件通讯
- 父 -> 子:
props - 子 -> 父:父组件通过props传递回调函数给子组件,子组件调用函数将数据作为参数传递给父组件
- 兄弟组件:因为React是单向数据流,因此需要借助父组件进行传递,通过父组件回调函数改变兄弟组件的props
- React中的状态管理: flux(提出状态管理的思想) -> Redux -> mobx
- Vue中的状态管理: Vuex
- 简单来说,就是统一管理了项目中所有的数据,让数据变的可控
- 组件通讯
Context特性
-
注意:如果不熟悉React中的数据流,不推荐使用这个属性
- 这是一个实验性的API,在未来的React版本中可能会被更改
-
作用:跨级传递数据(爷爷给孙子传递数据),避免向下每层手动地传递
props -
说明:需要配合
PropTypes类型限制来使用
1 | class Grandfather extends React.Component { |
react-router
- react router 官网
- react router github
- 安装:
npm i -S react-router-dom
基本概念说明
Router组件本身只是一个容器,真正的路由要通过Route组件定义
使用步骤
-
1 导入路由组件
-
2 使用
<Router></Router>作为根容器,包裹整个应用(JSX)- 在整个应用程序中,只需要使用一次
-
3 使用
<Link to="/movie"></Link>作为链接地址,并指定to属性 -
4 使用
<Route path="/" compoent={Movie}></Route>展示路由内容
1 | // 1 导入组件 |
注意点
<Router></Router>:作为整个组件的根元素,是路由容器,只能有一个唯一的子元素<Link></Link>:类似于vue中的<router-link></router-link>标签,to属性指定路由地址<Route></Route>:类似于vue中的<router-view></router-view>,指定路由内容(组件)展示位置
路由参数
- 配置:通过
Route中的path属性来配置路由参数 - 获取:
this.props.match.params获取
1 | // 配置路由参数 |
路由跳转
- react router - history
history.push()方法用于在JS中实现页面跳转history.go(-1)用来实现页面的前进(1)和后退(-1)
1 | this.props.history.push('/movie/movieDetail/' + movieId) |
fetch
- 作用:Fetch 是一个现代的概念, 等同于 XMLHttpRequest。它提供了许多与XMLHttpRequest相同的功能,但被设计成更具可扩展性和高效性。
fetch()方法返回一个Promise对象
fetch 基本使用
1 | /* |
跨域获取数据的三种常用方式
- 1 JSONP
- 2 代理
- 3 CORS
JSONP
- 安装:
npm i -S fetch-jsonp - 利用
JSONP实现跨域获取数据,只能获取GET请求 fetch-jsonp- fetch-jsonp
- 限制:1 只能发送GET请求 2 需要服务端支持JSONP请求
1 | /* movielist.js */ |
代理
webpack-dev-server代理配置如下:- 问题:webpack-dev-server 是开发期间使用的工具,项目上线了就不再使用 webpack-dev-server
- 解决:项目上线后的代码,也是会部署到一个服务器中,这个服务器配置了代理功能即可(要求两个服务器中配置的代理规则相同)
1 | // webpack-dev-server的配置 |
CORS - 服务器端配合
- 示例:NodeJS设置跨域
- 跨域资源共享 CORS 详解 - 阮一峰
1 | // 通过Express的中间件来处理所有请求 |
redux
- 状态管理工具,用来管理应用中的数据
核心
-
Action:行为的抽象,视图中的每个用户交互都是一个action
- 比如:点击按钮
-
Reducer:行为响应的抽象,也就是:根据action行为,执行相应的逻辑操作,更新state
- 比如:点击按钮后,添加任务,那么,添加任务这个逻辑放到 Reducer 中
- 1 创建State
-
Store:
- 1 Redux应用只能有一个store
- 2
getState():获取state - 3
dispatch(action):更新state
1 | /* action */ |
1 | /* reducer */ |