mysql> SHOW FULL PROCESSLIST\G *************************** 1. row *************************** Id: 22 User: repl Host: node2:39114 db: NULL Command: Binlog Dump Time: 4435 State: Master has sent all binlog to slave; waiting for more updates Info: NULL
mysql> SHOW VARIABLES LIKE 'have_ssl'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | have_ssl | YES | +---------------+-------+ 1 row in set (0.02 sec)
当 have_ssl 为 YES 时, 表示此时 MySQL 服务已经支持 SSL 了. 如果是 DESABLE, 则需要在启动 MySQL 服务时, 使能 SSL 功能.
使用 OpenSSL 创建 SSL 证书和私钥
首先我们需要使用 openssl 来创建服务器端的证书和私钥. 我使用的 openssl 版本为:
1 2
>>> /usr/local/Cellar/openssl/1.0.2j/bin/openssl version OpenSSL 1.0.2j 26 Sep 2016
You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]:CN State or Province Name (full name) [Some-State]:Beijing Locality Name (eg, city) []:Beijing Organization Name (eg, company) [Internet Widgits Pty Ltd]:xys Organizational Unit Name (eg, section) []:xys Common Name (e.g. server FQDN or YOUR name) []:xys Email Address []:yongshun1228@gmail.com
Generating a 2048 bit RSA private key .................+++ ..+++ writing new private key to 'server-key.pem' ----- You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]:CN State or Province Name (full name) [Some-State]:Beijing Locality Name (eg, city) []:Beijing Organization Name (eg, company) [Internet Widgits Pty Ltd]:xys Organizational Unit Name (eg, section) []:xys Common Name (e.g. server FQDN or YOUR name) []:xys Email Address []:yongshun1228@gmail.com
Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []:
mysql> \s -------------- mysql Ver 14.14 Distrib 5.7.17, for Linux (x86_64) using EditLine wrapper
Connection id: 14 Current database: Current user: ssl_test@172.17.0.4 SSL: Cipher in use is DHE-RSA-AES256-SHA Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 5.7.17 MySQL Community Server (GPL) Protocol version: 10 Connection: test_db via TCP/IP Server characterset: latin1 Db characterset: latin1 Client characterset: latin1 Conn. characterset: latin1 TCP port: 3306 Uptime: 1 hour 2 min 9 sec
Threads: 1 Questions: 23 Slow queries: 0 Opens: 126 Flush tables: 3 Open tables: 0 Queries per second avg: 0.006 --------------
如果输出中有 SSL: Cipher in use is DHE-RSA-AES256-SHA 之类的信息, 则表示已经使用 SSL 来连接了.
在 Docker 中使能 MySQL SSL 连接
上面我们简单介绍了一下如果使能 MySQL SSL 连接, 那么现在我们使用 Docker 来具体的实战一把吧!
mysql> \s -------------- mysql Ver 14.14 Distrib 5.7.17, for Linux (x86_64) using EditLine wrapper
Connection id: 5 Current database: Current user: ssl_test@172.17.0.5 SSL: Cipher in use is DHE-RSA-AES256-SHA Current pager: stdout Using outfile: '' Using delimiter: ; Server version: 5.7.17 MySQL Community Server (GPL) Protocol version: 10 Connection: test_db via TCP/IP Server characterset: latin1 Db characterset: latin1 Client characterset: latin1 Conn. characterset: latin1 TCP port: 3306 Uptime: 6 min 8 sec
Threads: 2 Questions: 10 Slow queries: 0 Opens: 113 Flush tables: 1 Open tables: 106 Queries per second avg: 0.027 --------------
输出中有 SSL: Cipher in use is DHE-RSA-AES256-SHA 信息则说明我们确实是使用了 SSL 连接的 MySQL 服务器.
2017-08-26T03:23:35.368366Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details). 2017-08-26T03:23:35.748679Z 0 [Warning] InnoDB: New log files created, LSN=45790 2017-08-26T03:23:35.793190Z 0 [Warning] InnoDB: Creating foreign key constraint system tables. 2017-08-26T03:23:35.848286Z 0 [Warning] No existing UUID has been found, so we assume that this is the first time that this server has been started. Generating a new UUID: f210c54b-8a0d-11e7-abbd-000c29129bb0. 2017-08-26T03:23:35.848889Z 0 [Warning] Gtid table is not ready to be used. Table 'mysql.gtid_executed' cannot be opened. 2017-08-26T03:23:35.849421Z 1 [Note] A temporary password is generated for root@localhost: ;b;s;)/rn6A3
Starting MySQL.2017-08-26T07:31:24.312411Z mysqld_safe error: log-error set to '/var/log/mariadb/mariadb.log', however file don't exists. Create writable for user 'mysql'. ERROR! The server quit without updating PID file (/var/lib/mysql/node1.pid).
insert into `course`(`id`,`name`) values (1,'语文'),(2,'高等数学'),(3,'视听说'),(4,'体育'),(5,'马克思概况'),(6,'民族理论'),(7,'毛中特'),(8,'计算机基础'),(9,'深度学习'),(10,'Java程序设计'),(11,'c语言程序设计'),(12,'操作系统'),(13,'计算机网络'),(14,'计算机组成原理'),(15,'数据结构'),(16,'数据分析'),(17,'大学物理'),(18,'数字逻辑'),(19,'嵌入式开发'),(20,'需求工程');
/*Table structure for table `stu_course` */
DROPTABLE IF EXISTS `stu_course`;
CREATE TABLE `stu_course` ( `sid` int(10) NOT NULL, `cid` int(10) NOT NULL, PRIMARY KEY (`sid`,`cid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `stu_course` */
insert into `stu_course`(`sid`,`cid`) values (1,2),(1,4),(1,14),(1,16),(1,19),(2,4),(2,8),(2,9),(2,14),(3,13),(3,14),(3,20),(4,5),(4,8),(4,9),(4,11),(4,16),(5,4),(5,8),(5,9),(5,11),(5,12),(5,16),(6,2),(6,14),(6,17),(7,1),(7,8),(7,15),(8,2),(8,3),(8,7),(8,17),(9,1),(9,7),(9,16),(9,20),(10,4),(10,12),(10,14),(10,20),(11,3),(11,9),(11,16),(12,3),(12,7),(12,9),(12,12),(13,1),(13,5),(13,13),(14,1),(14,3),(14,18),(15,1), (15,9),(15,15),(16,2),(16,7);
insert into `student`(`id`,`name`,`age`) values (25,'乾隆',17),(14,'关羽',43),(13,'刘备',12),(28,'刘永',12),(21,'后裔',12),(30,'吕子乔',28),(18,'嬴政',76),(22,'孙悟空',21),(4,'安其拉',24),(6,'宋江',22),(26,'康熙',51),(29,'张伟',26),(20,'张郃',12),(12,'张飞',32),(27,'朱元璋',19),(11,'李世民',54),(9,'李逵',12),(8,'林冲',43),(5,'橘右京',43),(24,'沙和尚',25),(23,'猪八戒',22),(15,'王与',21),(19,'王建',23),(10,'王莽',43),(16,'秦叔宝',43),(17,'程咬金',65),(3,'荆轲',21),(2,'诸葛亮',71),(7,'钟馗',23),(1,'鲁班',21);
EXPLAIN SELECT S.id,S.name,S.age,C.id,C.name FROM course C JOIN stu_course SC ON C.id = SC.cid JOIN student S ON S.id = SC.sid
结果是这样:
1 2 3 4 5
id select_type table partitions type possible_keys key key_len ref ------ ----------- ------ ---------- ------ ------------------- ------- ------- ----------- 1 SIMPLE SC (NULL) index PRIMARY PRIMARY 8 (NULL) 1 SIMPLE C (NULL) eq_ref PRIMARY PRIMARY 4 mydb.SC.cid 1 SIMPLE S (NULL) eq_ref PRIMARY,id_name_age PRIMARY 4 mydb.SC.sid
我们看到id全是1,那就说明光看id这个值是看不出来每个表的读取顺序的,那我们就来看table这一行,它的读取顺序是自上向下的,所以,这三个表的读取顺序应当是:SC - C - S。
再来看一条SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14
EXPLAIN SELECT* FROM course AS C WHERE C.`id` = ( SELECT SC.`cid` FROM stu_course AS SC WHERE SC.`sid` = ( SELECT S.`id` FROM student AS S WHERE S.`name` = "安其拉" ) ORDERBY SC.`cid` LIMIT 1 )
EXPLAIN SELECT* FROM course AS C WHERE C.`id` IN ( SELECT SC.`cid` FROM stu_course AS SC WHERE SC.`sid` = ( SELECT S.`id` FROM student AS S WHERE S.`name` = "安其拉" ) )
这个查询是:查询安其拉选课的课程信息
1 2 3 4 5
id select_type table partitions type possible_keys key key_len ref ------ ----------- ------ ---------- ------ ------------- ------- ------- ----------- 1 PRIMARY SC (NULL) ref PRIMARY PRIMARY 4 const 1 PRIMARY C (NULL) eq_ref PRIMARY PRIMARY 4 mydb.SC.cid 3 SUBQUERY S (NULL) ref name,name_age name 63 const
Using filesort 表示当SQL中有一个地方需要对一些数据进行排序的时候,优化器找不到能够使用的索引,所以只能使用外部的索引排序,外部排序就不断的在磁盘和内存中交换数据,这样就摆脱不了很多次磁盘IO,以至于SQL执行的效率很低。反之呢?由于索引的底层是B+Tree实现的,他的叶子节点本来就是有序的,这样的查询能不爽吗?
1 2
EXPLAIN SELECT*FROM course AS C ORDERBY C.`name`
1 2 3
type possible_keys key key_len ref rows filtered Extra ------ ------------- ------ ------- ------ ------ -------- ---------------- ALL (NULL) (NULL) (NULL) (NULL) 20 100.00 Using filesort
没有给C.name建立索引,所以在根据C.name排序的时候,他就使用了外部排序
Using tempporary 表示在对MySQL查询结果进行排序时,使用了临时表,这样的查询效率是比外部排序更低的,常见于order by和group by。
1 2
EXPLAIN SELECT C.`name` FROM course AS C GROUPBY C.`name`
1 2 3
possible_keys key key_len ref rows filtered Extra ------------- ------ ------- ------ ------ -------- --------------------------------- (NULL) (NULL) (NULL) (NULL) 20 100.00 Using temporary; Using filesort
-- 使用OUTER JOIN: SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score FROM students s RIGHT OUTER JOIN classes c ON s.class_id = c.id;
RIGHT OUTER JOIN返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会以NULL填充剩下的字段。
LEFT OUTER JOIN则返回左表都存在的行。如果我们给students表增加一行,并添加class_id=5,由于classes表并不存在id=5的行,所以,LEFT OUTER JOIN的结果会增加一行,对应的class_name是NULL:
1 2 3 4 5 6 7
-- 先增加一列class_id=5: INSERT INTO students (class_id, name, gender, score) values (5, '新生', 'M', 88); -- 使用LEFT OUTER JOIN: SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score FROM students s LEFT OUTER JOIN classes c ON s.class_id = c.id;
-- 使用FULL OUTER JOIN: SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score FROM students s FULL OUTER JOIN classes c ON s.class_id = c.id;
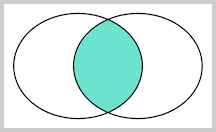
对于这么多种JOIN查询,到底什么使用应该用哪种呢?其实我们用图来表示结果集就一目了然了。
假设查询语句是:
1
SELECT ... FROM tableA ??? JOIN tableB ON tableA.column1 = tableB.column2;
MySQL Workbench可以用可视化的方式查询、创建和修改数据库表,但是,归根到底,MySQL Workbench是一个图形客户端,它对MySQL的操作仍然是发送SQL语句并执行。因此,本质上,MySQL Workbench和MySQL Client命令行都是客户端,和MySQL交互,唯一的接口就是SQL。
In [10]: df2 Out[10]: A B C D E F 0 1.0 2013-01-02 1.0 3 test foo 1 1.0 2013-01-02 1.0 3 train foo 2 1.0 2013-01-02 1.0 3 test foo 3 1.0 2013-01-02 1.0 3 train foo
In [13]: df.head() Out[13]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401
In [14]: df.tail(3) Out[14]: A B C D 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 2013-01-06 -0.673690 0.113648 -1.478427 0.524988
In [25]: df[0:3] Out[25]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
In [26]: df["20130102":"20130104"] Out[26]: A B C D 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 2013-01-04 0.721555 -0.706771 -1.039575 0.271860
In [39]: df[df["A"] > 0] Out[39]: A B C D 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 2013-01-04 0.721555 -0.706771 -1.039575 0.271860
In [40]: df[df > 0] Out[40]: A B C D 2013-01-01 0.469112 NaN NaN NaN 2013-01-02 1.212112 NaN 0.119209 NaN 2013-01-03 NaN NaN NaN 1.071804 2013-01-04 0.721555 NaN NaN 0.271860 2013-01-05 NaN 0.567020 0.276232 NaN 2013-01-06 NaN 0.113648 NaN 0.524988
In [42]: df2["E"] = ["one", "one", "two", "three", "four", "three"]
In [43]: df2 Out[43]: A B C D E 2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 one 2013-01-02 1.212112 -0.173215 0.119209 -1.044236 one 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 two 2013-01-04 0.721555 -0.706771 -1.039575 0.271860 three 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 four 2013-01-06 -0.673690 0.113648 -1.478427 0.524988 three
In [44]: df2[df2["E"].isin(["two", "four"])] Out[44]: A B C D E 2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 two 2013-01-05 -0.424972 0.567020 0.276232 -1.087401 four
In [55]: df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ["E"])
In [56]: df1.loc[dates[0] : dates[1], "E"] = 1
In [57]: df1 Out[57]: A B C D F E 2013-01-01 0.000000 0.000000 -1.509059 5.0 NaN 1.0 2013-01-02 1.212112 -0.173215 0.119209 5.0 1.0 1.0 2013-01-03 -0.861849 -2.104569 -0.494929 5.0 2.0 NaN 2013-01-04 0.721555 -0.706771 -1.039575 5.0 3.0 NaN
In [63]: s = pd.Series([1, 3, 5, np.nan, 6, 8], index=dates).shift(2)
In [64]: s Out[64]: 2013-01-01 NaN 2013-01-02 NaN 2013-01-03 1.0 2013-01-04 3.0 2013-01-05 5.0 2013-01-06 NaN Freq: D, dtype: float64
In [65]: df.sub(s, axis="index") Out[65]: A B C D F 2013-01-01 NaN NaN NaN NaN NaN 2013-01-02 NaN NaN NaN NaN NaN 2013-01-03 -1.861849 -3.104569 -1.494929 4.0 1.0 2013-01-04 -2.278445 -3.706771 -4.039575 2.0 0.0 2013-01-05 -5.424972 -4.432980 -4.723768 0.0 -1.0 2013-01-06 NaN NaN NaN NaN NaN
In [88]: df Out[88]: A B C D 0 foo one 1.346061 -1.577585 1 bar one 1.511763 0.396823 2 foo two 1.627081 -0.105381 3 bar three -0.990582 -0.532532 4 foo two -0.441652 1.453749 5 bar two 1.211526 1.208843 6 foo one 0.268520 -0.080952 7 foo three 0.024580 -0.264610
In [90]: df.groupby(["A", "B"]).sum() Out[90]: C D A B bar one 1.511763 0.396823 three -0.990582 -0.532532 two 1.211526 1.208843 foo one 1.614581 -1.658537 three 0.024580 -0.264610 two 1.185429 1.348368
In [97]: stacked Out[97]: first second bar one A -0.727965 B -0.589346 two A 0.339969 B -0.693205 baz one A -0.339355 B 0.593616 two A 0.884345 B 1.591431 dtype: float64
In [98]: stacked.unstack() Out[98]: A B first second bar one -0.727965 -0.589346 two 0.339969 -0.693205 baz one -0.339355 0.593616 two 0.884345 1.591431
In [99]: stacked.unstack(1) Out[99]: second one two first bar A -0.727965 0.339969 B -0.589346 -0.693205 baz A -0.339355 0.884345 B 0.593616 1.591431
In [100]: stacked.unstack(0) Out[100]: first bar baz second one A -0.727965 -0.339355 B -0.589346 0.593616 two A 0.339969 0.884345 B -0.693205 1.591431
In [102]: df Out[102]: A B C D E 0 one A foo -1.202872 0.047609 1 one B foo -1.814470 -0.136473 2 two C foo 1.018601 -0.561757 3 three A bar -0.595447 -1.623033 4 one B bar 1.395433 0.029399 5 one C bar -0.392670 -0.542108 6 two A foo 0.007207 0.282696 7 three B foo 1.928123 -0.087302 8 one C foo -0.055224 -1.575170 9 one A bar 2.395985 1.771208 10 two B bar 1.552825 0.816482 11 three C bar 0.166599 1.100230
In [103]: pd.pivot_table(df, values="D", index=["A", "B"], columns=["C"]) Out[103]: C bar foo A B one A 2.395985 -1.202872 B 1.395433 -1.814470 C -0.392670 -0.055224 three A -0.595447 NaN B NaN 1.928123 C 0.166599 NaN two A NaN 0.007207 B 1.552825 NaN C NaN 1.018601
In [121]: df["grade"] Out[121]: 0 very good 1 good 2 good 3 very good 4 very good 5 very bad Name: grade, dtype: category Categories (5, object): ['very bad', 'bad', 'medium', 'good', 'very good']
排序是按类别顺序,而不是字典顺序
1 2 3 4 5 6 7 8 9
In [122]: df.sort_values(by="grade") Out[122]: id raw_grade grade 5 6 e very bad 1 2 b good 2 3 b good 0 1 a very good 3 4 a very good 4 5 a very good
使用 observed=False 按分类列分组也会显示空类别
1 2 3 4 5 6 7 8 9
In [123]: df.groupby("grade", observed=False).size() Out[123]: grade very bad 1 bad 0 medium 0 good 2 very good 3 dtype: int64
In [141]: if pd.Series([False, True, False]): .....: print("I was true") .....: --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-141-b27eb9c1dfc0> in ?() ----> 1 if pd.Series([False, True, False]): 2 print("I was true")
~/work/pandas/pandas/pandas/core/generic.py in ?(self) 1575 @final 1576 def __nonzero__(self) -> NoReturn: -> 1577 raise ValueError( 1578 f"The truth value of a {type(self).__name__} is ambiguous. " 1579 "Use a.empty, a.bool(), a.item(), a.any() or a.all()." 1580 )
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().