# syntax = docker/dockerfile:experimental FROM node:alpine as builder
WORKDIR /app
COPY package.json /app/
RUN --mount=type=cache,target=/app/node_modules,id=my_app_npm_module,sharing=locked \ --mount=type=cache,target=/root/.npm,id=npm_cache \ npm i --registry=https://registry.npm.taobao.org
COPY src /app/src
RUN --mount=type=cache,target=/app/node_modules,id=my_app_npm_module,sharing=locked \ # --mount=type=cache,target=/app/dist,id=my_app_dist,sharing=locked \ npm run build
FROM nginx:alpine
# COPY --from=builder /app/dist /app/dist
# 为了更直观的说明 from 和 source 指令,这里使用 RUN 指令 RUN --mount=type=cache,target=/tmp/dist,from=builder,source=/app/dist \ # --mount=type=cache,target/tmp/dist,from=my_app_dist,sharing=locked \ mkdir -p /app/dist && cp -r /tmp/dist/* /app/dist
由于 BuildKit 为实验特性,每个 Dockerfile 文件开头都必须加上如下指令
1
# syntax = docker/dockerfile:experimental
第一个 RUN 指令执行后,id 为 my_app_npm_module 的缓存文件夹挂载到了 /app/node_modules 文件夹中。多次执行也不会产生多个中间层镜像。
第二个 RUN 指令执行时需要用到 node_modules 文件夹,node_modules 已经挂载,命令也可以正确执行。
第三个 RUN 指令将上一阶段产生的文件复制到指定位置,from 指明缓存的来源,这里 builder 表示缓存来源于构建的第一阶段,source 指明缓存来源的文件夹。
随着 Linux 系统对于命名空间功能的完善实现,程序员已经可以实现上面的所有需求,让某些进程在彼此隔离的命名空间中运行。大家虽然都共用一个内核和某些运行时环境(例如一些系统命令和系统库),但是彼此却看不到,都以为系统中只有自己的存在。这种机制就是容器(Container),利用命名空间来做权限的隔离控制,利用 cgroups 来做资源分配。
联合文件系统(UnionFS (opens new window))是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)。
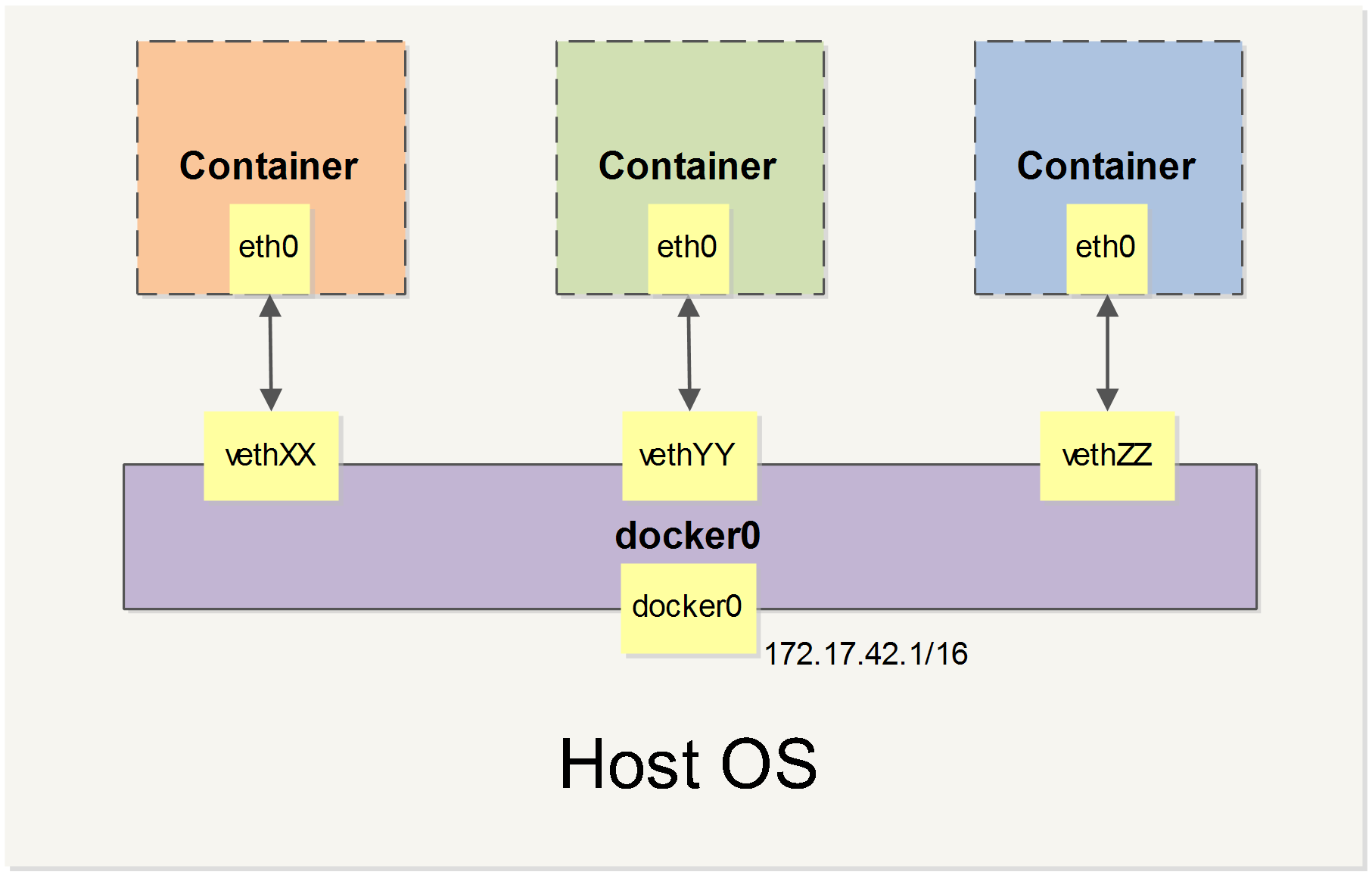
Docker 中的网络接口默认都是虚拟的接口。虚拟接口的优势之一是转发效率较高。 Linux 通过在内核中进行数据复制来实现虚拟接口之间的数据转发,发送接口的发送缓存中的数据包被直接复制到接收接口的接收缓存中。对于本地系统和容器内系统看来就像是一个正常的以太网卡,只是它不需要真正同外部网络设备通信,速度要快很多。
$ ip addr show docker0 21: docker0: ... inet 172.17.42.1/16 scope global docker0 ...
创建一对 “veth pair” 接口 A 和 B,绑定 A 到网桥 docker0,并启用它
1 2 3
$ sudo ip link add A type veth peer name B $ sudo brctl addif docker0 A $ sudo ip linkset A up
将B放到容器的网络命名空间,命名为 eth0,启动它并配置一个可用 IP(桥接网段)和默认网关。
1 2 3 4 5
$ sudo ip linkset B netns $pid $ sudo ip netns exec$pid ip linkset dev B name eth0 $ sudo ip netns exec$pid ip linkset eth0 up $ sudo ip netns exec$pid ip addr add 172.17.42.99/16 dev eth0 $ sudo ip netns exec$pid ip route add default via 172.17.42.1
$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS 03g1y59jwfg7cf99w4lt0f662 worker2 Ready Active 9j68exjopxe7wfl6yuxml7a7j worker1 Ready Active dxn1zf6l61qsb1josjja83ngz * manager Ready Active Leader
$ docker service ls ID NAME MODE REPLICAS IMAGE PORTS kc57xffvhul5 nginx replicated 3/3 nginx:1.13.7-alpine *:80->80/tcp
使用 docker service ps 来查看某个服务的详情。
1 2 3 4 5
$ docker service ps nginx ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS pjfzd39buzlt nginx.1 nginx:1.13.7-alpine swarm2 Running Running about a minute ago hy9eeivdxlaa nginx.2 nginx:1.13.7-alpine swarm1 Running Running about a minute ago 36wmpiv7gmfo nginx.3 nginx:1.13.7-alpine swarm3 Running Running about a minute ago
使用 docker service logs 来查看某个服务的日志。
1 2 3 4 5 6 7
$ docker service logs nginx nginx.3.36wmpiv7gmfo@swarm3 | 10.255.0.4 - - [25/Nov/2017:02:10:30 +0000] "GET / HTTP/1.1" 200 612 "-""Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:58.0) Gecko/20100101 Firefox/58.0""-" nginx.3.36wmpiv7gmfo@swarm3 | 10.255.0.4 - - [25/Nov/2017:02:10:30 +0000] "GET /favicon.ico HTTP/1.1" 404 169 "-""Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:58.0) Gecko/20100101 Firefox/58.0""-" nginx.3.36wmpiv7gmfo@swarm3 | 2017/11/25 02:10:30 [error] 5#5: *1 open() "/usr/share/nginx/html/favicon.ico" failed (2: No such file or directory), client: 10.255.0.4, server: localhost, request: "GET /favicon.ico HTTP/1.1", host: "192.168.99.102" nginx.1.pjfzd39buzlt@swarm2 | 10.255.0.2 - - [25/Nov/2017:02:10:26 +0000] "GET / HTTP/1.1" 200 612 "-""Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:58.0) Gecko/20100101 Firefox/58.0""-" nginx.1.pjfzd39buzlt@swarm2 | 10.255.0.2 - - [25/Nov/2017:02:10:27 +0000] "GET /favicon.ico HTTP/1.1" 404 169 "-""Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:58.0) Gecko/20100101 Firefox/58.0""-" nginx.1.pjfzd39buzlt@swarm2 | 2017/11/25 02:10:27 [error] 5#5: *1 open() "/usr/share/nginx/html/favicon.ico" failed (2: No such file or directory), client: 10.255.0.2, server: localhost, request: "GET /favicon.ico HTTP/1.1", host: "192.168.99.101"
$ docker stack down wordpress Removing service wordpress_db Removing service wordpress_visualizer Removing service wordpress_wordpress Removing network wordpress_overlay Removing network wordpress_default
ID NAME CREATED UPDATED l1vinzevzhj4goakjap5ya409 mysql_password 41 seconds ago 41 seconds ago yvsczlx9votfw3l0nz5rlidig mysql_root_password 12 seconds ago 12 seconds ago
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS rt677gop9d4x nginx.1 nginx:1.13.7-alpine VM-20-83-debian Running Running about a minute ago d9pw13v59d00 \_ nginx.1 nginx:1.13.12-alpine VM-20-83-debian Shutdown Shutdown 2 minutes ago i7ynkbg6ybq5 \_ nginx.1 nginx:1.13.7-alpine VM-20-83-debian Shutdown Shutdown 2 minutes ago
$ sudo systemctl stop docker $ sudo ip linkset dev docker0 down $ sudo brctl delbr docker0
然后创建一个网桥 bridge0。
1 2 3
$ sudo brctl addbr bridge0 $ sudo ip addr add 192.168.5.1/24 dev bridge0 $ sudo ip linkset dev bridge0 up
查看确认网桥创建并启动。
1 2 3 4 5
$ ip addr show bridge0 4: bridge0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state UP group default link/ether 66:38:d0:0d:76:18 brd ff:ff:ff:ff:ff:ff inet 192.168.5.1/24 scope global bridge0 valid_lft forever preferred_lft forever
$ sudo ip linkset A netns 2989 $ sudo ip netns exec 2989 ip addr add 10.1.1.1/32 dev A $ sudo ip netns exec 2989 ip linkset A up $ sudo ip netns exec 2989 ip route add 10.1.1.2/32 dev A
$ sudo ip linkset B netns 3004 $ sudo ip netns exec 3004 ip addr add 10.1.1.2/32 dev B $ sudo ip netns exec 3004 ip linkset B up $ sudo ip netns exec 3004 ip route add 10.1.1.1/32 dev B
$ docker container ls -l CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fae320d08268 nginx:alpine "/docker-entrypoint.…" 24 seconds ago Up 20 seconds 0.0.0.0:32768->80/tcp bold_mcnulty
$ docker run -it --rm --name busybox1 --network my-net busybox sh
打开新的终端,再运行一个容器并加入到 my-net 网络
1
$ docker run -it --rm --name busybox2 --network my-net busybox sh
再打开一个新的终端查看容器信息
1 2 3 4 5
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES b47060aca56b busybox "sh" 11 minutes ago Up 11 minutes busybox2 8720575823ec busybox "sh" 16 minutes ago Up 16 minutes busybox1
下面通过 ping 来证明 busybox1 容器和 busybox2 容器建立了互联关系。
在 busybox1 容器输入以下命令
1 2 3 4
/ # ping busybox2 PING busybox2 (172.19.0.3): 56 data bytes 64 bytes from 172.19.0.3: seq=0 ttl=64 time=0.072 ms 64 bytes from 172.19.0.3: seq=1 ttl=64 time=0.118 ms
用 ping 来测试连接 busybox2 容器,它会解析成 172.19.0.3。
同理在 busybox2 容器执行 ping busybox1,也会成功连接到。
1 2 3 4
/ # ping busybox1 PING busybox1 (172.19.0.2): 56 data bytes 64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.064 ms 64 bytes from 172.19.0.2: seq=1 ttl=64 time=0.143 ms
如何自定义配置容器的主机名和 DNS 呢?秘诀就是 Docker 利用虚拟文件来挂载容器的 3 个相关配置文件。
在容器中使用 mount 命令可以看到挂载信息:
1 2 3 4
$ mount /dev/disk/by-uuid/1fec...ebdf on /etc/hostname type ext4 ... /dev/disk/by-uuid/1fec...ebdf on /etc/hosts type ext4 ... tmpfs on /etc/resolv.conf type tmpfs ...
这种机制可以让宿主主机 DNS 信息发生更新后,所有 Docker 容器的 DNS 配置通过 /etc/resolv.conf 文件立刻得到更新。
配置全部容器的 DNS ,也可以在 /etc/docker/daemon.json 文件中增加以下内容来设置。
1 2 3 4 5 6
{ "dns":[ "114.114.114.114", "8.8.8.8" ] }
这样每次启动的容器 DNS 自动配置为 114.114.114.114 和 8.8.8.8。使用以下命令来证明其已经生效。
1 2 3 4
$ docker run -it --rm ubuntu:18.04 cat etc/resolv.conf
创建好私有仓库之后,就可以使用 docker tag 来标记一个镜像,然后推送它到仓库。例如私有仓库地址为 127.0.0.1:5000。
先在本机查看已有的镜像。
1 2 3
$ docker image ls REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE ubuntu latest ba5877dc9bec 6 weeks ago 192.7 MB
使用 docker tag 将 ubuntu:latest 这个镜像标记为 127.0.0.1:5000/ubuntu:latest。
格式为 docker tag IMAGE[:TAG] [REGISTRY_HOST[:REGISTRY_PORT]/]REPOSITORY[:TAG]。
1 2 3 4 5
$ docker tag ubuntu:latest 127.0.0.1:5000/ubuntu:latest $ docker image ls REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE ubuntu latest ba5877dc9bec 6 weeks ago 192.7 MB 127.0.0.1:5000/ubuntu:latest latest ba5877dc9bec 6 weeks ago 192.7 MB
使用 -d 参数启动后会返回一个唯一的 id,也可以通过 docker container ls 命令来查看容器信息。
1 2 3
$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 77b2dc01fe0f ubuntu:18.04 /bin/sh -c 'while tr 2 minutes ago Up 1 minute agitated_wright
要获取容器的输出信息,可以通过 docker container logs 命令。
1 2 3 4 5
$ docker container logs [container ID or NAMES] hello world hello world hello world . . .
$ docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES ba267838cc1b ubuntu:18.04 "/bin/bash" 30 minutes ago Exited (0) About a minute ago trusting_newton
$ docker run -dit ubuntu 243c32535da7d142fb0e6df616a3c3ada0b8ab417937c853a9e1c251f499f550
$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 243c32535da7 ubuntu:latest "/bin/bash" 18 seconds ago Up 17 seconds nostalgic_hypatia
只用 -i 参数时,由于没有分配伪终端,界面没有我们熟悉的 Linux 命令提示符,但命令执行结果仍然可以返回。
当 -i-t 参数一起使用时,则可以看到我们熟悉的 Linux 命令提示符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
$ docker run -dit ubuntu 69d137adef7a8a689cbcb059e94da5489d3cddd240ff675c640c8d96e84fe1f6
$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 69d137adef7a ubuntu:latest "/bin/bash" 18 seconds ago Up 17 seconds zealous_swirles
$ docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7691a814370e ubuntu:18.04 "/bin/bash" 36 hours ago Exited (0) 21 hours ago test $ docker export 7691a814370e > ubuntu.tar
$ cat ubuntu.tar | docker import - test/ubuntu:v1.0 $ docker image ls REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE test/ubuntu v1.0 9d37a6082e97 About a minute ago 171.3 MB
$ docker run myip -i docker: Error response from daemon: invalid header field value "oci runtime error: container_linux.go:247: starting container process caused \"exec: \\\"-i\\\": executable file not found in $PATH\"\n".
$ docker run myip -i HTTP/1.1 200 OK Server: nginx/1.8.0 Date: Tue, 22 Nov 2016 05:12:40 GMT Content-Type: text/html; charset=UTF-8 Vary: Accept-Encoding X-Powered-By: PHP/5.6.24-1~dotdeb+7.1 X-Cache: MISS from cache-2 X-Cache-Lookup: MISS from cache-2:80 X-Cache: MISS from proxy-2_6 Transfer-Encoding: chunked Via: 1.1 cache-2:80, 1.1 proxy-2_6:8006 Connection: keep-alive
#!/bin/sh ... # allow the container to be started with `--user` if [ "$1" = 'redis-server' -a "$(id -u)" = '0' ]; then find . \! -user redis -execchown redis '{}' + exec gosu redis "$0""$@" fi
之前说过每一个 RUN 都是启动一个容器、执行命令、然后提交存储层文件变更。第一层 RUN cd /app 的执行仅仅是当前进程的工作目录变更,一个内存上的变化而已,其结果不会造成任何文件变更。而到第二层的时候,启动的是一个全新的容器,跟第一层的容器更完全没关系,自然不可能继承前一层构建过程中的内存变化。
当运行该镜像后,可以通过 docker container ls 看到最初的状态为 (health: starting):
1 2 3
$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 03e28eb00bd0 myweb:v1 "nginx -g 'daemon off" 3 seconds ago Up 2 seconds (health: starting) 80/tcp, 443/tcp web
$ docker container ls CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 03e28eb00bd0 myweb:v1 "nginx -g 'daemon off" 18 seconds ago Up 16 seconds (healthy) 80/tcp, 443/tcp web
$ docker inspect --format '{{json .State.Health}}' web | python -m json.tool { "FailingStreak": 0, "Log": [ { "End": "2016-11-25T14:35:37.940957051Z", "ExitCode": 0, "Output": "<!DOCTYPE html>\n<html>\n<head>\n<title>Welcome to nginx!</title>\n<style>\n body {\n width: 35em;\n margin: 0 auto;\n font-family: Tahoma, Verdana, Arial, sans-serif;\n }\n</style>\n</head>\n<body>\n<h1>Welcome to nginx!</h1>\n<p>If you see this page, the nginx web server is successfully installed and\nworking. Further configuration is required.</p>\n\n<p>For online documentation and support please refer to\n<a href=\"http://nginx.org/\">nginx.org</a>.<br/>\nCommercial support is available at\n<a href=\"http://nginx.com/\">nginx.com</a>.</p>\n\n<p><em>Thank you for using nginx.</em></p>\n</body>\n</html>\n", "Start": "2016-11-25T14:35:37.780192565Z" } ], "Status": "healthy" }
RUN go get -d -v github.com/go-sql-driver/mysql \ && CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app . \ && cp /go/src/github.com/go/helloworld/app /root
REPOSITORY TAG IMAGE ID CREATED SIZE go/helloworld 3 d6911ed9c846 7 seconds ago 6.47MB go/helloworld 2 f7cf3465432c 22 seconds ago 6.47MB go/helloworld 1 f55d3e16affc 2 minutes ago 295MB