
1.9.1.1. 有条件创建
Terraform被设计成声明式而非命令式,例如没有常见的 if 条件语句,后来才加上了 count 和 for_each 实现的循环语句(但循环的次数必须是在 plan 阶段就能够确认的,无法根据其他 resource 的输出动态决定)
有时候我们需要根据某种条件来判断是否创建一个资源。虽然我们无法使用if来完成条件判断,但我们还有 count 和 for_each 可以帮助我们完成这个目标。
我们以 UCloud 为例,假如我们正在编写一个旨在被复用的模块,模块的逻辑要创建一台虚拟机,我们的代码可以是这样的:
1 | data ucloud_vpcs "default" { |
非常简单。但是如果我们想进一步,让模块的调用者决定创建的主机是否要搭配一个弹性公网 IP 该怎么办?
我们可以在上面的代码后面接上这样的代码:
1 | variable "allocate_public_ip" { |
我们首先创建了名为 allocate_public_ip 的输入变量,然后在编写弹性 IP 相关资源代码的时候都声明了 count 参数,值使用了条件表达式,根据 allocate_public_ip 这个输入变量的值决定是 1 还是 0。这实际上实现了按条件创建资源。
需要注意的是,由于我们使用了 count,所以现在弹性 IP 相关的资源实际上是多实例资源类型的。我们在 ucloud_eip_association.public_ip_binding 中引用 ucloud_eip.public 时,还是要加上访问下标。由于 ucloud_eip_association.public_ip_binding 与 ucloud_eip.public 实际上是同生同死,所以在这里他们之间的引用还比较简单;如果是其他没有声明 count 的资源引用它们的话,还要针对 allocate_public_ip 为 false 时 ucloud_eip.public 实际为空做相应处理,比如在 output 中:
1 | output "public_ip" { |
使用 join 函数就可以在即使没有创建弹性 IP 时也能返回空字符串。或者我们也可以用条件表达式:
1 | output "public_ip" { |
1.9.2.1. 依赖反转
Terraform 编排的基础设施对象彼此之间可能互相存在依赖关系,有时我们在编写一些旨在重用的模块时,模块内定义的资源可能本身需要依赖其他一些资源,这些资源可能已经存在,也可能有待创建。
举一个例子,假设我们编写了一个模块,定义了在 UCloud 上同一个 VPC 中的两台服务器;第一台服务器部署了一个 Web 应用,它被分配在一个 DMZ 子网里;第二台服务器部署了一个数据库,它被分配在一个内网子网里。现在的问题是,在我们编写模块时,我们并没有关于 VPC 和子网的任何信息,我们甚至连服务器应该部署在哪个可用区都不知道。VPC 和子网可能已经存在,也可以有待创建。
我们可以定义这样的一个模块代码:
1 | terraform { |
在代码中我们把依赖的网络参数定义为一个复杂类型,一个强类型对象结构。这样的话模块代码就不用再关注网络层究竟是查询而来的还是创建的,模块中只定义了抽象的网络层定义,其具体实现由调用者从外部注入,从而实现了依赖反转。
如果调用者需要创建网络层,那么代码可以是这样的(假设我们把前面编写的模块保存在 ./machine 目录下而成为一个内嵌模块):
1 | resource "ucloud_vpc" "vpc" { |
或者我们想使用现存的网络来托管服务器:
1 | data "ucloud_vpcs" "vpc" { |
由于模块代码中对网络层的定义是抽象的,并没有指定必须是 resource 或是 data,所以使得模块的调用者可以自己决定如何构造模块的依赖层,作为参数注入模块。
1.9.3.1. 多可用区分布
这是一个相当常见的小技巧。多数公有云为了高可用性,都在单一区域内提供了多可用区的设计。一个可区是一个逻辑上的数据中心,单个可用区可能由于各种自然灾害、网络故障而导致不可用,所以公有云应用部署高可用应用应时刻考虑跨可用区设计。
假如我们想要创建 N 台不同的云主机实例,在 Terraform 0.12 之前的版本中,我们只能用 count 配合模运算来达成这个目的
1 | variable "az" { |
简单来说就是使用 count 创建多实例资源时,用 var.az[count.index % length(var.az)] 可以循环使用每个可用区,使得机器尽可能均匀分布在各个可用区。
1 | $ terraform apply -auto-approve |
我们可以看一下创建的主机信息:
1 | $ terraform show |
可以看到,主机的确是均匀地分散在两个可用区了。
但是这样做在调整可用区时会发生大问题,例如:
1 | variable "az" { |
我们禁用了 cn-bj2-04 可用区,按道理我们期待的变更计划应该是将两台原本属于 cn-bj2-04 的主机删除,在 cn-bj2-03 可用区新增两台主机。让我们看看会发生什么:
1 | $ terraform plan |
变更计划与期望略有不同。我们仔细看细节:
1 | # ucloud_instance.web[2] will be updated in-place |
原本名为 cn-bj2-03-1 的主机被更名为 cn-bj2-03-2 了,原本属于 cn-bj2-04 的第一台主机的变更计划是:
1 | # ucloud_instance.web[1] must be replaced |
它的名字从 cn-bj2-04-0 变成了 cn-bj2-03-1。
仔细想想,实际上这是一个比较低效的变更计划。原本属于 cn-bj2-03 的两台主机应该不做任何变更,只需要删除 cn-bj2-04 的主机,再补充两台 cn-bj2-03 的主机即可。这是因为我们使用的是 count,而 count 只看元素在列表中的序号。当我们删除一个可用区时,实际上会引起主机序号的重大变化,导致出现大量低效的变更,这就是我们在讲 count 与 for_each 时强调过的,如果创建的资源实例彼此之间几乎完全一致,那么 count 比较合适。否则,那么使用 for_each 会更加安全。
让我们尝试使用 for_each 改写这段逻辑:
1 | variable "az" { |
为了生成主机独一无二的名字,我们首先用 range 函数生成了一个序号集合,比如目标主机数是 4,那么 range(4) 的结果就是 [0, 1, 2, 3];然后我们通过取模运算使得名字前缀在可用区列表之间循环递增,最后用 floor(i/length(var.az)) 计算出当前序号对应在当前可用区是第几台。例如 4 号主机在第二个可用区就是第二台,生成的名字应该就是 cn-bj-04-1。
执行结果是:
1 | $ terraform apply -auto-approve |
如果我们去掉一个可用区:
1 | variable "az" { |
我们可以检查一下执行计划:
1 | $ terraform plan |
可以看到,原来属于 cn-bj2-03 的两台主机原封不动,删除了属于 cn-bj2-04 的两台主机,并且在 cn-bj2-03 可用区新增两台主机。
1.9.4.1. provisioner 与 user_data
我们在介绍资源时介绍了预置器 provisioner。同时不少公有云厂商的虚拟机都提供了 cloud-init 功能,可以让我们在虚拟机实例第一次启动时执行一段自定义的脚本来执行一些初始化操作。例如我们在Terraform 初步体验一章里举的例子,在 UCloud 主机第一次启动时我们通过 user_data 来调用 yum 安装并配置了 ngnix 服务。预置器与 cloud-init 都可以用于初始化虚拟机,那么我们应该用哪一种呢?
首先要指出的是,provisioner 的官方文档里明确指出,由于预置器内部的行为 Terraform 无法感知,无法将它执行的变更纳入到声明式的代码管理中,所以预置器应被作为最后的手段使用,那么也就是说,如果 cloud-init 能够满足我们的要求,那么我们应该优先使用 cloud-init。
但是仍然存在一些 cloud-init 无法满足的场景。例如一个最常见的情况是,比如我们要在 cloud-init 当中格式化卷,后续的所有操作都必须在主机成功格式化并挂载卷之后才能顺利进行下去。但是比如 aws_instance,它的创建是不会等待 user_data 代码执行完成的,只要虚拟机创建成功开始启动,Terraform 就会认为资源创建完成从而继续后续的创建了。
解决这个问题目前来看还是只能依靠预置器。我们以一段 UCloud 云主机代码为例:
1 | resource "ucloud_instance" "web" { |
我们在资源声明中附加了一个 remote-exec 类型的预置器,它的 host 取值使用了 self.ip_set,self 在当前上下文中指代 provisioner 所属的 ucloud_instance.web,ip_set 是 ucloud_instance 的一个输出属性,内含云主机的内网 IP 以及绑定的弹性公网 IP 信息。我们用一个 for 表达式过滤出弹性公网 IP 地址,然后使用 ssh 连接。预置器执行的脚本代码很简单,休眠一小时。如果我们执行这段代码:
1 | $ terraform apply -auto-approve |
不出所料的话,该过程会持续一小时,也就是说,无论预置器脚本中执行的操作耗时多长,ucloud_instance 的创建都会等待它完成,或是触发超时。
在这里我们可以使用这种方法的前提是我们使用的 UCloud 云主机的资源定义允许我们定义资源时声明 network_interface 属性,直接绑定一个公网 IP。如果我们使用的云厂商 Provider 无法让我们在创建主机时绑定公网 IP,而是必须事后绑定弹性 IP 呢?又或者,初始化脚本必须在云主机成功绑定了云盘之后才能成功运行?这种情况下我们还有最后的武器,就是 null_resource。
null_resource 可能是 Terraform 体系中最“不 Terraform”的存在,它就是我们用来在 Terraform 这样一个声明式世界里干各种命令式脏活的工具。null_resouce 本身是一个空的 resource,只有一个名为 triggers 的参数以及 id 作为输出属性。
我们看下这个例子:
1 | data "ucloud_images" "centos" { |
我们假设需要远程执行的操纵是必须在云盘挂载成功以后才可以运行的,那么我们可以声明一个 null_resource,把 provisioner 声明放在那里,通过显式声明 depends_on 确保它的执行一定是在云盘挂载结束以后。
另外这个例子里我们运行的脚本非常简单,考虑一种更加复杂一些的场景,我们运行的脚本是通过文件读取的,我们希望在文件内容发生变化时能够重新在服务器上运行该脚本,这时我们可以使用 null_resource 的 triggers 参数:
1 | resource "null_resource" "web_init" { |
现在 provisioner 运行的脚本是通过 script 参数传入的脚本文件路径,而我们通过 filemd5 函数把文件内容的哈希值传入了 triggers。triggers 会在值发生改变时触发 null_resource 的重建,这样脚本发生些许变化都会导致重新执行。
官方文档上还给出了对于 triggers 的另一个妙用:
1 | resource "aws_instance" "cluster" { |
这个例子里,我们需要所有 AWS 主机的内网 IP 参与才能够成功初始化集群,可能是类似 Kafka 或是 RabbitMQ 这样的应用,我们需要把集群节点的IP写入配置文件。如何确保未来机器数量发生调整以后,机器上的配置文件始终能够获得完整的集群内网 IP 信息,这里使用 triggers 就可以轻松完成目标。
另外在绝大多数生产环境中,服务器都不允许拥有独立的公网 IP,或是禁止从服务器对外服务的公网 IP 直接连接 ssh。这时一般我们会在集群中配置一台堡垒机,通过堡垒机进行跳转连接。可以访问通过堡垒机使用SSH的官方文档获取详细信息,在此不再赘述。
destroy-provisioner中使用变量
1.9.5.1. destroy-provisioner 中使用变量
我们可以在定义一个 provisioner 块时设置 when 为 destroy,资源在销毁之前会首先执行 provisioner,可以帮助我们执行一些析构逻辑。但是如果我们在 Destroy-Provisioner 中引用了变量的话,比如这样的代码:
1 | resource "aws_volume_attachment" "attachement_myservice" { |
那么我们会看见这样的报错信息:
1 | | Error: Invalid reference from destroy provisioner |
从 0.12 开始 Terraform 会对在 Destroy-Time Provisioner 中引用除 self、count.index、each.key 以外的变量做警告,从 0.13 开始则会直接报错。
1.9.5.1.1. 解决方法
目前官方推荐的做法是把需要引用的变量值通过 triggers “捕获”一下再引用,例如:
1 | resource "null_resource" "foo" { |
通过这种方法就可以避免这个问题。
1.9.6.1. 利用 null_resource 的 triggers 触发其他资源更新
社区有人提了一个 Terraform 问题,他写了这样一段 Terraform 代码:
1 | resource "azurerm_key_vault_secret" "service_bus_connection_string" { |
意思大概是他把一段含有机密信息的连接字符串保存在 Azure KeyVault 服务中,然后创建了一个 Azure Faas 函数,通过 KeyVault 机密引用地址传递该机密。
1.9.6.1.1. 问题描述
这位老兄发现,如果他修改了机密的内容,也就是 azurerm_key_vault_secret 声明里的 value = azurerm_servicebus_topic_authorization_rule.mysb.primary_connection_string 这一段的值的时候,KeyVault 保存的机密内容的确会正确更新,但 Azure Function 读取到的还是旧的机密引用地址,也就是这段代码中得到的 KeyVault 机密引用地址没有更新:
1 | app_settings = { |
更加奇怪的是,这之后他什么都没有做,只是重新再执行一次 terraform apply,该引用地址又被正确更新了?!
1.9.6.1.2. 问题原因
因为 KeyVault Secret 被设计成是不可变的,所以更新 azurerm_key_vault_secret 的 value 会导致资源被重新创建。Terraform 官网上的相关文档中对该参数的定义如下:
value- (Required) Specifies the value of the Key Vault Secret.
在 Terraform 中 ,一个参数如果被标记为 Required,那么它不但是必填项,同时类似数据库记录的主键的概念,主键不同的记录被认定是两条不同的记录,修改记录的主键值可以看作是删除重建之。Terraform 资源的 Required 参数如果发生变化会触发重新创建资源,这就导致了修改 value 后,该 azurerm_key_vault_secret 的 id 也会发生变化。
那么为什么在 azurerm_key_vault_secret 被重新创建之后,我们会发现 azurerm_function_app 中引用的 id 没有变化呢?
Terraform 的工作流含有 Plan 和 Apply 两个主要阶段,首先会分析 Terraform 代码,调用 terraform refresh(可以用参数跳过该步骤)读取资源在云端目前的最新状态,再加上 State 文件中记录的状态,三个状态对比出一个执行计划,使得最终产生的云端状态能够符合当前代码描述的状态。
就这个场景而言,Terraform 能够意识到 azurerm_key_vault_secret 的参数发生了变化,这会导致某种程度的更新,但它无法意识到这个更新会导致 azurerm_key_vault_secret 的 id 发生变化,进而导致 azurerm_function_app 也必须进行更新,所以就发生了他第一次执行 terraform apply 后看到的情况。
当他第二次执行 terraform apply 时,Terraform 记录的 State 文件里,azurerm_key_vault_secret 的 id和azurerm_function_app 里使用的 id 已经对不上了,这时 Terraform 会再生成一个更新 azurerm_function_app 的 Plan,执行后一切恢复正常。
有没有办法让 azurerm_function_app 能在第一次生成 Plan 时就感知到这个变更?
1.9.6.1.3. 巧用 null_resource 的 triggers
HashiCorp 提供了一个非常常用的内建 Provider —— null。其中最知名的资源就是 null_resource 了,一般它都是和 provisioner 搭配出现,可以用来在某些资源创建完成后执行一些自定义脚本等等。但是它还有一个很有用的参数:
The
triggersargument allows specifying an arbitrary set of values that, when changed, will cause the resource to be replaced.
triggers 参数可以用来指向一些值,只要这些值的内容发生了变动,会导致 null_resource 资源被重新创建,从而生成一个新的 id。
1.9.6.1.4. 一个小实验
我们尝试构建一个简单的实验环境来验证一下,首先是这样一段代码:
1 | resource "azurerm_key_vault_secret" "example" { |
我们创建一个 azurerm_key_vault_secret,然后把它的 id 输出到一个文件里。随后我们复制一下该文件,比如叫 output.bak 好了。随后我们修改 azurerm_key_vault_secret 的 value 到一个新的值,执行 terraform apply 以后,我们会发现 output.txt 与 output.bak 的内容完全一样,说明 value 的更新并没有触发 local_file 的更新。
随后我们把代码改成这样:
1 | resource "azurerm_key_vault_secret" "example" { |
我们在代码中插入了一个 null_resource,并设置 triggers 的内容,盯住 azurerm_key_vault_secret.example.value。在 value 发生变化时,null_resource 的 id 也会发生变化。
然后我们在 local_file 的代码中,content 的赋值改成了这样一个三目表达式:null_resource.example.id == null_resource.example.id ? azurerm_key_vault_secret.example.id : ""。这个表达式里实际上 null_resource.example.id 是不起作用的,自己等于自己的永真条件会导致仍然使用 azurerm_key_vault_secret.example.id 作为值,但是由于掺入了 null_resource.example.id,使得 Terraform 在第一次计算 Plan 时就感知到 local_file 的内容发生了变化,从而使得我们可以一次 terraform apply 搞定。
1.9.7.1. 利用 null_resource 搭配 replace_triggered_by 更新无法从服务端读取内容的属性
曾经处理的一个提问,有人写了这样一段 Terraform 代码:
1 | resource "azurerm_container_group" "this" { |
结果每次执行 apply 操作时,都会发现 Terraform 试图重建这个容器:
1 | # module.dns_forwarder.azurerm_container_group.this must be replaced |
这个问题的原因是 API 在读取容器信息时不会返回 volume 的 secret 数据,这其实是一个还挺合理的设定,机密数据的确不应该可以直接从 API 返回,但这就导致 Terraform 每次制定变更计划时都会试图重新设置这个值(因为会理解成服务端这个值被修改成了空),而容器是不可变的,要修改容器的任何配置都会导致容器被重建。
有没有办法能够避免这种问题?经验告诉我们,可以使用 ignore_changes 让 Terraform 忽略这个属性的变更来避免重建,但如果 secret 真的变了怎么办?
我们可以这样干,第一,在 azurerm_container_group 添加这样一段 lifecycle 块:
1 | lifecycle { |
这会忽略 secret 的变化,但我们同时声明了一个 replace_triggered_by,在 null_resource.secret_trigger.id 的值发生变化时可以删除重建 azurerm_container_group 实例。
其次,我们把 secret 的内容提取到一个 local 里,这时 azurerm_container_group 的 volume 看起来大概是这样的:
1 | volume { |
local.secret 存放着使用的机密数据。这时我们再定义一个 null_resource 充当触发器:
1 | locals { |
这样在机密数据真的发生变化的时候,triggers 会触发 null_resource 的重建,导致 null_resource.secret_trigger.id 发生变化,进而触发 azurerm_container_group 的重建。
1.9.8.1. 创建资源的条件依赖另一个资源的输出时怎么办
我们在有条件创建当中介绍了如何可以通过判断用户的输入参数来决定是否要创建某个资源,让我们来看一下这样一个 Module 的例子:
1 | variable "vpc_id" { |
我们想在 Module 中创建一个 ucloud_subnet,用户可以输入一个 vpc_id 配置给它,也可以不输入,这时 Module 会创建一个 ucloud_vpc 来用。
假如我们使用这个模块,不传入 vpc_id:
1 | module vpc { |
这段代码生成的 Plan 内容如下:
1 | Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols: |
完全符合预期。假如我们希望由模块的调用者来创建 Vpc 的话:
1 | resource "ucloud_vpc" "vpc" { |
我们执行 terraform plan 的话,会得到这样的结果:
1 | ╷ |
Terraform 试图向我们抱怨,我们在 count 参数的表达式里使用了一个必须在 apply 阶段才能知道的值,所以它无法在 plan 阶段就计算出 count 的值。它建议我们先用 terraform apply 命令搭配 -target 参数把 Vpc 先创建出来,消除后续计算 Plan 时尚不知晓的值来解决这个问题。
这当然是一种很麻烦的方法,所以我们在设计 Module 时就要考虑到这种问题。有一种很简单的方法可以解决这个问题:
1 | variable "vpc" { |
我们把用来判断创建条件的输入参数类型改成 object,调用 Module 的代码就变成了:
1 | Terraform will perform the following actions: |
成功计算出 Plan。请注意虽然这个 Plan 仍然是创建两个资源,但 ucloud_vpc 资源并不是 Module 创建的。
这个方法的原理就是虽然 var.vpc.id 仍然是一个只有在 apply 阶段才能知道的值,但 var.vpc 本身是一个在 plan 阶段就可以知道的值,直接可以判读它是否为 null,所以该方法可以绕过这个限制。
1.9.9.1. 利用 create_before_destroy 调整资源 Update 的执行顺序
最近处理了一个问题,有人写了这样一段代码:
1 | provider "azurerm" { |
当他从 local.environments 中删除一个元素,然后执行 terraform apply 时,他遇到了下面的问题:
1 | │ Error: deleting Public Ip Address: (Name "azurelb" / Resource Group "example"): network.PublicIPAddressesClient#Delete: Failure sending request: StatusCode=400 -- Original Error: Code="PublicIPAddressCannotBeDeleted" Message="Public IP address /subscriptions/subscription-id/resourceGroups/resource-group/providers/Microsoft.Network/publicIPAddresses/one can not be deleted since it is still allocated to resource /subscriptions/subscription-id/resourceGroups/resource-group/providers/Microsoft.Network/loadBalancers/azurelb/frontendIPConfigurations/one. In order to delete the public IP, disassociate/detach the Public IP address from the resource. To learn how to do this, see aka.ms/deletepublicip." Details=[] |
这其实是一个还挺常见的问题,azurerm_lb.this 依赖于 azurerm_public_ip.lb[index],正确的变更顺序应该是先更新 azurerm_lb.this,再删除 azurerm_public_ip.lb 的成员,但是 Terraform 默认的执行顺序会首先尝试执行删除操作,这时因为 ip 仍然被 LoadBalancer 使用着,所以会引发一个错误。
解决方法是给 azurerm_public.lb 添加一个 create_before_destroy:
1 | resource "azurerm_public_ip" "lb" { |
create_before_destroy 名字里虽然看起来是与 Create 有关,实际上它也会将 Update 与 Create 放在一起调整,声明该参数后实际上是将 azurerm_public_ip.lb 的 Delete 推迟到执行 Update 之后再执行了,该问题得解。
1.9.10.1. Terraform 与自动化
如果团队使用 Terraform 作为变更管理和部署管道的核心工具,可能需要以某种自动化方式编排 Terraform 的运行,以确保运行之间的一致性,并提供其他有趣的功能,例如与版本控制系统钩子的集成。
Terraform 的自动化可以有多种形式,并且程度不同。一些团队继续在本地运行 Terraform,但使用脚本代码来准备一致的工作目录来运行 Terraform,而另一些团队则完全在 Jenkins 等 CI 工具中运行 Terraform。
本篇涵盖了实现此类自动化时应考虑的一些事项,既确保 Terraform 的安全运行,又适应 Terraform 工作流程中当前需要仔细注意的一些限制。它假设 Terraform 将在非交互式环境中运行,无法在终端提示输入。对于脚本代码来说不一定如此,但在 CI 工具中运行时通常如此。
1.9.10.1.1. 自动化的 Terraform 命令行工作流
在自动化流程中运行 Terraform 时,重点通常是核心的 plan/apply 循环。那么,使用 Terraform 命令行的流程大体如下:
- 初始化 Terraform 工作目录。
- 针对当前代码,为产生变化的资源计算变更计划
- 让操作员审查计划,以确保其可接受
- 应用计划描述的更改。
步骤 1、2 和 4 可以使用熟悉的 Terraform 命令以及一些附加选项来执行:
terraform init -input=false初始化工作目录。terraform plan -out=tfplan -input=false创建计划文件并将其保存到名为tfplan的本地文件。terraform apply -input=false tfplan执行存储在文件tfplan中的计划。
-input=false 参数命令 Terraform 不应尝试提示输入,而是要求配置文件或命令行提供所有必要的值。因此,可能需要在 terraform plan 上使用 -var 和 -var-file 参数来指定所有传统上在交互式使用下手动输入的变量值。
强烈建议使用支持远程状态的 Backend,因为 Terraform 可以自动将持久保存状态,后续运行可以在找回并更新状态。选择支持状态锁定的 Backend 还将提供针对 Terraform 并发运行的竞争安全保障。
1.9.10.1.2. 控制自动化中的 Terraform 输出
默认情况下,一些 Terraform 命令会提示用户下一步可能执行的步骤,通常包括具体的下一步要运行的命令。
自动化工具通常会封装正在运行的命令的具体细节,只提供抽象的步骤,这时 Terraform 输出的此类消息反而令人困惑,且无法操作,如果它们无意中鼓励用户完全绕过自动化工具,则可能还是有害的。
当环境变量 TF_IN_AUTOMATION 设置为任何非空值时,Terraform 会对其输出进行一些细微调整,不再强调要运行的特定命令。所做的具体更改会随着时间的推移而变化,但一般来说,Terraform 发现该变量时,会认为存在某种包装了 Terraform 的应用程序,它们会帮助用户进行下一步。
为了降低复杂性,该功能主要针对 Terraform 主要的工作流程命令实现。无论该变量为何值如何,其他辅助命令仍可能会产生命令行建议。
1.9.10.1.3. 在不同的机器上运行 plan 和 apply
在 CI 工具中运行时,可能很难或无法确保 plan 和 apply 命令在同一台计算机上的同一目录中运行,并且所有的文件都保持相同。
在不同的机器上运行 plan 和 apply 需要一些额外的步骤来确保正确的行为。稳健的策略如下:
plan完成后,保存整个工作目录,包括init期间创建的.terraform子目录,并将其保存在apply阶段可以访问得到的位置。常见的选择是作为所选 CI 工具中的“Build Artifact”。- 在运行
apply之前,获取上一步中创建的存档并将其解压到相同的绝对路径。这会重新创建plan后出现的所有内容,避免在plan步骤期间创建本地文件的奇怪问题。
Terraform 目前为此类自动化系统设置了一些必须满足的前提条件:
- 保存的计划文件可以包含子模块的绝对路径以及代码中引用的其他数据文件。因此,必须确保在相同的绝对路径中还原保存的工作目录。这通常是通过在某种隔离中运行 Terraform 来实现的,例如可以控制文件系统布局的 Docker 容器。
- Terraform 假设该计划将在与其创建时相同的操作系统和 CPU 架构上 Apply。例如,这意味着无法在 Windows 计算机上创建计划,然后将其应用到 Linux 服务器上。
- Terraform 期望用于生成计划的 Provider 程序插件在应用计划时可用且相同,以确保正确执行计划。如果在创建和应用计划之间升级 Terraform 或任何插件,将会产生错误。
- Terraform 无法自动检测用于创建计划的凭据是否授予对用于应用该计划的相同资源的访问权限。如果对每个凭据使用不同的凭据(例如,使用只读凭据生成计划),那么确保两套凭据在它们所属的相应服务的帐户中保持一致非常重要。
警告:计划文件包含代码的完整副本、计划所要应用的状态数据以及传递给 terraform plan 的所有变量。如果其中包含任意敏感数据,则包含计划文件的存档工作目录应受到相应保护。对于 Provider 使用的身份验证凭据,建议尽可能使用环境变量,因为这些变量不会被包含在计划中或由 Terraform 以任何其他方式保存到磁盘。
1.9.10.1.4. 交互式审批计划
自动化 Terraform 工作流程的另一个挑战是需要在计划和应用之间进行交互式审批步骤。为了稳健地实现这一点,重要的是要确保一次只能有一个计划未完成,或者两个步骤相互连接,以便批准计划将足够的信息传递到应用步骤,以确保应用正确的计划,与后来也存在的一些计划相反。
不同的 CI 工具以不同的方式解决这个问题,但通常这是通过构建管道功能实现的,其中可以按顺序应用不同的步骤,后面的步骤可以访问前面步骤生成的数据。
推荐的方法是一次只允许一个计划处于未应用状态。应用计划时,针对同一状态生成的任何其他现有计划都会失效,因为现在必须相对于新状态重新计算它们。通过强制计划按顺序获得批准(或驳回),可以避免这种情况。
1.9.10.1.5. 自动批准计划
虽然强烈建议对生产环境应用计划前要进行人工审查,但有时在预生产或开发环境中部署时需要采取更自动化的方法。
如果不需要手动批准,可以使用更简单的命令序列:
terraform init -input=falseterraform apply -input=false -auto-approve
apply 命令的这个变体隐式地创建一个新计划,然后立即应用它。 -auto-approve 选项告诉 Terraform 在应用计划之前不需要对计划进行交互式批准。
警告:当 Terraform 有权对基础设施进行破坏性更改时,始终建议对计划进行人工审查,除非在发生意外更改时可以容忍停机。仅对非关键基础设施使用自动批准。
1.9.10.1.6. 用 terraform plan 命令测试 Pull Requests
terraform plan 可以用来对 Terraform 配置的有效性进行某些有限的验证,而不影响实际的基础设施。尽管 plan 命令会更新状态以匹配实际资源,从而确保准确的计划,但更新后的状态文件并不会持久保存,因此可以安全地使用该命令来生成仅为了帮助代码审查而创建的“一次性”计划。
实现此类工作流程时,可以在相关代码审查工具(例如,Github Pull Request)中使用钩子,为每个正在审查的新提交触发 CI 工具。在这种情况下,Terraform 可以按如下方式运行:
terraform plan -input=false
与在“主”工作流程中一样,可能需要根据需要设置 -var 或 -var-file。在这种情况下不使用 -out 选项,因为为代码审查目的而生成的计划永远不会被应用。相反,一旦合并更改,就可以从主版本控制分支创建并应用新计划。
警告:请注意,通过输入变量或环境变量将敏感秘密数据传递给 Terraform 将使任何可以提交 PR 的人都可以看到,因此在开源项目或任何私人项目上必须谨慎使用此流程部分,或所有贡献者不应能够直接访问凭据等。
1.9.10.1.7. 多环境部署
Terraform 的自动化通常会被用来创建数个相同的配置,比如为预发布、测试或多租户基础设施等场景生成平行的环境。这种情况下的自动化可以帮助确保为每个环境使用正确的设置,并且在每次操作之前正确配置工作目录。
多环境编排最有趣的两个命令是 terraform init 和 terraform workspace。前者可以与其他参数一起使用,以针对环境之间的差异定制 Backend 配置,而后者可用于在单个 Backend 中存储的相同配置的多个状态之间安全切换。
如果可能,建议对所有环境使用单一后端配置,并使用 terraform workspace 命令在工作空间之间切换:
terraform init -input=falseterraform workspace select QA
在此使用模型中,Backend 存储中使用固定的命名方案,以允许多个状态共存,而无需任何进一步的配置。
或者,自动化工具可以将环境变量 TF_WORKSPACE 设置为现有工作空间名称,这将覆盖使用 terraform workspace select 命令所做的任何选择。建议仅在非交互式使用中使用此环境变量,因为在本地 shell 环境中,很容易忘记设置该变量并将变更应用到错误的状态。
在一些更复杂的情况下,不可能跨环境共享相同的 Backend 配置。例如,环境可能运行在完全独立的不同帐户的服务里,因此需要对 Backend 本身使用不同的凭据或端点。在这种情况下,可以通过 terraform init 的 -backend-config 选项覆盖后端配置设置。
1.9.10.1.8. 预先安装的插件
在默认使用情况下,terraform init 会自动下载并安装代码中使用的所有 Provider 程序的插件,并将它们放置在 .terraform 目录的子目录中。这为简单的情况提供了更简单的工作流程,并允许每段代码可以使用不同版本的插件。
在自动化环境中,可能需要禁用此行为,而是提供一组已安装在运行 Terraform 的系统上的固定插件。这样就避免了每次执行时重新下载插件的开销,并允许系统管理员控制可以使用哪些插件。
要使用此机制,请在系统上的某个位置创建一个 Terraform 运行时会将插件可执行文件放入其中的目录。已发布的插件文件可在 releases.hashicorp.com 上下载。请务必下载适合目标操作系统和体系结构的文件。
提取必要的插件后,新插件目录的内容将如下所示:
1 | ls -lah /usr/lib/custom-terraform-plugins |
文件名末尾的版本信息很重要,它使得 Terraform 可以推断每个插件的版本号。可以安装同一 Provider 程序插件的多个版本,Terraform 将使用与 Terraform 代码中的 Provider 程序版本约束相匹配的最新版本。
填充此目录后,可以使用 terraform init 的 -plugin-dir 选项跳过常规的自动下载和插件发现行为:
terraform init -input=false -plugin-dir=/usr/lib/custom-terraform-plugins
使用该组参数时,只有给定目录中的插件可以被使用。这使系统管理员可以对执行环境进行强力控制,但另一方面,它会阻止使用尚未安装到本地插件目录中的较新插件版本。哪种方法更合适将取决于每个组织内的特定情况。
还可以通过创建 terraform.d/plugins/OS_ARCH 目录与配置一起提前安装插件,在自动下载其他插件之前将搜索该目录。 -get-plugins=false 参数可禁止 Terraform 自动下载其他插件。
1.8.1. 测试
-> 注意: 该测试框架在 Terraform v1.6.0 及以后版本中可用。
Terraform 测试功能允许模块作者验证配置变更不会引入破坏性更改。测试针对特定的、临时的资源进行,防止对现有的基础设施或状态产生任何风险。
1.8.1.1. 集成测试或单元测试
默认情况下,Terraform 测试会创建真实的基础设施,并可以对这些基础设施进行断言和验证。这相当于集成测试,它通过调用 Terraform 创建基础设施并对其进行验证来测试 Terraform 的核心功能。
你可以通过更新 run 块中的 command 属性(下面有示例)来覆盖默认的测试行为。默认情况下,每个 run 块都会执行 command = apply,命令 Terraform 对你的配置执行完整的 apply 操作。将 command 值替换为 command = plan 会告诉 Terraform 不为这个 run 块创建新的基础设施。这将允许测试作者验证他们的基础设施中的逻辑操作和自定义条件,相当于编写了单元测试。
Terraform v1.7.0 引入了在 terraform test 执行期间模拟 Provider 返回数据的能力。这可以用于编写更详细和完整的单元测试。
1.8.1.2. 语法
每个 Terraform 测试都保存在一个测试文件中。Terraform 根据文件扩展名发现测试文件:.tftest.hcl 或 .tftest.json。
每个测试文件包含以下根级别的属性和块:
Terraform 按顺序执行 run 块,模拟一系列直接在配置目录中执行的 Terraform 命令。 variables 和 provider 块的顺序并不重要,Terraform 在测试操作开始时处理这些块中的所有值。我们建议首先在测试文件的开头定义你的 variables 和 provider 块。
1.8.1.2.1. 示例
以下示例演示了一个简单的 Terraform 配置,该配置创建了一个 AWS S3 存储桶,并使用输入变量来修改其名称。我们将创建一个示例测试文件(如下)来验证存储桶的名称是否如预期那样被创建。
1 | # main.tf |
以下测试文件运行了一个单独的Terraform plan 命令,该命令创建了S3存储桶,然后通过检查实际名称是否与预期名称匹配,来验证计算名称的逻辑是否正确。
1 | # valid_string_concat.tftest.hcl |
1.8.1.3. run 块
每个 run 块都有以下字段和块:
| 字段或块名称 | 描述 | 默认值 |
|---|---|---|
command |
一个可选属性,可以是 apply 或 plan。 |
apply |
plan_options.mode |
一个可选属性,可以是 normal 或 refresh-only。 |
normal |
plan_options.refresh |
一个可选的 bool 属性。 |
true |
plan_options.replace |
一个可选属性,包含一个资源地址列表,引用测试配置中的资源。 | |
plan_options.target |
一个可选属性,包含一个资源地址列表,引用测试配置中的资源。 | |
variables |
一个可选的 variables 块。 |
|
module |
一个可选的 module 块。 |
|
providers |
一个可选的 providers 属性。 |
|
assert |
可选的 assert 块。 |
|
expect_failures |
一个可选属性。 |
command 属性和 plan_options 块告诉 Terraform 对于每个 run 块执行哪个命令和选项。如果您没有指定 command 属性或 plan_options 块,那么默认操作是普通的 terraform apply 操作。
command 属性指明操作应该是一个 plan 操作还是一个 apply 操作。
plan_options 块允许测试的作者定义他们通常需要通过命令行标志和选项定义的 plan mode 和 选项。我们将在 变量 部分介绍 -var 和 -var-file 选项。
1.8.1.3.1. 断言
Terraform 测试的 run 块断言是自定义条件,由条件和错误消息组成。
在 Terraform 测试命令执行结束时,Terraform 会将所有失败的断言作为测试通过或失败状态的一部分展示出来。
断言中的引用
测试中的断言可以引用主 Terraform 配置中的其他自定义条件可用的任何现有命名值。
此外,测试断言可以直接引用当前和先前 run 块的输出。比如引用了上一个示例中的输出的一个合法的表达式条件:condition = output.bucket_name == "test_bucket"。
1.8.1.4. variable 块
你可以直接在你的测试文件中为 输入变量 设置值。
你可以在测试文件的根级别或者 run 块内部定义 variables 块。Terraform 将测试文件中的所有变量值传递到文件中的所有 run 块。你可以通过在某个 run 块中直接设置变量值来覆盖从根部继承的值。
在上述 示例 的测试文件中添加:
1 | # variable_precedence.tftest.hcl |
我们添加了第二个 run 块,该块指定 bucket_prefix 变量值为 other,覆盖了测试文件提供的,并在第一个 run 块中使用的值 —— test。
1.8.1.4.1. 通过命令行或定义文件指定变量
除了通过测试文件指定变量值外,Terraform test 命令还支持指定变量值的其他方法。
您可以通过 命令行 和 变量定义文件 为所有测试指定变量值。
像普通的 Terraform 命令一样,Terraform 会自动加载测试目录中定义的任何变量文件。自动变量文件包括 terraform.tfvars、terraform.tfvars.json,以及所有以 .auto.tfvars 或 .auto.tfvars.json 结尾的文件。
注意: 从测试目录中的自动变量文件加载的变量值只适用于在同一测试目录中定义的测试。以所有其他方式定义的变量将适用于给定测试运行中的所有测试。
这在使用敏感变量值和设置 Provider 配置时特别有用。否则,测试文件可能会直接暴露这些敏感值。
1.8.1.4.2. 变量定义优先级
除了测试文件中设置的变量值,变量定义优先级 在测试中保持不变。在测试文件中定义的变量具有最高优先级,可以覆盖环境变量、变量文件或命令行输入。
对于在测试目录中定义的测试,任何在测试目录的自动变量文件中定义的变量值都将覆盖主配置目录的自动变量文件中定义的值。
1.8.1.4.3. 变量中的引用
在 run 块中定义的 variable 中可以引用在先前 run 块中执行的模块的输出和在更高优先级定义的变量。
例如,以下代码块显示了变量如何引用更高优先级的变量和先前的 run 块:
1 | variables { |
上面,run_block_one 中的 local_value 从 global_value 变量获取值。如果你想给多个变量分配相同的值,这种模式很有用。你可以在文件级别一次指定一个变量的值,然后与不同的变量共享它。
相比之下,run_block_two 中的 local_value 引用了 run_block_one 的 output_one 的输出值。这种模式对于在 run 块之间传递值特别有用,特别是如果 run 块正在执行模块部分中详细描述的不同模块。
1.8.1.5. provider 块
您可以通过使用 provider 和 providers 块和属性,在测试文件中设置或覆盖 Terraform 代码所需的 Provider。
您可以在 Terraform 测试文件的根级别,定义 provider 块,就像在 Terraform 配置代码中创建它们一样。然后,Terraform 会将这些 provider 块传递到其配置中,每个 run 块执行时都是如此。
默认情况下,您指定的每个 Provider 都直接在每个 run 块中可用。您可以通过使用 providers 属性在特定 run 块中设置 Provider 的可用性。这个块的行为和语法与 providers meta-argument 的行为相匹配。
如果您在测试文件中不提供 Provider 配置,Terraform 会尝试使用 Provider 的默认设置初始化其配置中的所有 Provider。例如,任何旨在配置 Provider 的环境变量仍然可用,并且 Terraform 可以使用它们来创建默认 Provider。
下面,我们将扩展我们之前的 示例,用测试代码而不是 Terraform 配置代码来指定 region。在这个示例中,我们将测试以下配置文件:
1 | # main.tf |
我们现在可以在以下测试文件中定义如下的 provider 块:
1 | # customised_provider.tftest.hcl |
现在我们也可以创建一个更复杂的示例配置,使用多个 Provider 以及别名:
1 | # main.tf |
在我们的测试文件中,我们可以设定多个 Provider:
1 | # customised_providers.tftest.hcl |
我们也可以在特定 run 块中声明特定的 Provider:
1 | # main.tf |
我们的测试文件可以为不同的 run 块配置的 Provider:
1 | # customised_providers.tftest.hcl |
注意: 在使用 command = apply 运行测试时,run 块之间切换 Provider 可能会导致运行和测试失败,因为由一个 Provider 定义创建的资源在被另一个修改时将无法使用。
从 Terraform v1.7.0 开始,provider 块也可以引用测试文件变量和 run 块输出。这意味着测试框架可以从一个 Provider 获取凭证和其他设置信息,并在初始化第二个 Provider 时使用这些信息。
在下面的示例中,首先初始化 vault Provider,然后在一个设置模块中使用它来提取 aws Provider 的凭证。有关 setup 模块的更多信息,请参阅 模块。
1 |
|
1.8.1.6. module 块
您可以修改特定的 run 块执行的模块。
默认情况下,Terraform 针对正在测试的配置代码,依次执行所有 run 块中设定的命令。Terraform 在您执行 terraform test 命令的目录(或者您用 -chdir 参数指向的目录)内测试配置。每个 run 块也允许用户使用 module 块更改目标配置。
与传统的 module 块不同,测试文件中的 module 块 仅 支持 source 属性和 version 属性。通常通过传统的 module 块提供的其余属性应由 run 块内的替代属性和块提供。
注意: Terraform 测试文件只支持 source 属性中的 本地 和 注册表 模块。
在执行其他模块时,run 块内的所有其他块和属性都受支持,assert 块执行时使用来自其他模块的值。这在 模块状态 中有更详细的说明。
测试文件中 modules 块的两个示例用例是:
- 一个设置模块,为待测 Terraform 配置代码创建测试所需的基础设施。
- 一个加载模块,用于加载和验证 Terraform 配置代码未直接创建的次要基础设施(如数据源)。
以下示例演示了这两种用例。
首先,我们有一个模块,它将创建并将多个文件加载到已创建的 S3 存储桶中。这是我们要测试的配置。
1 | # main.tf |
然后,我们使用配置模块创建这个 S3 存储桶,这样在测试时就可以使用它:
1 | # testing/setup/main.tf |
第三步,我们使用一个加载模块,读取 S3 存储桶中的文件。这是一个比较牵强的例子,因为我们完全可以直接在创建这些文件的模块中创建这些数据源,但它在这里可以很好地演示如何编写测试:
1 | # testing/loader/main.tf |
最后,我们使用测试文件把刚才创建的多个助手模块以及待测模块编织在一起形成一个有效的测试配置:
1 | # file_count.tftest.hcl |
1.8.1.6.1. 模块状态
当 Terraform 执行 terraform test 命令时,Terraform 会为每个测试文件在内存中维护一个或多个状态文件。
总是至少有一个状态文件维护在测试下的 Terraform 配置代码的状态。这个状态文件由所有没有 module 块指定要加载的替代模块的 run 块共享。
此外,Terraform 加载的每个替代模块都有一个状态文件。一个替代模块的状态文件被执行给定模块的所有 run 块共享。
Terraform 团队对任何需要手动状态管理或在 test 命令中对同一状态执行不同配置的用例感兴趣。如果你有一个用例,请提交一个 issue并与我们分享。
以下示例使用注释来解释每个 run 块的状态文件的来源。在下面的示例中,Terraform 创建并管理了总共三个状态文件。第一个状态文件是针对测试下的主模块,第二个是针对设置模块,第三个是针对加载模块。
1 | run "setup" { |
模块的清理
在测试文件执行结束时,Terraform 会试图销毁在该测试文件执行过程中创建的每个资源。当 Terraform 加载替代模块时,Terraform 销毁这些对象的顺序很重要。例如,在第一个 模块 示例中,Terraform 不能在 “execute” run 块中创建的对象之前销毁在 “setup” run 块中创建的资源,因为我们在 “setup” 步骤中创建的 S3 桶在包含对象的情况下无法被销毁。
Terraform 按照 run 块的反向顺序销毁资源。在最近的 例子 中,有三个状态文件。一个用于主状态,一个用于 ./testing/loader 模块,还有一个用于 ./testing/setup 模块。由于 ./testing/loader 状态文件最近被最后一个运行块引用,因此首先被销毁。主状态文件将被第二个销毁,因为它被 “update” run 块引用。然后 ./testing/setup 状态文件将被最后销毁。
请注意,前两个 run 块 “setup” 和 “init” 在销毁操作中不做任何事情,因为它们的状态文件被后续的 run 块使用,并且已经被销毁。
如果你使用单个设置模块作为替代模块,并且它首先执行,或者你不使用任何替代模块,那么销毁顺序不会影响你。更复杂的情况可能需要仔细考虑,以确保资源的销毁可以自动完成。
1.8.1.7. 预期失败
默认情况下,如果在执行 Terraform 测试文件期间,任何自定义条件,包括 check 块断言失败,则整体命令会将测试报告为失败。
然而,我们经常想要测试代码运行失败时的行为。Terraform 为此用例提供了 expect_failures 属性。
在每个 run 块中,expect_failures 属性可以设置应该导致自定义条件检查失败的可检查对象(资源,数据源,检查块,输入变量和输出)的列表。如果您指定的可检查对象报告问题,测则试通过,如果没有报告错误,那么测试总体上失败。
您仍然可以在 expect_failures 块附近编写断言,但您应该注意,除了 check 块断言外,所有自定义条件都会停止 Terraform 的执行。这在测试执行期间仍然适用,所以这些断言应该只考虑你确定会在可检查对象应该失败之前可知的值。您可以使用引用或在主配置中的 depends_on 元参数来管理这一点。
这也意味着,除了 check 块,你只能可靠地包含一个可检查的对象。我们支持在 expect_failures 属性中列出可检查对象的列表,仅用于 check 块。
下面的一个快速示例演示了测试输入变量的 validation 块。配置文件接受一个必须是偶数的单一输入变量。
1 | # main.tf |
测试文件包含了两个 run 块。一个验证了我们的自定义条件在偶数条件下是通过的,另一个验证输入奇数时会失败。
1 | # input_validation.tftest.hcl |
注意:Terraform 只期望在 run 块的 command 属性指定的操作中出现失败。
在使用 command = apply 的 run 块中使用 expect_failures 时要小心。一个 run 块中的 command = apply 如果期望自定义条件失败,那么如果该自定义条件在 plan 期间失败,整体将会失败。
这在逻辑上是正确的,因为 run 块期望能够运行应用操作,但由于 plan 失败而不能运行,但这也可能会引起混淆,因为即使那个失败被标记为预期的,你还是会在诊断中看到失败。
有时,Terraform 在计划阶段不执行自定义条件,因为该条件依赖于只有在 Terraform 创建引用资源后才可用的计算属性。在这些情况下,你可以在设置 command = apply 时使用 expect_failures 块。然而,大多数情况下,我们建议只在 command = plan 时使用 expect_failures。
注意:预期的失败只适用于用户定义的自定义条件。
除了在可检查对象中指定的预期失败之外的其他种类的失败仍会导致整体测试失败。例如,一个期望布尔值作为输入的变量,如果 Terraform 收到的是错误的值类型,即使该变量包含在 expect_failures 属性中,也会导致周围的测试失败。
expect_failures 属性包含在其中是为了允许作者测试他们的配置和任何定义的逻辑。像前面的例子中的类型不匹配错误,不是 Terraform 作者应该担心和测试的事情,因为 Terraform 本身会处理强制类型约束。因此,你只能在自定义条件中 expect_failures。
1.7.16.1. refresh
terraform refresh 命令将实际存在的基础设施对象的状态同步到状态文件中记录的对象状态。它可以用来检测真实状态与记录状态之间的漂移并更新状态文件。
警告!!!该命令已在最新版本 Terraform 中被废弃,因为该命令的默认行为在当前用户错误配置了使用的云平台令牌时会引发对状态文件错误的变更。
该命令并不会修改基础设施对象,只修改状态文件。
我们一般不需要使用该命令,因为 Terraform 会自动执行相同的刷新操作,作为在 terraform plan 和 terraform apply 命令中创建计划的一部分。本命令在这里主要是为了向后兼容,但我们不建议使用它,因为它没有提供在更新状态之前检查操作效果的机会。
1.7.16.1.1. 用法
terraform refresh [options]
该命令本质上是以下命令的别名,具有完全相同的效果:
1 | terraform apply -refresh-only -auto-approve |
因此,该命令支持所有 terraform apply 所支持的参数,除了它不接受一个现存的变更计划文件,不允许选择 “refresh only” 之外的模式,并且始终应用 -auto-approve 选项。
自动执行 refresh 是很危险的,因为如果当前用户错误配置了使用的 Provider 的令牌,那么 Terraform 会错误地以为当前状态文件中记录的所有资源都被删除了,随即从状态文件中无预警地删除所有相关记录。
我们推荐运行如下命令来取得相同的效果,同时可以在修改状态文件之前预览即将对其作出的修改:
1 | terraform apply -refresh-only |
该命令将会在交互界面中提示用户检测到的变更,并提示用户确认执行。
terraform apply 和 terraform plan 命令的 -refresh-only 选项是从 Terraform v0.15.4 版本开始被引入的。对更早的版本,用户只能直接使用 terraform refresh 命令,同时要小心本篇警告过的危险副作用。尽可能避免显式使用 terraform refresh 命令,Terraform 在执行 terraform plan 和 terraform apply 命令时都会自动执行刷新状态的操作以生成变更计划,尽可能依赖该机制来维持状态文件的同步。
show
1.7.17.1. show
terraform show 命令从状态文件或是变更计划文件中打印人类可读的输出信息。这可以用来检查变更计划以确定所有操作都是符合预期的,或是审查当前的状态文件。
可以通过添加 -json 参数输出机器可读的 JSON 格式输出。
需要注意的是,使用 -json 输出时所有标记为 sensitive 的敏感数据都会以明文形式被输出。
1.7.17.1.1. JSON 输出
可以使用 terraform show -json 命令打印 JSON 格式的状态信息。
如果指定了一个变更计划文件,terraform show -json 会以 JSON 格式记录变更计划、配置以及当前状态。
如果在写入状态文件后更新了包含新架构版本的 Provider 程序,则需要先升级状态,然后才能使用 show -json 显示状态。如果要查看计划,必须先在不使用 -refresh=false 的情况下创建计划文件。如果要查看当前状态,请先运行 terraform refresh。
1.7.17.1.2. 用法
terraform show [options] [file]
您可以将为 file 指定状态文件或计划文件的路径。如果不指定文件路径,Terraform 将显示最新的状态快照。
该命令支持以下参数:
-json:以 JSON 格式输出-no-color:与apply类似,不再赘述
state
1.7.18.1. state
terraform state 命令可以用来进行复杂的状态管理操作。随着你对 Terraform 的使用越来越深入,有时候你需要对状态文件进行一些修改。由于我们在状态管理章节中提到过的,状态文件的格式属于 HashiCorp 未公开的私有格式,所以直接修改状态文件是不适合的,我们可以使用 terraform state 命令来执行修改。
该命令含有数个子命令,我们会一一介绍。
1.7.18.1.1. 用法
terraform state <subcommand> [options] [args]
1.7.18.1.2. 远程状态
所有的 state 子命令都可以搭配本地状态文件以及远程状态使用。使用远程状态时读写操作可能用时稍长,因为读写都要通过网络完成。备份文件仍然会被写入本地磁盘。
1.7.18.1.3. 备份
所有会修改状态文件的 terraform state 子命令都会生成备份文件。可以通过 -backup 参数指定备份文件的位置。
只读子命令(例如 list )由于不会修改状态,所以不会生成备份文件。
注意修改状态的 state 子命令无法禁用备份。由于状态文件的敏感性,Terraform 强制所有修改状态的子命令都必须生成备份文件。如果你不想保存备份,可以手动删除。
1.7.18.1.4. 命令行友好
state 子命令的输出以及命令结构都被设计得易于同 Unix 下其他命令行工具搭配使用,例如 grep、awk 等等。同样的,输出结果也可以在 Windows 上轻松使用 PowerShell 处理。
对于复杂场景,我们建议使用管道组合 state 子命令与其他命令行工具一同使用。
1.7.18.1.5. 资源地址
state 子命令中大量使用了资源地址,我们在资源地址章节中做了相关的介绍。
list
1.7.18.1.1. list
terraform state list 命令可以列出状态文件中记录的资源对象。
1.7.18.1.1.1. 用法
terraform state list [options] [address...]
该命令会根据 address 列出状态文件中相关资源的信息(如果给定了 address 的话)。如果没有给定 address,那么所有资源都会被列出。
列出的资源根据模块深度以及字典序进行排序,这意味着根模块的资源在前,越深的子模块定义的资源越在后。
对于复杂的基础设施,状态文件可能包含成千上万到的资源对象。可以指定一个或多个资源地址来进行过滤。
可以使用的可选参数有:
-state=path:指定使用的状态文件地址。默认为terraform.tfstate。使用远程 Backend 时该参数设置无效-id=id:要显示的资源 ID
1.7.18.1.1.2. 例子:列出所有资源
1 | $ terraform state list |
1.7.18.1.1.3. 例子:根据资源地址过滤
1 | $ terraform state list aws_instance.bar |
1.7.18.1.1.4. 例子:根据模块过滤
该例子列出给定模块及其子模块的所有资源:
1 | $ terraform state list module.elb |
1.7.18.1.1.5. 例子:根据ID过滤
此示例将仅列出在命令行中指定 ID 的资源,查找特定资源在代码中的位置时非常有用:
1 | $ terraform state list -id=sg-1234abcd |
1.7.18.2.1. mv
Terraform 状态的主要功能是记录下代码中的资源实例地址与其代表的远程对象之间的绑定。通常,Terraform 会自动更新状态以响应应用计划时采取的操作,例如删除已被删除的远程对象的绑定。
在修改了 resource 块名称,或是将资源移动到代码中的不同模块时,如果想保留现有的远程对象,可以使用 terraform state mv 命令。
1.7.18.2.1.1. 用法
terraform state mv [options] SOURCE DESTINATION
Terraform 将在当前状态中查找与给定地址匹配的资源实例、资源或模块,如果找到,则将原本由源地址跟踪的远程对象移动到目标地址下。
源地址和目标地址都必须使用资源地址语法,并且它们引用对象的类型必须相同:我们只能将一个资源实例移动到另一个资源实例,将整个模块实例移动到另一个整个模块实例,等等。此外,如果我们要移动资源或资源实例,则只能将其移动到具有相同资源类型的新地址。
terraform state mv 最常见的用途是当我们在代码中重命名 resource 块,或是将 resource 块移动到子模块中时,这两种情况都是为了保留现有对象但以新地址跟踪它。默认情况下,Terraform 会将移动或重命名资源配置理解为删除旧对象并在新地址创建新对象的请求,因此 terraform state mv 允许我们已经存在的对象附加到Terraform 中的新地址上。
警告:如果我们在多人协作环境中使用 Terraform,则必须确保当我们使用 terraform state mv 进行代码重构时,我们与同事进行了仔细沟通,以确保没有人在我们的配置更改和 terraform 状态之间进行任何其他更改mv 命令,因为否则他们可能会无意中创建一个计划,该计划将销毁旧对象并在新地址创建新对象。
该命令提供以下可选参数:
-dry-run:报告与给定地址匹配的所有资源实例。-lock=false:执行时是否先锁定状态文件。如果其他人可能同时对同一工作区运行命令,则这是危险的。-lock-timeout=DURATION:除非使用-lock=false禁用锁定,否则命令 Terraform 为上锁操作设置一个超时时长。持续时间语法是一个数字后跟一个时间单位字母,例如“3s”表示三秒。
以下是使用 local Backend 时可用的遗留参数:
-backup=FILENAME:指定源状态文件的备份地址,默认为源状态文件加上".backup"后缀-bakcup-out=FILENAME:指定目标状态文件的备份地址,默认为目标状态文件加上".backup"后缀-state=FILENAME:源状态文件地址,默认为当前 Backend 或是"terraform.tfstate"-state-out=FILENAME:目标状态文件地址。如果不指定则使用源状态文件。可以是一个已经存在的文件或新建一个文件
1.7.18.2.1.2. 例子:重命名一个资源
1 | $ terraform state mv 'packet_device.worker' 'packet_device.helper' |
1.7.18.2.1.3. 例子:将一个资源移动进一个模块
如果我们最初在根模块中编写了资源,但现在希望将其重构进子模块,则可以将 resource 块移动到子模块代码中,删除根模块中的原始资源,然后运行以下命令告诉 Terraform 将其视为一次移动:
1 | $ terraform state mv 'packet_device.worker' 'module.app.packet_device.worker' |
在上面的示例中,新资源具有相同的名称,但模块地址不同。如果新的模块组织建议不同的命名方案,您还可以同时更改资源名称:
1 | $ terraform state mv packet_device.worker module.worker.packet_device.main |
1.7.18.2.1.4. 例子:移动一个模块进入另一个模块
我们还可以将整个模块重构为子模块。在配置中,将代表模块的 module 块移动到不同的模块中,然后使用如下命令将更改配对:
1 | $ terraform state mv 'module.app' 'module.parent.module.app' |
1.7.18.2.1.5. 例子:移动一个模块到另一个状态文件
1 | $ terraform state mv -state-out=other.tfstate 'module.app' 'module.app' |
1.7.18.2.1.6. 移动一个带有 count 参数的资源
使用 count 元参数定义的资源具有多个实例,每个实例都由一个整数标识。我们可以通过在给定地址中包含显式索引来选择特定实例:
1 | $ terraform state mv 'packet_device.worker[0]' 'packet_device.helper[0]' |
不使用 count 或 for_each 的资源只有一个资源实例,其地址与资源本身相同,因此我们可以从不包含索引的地址移动到包含索引的地址,或相反:
1 | $ terraform state mv 'packet_device.main' 'packet_device.all[0]' |
方括号 ([, ]) 在某些 shell 中具有特殊含义,因此您可能需要引用或转义地址,以便将其逐字传递给 Terraform。上面的示例显示了 Unix 风格 shell 的典型引用语法。
1.7.18.2.1.7. 移动一个带有 for_each 参数的资源
使用 for_each 元参数定义的资源具有多个实例,每个实例都由一个字符串标识。我们可以通过在给定地址中包含显式的键来选择特定实例。
但是,字符串的语法包含引号,并且引号符号通常在命令 shell 中具有特殊含义,因此我们需要为正在使用的 shell 使用适当的引用和/或转义语法。例如:
Linux、MacOS 以及 Unix:
1 | $ terraform state mv 'packet_device.worker["example123"]' 'packet_device.helper["example456"]' |
PowerShell:
1 | $ terraform state mv 'packet_device.worker[\"example123\"]' 'packet_device.helper[\"example456\"]' |
Windows 命令行(cmd.exe):
1 | $ terraform state mv packet_device.worker[\"example123\"] packet_device.helper[\"example456\"] |
除了使用字符串而不是整数作为实例键之外,for_each 资源的处理与 count 资源类似,因此具有和不具有索引组件的相同地址组合都是有效的,如上一节所述。
1.7.18.3.1. pull
terraform state pull 命令可以从远程 Backend 中人工下载状态并输出。该命令也可搭配本地状态文件使用。
1.7.18.3.1.1. 用法
terraform state pull
该命令下载当前位置对应的状态文件,并以原始格式打印到标准输出流。
由于状态文件使用 JSON 格式,该功能可以搭配例如 jq 这样的命令行工具使用,也可以用来人工修改状态文件。
注意:Terraform 状态文件必须采用 UTF-8 格式,不带字节顺序标记 (BOM)。对于 Windows 上的 PowerShell,使用 Set-Content 自动以 UTF-8 格式对文件进行编码。例如,运行 terraform state pull | sc terraform.tfstate
push
1.7.18.4.1. push
terraform push 命令被用来手动上传本地状态文件到远程 Backend。该命令也可以被用在当前使用的本地状态文件上。
该命令应该很少使用。它时一种需要对远程状态进行手动干预的情况下使用的工具。
1.7.18.4.1.1. 用法
terraform state push [options] PATH
该命令会把 PATH 位置的状态文件推送到当前使用的 Backend 上(可以是当前使用的 terraform.tfstate 文件)。
如果 PATH 为 -,则从标准输入流读取要推送的状态数据。该数据在写入目标状态之前被完全加载到内存中并进行验证。
注意:Terraform 状态文件必须采用 UTF-8 格式,不带字节顺序标记 (BOM)。对于 Windows 上的 PowerShell,使用 Set-Content 自动以 UTF-8 格式对文件进行编码。例如,运行 terraform state push | sc terraform.tfstate。
Terraform 会进行一系列检查以防止你进行一些不安全的变更:
- 检查 lineage:如果两个状态文件的 lineage 值不同,Terraform 会禁止推送。一个不同的 lineage 说明两个状态文件描述的是完全不同的基础设而你可能会因此丢失重要数据
- 序列号检查:如果目标状态文件的 serial 值大于你要推送的状态的 serial 值,Terraform 会禁止推送。一个更高的 serial 值说明目标状态文件已经无法与要推送的状态文件对应上了
这两种检查都可以通过添加 -force 参数禁用,但不推荐这样做。如果禁用安全检查直接推送,那么目标状态文件将被覆盖。
replace-provider
1.7.18.5.1. replace-provider
terraform state replace-provider 命令可以替换状态文件中资源对象所使用的 Provider.
1.7.18.5.1.1. 用法
terraform state replace-provider [options] FROM_PROVIDER_FQN TO_PROVIDER_FQN
该命令会更新所有使用 from 的 Provider 的资源,将它们使用的 Provider 更新为 to Provider。这让我们可以更新状态文件中资源所使用的 Provider 的源。
该命令在进行任意修改之前会先生成一个备份文件。备份机制不可关闭。
支持以下可选参数:
-auto-approve:跳过交互式提示确认环节-lock=false:执行时是否先锁定状态文件。如果其他人可能同时对同一工作区运行命令,则这是危险的。-lock-timeout=0s:除非使用-lock=false禁用锁定,否则命令 Terraform 为上锁操作设置一个超时时长。持续时间语法是一个数字后跟一个时间单位字母,例如“3s”表示三秒。
以下是使用 local Backend 时可用的遗留参数:
-backup=FILENAME:指定源状态文件的备份地址,默认为源状态文件加上".backup"后缀-bakcup-out=FILENAME:指定目标状态文件的备份地址,默认为目标状态文件加上".backup"后缀-state=FILENAME:源状态文件地址,默认为当前 Backend 或是"terraform.tfstate"-state-out=FILENAME:目标状态文件地址。如果不指定则使用源状态文件。可以是一个已经存在的文件或新建一个文件
1.7.18.5.1.2. 样例
下面的示例将 hashicorp/aws Provider 程序替换为 acme 的复刻版本,该 Provider 托管在 registry.acme.corp 的私有注册表中:
1 | $ terraform state replace-provider hashicorp/aws registry.acme.corp/acme/aws |
1.7.18.6.1. rm
Terraform 状态的主要功能是记录下代码中的资源实例地址与其代表的远程对象之间的绑定。通常,Terraform 会自动更新状态以响应应用计划时采取的操作,例如删除已被删除的远程对象的绑定。
terraform state rm 命令可以用来从状态文件中删除对象和实际远程对象的绑定,该命令只是删除绑定,不会删除实际存在的远程对象,删除后 Terraform 会“忘记”这个对象的存在。
注意:从 Terraform v1.7.0 开始支持 removed 块。与 terraform state rm 命令不同,您可以使用 removed 块一次删除多个资源,并且您可以将删除操作作为正常计划和执行工作流程的一部分进行审查。了解有关将 removed 块与资源一起使用以及将 removed 块与模块一起使用的更多信息。
1.7.18.6.1.1. 用法
terraform state rm [options] ADDRESS...
Terraform 将在状态中搜索与给定资源地址匹配的任何实例,并删除所有实例对应的记录,以便 Terraform 将不再跟踪相应的远程对象。
这意味着尽管这些对象仍将继续存在于远程系统中,但后续的 terraform plan 会尝试新建这些被“遗忘”的实例。根据远程系统施加的约束,如果这些对象的名称或其他标识符与仍然存在的旧对象发生冲突,创建这些对象可能会失败。
可以使用如下可选参数:
-dry-run:报告与给定地址匹配的所有资源实例(由于此时并未执行删除,所以 Terraform 这时还不会“遗忘”任何资源)。-lock=false:执行时是否先锁定状态文件。如果其他人可能同时对同一工作区运行命令,则这是危险的。-lock-timeout=DURATION:除非使用-lock=false禁用锁定,否则命令 Terraform 为上锁操作设置一个超时时长。持续时间语法是一个数字后跟一个时间单位字母,例如“3s”表示三秒。
以下是使用 local Backend 时可用的遗留参数:
-backup=FILENAME:指定源状态文件的备份地址,默认为源状态文件加上".backup"后缀-bakcup-out=FILENAME:指定目标状态文件的备份地址,默认为目标状态文件加上".backup"后缀-state=FILENAME:源状态文件地址,默认为当前 Backend 或是"terraform.tfstate"-state-out=FILENAME:目标状态文件地址。如果不指定则使用源状态文件。可以是一个已经存在的文件或新建一个文件
1.7.18.6.1.1.1. 删除一个资源
下面的例子演示了如何让 Terraform “遗忘”所有类型为 packet_device,并且名为 worker 的资源实例:
1 | $ terraform state rm 'packet_device.worker' |
不使用 count 或 for_each 的资源只有一个实例,因此该示例也是选择该单个实例的正确语法。
1.7.18.6.1.1.2. 删除一个模块
1 | $ terraform state rm 'module.foo' |
1.7.18.6.1.1.3. 删除一个模块内资源
要选择在子模块中定义的资源,我们必须指定该模块的路径作为资源地址的一部分:
1 | $ terraform state rm 'module.foo.packet_device.worker' |
1.7.18.6.1.1.4. 删除一个声明count的资源
使用 count 元参数定义的资源具有多个实例,每个实例都由一个整数标识。我们可以通过在给定地址中包含显式索引来选择特定实例:
1 | $ terraform state rm 'packet_device.worker[0]' |
方括号 ([, ]) 在某些 shell 中具有特殊含义,因此我们可能需要引用或转义地址,以便将其逐字传递给 Terraform。上面的例子使用了 Unix 风格 shell 的典型引用语法。
1.7.18.6.1.1.5. 删除一个声明for_each的资源
使用 for_each 元参数定义的资源具有多个实例,每个实例都由一个字符串标识。我们可以通过在给定地址中包含显式密钥来选择特定实例。
但是,字符串的语法包含引号,并且引号符号通常在命令 shell 中具有特殊含义,因此我们需要为我们正在使用的 shell 使用适当的引用和/或转义语法。例如:
Linux, MacOS, and Unix:
1 | $ terraform state rm 'packet_device.worker["example"]' |
PowerShell:
1 | $ terraform state rm 'packet_device.worker[\"example\"]' |
Windows命令行(cmd.exe):
1 | $ terraform state rm packet_device.worker[\"example\"] |
show
1.7.18.7.1. show
terraform state show 命令可以展示状态文件中单个资源的属性。
1.7.18.7.1.1.1. 用法
terraform state show [options] ADDRESS
该命令需要指定一个资源地址。资源地址需要遵循资源地址格式。
该命令支持以下可选参数:
-state=path:指向状态文件的路径。默认情况下是terraform.tfstate。如果启用了远程 Backend 则该参数设置无效
terraform state show 的输出被设计成人类可读而非机器可读。如果想要从输出中提取数据,请使用 terraform show -json。
1.7.18.7.1.1.2. 展示单个资源
1 | $ terraform state show 'packet_device.worker' |
1.7.18.7.1.1.3. 展示单个模块资源
1 | $ terraform state show 'module.foo.packet_device.worker' |
1.7.18.7.1.1.4. 展示声明count资源中特定实例
1 | $ terraform state show 'packet_device.worker[0]' |
1.7.18.7.1.1.5. 展示声明for_each资源中特定实例
Linux, MacOS, and Unix:
1 | $ terraform state show 'packet_device.worker["example"]' |
PowerShell:
1 | $ terraform state show 'packet_device.worker[\"example\"]' |
Windows命令行:
1 | $ terraform state show packet_device.worker[\"example\"] |
1.7.19.1. taint
terrform taint 命令可以手动标记某个Terraform管理的资源有"污点",强迫在下一次执行apply时删除并重建之。
该命令并不会修改基础设施,而是在状态文件中的某个资源对象上标记污点。当一个资源对象被标记了污点,在下一次 plan 操作时会计划将之删除并且重建,apply 操作会执行这个变更。
强迫重建某个资源可以使你能够触发某种副作用。举例来说,你想重新执行某个预置器操作,或是某些人绕过 Terraform 修改了虚拟机状态,而你想将虚拟机重置。
注意为某个资源标记污点并重建之会影响到所有依赖该资源的对象。举例来说,一条 DNS 记录使用了服务器的 IP 地址,我们在服务器上标记污点会导致 IP 发生变化从而影响到 DNS 记录。这种情况下可以使用 plan 命令查看变更计划。
警告:此命令已被弃用。从 Terraform v0.15.2 开始,我们建议使用 -replace 选项和 terraform apply 代替(详细信息如下)。
1.7.19.1.1. 推荐的替代方法
从 Terraform v0.15.2 开始,我们建议使用 terraform apply 的 -replace 选项来强制 Terraform 替换对象,即使没有发生需要变更的配置更改。
1 | terraform apply -replace="aws_instance.example[0]" |
我们推荐使用 -replace 参数,因为这可以在 Terraform 计划中显示将要发生的变更,让我们在采取任何会影响系统的操作之前了解计划将如何影响我们的基础设施。当我们使用 terraform taint 时,其他用户有可能可以在我们审查变更之前针对标记的对象创建新的变更计划。
1.7.19.1.2. 用法
1 | terraform taint [options] <address> |
address 参数是要标记污点的资源地址。该地址格式遵循资源地址语法,例如:
aws_instance.fooaws_instance.bar[1]aws_instance.baz[\"key\"](资源地址中的引号必须在命令行中转义,这样它们就不会被 shell 解释)module.foo.module.bar.aws_instance.qux
该命令可以使用如下可选参数:
-allow-missing:如果声明该参数,那么即使资源不存在,命令也会返回成功(状态码0)。对于其他异常情况,该命令可能仍会返回错误,例如读取或写入状态时出现问题。-lock=false:执行时是否先锁定状态文件。如果其他人可能同时对同一工作区运行命令,则这是危险的。-lock-timeout=DURATION:除非使用-lock=false禁用锁定,否则命令 Terraform 为上锁操作设置一个超时时长。持续时间语法是一个数字后跟一个时间单位字母,例如“3s”表示三秒。
以下是使用 local Backend 时可用的遗留参数:
-backup=FILENAME:指定源状态文件的备份地址,默认为源状态文件加上".backup"后缀-bakcup-out=FILENAME:指定目标状态文件的备份地址,默认为目标状态文件加上".backup"后缀-state=FILENAME:源状态文件地址,默认为当前 Backend 或是"terraform.tfstate"-state-out=FILENAME:目标状态文件地址。如果不指定则使用源状态文件。可以是一个已经存在的文件或新建一个文件
1.7.19.1.3. 标记单个资源
1 | $ terraform taint aws_security_group.allow_all |
1.7.19.1.4. 标记使用for_each创建的资源的特定实例
1 | $ terraform taint "module.route_tables.azurerm_route_table.rt[\"DefaultSubnet\"]" |
1.7.19.1.5. 标记模块中的资源
1 | $ terraform taint "module.couchbase.aws_instance.cb_node[9]" |
虽然我们推荐模块深度不要超过1,但是我们仍然可以标记多层模块中的资源:
1 | $ terraform taint "module.child.module.grandchild.aws_instance.example[2]" |
1.7.20.1. validate
terraform validate 命令可以检查目录下 Terraform 代码,只检查语法文件,不会访问诸如远程 Backend、Provider 的 API 等远程资源。
validate 检查代码的语法是否合法以及一致,不管输入变量以及现存状态。
自动运行此命令是安全的,例如作为文本编辑器中的保存后检查或作为 CI 系统中可复用的测试步骤。
validate 命令需要已初始化的工作目录,所有引用的插件与模块都被安装完毕。如果只想检查语法而不想与 Backend 交互,可以这样初始化工作目录:
1 | $ terraform init -backend=false |
要验证特定运行上下文中的配置(特定目标工作空间、输入变量值等),请改用 terraform plan 命令,其中包括隐式验证检查。
1.7.20.1.1. 用法
terraform validate [options]
默认情况下 validate 命令不需要任何参数就可以在当前工作目录下进行检查。
可以使用如下可选参数:
- -json:使用 JSON 格式输出机器可读的结果
- -no-color:禁止使用彩色输出
1.7.20.1.2. JSON 输出格式
当您使用 -json 选项时,Terraform 将生成 JSON 格式的验证结果,使得我们可以将之与验证结果的工具进行集成,例如在文本编辑器中突出显示错误。
与所有 JSON 输出选项一样,Terraform 在开始验证任务之前就可能会遇到错误,因此输出的错误可能不会是 JSON 格式的。因此,使用 Terraform 输出的外部软件应该准备好在 stdout 上读取到非有效 JSON 的数据,然后将其视为一般错误情况。
输出包含一个 format_version 键,从 Terraform 1.1.0 开始,其值为“1.0”。该版本的语义是:
- 对于向后兼容的变更或新增字段,我们将增加 minor 版本号,例如
"1.1"。这种变更会忽略所有不认识的对象属性,以保持与未来其他 minor 版本的前向兼容。 - 对于不向后兼容的变更,我们将增加 major 版本,例如
"2.0"。不同的 major 版本之间的数据无法直接传递。
我们只会在 Terraform 1.0 兼容性承诺的范围内更新 major 版本。
在正常情况下,Terraform 会将 JSON 对象打印到标准输出流。顶级 JSON 对象将具有以下属性:
valid(bool):总体验证结果结论,如果 Terraform 认为当前配置有效,则为true;如果检测到任何错误,则为false。error_count(number):零或正整数,给出 Terraform 检测到的错误计数。如果valid为true,则error_count将始终为零,因为错误的存在表明配置无效。warning_count(number):零或正整数,给出 Terraform 检测到的警告计数。警告不会导致 Terraform 认为配置无效,但用户应考虑并尝试解决它们。diagnostics(对象数组):嵌套对象的 JSON 数组,每个对象描述来自 Terraform 的错误或警告。
diagnostics 中的对象拥有如下属性:
severity(string):字符串关键字,可以是"error"或"warning",指示诊断严重性。error的存在会导致 Terraform 认为配置无效,而warning只是对用户的建议或警告,不会阻止代码运行。Terraform 的后续版本可能会引入新的严重性等级,因此解析错误信息时应该准备好接受并忽略他们不了解的severity值。summary(string):诊断报告的问题性质的简短描述。
在 Terraform 易于阅读的的诊断消息中,summary 充当诊断的一种“标题”,打印在 “Error:” 或 “Warning:” 指示符之后。
摘要通常是简短的单个句子,但如果返回错误的子系统并没有设计成返回全面的诊断信息时,就只能把整个错误信息作为摘要返回,导致较长的摘要。这种情况下,摘要可能包含换行符,渲染摘要信息时需要注意。
detail(string):可选的附加消息,提供有关问题的更多详细信息。
在 Terraform 易于阅读的的诊断消息中,详细信息提供了标题和源位置引用之后出现的文本段落。
详细消息通常是多个段落,并且可能散布有非段落行,因此旨在向用户呈现详细消息的工具应该区分没有前导空格的行,将它们视为段落,以及有前导空格的行,将它们视为预格式化文本。然后,渲染器应该对段落进行软换行以适合渲染容器的宽度,但保留预格式化的行不换行。
一些 Terraform 详细消息包含使用 ASCII 字符来标记项目符号的近似项目符号列表。这不是官方承诺,因此渲染器应避免依赖它,而应将这些行视为段落或预格式化文本。此格式的未来版本可能会为其他文本约定定义附加规则,但将保持向后兼容性。
range(对象):引用与诊断消息相关的配置源代码的一部分的可选对象。对于错误,这通常指示被检测为无效的特定块头、属性或表达式的边界。
源范围是一个具有 filename 属性的对象,该 filename 为当前工作目录的相对路径,然后两个属性 start 和 end 本身都是描述源位置的对象,如下所述。
并非所有诊断消息都与配置的特定部分相关,因此对于不相关的诊断消息,range 将被省略或为 null。
snippet(对象):可选对象,包括与诊断消息相关的配置源代码的摘录。
snippet 信息包括了:
context(string):诊断的根上下文的可选摘要。例如,这可能是包含触发诊断的表达式的resource块。对于某些诊断,此信息不可用,并且此属性将为空。code(string):Terraform 配置的片段,包括诊断源。可能包含多行,并且可能包括触发诊断的表达式周围的附加配置源代码。start_line(number):从一开始的行计数,表示源文件中代码摘录开始的位置。该值不一定与range.start.line相同,因为code可能在诊断源之前包含一行或多行上下文。highlight_start_offset(number):代码字符串中从零开始的字符偏移量,指向触发诊断的表达式的开头。highlight_end_offset(number):代码字符串中从零开始的字符偏移量,指向触发诊断的表达式的末尾。values(对象数组):包含零个或多个表达式值,帮助我们理解复杂表达式中的诊断来源。这些表达式值对象如下所述。
1.7.20.1.2.1. 源位置(Source Position)
在诊断对象的 range 属性中源位置对象具有以下属性:
byte(number):指定文件中从零开始的字节偏移量。line(number):从一开始的行计数,指向文件中相关位置的行。column(number):从一开始的列计数,指向line对应的行开头开始的 Unicode 字符计数位置。start位置是包含的(数学的[]),而end位置是不包含的(数学的())。用于特定错误消息的确切位置仅供人类解读。
1.7.20.1.2.2. 表达式值
表达式值对象提供有关触发诊断的表达式一部分的值的附加信息。当使用 for_each 或类似结构时,这特别有用,以便准确识别哪些值导致错误。该对象有两个属性:
-
traversal(string):类似 HCL 的可遍历表达式字符串,例如var.instance_count。复杂的索引键值可能会被省略,因此该属性并非总是合法、可解析的 HCL。该字符串的内容旨在便于人类阅读。 -
statement(string):一个简短的英语片段,描述触发诊断时表达式的值。该字符串的内容旨在便于人类阅读,并且在 Terraform 的未来版本中可能会发生变化。
1.7.21.1. untaint
Terraform 有一个名为“tainted”的标记,用于跟踪可能损坏的对象,该命令已被废弃,应使用 terraform apply -replace 代替。
如果创建一个资源的操作由多个步骤组成,操作期间其中之一的操作发生错误,Terraform 会自动将对象标记为“受污染”,因为 Terraform 无法确定该对象是否处于完整功能状态。
terraform untaint 命令可以手动清除一个 Terraform 管理的资源对象上的污点,恢复它在状态文件中的状态。它是 terraform taint 的逆向操作。
该命令不会修改实际的基础设施资源,只会在资源文件中清除资源对象上的污点标记。
如果我们从对象中删除污点标记,但后来发现它还是损坏了,则可以使用如下命令创建并应用一个计划来替换受损的资源对象,而无需首先重新在该对象上标记污点:
1 | terraform apply -replace="aws_instance.example[0]" |
1.7.21.1.1. 用法
terraform untaint [options] address
name参数是要清除污点的资源的资源名称。该参数的格式为TYPE.NAME,比如aws_instance.foo。
可以使用如下可选参数:
-allow-missing:如果声明该参数,那么即使资源不存在,命令也会返回成功(状态码0)。对于其他异常情况,该命令可能仍会返回错误,例如读取或写入状态时出现问题。-lock=false:执行时是否先锁定状态文件。如果其他人可能同时对同一工作区运行命令,则这是危险的。-lock-timeout=DURATION:除非使用-lock=false禁用锁定,否则命令 Terraform 为上锁操作设置一个超时时长。持续时间语法是一个数字后跟一个时间单位字母,例如“3s”表示三秒。-no-color:关闭彩色输出。在无法解释输出色彩的终端中运行 Terraform 时请使用此参数。
以下是使用 local Backend 时可用的遗留参数:
-
-backup=FILENAME:指定源状态文件的备份地址,默认为源状态文件加上".backup"后缀 -
-bakcup-out=FILENAME:指定目标状态文件的备份地址,默认为目标状态文件加上".backup"后缀 -
-state=FILENAME:源状态文件地址,默认为当前 Backend 或是"terraform.tfstate" -
-state-out=FILENAME:目标状态文件地址。如果不指定则使用源状态文件。可以是一个已经存在的文件或新建一个文件
1.7.22.1. workspace
terraform workspace 命令可以用来管理当前使用的工作区。我们在状态管理章节中介绍过工作区的概念。
该命令包含一系列子命令,我们将会一一介绍。
1.7.22.1.1. 用法
terraform workspace <subcommand> [options] [args]
1.7.22.1.1. list
terraform workspace list 命令列出当前存在的工作区。
1.7.22.1.1.1. 用法
terraform workspace list [DIR]
该命令会打印出存在的工作区。当前工作会使用 * 号标记:
1 | $ terraform workspace list |
1.7.22.2.1. select
terraform workspace select 命令用来选择使用的工作区。
1.7.22.2.1.1. 用法
terraform workspace select NAME [DIR]
NAME 指定的工作区必须已经存在:
该命令支持以下参数
-or-create:如果指定的工作区不存在,则创建之。默认为false。
1 | $ terraform workspace list |
new
1.7.22.3.1. new
terraform workspace new 命令用来创建新的工作区。
1.7.22.3.1.1. 用法
terraform workspace new [OPTIONS] NAME [DIR]
该命令使用给定名字创建一个新的工作区。不可存在同名工作区。
如果使用了 -state 参数,那么给定路径的状态文件会被拷贝到新工作区。
该命令支持以下可选参数:
-lock=false:执行时是否先锁定状态文件。如果其他人可能同时对同一工作区运行命令,则这是危险的。-lock-timeout=DURATION:除非使用-lock=false禁用锁定,否则命令 Terraform 为上锁操作设置一个超时时长。持续时间语法是一个数字后跟一个时间单位字母,例如“3s”表示三秒。默认为0s。-state=path:用来初始化新环境所使用的状态文件路径
创建新工作区:
1 | $ terraform workspace new example |
使用状态文件创建新工作区:
1 | $ terraform workspace new -state=old.terraform.tfstate example |
delete
1.7.22.4.1. delete
terraform workspace delete 命令被用以删除已经存在的工作区。
1.7.22.4.1.1. 用法
terraform workspace delete [OPTIONS] NAME [DIR]
该命令被用以删除已经存在的工作区。
被删除的工作区必须已经存在,并且不可以删除当前正在使用的工作区。如果工作区状态不是空的(存在跟踪中的远程对象),Terraform 会禁止删除,除非声明 -force 参数。
另外,不同的 Backend 在没有 -force 参数时可能会有不同的限制,以实现对工作区的安全删除,例如检查工作区是否已上锁。
如果使用 -force 删除非空工作区,那么原本跟踪的资源的状态就将处于"dangling",也就是实际基础设施资源仍然存在,但脱离了 Terraform的 管理。有时我们希望这样,只是希望当前 Terraform 项目不再管理这些资源,交由其他项目管理。但大多数情况下并非这样,所以 Terraform 默认会禁止删除非空工作区。
该命令可以使用如下可选参数:
-force:删除含有非空状态文件的工作区。默认为false。-lock=false:执行时是否先锁定状态文件。如果其他人可能同时对同一工作区运行命令,则这是危险的。-lock-timeout=DURATION:除非使用-lock=false禁用锁定,否则命令 Terraform 为上锁操作设置一个超时时长。持续时间语法是一个数字后跟一个时间单位字母,例如“3s”表示三秒。默认为0s。
例子:
1 | $ terraform workspace delete example |
1.7.22.5.1. show
terraform workspace show 命令被用以输出当前使用的工作区。
1.7.22.5.1.1. 用法
terraform workspace show
例子:
1 | $ terraform workspace show |
1.7.23.1. test
terraform test 命令读取 Terraform 测试文件并执行其中的测试。
test 命令和测试文件对于想要验证和测试其旨在被复用的模块的作者特别有用。我们也可以使用 test 命令来验证根模块。
1.7.23.1.1. 用法
terraform test [options]
该命令在当前目录和指定的测试目录(默认情况下是 test 目录)中搜索所有 Terraform 测试文件,并执行指定的测试。有关测试文件的更多详细信息,请参阅测试。
Terraform 然后会根据测试文件的规范执行一系列 Terraform 的 plan 或 apply 命令,并根据测试文件的规范验证相关计划和状态文件。
警告:Terraform 测试命令可以创建真正的基础设施,但可能会产生成本。请参阅 Terraform 测试清理部分,了解确保创建的基础设施被清理的最佳实践。
1.7.23.1.2. 一般参数
Terraform test 命令支持以下参数:
-cloud-run=<module source>- 通过 HCP Terraform 远程运行针对指定的 Terraform 私有注册表模块的测试。-filter=testfile- 将terraform test操作限制为指定的测试文件。-json- 显示测试结果的机器可读 JSON 输出。-test-directory=<relative directory>- 指定 Terraform 查找测试文件的目录。请注意,Terraform 始终在主代码目录中加载测试文件。默认的测试目录是tests。-verbose- 根据每个运行块的command属性打印出测试文件中每个run块的计划或状态。
1.7.23.1.3. 状态管理
每个 Terraform 测试文件在执行时都会在内存中从无到有地维护所需的所有 Terraform 状态。该状态完全独立于被测代码的任何现有状态,因此您可以安全地执行 Terraform 测试命令,而不会影响任何已存在的基础设施。
1.7.23.1.3.1. Terraform 测试清理
Terraform test 命令可以创建真实的基础设施。一旦 Terraform 完全执行了所有测试文件,Terraform 就会尝试销毁所有遗留的基础设施。如果无法销毁,Terraform 会报告由它创建但无法销毁的资源列表。
我们应该密切监视测试命令的输出,以确保 Terraform 清理了它创建的基础设施,否则需要执行手动清理。我们建议为目标 Provider 创建专用的测试帐户,这样可以定期安全地清除该帐户内的资源,确保不会意外地留下昂贵的资源。
Terraform 还提供诊断,解释为什么它无法自动清理。我们应该检查这些诊断,以确保未来的清理操作成功。
1.7.23.1.4. 在 HCP Terraform 上运行测试
我们可以使用 -cloud-run 参数在 HCP Terraform 上远程执行测试。
-cloud-run 参数接受私有注册表模块地址。此参数针对 HCP Terraform 用户界面中指定的私有模块运行测试。
我们必须提供来自私有注册表的模块,而不是公共 Terraform 注册表。
在使用该参数之前,您必须执行 terraform login,并确保您的 host 参数与目标模块的私有注册表主机名匹配。
1.7.23.1.5. 例子:测试的目录结构与命令
以下目录结构表示包含测试和配置(setup)模块的 Terraform 模块的示例目录树:
1 | project/ |
在项目的根目录下,有一些典型的 Terraform 配置文件:main.tf、outputs.tf、terraform.tf 和 variables.tf。测试文件 validations.tftest.hcl 和 outputs.tftest.hcl 位于默认测试目录 tests 中。
另外 testing 目录下有一个为测试而存在的设置(setup)模块
要执行测试,我们应该从代码根目录运行 terraform test,如同运行 terraform plan 或 terraform apply 一样。尽管实际的测试文件位于内嵌的 tests 目录中,但 Terraform 仍从主代码目录执行。
可以使用 -filter 参数指定执行特定的测试文件。
Linux、Mac 操作系统和 UNIX 下:
1 | terraform test -filter=tests/validations.tftest.hcl |
PowerShell:
1 | terraform test -filter='tests\validations.tftest.hcl' |
Windows cmd.exe:
1 | terraform test -filter=tests\validations.tftest.hcl |
1.7.23.1.5.1. 另一种测试目录结构
在上面的示例中,测试文件位于默认的 tests 目录中。测试文件也可以直接包含在主代码目录中:
1 | project/ |
测试文件的位置不会影响 terraform test 的运行。测试文件的所有引用以及其中的绝对文件路径都应相对于主代码目录。
我们还可以使用 -test-directory 参数来更改测试文件的位置。例如, terraform test -test-directory=testing 将命令 Terraform 从 testing 目录加载测试,而不是 tests。
测试目录必须位于主代码目录下,但可以多层嵌套。
注意:无论
-test-directory的值为何,根代码目录中的测试文件始终会被加载。
我们不建议更改默认测试目录。这些自定义选项是为那些在 terraform test 功能发布之前可能已在其代码中包含了 tests 子模块的代码作者准备的。一般来说,应始终使用默认的 tests 目录。
1.7.1. Terraform命令行
我们在前面的的章节中主要介绍了如何书写和组织Terraform代码,下面我们要介绍一下如何使用Terraform命令行工具来应用这些代码,并且管理和操作我们的云端基础设施。
Terraform是用Go语言编写的,所以它的交付物只有一个可执行命令行文件:terraform。在Terraform执行发生错误时,terraform进程会返回一个非零值,所以在脚本代码中我们可以轻松判断执行是否成功。
我们可以在命令行中输入terraform来查看所有可用的子命令:
1 | $ terraform |
1.7.1.1. 通过 -chdir 参数切换工作目录
运行Terraform时一般要首先切换当前工作目录到包含有想要执行的根模块.tf代码文件的目录下(比如使用cd命令),这样Terraform才能够自动发现要执行的代码文件以及参数文件。
在某些情况下——尤其是将Terraform封装进某些自动化脚本时,如果能够从其他路径直接执行特定路径下的根模块代码将会十分的方便。为了达到这一目的,Terraform目前支持一个全局参数-chdir=...,你可以在任意子命令的参数中使用该参数指定要执行的代码路径:
1 | terraform -chdir=environments/production apply |
-chdir参数指引Terraform在执行具体子命令之前切换工作目录,这意味着使用该参数后Terraform将会在指定路径下读写文件,而非当前工作目录下的文件。
在两种场景下Terraform会坚持使用当前工作目录而非指定的目录,即使是我们通过-chdir指定了一个目标路径:
- Terraform处理命令行配置文件中的设置而非执行某个具体的子命令时,该阶段发生在解析
-chdir参数之前 - 如果你需要使用当前工作目录下的文件作为你配置的一部分时,你可以通过在代码中使用
path.cwd变量获得对当前工作路径的引用,而不是-chdir所指定的路径。可以通过使用path.root来获取代表根模块所在的路径。
1.7.1.2. 自动补全
如果你使用的是bash或是zsh,那么可以轻松安装自动补全:
1 | $ terraform -install-autocomplete |
卸载自动补全也很容易:
1 | $ terraform -uninstall-autocomplete |
目前自动补全并没有覆盖到所有子命令。
1.7.1.3. 版本信息
Terraform命令行会与HashiCorp的Checkpoint服务交互来检查当前版本是否有更新或是关键的安全公告。
可以通过执行terraform version命令来检查是否有新版本可用。
1.7.1.4. Checkpoint服务
Terraform会收集一些不涉及用户身份信息或是主机信息的数据发送给Checkpoint服务。一个匿名ID会被发送到Checkpoint来消除重复的告警信息。我们可以关闭与Checkpoint的交互。
我们可以设置CHECKPOINT_DISABLE环境变量的值为任意非空值来完全关闭HashiCorp所有产品与Checkpoint的交互。另外,我们也可以通过设置命令行配置文件来关闭这些功能:
-
disable_checkpoint:设置为true可以完全关闭与Checkpoint的交互
-
disable_checkpoint_signature:设置为true可以阻止向Checkpoint发送匿名ID
1.7.1.1. 命令行配置文件(.terraformrc 或 terraform.rc)
命令行配置文件为每个用户配置了命令行的行为,适用于所有的 Terraform 工作目录,这与我们编写的 Terraform 代码是分开的。
1.7.1.1.1. 位置
配置文件的位置取决于用户使用的操作系统:
- Windows 平台上,文件名必须是
terraform.rc,位置必须在相关用户的%APPDATA%目录下。这个目录的物理路径取决于 Windows 的版本以及系统配置;在 PowerShell 中查看$env:APPDATA可以找到对应的路径 - 在其他操作系统上,文件名必须是
.terraformrc(注意第一个是.),位置必须是在相关用户的HOME目录
在 Windows 上创建配置文件时,要注意 Windows Explorer 默认隐藏文件扩展名的行为。Terraform 不会把 terraform.rc.txt 文件识别为命令行配置文件,而默认情况下 Windows Explorer 会将它的文件名显示为 terraform.rc (隐藏了扩展名的缘故)。可以在 PowerShell 或命令行中使用 dir 命令来确认文件名。
可以通过设置 TF_CLI_CONFIG_FILE 环境变量的方式来修改配置文件的位置。
1.7.1.1.2. 配置文件语法
配置文件本身如同 .tf 文件那样也采用HCL语法,但使用不同的属性和块。以下是常见语法的演示,后续的部分会详细介绍这些配置项:
1 | plugin_cache_dir = "$HOME/.terraform.d/plugin-cache" |
1.7.1.1.3. 可用配置
命令行配置文件中可以设置的配置项有:
credentials:使用 Terraform Cloud 服务或 Terraform 企业版时使用的凭据credentials_helper:配置一个外部的用于读写 Terraform Cloud 或 Terraform 企业版凭据的帮助程序disable_checkpoint:设置为true可以完全关闭与 Checkpoint 的交互disable_checkpoint_signature:设置为true可以阻止向 Checkpoint 发送匿名 IDplugin_cache_dir:开启插件缓存,我们在介绍 Provider 的章节中介绍过provider_installation:定制化执行terraform init时安装插件的行为
鉴于本教程无意涉及与 Terraform Cloud 或企业版相关的部分,所以我们会略过对 credentials 和 credentials_helper 的介绍;插件缓存的相关知识我们在 Provider 章节中已做过介绍,在此先偷懒略过。感兴趣的读者可以自行查阅相关文档
1.7.1.1.4. Provider 的安装
默认情况下 Terraform 从官方 Provider Registry 下载安装 Provider 插件。Provider 在 Registry 中的原始地址采用类似 registry.terraform.io/hashicorp/aws 的编码规则。通常为了简便,Terraform 允许省略地址中的主机名部分 registry.terraform.io,所以我们可以直接使用地址 hashicorp/aws。
有时无法直接从官方 Registry 下载插件,例如我们要在一个与公网隔离的环境中运行 Terraform 时。为了允许 Terraform 工作在这样的环境下,有一些可选方法允许我们从其他地方获取 Provider 插件。
1.7.1.1.4.1. 显式安装方法配置
可以在命令行配置文件中定义一个 provider_installation 块来修改 Terraform 默认的插件安装行为,命令 Terraform 使用本地的 Registry 镜像服务,或是使用一些用户修改过的插件。
通常 provider_installation 块的结构如下:
1 | provider_installation { |
provider_installation 块中每一个内嵌块都指定了一种安装方式。每一种安装方式都可以同时包含 include 与 exclude 模式来指定安装方式使用的 Provider 类型。在上面的例子里,我们把所有原先位于 example.com 这个 Registry 存储中的 Provider 设置成只能从本地文件系统的 /usr/share/terraform/providers 镜像存储中寻找并安装,而其他的 Provider 只能从它们原先的 Registry 存储下载安装。
如果你为一种安装方式同时设置了 include 与 exclude,那么 exclude 模式将拥有更高的优先级。举例:包含registry.terraform.io/hashicorp/*但排除registry.terraform.io/hashicorp/dns将对所有hashicorp空间下的插件有效,但是hashicorp/dns除外。
和Terraform代码文件中Provider的source属性一样的是,在provider_installation里你也可以省略registry.terraform.io/的前缀,甚至是使用通配符时亦是如此。比如,registry.terraform.io/hashicorp/*和hashicorp/*是等价的;*/*是registry.terraform.io/*/*的缩写,而不是*/*/*的缩写。
目前支持的安装方式如下:
direct:要求直接从原始的Registry服务下载。该方法不需要额外参数。filesystem_mirror:一个本地存有 Provider 插件拷贝的目录。该方法需要一个额外的参数path来指定存有插件拷贝的目录路径。 Terraform 期待给定路径的目录内通过路径来描述插件的一些元信息。支持一下两种目录结构:- 打包式布局:
HOSTNAME/NAMESPACE/TYPE/terraform-provider-TYPE_VERSION_TARGET.zip的格式指定了一个从原始 Registry 获取的包含插件的发行版 zip 文件 - 解压式布局:
HOSTNAME/NAMESPACE/TYPE/VERSION/TARGET式一个包含有 Provider 插件发行版 zip 文件解压缩后内容物的目录 这两种布局下,VERSION都是代表着插件版本的字符串,比如2.0.0;TARGET则指定了插件发行版对应的目标平台,例如darwin_amd64、linux_arm、windows_amd64等等。
- 打包式布局:
如果使用解压式布局,Terraform 在安装插件时会尝试创建一个到镜像目录的符号连接来避免拷贝文件夹。打包式布局则不会这样做,因为 Terraform 必须在安装插件时解压发行版文件。
你可以指定多个filesystem_mirror块来指定多个不同的目录。
network_mirror:指定一个 HTTPS 服务地址提供 Provider 插件的拷贝,不论这些插件原先属于哪些 Registry 服务。该方法需要一个额外参数url来指定镜像服务的地址,url地址必须使用https:作为前缀,以斜杠结尾。 Terraform期待该地址指定的服务实现了 Provider网络镜像协议,这是一种被设计用来托管插件拷贝的网站所需要实现的协议,在此我们不展开讨论。
需要特别注意的是,请不要使用不可信的 network_mirror 地址。Terraform 会验证镜像站点的 TLS 证书以确认身份,但一个拥有合法 TLS 证书的镜像站可能会提供包含恶意内容的插件文件。
dev_overrides:指定使用本地的开发版本插件。有时我们想要对 Provider 代码做一些修改,为了调试本地代码编译后的插件,可以使用dev_overrides指定使用本地编译的版本。
例如,我们想要调试本地修改过的 UCloud Provider 插件,我们可以从 github 上克隆该项目源代码,修改完代码后,编译一个可执行版本(以Mac OS为例):
1 | $ GOOS=darwin GOARCH=arm64 go build -o bin/terraform-provider-ucloud |
然后编写如下provider_installation配置:
1 | provider_installation{ |
当 Terraform 代码中要求了 source 为 ucloud/ucloud 的 Provider 时,执行 terraform init 仍然会报错,抱怨找不到 ucloud/ucloud 这个 Provider,但执行 terraform plan 或是 terraform apply 等操作时可以顺利执行,此时 Terraform 会使用路径指定的本地 Provider 插件。这种方式比较适合于调试本地 Provider 插件代码。
对于上述的几种插件安装方式,Terraform 会尝试通过 include 和 exclude 模式匹配 Provider,遍历匹配的安装方式,选择一个符合 Terraform 代码中对插件版本约束的最新版本。如果你拥有一个插件的特定版本的本地镜像,并且你希望 Terraform 只使用这个本地镜像,那么你需要移除 direct 安装方式,或是在 direct 中通过exclude 参数排除特定的 Provider。
1.7.1.1.5. 隐式的本地镜像目录
如果命令行配置文件中没有包含 provider_installation 块,那么 Terraform 会生成一个隐式的配置。该隐式配置包含了一个 filesystem_mirror 方法以及一个 direct 方法。
在不同的操作系统上,Terraform 会选择不同的路径作为隐式 filesystem_mirror 路径:
- Windows:
%APPDATA%/terraform.d/plugins以及%APPDATA%/HashiCorp/Terraform/plugins - Mac OS X:
$HOME/.terraform.d/plugins/,~/Library/Application Support/io.terraform/plugins以及/Library/Application Support/io.terraform/plugins - Linux 以及其他 Unix 风格系统:
$HOME/.terraform.d/plugins/,以及配置的 XDG 基础目录后接terraform/plugins。如果没有设置 XDG 环境变量,Terraform 会使用~/.local/share/terraform/plugins,/usr/local/share/terraform/plugins,以及/usr/share/terraform/plugins
Terraform 会在启动时为上述路径的每一个目录创建一个隐式 filesystem_mirror 块。另外如果当前工作目录下包含有 terraform.d/plugins 目录,那么也会为它创建一个隐式 filesystem_mirror 块。
相对于任意多个隐式 filesystem_mirror 块,Terraform 同时也会创建一个隐式 direct 块。Terraform 会扫描所有文件系统镜像目录,对找到的 Provider 自动从 direct 块中排除出去(这种自动的 exclude 行为只对隐式 direct 块有效。如果你在 provider_installation 块中显式指定了 direct 块,那么你需要自己显式定义 exclude 规则)。
TODO:https://developer.hashicorp.com/terraform/cli/config/config-file#provider-plugin-cache
1.7.1.1.6. Provider 插件缓存
1.7.1.1.7. 允许 Provider 缓存跳过依赖锁文件检查
1.7.2.1. 环境变量
Terraform使用一系列的环境变量来定制化各方面的行为。如果只是想简单使用Terraform,我们并不需要设置这些环境变量;但他们可以在一些不常见的场景下帮助我们改变Terraform的默认行为,或者是出于调试目的修改输出日志的级别。
1.7.2.1.1. TF_LOG
该环境变量可以设定 Terraform 内部日志的输出级别,例如:
1 | $ export TF_LOG=TRACE |
Terraform 日志级别有 TRACE、DEBUG、INFO、WARN 和 ERROR。TRACE 包含的信息最多也最冗长,如果 TF_LOG 被设定为这五级以外的值时 Terraform 会默认使用 TRACE。
如果在使用 Terraform 的过程中遇到未知的错误并怀疑是 Terraform 或相关插件的 bug,请设置 TF_LOG 级别后收集输出的日志并提交给相关人员。
有志于获取 Terraform 认证的读者请注意,该知识点近乎属于必考。
1.7.2.1.2. TF_LOG_PATH
该环境变量可以设定日志文件保存的位置。注意,如果TF_LOG_PATH被设置了,那么 TF_LOG 也必须被设置。举例来说,想要始终把日志输出到当前工作目录,我们可以这样:
1 | $ export TF_LOG_PATH=./terraform.log |
1.7.2.1.3. TF_INPUT
该环境变量设置为 "false" 或 "0" 时,等同于运行 Terraform 相关命令行命令时添加了参数 -input=false。如果你想在自动化环境下避免 Terraform 通过命令行的交互式提示要求给定输入变量的值而是直接报错时(无 default 值的输入变量,无法通过任何途径获得值)可以设置该环境变量:
1 | $ export TF_INPUT=0 |
1.7.2.1.4. TF_VAR_name
我们在介绍输入变量赋值时介绍过,可以通过设置名为 TF_VAR_name 的环境变量来为名为 "name" 的输入变量赋值:
1 | $ export TF_VAR_region=us-west-1 |
1.7.2.1.5. TF_CLI_ARGS 以及 TF_CLI_ARGS_name
TF_CLI_ARGS 的值指定了附加给命令行的额外参数,这使得在自动化 CI 环境下可以轻松定制 Terraform 的默认行为。
该参数的值会被直接插入在子命令后(例如 plan)以及通过命令行指定的参数之前。这种做法确保了环境变量参数优先于通过命令行传递的参数。
例如,执行这样的命令:TF_CLI_ARGS="-input=false" terraform apply -force,它等价于手工执行 terraform apply -input=false -force。
TF_CLI_ARGS 变量影响所有的 Terraform 命令。如果你只想影响某个特定的子命令,可以使用 TF_CLI_ARGS_name 变量。例如:TF_CLI_ARGS_plan="-refresh=false",就只会针对 plan 子命令起作用。
该环境变量的值会与通过命令行传入的参数一样被解析,你可以在值里使用单引号和双引号来定义字符串,多个参数之间以空格分隔。
1.7.2.1.6. TF_DATA_DIR
TF_DATA_DIR 可以修改 Terraform 保存在每个工作目录下的数据的位置。一般来说,Terraform 会把这些数据写入当前工作目录下的 .terraform 文件夹内,但这一位置可以通过设置 TF_DATA_DIR 来修改。
大部分情况下我们不应该设置该变量,但有时我们不得不这样做,比如默认路径下我们无权写入数据时。
该数据目录被用来保存下一次执行任意命令时需要读取的数据,所以必须被妥善保存,并确保所有的 Terraform 命令都可以一致地读写它,否则 Terraform 会找不到 Provider 插件、模块代码以及其他文件。
1.7.2.1.7. TF_WORKSPACE
多环境部署时,可以使用此环境变量而非 terraform workspace select your_workspace 来切换 workspace。使用 TF_WORKSPACE 允许设置使用的工作区。
比如:
1 | export TF_WORKSPACE=your_workspace |
建议仅在非交互式使用中使用此环境变量,因为在本地 shell 环境中,很容易忘记设置了该变量并将变更执行到错误的环境中。
可以在这里阅读工作区的更多信息。
1.7.2.1.8. TF_IN_AUTOMATION
如果该变量被设置为非空值,Terraform 会意识到自己运行在一个自动化环境下,从而调整自己的输出以避免给出关于该执行什么子命令的建议。这可以使得输出更加一致且减少非必要的信息量。
1.7.2.1.9. TF_REGISTRY_DISCOVERY_RETRY
该变量定义了尝试从 registry 拉取插件或模块代码遇到错误时的重试次数。
1.7.2.1.10. TF_REGISTRY_CLIENT_TIMEOUT
该变量定义了发送到 registry 连接请求的超时时间,默认值为 10 秒。可以这样设置超时:
1 | $ export TF_REGISTRY_CLIENT_TIMEOUT=15 |
1.7.2.1.11. TF_CLI_CONFIG_FILE
该变量设定了 Terraform 命令行配置文件的位置:
1 | $ export TF_CLI_CONFIG_FILE="$HOME/.terraformrc-custom" |
1.7.2.1.12. TF_PLUGIN_CACHE_DIR
TF_PLUGIN_CACHE_DIR 环境变量是配置插件缓存目录的另一种方法。你也可以使用 TF_PLUGIN_CACHE_MAY_BREAK_DEPENDENCY_LOCK_FILE 环境变量设置 plugin_cache_may_break_dependency_lock_file 配置项
1.7.2.1.13. TF_IGNORE
如果 TF_IGNORE 设置为 "trace",Terraform 会在调试信息中输出被忽略的文件和目录。该配置与 .terraformignore 文件搭配时对调试大型代码仓库相当有用:
1 | export TF_IGNORE=trace |
1.7.3.1. 资源地址
在编码时我们有时会需要引用一些资源的输出属性或是一些模块的输出值,这都涉及到如何在代码中引用特定模块或是资源。另外在执行某些命令行操作时也需要我们显式指定一些目标资源,这时我们要掌握Terraform的资源路径规则。
一个资源地址是用以在一个庞大的基础设施中精确引用一个特定资源对象的字符串。一个地址由两部分组成:[module path][resource spec]。
1.7.3.1.1. 模块路径
一个模块路径在模块树上定位了一个特定模块。它的形式是这样的:module.module_name[module index]
module:module关键字标记了这时一个子模块而非根模块。在路径中可以包含多个module关键字module_name:用户定义的模块名[module index]:(可选)访问多个子模块中特定实例的索引,由方括号包围
一个不包含具体资源的地址,例如 module.foo 代表了模块内所有的资源(如果只是单个模块而不是多实例模块),或者是多实例模块的所有实例。要指代特定模块实例的所有资源,需要在地址中附带下标,例如 module.foo[0]。
如果地址中模块部分被省略,那么地址就指代根模块资源。
这里有一个包含多个 module 关键字应用于多实例模块的例子:module.foo[0].module.bar["a"]。
要注意的是,由于模块的 count 和 for_each 元参数是 Terraform 0.13 开始引进的,所以多实例模块地址也只能在 0.13 及之后的版本使用。
1.7.3.1.2. 资源地址形式
一个资源地址定位了代码中特定资源对象,它的形式是这样的:resource_type.resource_name[resource index]
resource_type:资源类型resource_name:用户定义的资源名称[resource index]:(可选)访问多实例资源中特定资源实例的索引,由方括号包围
1.7.3.1.3. 多实例模块与资源的访问索引
以下规约适用于访问多实例模块及资源时使用的索引值:
[N]:当使用count元参数时N是一个自然数。如果省略,并且count> 1,那么指代所有的实例["INDEX"]:当使用for_each元参数时INDEX是一个字母数字混合的字符串
1.7.3.1.4. 例子
1.7.3.1.4.1. count 的例子
给定一个代码定义:
1 | resource "aws_instance" "web" { |
给定一个地址:aws_instance.web[3],它指代的是最后一个名为 web 的 aws_instance 实例;给定地址 aws_instance.web,指代的是所有名为 web 的 aws_instance 实例。
1.7.3.1.4.2. for_each 的例子
给定如下代码:
1 | resource "aws_instance" "web" { |
地址 aws_instance.web["example"] 引用的是 aws_instance.web 中键为 "example" 的实例。
1.7.4.1. apply
Terraform 最重要的命令就是 apply。apply 命令可以生成执行计划(可选)并执行之,使得基础设施资源状态符合代码的描述。
1.7.4.1.1. 用法
terraform apply [options] [plan file]
Terraform 的 Apply 有两种模式:自动 Plan 模式以及既有 Plan 模式。
1.7.4.1.2. 自动 Plan 模式
当我们运行 terraform apply 而不指定计划文件时,Terraform 会自动创建一个新的执行计划,就像我们已运行 terraform plan 一样,提示我们批准该计划,并采取指示的操作。我们可以使用所有 plan 模式和 plan 选项来自定义 Terraform 创建计划的方式。
我们可以设置 -auto-approve 选项来要求 Terraform 跳过确认直接执行计划。
警告:如果使用 -auto-approve,建议确保没有人可以在 Terraform 工作流程之外更改我们的基础设施。这可以最大限度地降低不可预测的变更和配置漂移的风险。
1.7.4.1.3. 既有 Plan 模式
当您将既有的计划文件传递给 terraform apply 时,Terraform 会执行既有的计划中的操作,而不提示确认。在自动化运行 Terraform 时,可能需要使用由这样的两个步骤组成的工作流。
我们在应用计划之前可以使用 terraform show 检查既有的计划文件。
使用既有的计划时,我们无法指定任何其他计划模式或选项。这些选项只会影响 Terraform 关于采取哪些操作的决策,而这些决策的最终结果已经在计划文件中包含了。
1.7.4.1.4. Plan 参数
在未提供既有计划文件时,terraform apply 命令支持 terraform plan 命令所支持的所有 Plan 模式参数以及 Plan 选项参数。
- Plan 模式参数:包括
-destroy(创建销毁所有远程对象的计划)和-refresh-only(创建更新 Terraform 状态和根模块输出值的计划)。 - Plan 选项参数:包括指定 Terraform 应替换哪些资源实例、设置 Terraform 输入变量等的参数。
1.7.4.1.5. Apply 参数
下面的参数可以更改 apply 命令的执行方式和 apply 操作生成的报告格式。
-auto-approve:跳过交互确认步骤,直接执行变更。此选项将被忽略,因为 Terraform 认为我们指定了计划文件即已批准执行,因此在这种情况下永远不会提示。-compact-warnings:以紧凑的形式显示所有警告消息,其中仅包含摘要消息,除非输出信息中存在至少一个错误,因此警告文本中可能包含有错误的上下文信息。-input=true:禁用 Terraform 的所有交互式提示。请注意,这也会阻止 Terraform 提示交互式批准计划,这时 Terraform 将保守地假设您不希望应用该计划,从而导致操作失败。如果您希望在非交互式上下文中运行 Terraform,请参阅 Terraform 与自动化 了解一些不同的方法。-json:启用机器可读的 JSON UI 输出。这意味着-input=false,因此配置variable值都已赋值才能继续。要启用此参数,您还必须启用-auto-approve标志或指定既有的计划文件。-lock=false:执行时是否先锁定状态文件。如果其他人可能同时对同一工作区运行命令,则这是危险的。-lock-timeout=DURATION:除非使用-lock=false禁用锁定,否则命令 Terraform 为上锁操作设置一个超时时长。持续时间语法是一个数字后跟一个时间单位字母,例如“3s”表示三秒。-no-color:关闭彩色输出。在无法解释输出色彩的终端中运行 Terraform 时请使用此参数。-parallelism=n:限制 Terraform 遍历图时的最大并行度,默认值为10(考试高频考点)
当配置中只使用了 local Backend 时,terraform apply 还支持以下三个遗留参数:
-backup-path:保存备份文件的路径。默认等于-state-out参数后加上".backup"后缀。设置为"-"可关闭-state=path:保存状态文件的路径,默认值是"terraform.tfstate"。如果使用了远程 Backend 该参数设置无效。该参数不影响其他命令,比如执行init时会找不到它设置的状态文件。如果要使得所有命令都可以使用同一个特定位置的状态文件,请使用 Local Backend-state-out=path:写入更新的状态文件的路径,默认情况使用-state的值。该参数在使用远程 Backend 时设置无效
1.7.4.1.6. 指定其他配置文件目录
Terraform v0.13 及更早版本接受提供目录路径的附加位置参数,在这种情况下,Terraform 将使用该目录作为根模块而不是当前工作目录。
该用法在 Terraform v0.14 中已弃用,并在 Terraform v0.15 中删除。如果您的工作流程需要修改根模块目录,请改用 -chdir 全局选项,该选项适用于所有命令,并使 Terraform 始终在给定目录中查找它通常在当前工作目录中读取或写入的所有文件。
如果我们之前使用此遗留模式时同时需要 Terraform 将 .terraform 子目录写入当前工作目录,即使根模块目录已被覆盖,请使用 TF_DATA_DIR 环境变量命令 Terraform 将 .terraform 目录写入其他位置,而不是当前工作目录。
1.7.5.1. console
有时我们想要一个安全的调试工具来帮助我们确认某个表达式是否合法,或者表达式的值是否符合预期,这时我们可以使用 terraform console 启动一个交互式控制台。
1.7.5.1.1. 用法
terraform console [options] [options]
console 命令提供了一个用以执行和测试各种表达式的命令行控制台。在编码时如果我们不确定某个表达式的最终结果时(例如使用字符串模版),我们可以在这个控制台中搭配当前状态文件中的数据进行各种测试。
如果当前状态是空的或还没有创建状态文件,那么控制台可以用来测试各种表达式语法以及内建函数。假如当前根模块有状态,console 命令将会对状态加锁,这使得我们无法在运行其他可能会修改状态的操作时使用 console 命令。
在控制台中可以使用 exit 命令或是 Ctrl-C 或是 Ctrl-D 退出。
当使用的是 local Backend 时,terraform console 可以使用 -state 遗留参数:
-state=path:指向本机状态文件的路径。表达式计算会使用该状态文件中记录的值。如果没有指定,则会使用当前工作区(Workspace)关联的状态文件
1.7.5.1.2. 脚本化
terraform console 命令可以搭配非交互式脚本使用,可以使用管道符将其他命令输出接入控制台执行。如果没有发生错误,只有最终结果会被打印。
样例:
1 | echo 'split(",", "foo,bar,baz")' | terraform console |
1.7.5.1.3. 远程状态
如果使用了远程 Backend 存储状态,Terraform 会从远程 Backend 读取当前工作区的状态数据来计算表达式。
1.7.5.1.4. 搭配既有计划文件运行
默认情况下,terraform console 根据当前 Terraform 状态计算表达式,因此对于尚未通过 Apply 创建的资源实例,结果通常非常有限。
您可以使用 -plan 选项首先生成执行计划,就像运行 terraform plan 一样,然后根据计划的状态进行计算,以描述 Terraform 期望在应用计划后应得的值。这通常会在控制台提示出现之前引发更长的延迟,但作为回报,可知的表达式范围中将有一组更完整的可用值。
一个好的 Terraform 配置代码,在 Plan 阶段不应对实际远程对象进行任何修改,但我们可以编写一个在 Plan 时可以执行重要操作的配置。例如,使用 hashcorp/external Provider 程序的 external 数据源的配置可能会在 Plan 阶段运行设置的的外部命令,这意味着该外部命令也会被 terraform console -plan 运行。
我们不建议编写在 Plan 阶段进行更改的配置。如果您不顾该建议而编写了此类配置,则在 Plan 模式下针对该配置使用控制台时请务必小心。
1.7.5.1.5. 例子
terraform console 命令将从配置的 Backend 读取当前工作目录中的 Terraform 配置和 Terraform 状态文件,以便可以根据配置和状态文件中的值计算表达式。
假设我们有如下的 main.tf:
1 | variable "apps" { |
执行 terraform console 会进入交互式 shell,我们可以在其中计算表达式:
打印一个 map:
1 | > var.apps.foo |
根据给定值过滤 map:
1 | > { for key, value in var.apps : key => value if value.region == "us-east-1" } |
确认特定值是否为尚不知晓(Known after apply)值:
1 | > random_pet.example |
测试各种函数:
1 | > cidrnetmask("172.16.0.0/12") |
destroy
1.7.6.1. destroy
terraform destroy 命令可以用来销毁并回收所有由 Terraform 配置所管理的基础设施资源。
虽然我们一般不会删除长期存在于生产环境中的对象,但有时我们会用 Terraform 管理用于开发目的的临时基础设施,在这种情况下,您可以在完成后使用 terraform destroy 来方便地清理所有这些临时资源。
1.7.6.1.1. 用法
terraform destroy [options]
该命令是以下命令的快捷方式:
1 | terraform apply -destroy |
因此,此命令接受 terraform apply 所支持的大部分选项,但是它不支持 -destroy 模式搭配指定计划文件的用法。
我们还可以通过运行以下命令创建推测性销毁计划,以查看销毁的效果:
1 | terraform plan -destroy |
该命令会以 destroy 模式运行 terraform plan 命令,显示准备要销毁的变更,但不予执行。
注意:terraform apply 的 -destroy 选项仅存在于 Terraform v0.15.2 及更高版本中。对于早期版本,必须使用 terraform destroy 才能获得 terraform apply -destroy 的效果。
1.7.7.1. fmt
terraform fmt 命令被用来格式化 Terraform 代码文件的格式和规范。该命令会对代码文件应用我们之前介绍过的代码风格规范中的一些规定,另外会针对可读性对代码做些微调整。
其他具有生成Terraform代码文件功能的命令会按照terraform fmt的标准来生成代码,所以请在项目中遵循fmt的代码风格以保持代码风格的统一。
其他那些会生成 Terraform 代码的 Terraform 命令,生成的代码都会符合 terraform fmt 所强制推行的格式,因此对我们自己编写的文件使用该命令可以保持所有代码风格的一致。
Terraform 不同版本的代码风格规范会有些微不同,所以在升级 Terraform 后我们建议要对代码执行一次 terraform fmt。
我们不会将修改 terraform fmt 执行的格式规则视作是 Terraform 新版本的破坏性变更(意为,不同版本的 terraform fmt 可能会对代码做不同的格式化),但我们的目标是最大限度地减少对那些已符合 Terraform 文档中显示的样式示例的代码的更改。添加新的格式规则时,他们通常会按照文档中代码示例中展示的新规则来制定,因此我们建议遵循文档中的样式,即使这些文档中的样式尚未被 terraform fmt 强制执行。
格式化决定始终是主观的,因此您可能不同意 terraform fmt 做出的决定。该命令是被设计成固执己见的,并且没有自定义选项,因为它的主要目标是鼓励不同 Terraform 代码库之间风格的一致性,即使所选的风格永远不可能是每个人都喜欢的。
我们建议代码作者在编写 Terraform 模块时遵循 terraform fmt 应用的样式约定,但如果您发现结果特别令人反感,那么您可以选择不使用此命令,并可能选择使用第三方格式化工具。如果您选择使用第三方工具,那么您还应该在 Terraform 自动生成的文件上运行它,以获得手写文件和生成文件之间的一致性。
1.7.7.1.1. 用法
terraform fmt [options] [target...]
默认情况下,fmt 会扫描当前文件夹以寻找代码文件。如果 [target...] 参数指向一个目录,那么 fmt 会扫描该目录。如果 [target...] 参数是一个文件,那么 fmt 只会处理那个文件。如果 [target...] 参数是一个减号(-),那么 fmt 命令会从标准输入中读取(STDIN)。
该命令支持以下参数:
-
-list=false:不列出包含不一致风格的文件 -
-write=false:不要重写输入文件(通过-check参数实现,或是使用标准输入流时) -
-diff:展示格式差异 -
-check:检查输入是否合规。返回状态码 0 则代表所有输入的代码风格都是合规,反之则不是 0,并且会打印一份包含了文件内容不合规的文件名清单。 -
-recursive:是否递归处理所有子文件夹。默认情况下为false(只有当前文件夹会被处理,不涉及内嵌子模块)
1.7.8.1. force-unlock
手动解除状态锁。
这个命令不会修改你的基础设施,它只会删除当前工作区对应的状态锁。具体操作步骤取决于使用的 Backend。本地状态文件无法被其他进程解锁。
1.7.8.1.1. 用法
terraform force-unlock [options] LOCK_ID
参数:
-force=true:解锁时不提示确认
需要注意的是,就像我们在状态管理篇当中介绍过的那样,每一个状态锁都有一个锁 ID。Terraform 为了确保我们解除正确的状态锁,所以会要求我们显式输入锁 ID。
一般情况下我们不需要强制解锁,只有在 Terraform 异常终止,来不及解除锁时需要我们手动强制解除锁。错误地解除状态锁可能会导致状态混乱,所以请小心使用。
1.7.9.1. get
terraform get 命令可以用来下载以及更新根模块中使用的模块。
1.7.9.1.1. 用法
terraform get [options]
模块被下载并安装在当前工作目录下 .terraform 子目录中。这个子目录不应该被提交至版本控制系统。
get 命令支持以下参数:
-update:如果指定,已经被下载的模块会被检查是否有新版本,如果存在新版本则会更新-no-color:禁用输出中的文字颜色
graph
1.7.10.1. graph
terraform graph 命令可以用来生成代码描述的基础设施或是执行计划的可视化图形。它的输出是 DOT 格式),可以使用 GraphViz 来生成图片,也有许多网络服务可以读取这种格式。
1.7.10.1.1. 用法
terraform graph [options]
默认情况下,该命令输出一个简化图,仅描述配置中资源(resource 和 data 块)的依赖顺序。
-type=... 参数可以在一组具有更多细节的其他图类型中进行选择,但作为代价,它也暴露了 Terraform 语言运行时的一些实现细节。
参数:
-plan=tfplan:针对指定计划文件生成图。使用该参数暗示着-type=apply。-draw-cycles:用彩色的边高亮图中的环,这可以帮助我们分析代码中的环错误(Terraform 禁止环状依赖)。该参数只有在通过-type=...参数指定了操作类型时有效。-type=...:生成图表的类型,默认生成只包含resource的简化图。可以是:plan、plan-destroy或是apply。
1.7.10.1.2. 创建图片文件
terraform graph 命令输出的是 DOT 格式)的数据,可以轻松地使用 GraphViz 转换为图形文件:
1 | $ terraform graph -type=plan | dot -Tpng >graph.png |
输出的图片大概是这样的:
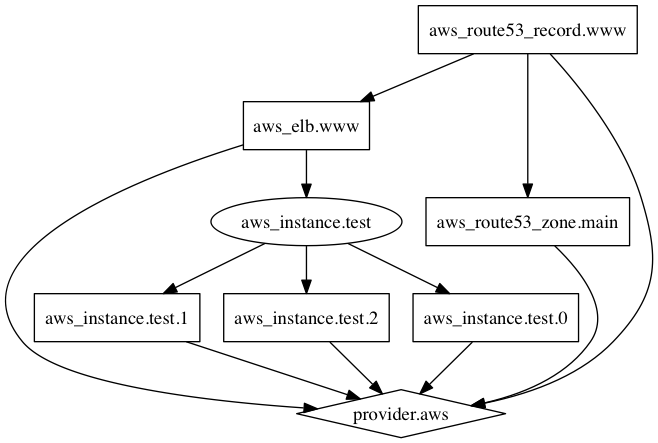
图 1.7.10/1 - 生成的依赖图
1.7.10.1.3. 如何安装GraphViz
安装GraphViz也很简单,对于Ubuntu:
1 | $ sudo apt install graphviz |
对于CentOS:
1 | $ sudo dnf install graphviz |
对于Windows,也可以使用choco:
1 | > choco install graphviz |
对于Mac用户:
1 | $ brew install graphviz |
1.7.11.1. import
terraform import 命令用来将已经存在的资源对象导入 Terraform。
我们并不总是那么幸运,能够在项目一开始就使用 Terraform 来构建和管理我们的基础设施;有时我们有一组已经运行着的基础设施资源,然后我们为它们编写了相应的 Terraform 代码,我们进行了测试,确认了这组代码描述的基础设施与当前正在使用的基础设施是等价的;但是我们仍然无法直接使用这套代码来管理现有的基础设施,因为我们缺乏了相应的状态文件。这时我们需要使用 terraform import 将资源对象“导入”到 Terraform 状态文件中去。
1.7.11.1.1. 用法
terraform import [options] ADDRESS ID
terraform import 会根据资源 ID 找到相应资源,并将其信息导入到状态文件中 ADDRESS 对应的资源上。ADDRESS 必须符合我们在资源地址中描述的合法资源地址格式,这样 terraform import 不但可以把资源导入到根模块中,也可以导入到子模块中。
ID 取决于被导入的资源对象的类型。举例来说,AWS 主机的 ID 格式类似于 i-abcd1234,而 AWS Route53 Zone 的 ID 类似于 Z12ABC4UGMOZ2N,请参考相关 Provider 文档来获取有关 ID 的详细信息。如果不确信的话,可以随便尝试任意 ID。如果 ID 不合法,你会看到一个错误信息。
警告,Terraform设想的是每一个资源对象都仅对应一个独一无二的实际基础设施对象,通常来说如果我们完全使用 Terraform 创建并管理基础设施时这一点不是问题;但如果你是通过导入的方式把基础设施对象导入到 Terraform 里,要绝对避免将同一个对象导入到两个以及更多不同的地址上,这会导致 Terraform 产生不可预测的行为。
该命令有以下参数可以使用:
-config=path:包含含有导入目标的Terraform代码的文件夹路径。默认为当前工作目录。如果当前目录不包含 Terraform 代码文件,则必须通过手动输入或环境变量来配置 Provider。-input=true:是否允许提示输入 Provider 配置信息-lock=false:如果 Backend 支持,是否锁定状态文件。在其他人可能会同时修改同一工作区的配置时关闭锁是危险的。-lock-timeout=0s:重试尝试获取状态锁的间隔-no-color:如果设定该参数,则不会输出彩色信息-parallelism=n:限制 Terraform 遍历图的最大并行度,默认值为 10(又是考点)-var 'foo=bar':通过命令行设置输入变量值,类似plan命令中的介绍-var-file=foo:类似plan命令中的介绍
当代码只使用了 local 类型的 Backend 时,terraform import 同时接受以下遗留参数:
-state=FILENAME:要读取的状态文件的地址-state-out=FILENAME:指定修改后的状态文件的保存路径,如果我们设置了-state而没同时设置-state-out,则 Terraform-state的值写给-state-out,这意味着 Terraform 如果创建新的状态快照,将直接写入源状态文件。-backup=FILENAME:生成状态备份文件的地址,默认情况下是-state-out路径加上.backup后缀名。设置为-可以关闭备份(不推荐)
1.7.11.1.2. Provider配置
Terraform 会尝试读取要导入的资源对应的 Provider 的配置信息。如果找不到相关 Provider 的配置,那么 Terraform 会提示你输入相关的访问凭据。你也可以通过环境变量来配置访问凭据。
Terraform 在读取 Provider 配置时唯一的限制是不能依赖于"非输入变量"的输入。举例来说,Provider 配置不能依赖于数据源的输出。
举一个例子,如果你想要导入 AWS 资源而你有这样的一份代码文件,那么 Terraform 会使用这两个输入变量来配置 AWS Provider:
1 | variable "access_key" {} |
1.7.11.1.3. 例子
1 | $ terraform import aws_instance.foo i-abcd1234 |
1 | $ terraform import module.foo.aws_instance.bar i-abcd1234 |
1 | $ terraform import 'aws_instance.baz[0]' i-abcd1234 |
1 | $ terraform import 'aws_instance.baz["example"]' i-abcd1234 |
上面这条命令如果是在PowerShell下:
1 | $ terraform import 'aws_instance.baz[\"example\"]' i-abcd1234 |
如果是cmd:
1 | $ terraform import aws_instance.baz[\"example\"] i-abcd1234 |
1.7.12.1. init
terraform init 命令被用来初始化一个包含 Terraform 代码的工作目录。在编写了一些 Terraform 代码或是克隆了一个 Terraform 项目后应首先执行该命令。反复执行该命令是安全的(考点)。
1.7.12.1.1. 用法
terraform init [options]
该命令为初始化工作目录执行了多个不同的步骤。详细说明可以见下文,总体来说用户不需要担心这些步骤。即使某些步骤可能会遭遇错误,但是该命令绝对不会删除你的基础设施资源或是状态文件。
1.7.12.1.2. 常用参数
-input=true:是否在取不到输入变量值时提示用户输入-lock=false:是否在运行时锁定状态文件-lock-timeout=<duration>:尝试获取状态文件锁时的超时时间,默认为0s(0 秒),意为一旦发现锁已被其他进程获取立即报错-no-color:禁止输出中包含颜色-upgrade:是否升级模块代码以及插件
1.7.12.1.3. 从模块源拷贝模块
默认情况下,terraform init 会假设工作目录下已经包含了 Terraform 代码文件。
我们也可以在空文件夹内搭配 -from-module=MODULE-SOURCE 参数运行该命令,这样在运行任何其他初始化步骤之前,指定的模块将被复制到目标目录中。
这种特殊的使用方式有两种场景:
- 我们可以用这种方法从模块源对应的版本控制系统当中签出指定版本代码并为它初始化工作目录
- 如果模块源指向的是一个样例项目,那么这种方式可以把样例代码拷贝到本地目录以便我们后续基于样例编写新的代码
如果是常规使用时,建议使用版本控制系统自己的命令单独检查版本控制的配置。这样,可以在必要时将额外的标志传递给版本控制系统,并在运行 terraform init 之前执行其他准备步骤(例如代码生成或激活凭据)。
1.7.12.1.4. Backend 初始化
在执行 init 时,会分析根模块代码以寻找 Backend 配置,然后使用给定的配置设定初始化 Backend 存储。
在已经初始化 Backend 后重复执行 init 命令会更新工作目录以使用新的 Backend 设置。这时我们必须设置 -reconfigure 或是 -migrate-state 来升级 Backend 配置。
-migrate-state 选项会尝试将现有状态复制到新 Backend,并且根据更改的内容,可能会导致交互式提示以确认工作区状态的迁移。 设置 -force-copy 选项可以阻止这些提示并对迁移问题回答 yes。启用 -force-copy 还会自动启用 -migrate-state 选项。
-reconfigure 选项会忽略任何现有配置,从而防止迁移任何现有状态。
要跳过后端配置,请使用 -backend=false。请注意,其他一些初始化步骤需要初始化后端,因此建议仅当先前已为特定后端初始化工作目录时才使用此标志。
要跳过 Backend 配置,可以设置 -backend=false。注意某些其他 init 步骤需要已经被初始化的 Backend,所以推荐只在已经初始化过 Backend 后使用该参数。
-backend-config=... 参数可以用来动态指定 Backend 配置,我们在状态管理章节中介绍“部分配置”时已经提过,在此不再赘述。
1.7.12.1.5. 初始化子模块
init 会搜索代码中的 module 块,然后通过 source 参数取回引用的模块代码。
模块安装之后重新运行 init 命令会继续安装那些自从上次 init 之后新增的模块,但不会修改已被安装的模块。设置 -upgrade 可以改变这种行为,将所有模块升级到最新版本的代码。
要跳过子模块安装步骤,可以设置 -get=false 参数。要注意其他一些init步骤需要模块树完整,所以建议只在成功安装过模块以后使用该参数。
1.7.12.1.6. 插件安装
我们在 Provider 章节中介绍了插件安装,所以在此不再赘述,我们值介绍一下参数:
-upgrade:将之前所有已安装的插件升级到符合version约束的最新版本。-plugin-dir=PATH:跳过插件安装,只从命令行配置文件的filesystem_mirror指定的目录加载插件。该参数会跳过用户插件目录以及所有当前工作目录下的插件。我们推荐使用命令行参数文件来全局设置 Terraform 安装方法,-plugin-dir可以作为一次性的临时方法,例如测试当前本地正在开发的 Provider 插件。-lockfile=MODE设置依赖锁文件的模式 该参数的可选值有:readonly:禁用锁定文件更改,但根据已记录的信息验证校验和。该参数与-upgrade参数冲突。如果我们使用第三方依赖项管理工具更新锁定文件,那么控制它何时显式更改将很有用。
1.7.12.1.7. 在自动化环境下运行 terraform init 命令
如果在团队的变更管理和部署流水线中 Terraform 扮演了关键角色,那么我们可能需要以某种自动化方式编排 Terraform 运行,以确保运行之间的一致性,并提供其他有趣的功能,例如与版本控制系统的钩子进行集成。
在此类环境中运行 init 时需要注意一些特殊问题,包括可选择在本地提供插件以避免重复重新安装。有关更多信息,请参阅 Terraform 与自动化。
1.7.12.1.8. 设置其他代码文件夹
Terraform v0.13 及更早版本还可以设置目录路径来代替 terraform apply 的计划文件参数,在这种情况下,Terraform 将使用该目录作为根模块而不是当前工作目录。
Terraform v0.14 中仍支持该用法,但现已在 Terraform v0.15 中弃用并删除。如果我们的工作流程依赖于覆盖根模块目录,请改用 -chdir 全局选项,该选项适用于所有命令,并使 Terraform 始终在给定目录中查找它通常在当前工作目录中读取或写入的所有文件。
如果您之前的工作流同时要求 Terraform 即使根模块目录已被修改也要将 .terraform 子目录写入当前工作目录,请使用 TF_DATA_DIR 环境变量命令 Terraform 将 .terraform 目录写入当前工作目录之外的其他位置。
1.7.13.1. output
terraform output 命令被用来提取状态文件中输出值的值。
1.7.13.1.1. 用法
terraform output [options] [NAME]
如果不添加参数,output 命令会展示根模块内定义的所有输出值。如果指定了 NAME,只会输出相关输出值。
可以使用以下参数:
-json:设置该参数后 Terraform 会使用 JSON 格式输出。如果指定了NAME,只会输出相关输出值。该参数搭配jq使用可以构建复杂的流水线-raw:设置该参数后 Terraform 会将指定的输出值转换为字符串,并将该字符串直接打印到输出中,不带任何特殊格式。这在使用 shell 脚本时很方便,但它仅支持字符串、数字和布尔值。处理复杂的数据类型时还请使用-json。-no-color:不输出颜色-state=path:状态文件的路径,默认为terraform.tfstate。启用远程 Backend 时该参数无效
注意:设置 -json 或 -raw 参数时,Terraform 状态中的任何敏感值都将以纯文本显示。有关详细信息,请参阅状态中的敏感数据。
1.7.13.1.2. 样例
假设有如下输出值代码:
1 | output "instance_ips" { |
列出所有输出值:
1 | $ terraform output |
注意password输出值定义了sensitive = true,所以它的值在输出时会被隐藏:
1 | $ terraform output password |
要查询负载均衡的DNS地址:
1 | $ terraform output lb_address |
查询所有主机的IP:
1 | $ terraform output instance_ips |
使用-json和jq查询指定主机的ip:
1 | $ terraform output -json instance_ips | jq '.value[0]' |
1.7.13.1.3. 在自动化环境下运行 terraform output 命令
terraform output 命令默认以便于人类阅读的格式显示,该格式可以随着时间的推移而改变以提高易读性。
对于脚本编写和自动化,请使用 -json 生成稳定的 JSON 格式。您可以使用 JSON 命令行解析器(例如 jq)解析输出:
1 | terraform output -json instance_ips | jq -r '.[0]' |
如果要在 shell 脚本中直接使用字符串值,可以转而使用 -raw 参数,它将直接打印字符串,没有额外的转义或空格。
1 | terraform output -raw lb_address |
-raw 选项仅适用于 Terraform 可以自动转换为字符串的值。处理复杂类型的值(例如对象)时还请改用 -json(可以与 jq 结合使用)。
Terraform 字符串是 Unicode 字符序列而不是原始字节,因此 -raw 输出在包含非 ASCII 字符时将采用 UTF-8 编码。如果您需要不同的字符编码,请使用单独的命令(例如 iconv)对 Terraform 的输出进行转码。
1.7.14.1. plan
terraform plan 命令被用来创建变更计划。Terraform 会先运行一次 refresh(我们后面的章节会介绍,该行为也可以被显式关闭),然后决定要执行哪些变更使得现有状态迁移到代码描述的期待状态。
该命令可以方便地审查状态迁移的所有细节而不会实际更改现有资源以及状态文件。例如,在将代码提交到版本控制系统前可以先执行 terraform plan,确认变更行为如同预期一般。
如果您直接在交互式终端中使用 Terraform 并且希望执行 Terraform 所提示的变更,您也可以直接运行 terraform apply。默认情况下,apply 命令会自动生成新计划并提示您批准它。
可选参数 -out 可以将变更计划保存在一个文件中,以便日后使用 terraform apply 命令来执行该计划。
在使用版本控制和代码审查工作流程对实际基础架构进行更改的团队中,开发人员可以使用保存下来的的计划文件来验证更改的效果,然后再对提交的变更进行代码审查。但是,要慎重考虑考虑对目标系统同时进行的其他更改可能会导致配置更改的最终效果与早期保存的计划所指示的不同,因此您应该始终重新检查最终的实际执行的计划,在执行之前确保它仍然符合您的意图。
如果 Terraform 检测不到任何变更,那么 terraform plan 会提示没有任何需要执行的变更。
1.7.14.1.1. 用法
terraform plan [options]
plan 命令在当前工作目录中查找根模块配置。
由于 plan 命令是 Terraform 的主要命令之一,因此它有多种不同的选项,如下部分所述。但是,大多数时候我们不需要设置这些选项,因为 Terraform 配置通常应设计为无需特殊的附加选项即可进行日常工作。
plan 命令的参数选项可以分为以下三大类
- Plan 模式:当我们的目标不仅仅是更改远程系统以匹配代码配置时,我们可以在某些特殊情况下使用一些特殊的替代规划模式。
- Plan 选项:除了特殊的 Plan 模式之外,我们还可以设置一些选项,以便根据特殊的需求来定制计划流程。
- 其他选项:这些选项改变了规划命令本身的行为,而不是定制生成的计划的内容。
1.7.14.1.2. Plan 模式
上一节描述了 Terraform 的默认规划变更计划行为,该行为会变更远程系统以匹配我们对配置代码所做的更改。 Terraform 还有两种不同的规划模式,每种模式都会创建具有不同预期结果的计划。这些选项可用于 terraform plan 和 terraform apply。
-
Destroy 模式:创建一个计划,其目的是销毁当前存在的所有远程对象,留下空的 Terraform 状态。这与运行
terraform destroy相同。销毁模式对于临时的开发环境等情况非常有用,在这种情况下,一旦开发任务完成,托管对象就不再需要保留。通过
-destroy命令行选项启用销毁模式。 -
Refresh-Only 模式:创建一个计划,其目标仅是更新 Terraform 状态和所有根模块的输出值,以匹配对 Terraform 外部远程对象所做的更改。如果您使用 Terraform 之外的工具更改了一个或多个远程对象(例如,在响应事件时),并且您现在需要使 Terraform 的记录与这些更改保持一致,那么该命令会很有帮助。
使用
-refresh-only命令行选项启用 Refresh-Only 模式。
相对而言,我们把 Terraform 在未选择任何替代模式时使用的默认规划模式的情况下的行为称为“正常模式”。由于上述的替代模式仅适用于特殊情况,因此其他一些 Terraform 文档仅讨论正常规划模式。
Plan 模式都是互斥的,因此启用任何非默认 Plan 模式时都会禁用“正常”计划模式,并且我们不能同时使用多种替代模式。
注意:在 Terraform v0.15 及更早版本中,只有 terraform plan 命令支持 -destroy 选项,terraform apply 命令是不支持的。要在早期版本中以 Destroy 模式创建并应用计划,我们必须运行 terraform destroy。另外,-refresh-only 选项仅在 Terraform v0.15.4 及之后的版本中可用。
1.7.14.1.3. Plan 选项
相较于 Plan 模式,还有一些可以用来更改规划行为的参数选项。
-refresh=false:在检查配置更改之前跳过同步 Terraform 状态与远程对象的默认行为。这可以减少远程 API 请求的数量,加快规划操作的速度。但是,设置refresh=false会导致 Terraform 忽略外部更改,这可能会导致计划不完整或不正确。您不能在 Refresh Only 计划模式中使用refresh=false,因为这将导致什么都不做。-replace=ADDRESS- 命令 Terraform 在计划中替换给定地址的资源实例。当一个或多个远程对象降级时,这非常有用,并且我们可以替换成具有相同配置的对象来与不可变的基础架构模式保持一致。如果指定的资源在计划中存在“更新”操作或没有变化,则 Terraform 将使用“替换”操作。多次包含此选项可一次替换多个对象。您不能将-replace与-destroy选项一起使用,并且该功能仅从 Terraform v0.15.2 开始可用。对于早期版本,使用terraform taint来实现类似的结果。-target=ADDRESS- 命令 Terraform 只计算给定地址匹配的资源实例以及这些实例所依赖的任何对象的变更。 注意:应该仅在特殊情况下使用-target=ADDRESS,例如从错误中恢复或绕过 Terraform 限制。有关更多详细信息,请参阅资源定位。-var 'NAME=VALUE'- 设置在配置的根模块中声明的单个输入变量的值。多次设置该选项可设置多个变量。有关详细信息,请参阅在命令行中输入变量。-var-file=FILENAME- 使用tfvars文件中的定义为配置的根模块中声明的潜在多个输入变量设置值。多次设置该选项可包含多个文件中的值。
除了 -var 和 -var-file 选项之外,还有其他几种方法可以在根模块中设置输入变量的值。有关详细信息,请参阅为根模块输入变量赋值。
1.7.14.1.4. 在命令行中输入变量
我们可以使用 -var 命令行选项来指定根模块中声明的输入变量的值。
然而,要做到这一点,需要编写一个可由您选择的 shell 和 Terraform 解析的命令,对于涉及大量引号和转义序列的表达式来说这可能会很复杂。在大多数情况下,我们建议改用 -var-file 选项,并将实际值写入单独的文件中,以便 Terraform 可以直接解析它们,而不是解释 shell 解析后的结果。
警告:如果在等号之前或之后包含空格(例如 -var “length = 2”),Terraform 将报错。
要在 Linux 或 macOS 等系统上的 Unix 风格 shell 上使用 -var,我们建议将选项参数写在单引号 ' 中,以确保 shell 按字面解释该值:
1 | terraform plan -var 'name=value' |
如果我们的预期值还包含单引号,那么我们仍然需要对其进行转义,以便 shell 进行正确解释,这还需要暂时终止引号序列,以便反斜杠转义字符合法:
1 | terraform plan -var 'name=va'\''lue' |
在 Windows 上使用 Terraform 时,我们建议使用 Windows 命令提示符 (cmd.exe)。当您从 Windows 命令提示符将变量值传递给 Terraform 时,请在参数周围使用双引号 ":
1 | terraform plan -var "name=value" |
如果我们的预期值还包含双引号,那么您需要用反斜杠转义它们:
1 | terraform plan -var "name=va\"lue" |
Windows 上的 PowerShell 无法正确地将文字引号传递给外部程序,因此我们不建议您在 Windows 上时将 Terraform 与 PowerShell 结合使用。请改用 Windows 命令提示符。
根据变量的类型约束,声明变量值的语法有所不同。原始类型 string、number 和 bool 对应一个直接的字符串值,除非您的 shell 如上面的示例所示需要,否则不需要添加特殊的标点符号。对于所有其他类型约束,包括 list、map 和 set 类型以及特殊的 any 关键字,您必须编写一个表示该值的有效 Terraform 语言表达式,并附带必要的引用或转义字符以确保它将通过您的 shell 逐字传递到 Terraform。例如,对于 list(string) 类型约束:
1 | Unix-style shell |
使用环境变量设置输入变量时也适用类似的约束。有关设置根模块输入变量的各种方法的更多信息,请参阅为根模块变量赋值。
1.7.14.1.5. 资源定位
我们可以使用 -target 选项将 Terraform 的计算范围仅集中在少数资源上。我们可以使用资源地址语法来指定约束。Terraform 对代码中的资源地址的解释行为如下:
- 如果给定地址定位了一个特定资源实例,Terraform 将单独选择该实例。对于设置了
count或for_each的资源,资源实例地址必须包含实例索引部分,例如azurerm_resource_group.example[0]。 - 如果给定的地址对应到一个资源整体(即表达式中不含索引部分),Terraform 将选择该资源的所有实例。对于设置了
count或for_each的资源,这意味着选择当前与该资源关联的所有实例索引。对于单实例资源(没有count或for_each),资源地址和资源实例地址相同,因此这种可能性不适用。 - 如果给定的地址标识整个 Module 实例,Terraform 将选择属于该 Module 实例及其所有子 Module 实例的所有资源的所有实例。
一旦 Terraform 选择了我们直接定位的一个或多个资源实例,它还会扩展选择范围以包括这些选择直接或间接依赖的所有其他对象。
这种资源定位功能是为某些特殊情况设计的,例如从故障中恢复或绕过 Terraform 的某些限制。不建议将 -target 用于常规操作,因为这可能会导致未检测到的配置漂移以及对资源真实状态与配置的关系的混淆。
与其使用 -target 作为对非常庞大的配置的一小部分子集进行操作的方法,不如将大型配置分解为多个较小的配置,每个配置都可以独立应用。数据源可用于访问有关在其他配置中创建的资源的信息,从而允许将复杂的系统架构分解为更易于管理且可以独立更新的部分。
1.7.14.1.6. 其他选项
terraform plan 命令还有一些与规划命令的输入和输出相关的其他选项,这些配置不会影响 Terraform 将创建哪种类型的计划。这些命令不一定在 terraform apply 上也可用,除非该命令的文档中另有说明。
-
-compact-warnings:如果 Terraform 生成了一些告警信息而没有伴随的错误信息,那么以只显示消息总结的精简形式展示告警 -
-detailed-exitcode:当命令退出时返回一个详细的返回码。如果有该参数,那么返回码将会包含更详细的含义: -
0 = 成功的空计划(没有变更)
-
1 = 错误
-
2 = 成功的非空计划(有变更)
-
-generate-config-out=PATH-(实验功能)如果配置中存在import块,则命令 Terraform 为尚未存在的任何导入资源生成 HCL。配置将写入PATH位置的新文件,该文件不可以存在,否则 Terraform 将报错。如果plan命令因为其他原因失败,Terraform 仍可能尝试写入配置。 -
-input=false:在取不到值的情况下是否提示用户给定输入变量值。此参数在非交互式自动化系统中运行 Terraform 时特别有用。 -
-lock=false:操作过程中不对状态文件上锁。如果其他人可能同一时间对同一工作区运行命令可能引发事故。 -
-lock-timeout=DURATION:除非使用-lock=false禁用锁定,否则指示 Terraform 在返回错误之前重试获取锁定一段时间。持续时间语法是一个数字后跟一个时间单位字母,例如"3s"表示三秒。 -
-no-color:关闭彩色输出。在无法解释输出色彩的终端中运行 Terraform 时请使用此参数。 -
-out=FILENAME:将变更计划保存到指定路径下的文件中,随后我们可以使用terraform apply执行该计划Terraform 将允许计划文件使用任何文件名,但典型的约定是将其命名为
tfplan。请不要使用 Terraform 支持的后缀名来命名文件;如果您使用.tf后缀,那么 Terraform 将尝试将该文件解释为配置源文件,这将导致后续命令出现语法错误。 -
-parallelism-n:限制Terraform遍历图的最大并行度,默认值为10。
1.7.14.1.7. 指定其他配置文件目录
Terraform v0.13 及更早版本接受提供目录路径的附加位置参数,在这种情况下,Terraform 将使用该目录作为根模块而不是当前工作目录。
该用法在 Terraform v0.14 中已弃用,并在 Terraform v0.15 中删除。如果您的工作流程需要修改根模块目录,请改用 -chdir 全局选项,该选项适用于所有命令,并使 Terraform 始终在给定目录中查找它通常在当前工作目录中读取或写入的所有文件。
如果我们之前使用此遗留模式时同时需要 Terraform 将 .terraform 子目录写入当前工作目录,即使根模块目录已被覆盖,请使用 TF_DATA_DIR 环境变量命令 Terraform 将 .terraform 目录写入其他位置,而不是当前工作目录。
1.7.14.1.8. 安全警告
被保存的变更计划文件(使用 -out 参数)内部可能含有敏感信息,Terraform 本身并不会加密计划文件。如果你要移动或是保存该文件一段时间,强烈建议你自行加密该文件。
Terraform 未来打算增强计划文件的安全性。
1.7.15.1. providers
terraform providers 命令显示有关当前工作目录中代码的 Provider 声明的信息,以帮助我们了解每个被需要的 Provider 是从何而来。
该命令是含有内嵌子命令,这些子命令我们会逐个解释。
1.7.15.1.1. 用法
1 | terraform providers |
mirror
1.7.15.1.1. terraform providers mirror
该子命令从 Terraform 0.13 开始引入。
terraform providers mirror 命令下载当前代码所需要的 Provider 并且将其拷贝到本地文件系统的一个目录下。
一般情况下,terraform init 会在初始化当前工作目录时自动从 registry 下载所需的 Provider。有时 Terraform 工作在无法执行该操作的环境下,例如一个无法访问 registry 的局域网内。这时可以通过显式配置 Provider 安装方式来使得在这样的环境下 Terraform 可以从本地插件镜像存储中获取插件。
terraform providers mirror 命令可以自动填充准备用以作为本地插件镜像存储的目录。
1.7.15.1.1.1. 用法
terraform providers mirror [options] <target-dir>
target-dir 参数是必填的。Terraform 会自动在目标目录下建立起插件镜像存储所需的文件结构,填充包含插件文件的 .zip 文件。
Terraform同时会生成一些包含了合法的网络镜像协议响应的 .json 索引文件,如果我们把填充好的文件夹上传到一个静态站点,那就能够得到一个静态的网络插件镜像存储服务。Terraform 在使用本地文件镜像存储时会忽略这些镜像文件,因为使用本地文件镜像时文件夹本身的信息更加权威。
该命令支持如下可选参数:
-
-platform=OS_ARCH:选择构建镜像的目标平台。默认情况下,Terraform 会使用当前运行 Terraform 的平台。可以多次设置该参数以构建多目标平台插件镜像目标平台必须包含操作系统以及 CPU 架构。例如:
linux_amd64代表运行在 AMD64 或是 X86_64 CPU 之上的 Linux 操作系统。
我们可以针对已构建的镜像文件夹重新运行 terraform providers mirror 来添加新插件。例如,可以通过设置 -platform 参数来添加新目标平台的插件,Terraform 会下载新平台插件同时保留原先的插件,将二者合并存储,并更新索引文件。
schema
1.7.15.2.1. terraform providers schema
terraform providers schema 命令被用来打印当前代码使用的 Provider 的架构。Provider 架构包含了使用的所有 Provider 本身的参数信息,以及所提供的 resource、data 的架构信息。
1.7.15.2.1.1. 用法
terraform providers schema [options]
可选参数为:
-json:用机器可读的 JSON 格式打印架构
请注意,目前 -json 参数是必填的,未来该命令将允许使用其他参数。
输出包含一个 format_version 键,就拿 Terraform 1.1.0 来说,其值为 "1.0"。该版本的语义是:
- 对于向后兼容的变更或新增字段,我们将增加 minor 版本号,例如
"1.1"。这种变更会忽略所有不认识的对象属性,以保持与未来其他 minor 版本的前向兼容。 - 对于不向后兼容的变更,我们将增加 major 版本,例如
"2.0"。不同的 major 版本之间的数据无法直接传递。
我们只会在 Terraform 1.0 兼容性承诺的范围内更新 major 版本。
1.7.15.3.1. terraform providers lock
terraform providers lock 会查询上游 registry(默认情况下),以便将 Provider 的依赖项信息写入依赖项锁文件。
更新依赖项锁定文件的常见方法是由 terraform init 命令安装 Provider 时生成,但在某些情况下,这种自动生成的方法可能不够:
-
如果您在使用其他 Provider 程序安装方法(例如文件系统或网络镜像)的环境中运行 Terraform,则常规的 Provider 安装程序将不会访问 Provider 程序在 Registry 上的源,因此 Terraform 将无法填充所有可能的包校验和选定的 Provider 版本。
如果您使用
terraform lock将 Provider 程序的官方版本校验和写入依赖项锁定文件中,则将来的terraform init运行将根据之前记录的官方校验和验证所选镜像中可用的软件包,从而进一步确保镜像返回的 Provider 程序的确是官方版本。 -
如果您的团队在多个不同平台上运行 Terraform(例如在 Windows 和 Linux 上),并且 Provider 的上游 Registry 无法使用最新的哈希方案提供签名的校验和,则后续在其他平台上运行 Terraform 可能会添加额外的校验和锁定文件。您可以通过使用
terraform providers lock命令为您打算使用的所有平台预先填充哈希值来避免这种情况。
terraform providers lock 仅在 Terraform v0.14 或更高版本中可用。
1.7.15.3.1.1. 用法
terraform providers lock [options] [providers...]
在没有额外的命令行参数的情况下,terraform providers lock 将分析当前工作目录中的代码,以查找它所依赖的所有 Provider 程序,并且将从其源 Registry 中获取有关这些 Provider 程序的关键数据,然后更新依赖项锁文件,写入所有选定的 Provider 程序版本以及 Provider 程序开发人员的私钥签名的包校验和。
警告:terraform providers lock 命令会打印有关其获取的内容以及每个包是否使用加密签名进行签名的信息,但它无法自动验证 Provider 提供者是否值得信赖以及它们是否符合您的本地系统策略或相关法规。在将更新的锁定文件提交到版本控制系统之前,请检查输出中的签名密钥信息,以确认您信任所有签名者。
如果您在命令行上列出一个或多个 Provider 程序源地址,则 terraform providers lock 将其工作仅限于这些提供程序,而其他提供程序(如果有的话)的锁定条目保持不变。
我们可以使用以下附加选项定制该命令的行为:
-
-fs-mirror=PATH- 命令 Terraform 在给定的本地文件系统镜像目录中查找提供程序包,而不是在上游注册表中。给定目录必须使用通常的文件系统镜像目录布局。 -
-net-mirror=URL- 命令 Terraform 在给定的网络镜像服务中查找提供程序包,而不是在上游注册表中。给定的 URL 必须实现 Terraform Provider 网络镜像协议。 -
-platform=OS_ARCH- 设置打算用于处理此 Terraform 配置的平台。Terraform 将确保 Provider 程序均可用于指定的平台,并将在锁文件中保存足够的包校验和以至少支持指定的平台。可以多次设置此选项以包含多个目标系统的校验和。
目标平台名称由操作系统和 CPU 架构组成。例如,linux_amd64 选择在 AMD64 或 x86_64 CPU 上运行的 Linux 操作系统。
我们将在后续节中讲述有关于此参数的更多详细信息。
-
-enable-plugin-cache- 启用全局配置的插件缓存的使用。这将加快锁定过程。默认情况下不启用此功能,因为插件缓存不是权威来源。由于terraform providers lock命令用于确保使用受信任的 Provider 程序版本,因此从缓存安装插件被认为是有风险的。
1.7.15.3.1.2. 指定目标平台
例如,在我们的团队中可能既有在 Windows 或 macOS 工作站上使用 Terraform 配置的开发人员,也有在 Linux 上运行 Terraform 配置的自动化系统。
在这种情况下,我们可以选择验证所有 Provider 程序是否支持所有这些平台,并通过运行 terraform providers lock 并指定这三个平台来预先填充锁文件所需的校验和:
1 | terraform providers lock \ |
(上面的示例使用 Unix 风格的 shell 包装语法来提高可读性。如果您在 Windows 上运行该命令,则需要将所有参数放在一行上,并删除反斜杠和注释。)
1.7.15.3.1.3. 内部 Providers 的锁条目
所谓内部 Provider 程序是还没有在真正的 Terraform Provider 注册表上发布的 Provider 程序,因为它仅在特定组织内开发和使用,并通过文件系统镜像或网络镜像进行分发。
默认情况下,terraform providers lock 命令假定所有 Provider 程序都是在 Terraform Provider 程序注册表中可用,并尝试联系源注册表以访问有关提供程序包的所有细节信息。
要为仅在本地镜像中可用的特定 Provider 程序创建锁定条目,可以使用 -fs-mirror 或 -net-mirror 命令行选项来覆盖查询 Provider 程序的原始注册表的默认行为:
1 | terraform providers lock \ |
(上面的示例使用 Unix 风格的 shell 包装语法来提高可读性。如果您在 Windows 上运行该命令,则需要将所有参数放在一行上,并删除反斜杠和注释。)
由于上面的命令包含 Provider 程序源地址 tf.example.com/ourcompany/ourplatform,因此 terraform providers lock 将仅尝试访问该特定 Provider 程序,并将保留所有其他 Provider 程序的锁条目不变。如果我们有来自不同来源的各种不同的 Provider 程序,可以多次运行 terraform providers lock 并每次指定不同的 Provider 程序子集。
-fs-mirror 和 -net-mirror 选项与 Provider 程序安装方法配置中的 filesystem_mirror 和 network_mirror 块具有相同的含义,但仅配置其中之一,以便明确您打算从何处派生包校验和信息。
请注意,只有原始注册表可以提供开发人员的原始加密签名所签署的官方校验和。因此,从文件系统或网络镜像创建的锁条目将仅覆盖您请求的确切平台,并且记录的校验和将是镜像报告的校验和,而不是原始注册表的官方校验和。如果要确保记录的校验和是由原始 Provider 发布者签名的校验和,请运行不带 -fs-mirror 或 -net-mirror 选项的此命令,以从原始注册表中获取所有信息。
如果您愿意,您可以通过内部 Provider 程序注册表发布您的内部 Provider 程序,然后该注册表将允许锁定和安装这些 Provider 程序,而无需任何特殊选项或额外的 CLI 配置。有关详细信息,请参阅 Provider 注册协议。