运算符是检查、改变、合并值的特殊符号或短语。例如,加号(+)将两个数相加(如 let i = 1 + 2)。更复杂的运算例子包括逻辑与运算符 &&(如 if enteredDoorCode && passedRetinaScan)。
Swift 支持大部分标准 C 语言的运算符,且为了减少常见编码错误做了部分改进。如:赋值符(=)不再有返回值,这样就消除了手误将判等运算符(==)写成赋值符导致代码错误的缺陷。算术运算符(+,-,*,/,% 等)的结果会被检测并禁止值溢出,以此来避免保存变量时由于变量大于或小于其类型所能承载的范围时导致的异常结果。当然允许你使用 Swift 的溢出运算符来实现溢出。详情参见 溢出运算符。
Swift 还提供了 C 语言没有的区间运算符,例如 a..<b 或 a...b,这方便我们表达一个区间内的数值。
本章节只描述了 Swift 中的基本运算符,高级运算符 这章会包含 Swift 中的高级运算符,及如何自定义运算符,及如何进行自定义类型的运算符重载。
let name ="world" if name =="world" { print("hello, world") } else { print("I'm sorry \(name), but I don't recognize you") } // 输出“hello, world", 因为 `name` 就是等于 "world”
Swift 还增加了可选(Optional)类型,用于处理值缺失的情况。可选表示 “那儿有一个值,并且它等于 x ” 或者 “那儿没有值” 。可选有点像在 Objective-C 中使用 nil ,但是它可以用在任何类型上,不仅仅是类。可选类型比 Objective-C 中的 nil 指针更加安全也更具表现力,它是 Swift 许多强大特性的重要组成部分。
Swift 是一门类型安全的语言,这意味着 Swift 可以让你清楚地知道值的类型。如果你的代码需要一个 String ,类型安全会阻止你不小心传入一个 Int 。同样的,如果你的代码需要一个 String,类型安全会阻止你意外传入一个可选的 String 。类型安全可以帮助你在开发阶段尽早发现并修正错误。
let (statusCode, statusMessage) = http404Error print("The status code is \(statusCode)") // 输出“The status code is 404” print("The status message is \(statusMessage)") // 输出“The status message is Not Found”
如果你只需要一部分元组值,分解的时候可以把要忽略的部分用下划线(_)标记:
1 2 3
let (justTheStatusCode, _) = http404Error print("The status code is \(justTheStatusCode)") // 输出“The status code is 404”
此外,你还可以通过下标来访问元组中的单个元素,下标从零开始:
1 2 3 4
print("The status code is \(http404Error.0)") // 输出“The status code is 404” print("The status message is \(http404Error.1)") // 输出“The status message is Not Found”
你可以在定义元组的时候给单个元素命名:
1
let http200Status = (statusCode: 200, description: "OK")
给元组中的元素命名后,你可以通过名字来获取这些元素的值:
1 2 3 4
print("The status code is \(http200Status.statusCode)") // 输出“The status code is 200” print("The status message is \(http200Status.description)") // 输出“The status message is OK”
C 和 Objective-C 中并没有可选类型这个概念。最接近的是 Objective-C 中的一个特性,一个方法要不返回一个对象要不返回 nil,nil 表示“缺少一个合法的对象”。然而,这只对对象起作用——对于结构体,基本的 C 类型或者枚举类型不起作用。对于这些类型,Objective-C 方法一般会返回一个特殊值(比如 NSNotFound)来暗示值缺失。这种方法假设方法的调用者知道并记得对特殊值进行判断。然而,Swift 的可选类型可以让你暗示任意类型的值缺失,并不需要一个特殊值。
来看一个例子。Swift 的 Int 类型有一种构造器,作用是将一个 String 值转换成一个 Int 值。然而,并不是所有的字符串都可以转换成一个整数。字符串 "123" 可以被转换成数字 123 ,但是字符串 "hello, world" 不行。
下面的例子使用这种构造器来尝试将一个 String 转换成 Int:
1 2 3
let possibleNumber ="123" let convertedNumber =Int(possibleNumber) // convertedNumber 被推测为类型 "Int?", 或者类型 "optional Int"
因为该构造器可能会失败,所以它返回一个可选类型(optional)Int,而不是一个 Int。一个可选的 Int 被写作 Int? 而不是 Int。问号暗示包含的值是可选类型,也就是说可能包含 Int 值也可能不包含值。(不能包含其他任何值比如 Bool 值或者 String 值。只能是 Int 或者什么都没有。)
nil
你可以给可选变量赋值为 nil 来表示它没有值:
1 2 3 4
var serverResponseCode: Int? =404 // serverResponseCode 包含一个可选的 Int 值 404 serverResponseCode =nil // serverResponseCode 现在不包含值
iflet actualNumber =Int(possibleNumber) { print("\'\(possibleNumber)\' has an integer value of \(actualNumber)") } else { print("\'\(possibleNumber)\' could not be converted to an integer") } // 输出“'123' has an integer value of 123”
这段代码可以被理解为:
“如果 Int(possibleNumber) 返回的可选 Int 包含一个值,创建一个叫做 actualNumber 的新常量并将可选包含的值赋给它。”
如果转换成功,actualNumber 常量可以在 if 语句的第一个分支中使用。它已经被可选类型 包含的 值初始化过,所以不需要再使用 ! 后缀来获取它的值。在这个例子中,actualNumber 只被用来输出转换结果。
你可以在可选绑定中使用常量和变量。如果你想在 if 语句的第一个分支中操作 actualNumber 的值,你可以改成 if var actualNumber,这样可选类型包含的值就会被赋给一个变量而非常量。
你可以包含多个可选绑定或多个布尔条件在一个 if 语句中,只要使用逗号分开就行。只要有任意一个可选绑定的值为 nil,或者任意一个布尔条件为 false,则整个 if 条件判断为 false,这时你就需要使用嵌套 if 条件语句来处理,如下所示:
if age >10 { print("You can ride the roller-coaster or the ferris wheel.") } elseif age >0 { print("You can ride the ferris wheel.") } else { assertionFailure("A person's age can't be less than zero.") }
(This dissertation explores a junction on the frontiers of two research disciplines in computer science: software and networking. Software research has long been concerned with the categorization of software designs and the development of design methodologies, but has rarely been able to objectively evaluate the impact of various design choices on system behavior. Networking research, in contrast, is focused on the details of generic communication behavior between systems and improving the performance of particular communication techniques, often ignoring the fact that changing the interaction style of an application can have more impact on performance than the communication protocols used for that interaction. My work is motivated by the desire to understand and evaluate the architectural design of network-based application software through principled use of architectural constraints, thereby obtaining the functional, performance, and social properties desired of an architecture. )
二、名称
Fielding将他对互联网软件的架构原则,定名为REST,即Representational State Transfer的缩写。我对这个词组的翻译是"表现层状态转化"。
如果一个架构符合REST原则,就称它为RESTful架构。
**要理解RESTful架构,最好的方法就是去理解Representational State Transfer这个词组到底是什么意思,它的每一个词代表了什么涵义。**如果你把这个名称搞懂了,也就不难体会REST是一种什么样的设计。
... 2022-11-25T11:10:34.006+08:00 INFO 13537 --- [ main] com.itranswarp.learnjava.Application : No active profile set, falling back to 1 default profile: "default"
... 2022-11-25T11:09:02.946+08:00 INFO 13510 --- [ main] com.itranswarp.learnjava.Application : The following 1 profile is active: "test" ... 2022-11-25T11:09:05.124+08:00 INFO 13510 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8000 (http) with context path '' ...
2022-11-25T10:49:31.100+08:00 INFO 13105 --- [ main] com.itranswarp.learnjava.Application : Starting Application using Java 17 with PID 13105 (/Users/liaoxuefeng/Git/springboot-hello/target/classes started by liaoxuefeng in /Users/liaoxuefeng/Git/springboot-hello) 2022-11-25T10:49:31.107+08:00 INFO 13105 --- [ main] com.itranswarp.learnjava.Application : No active profile set, falling back to 1 default profile: "default" 2022-11-25T10:49:32.404+08:00 INFO 13105 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http) 2022-11-25T10:49:32.423+08:00 INFO 13105 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2022-11-25T10:49:32.426+08:00 INFO 13105 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.1] 2022-11-25T10:49:32.549+08:00 INFO 13105 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2022-11-25T10:49:32.551+08:00 INFO 13105 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 1327 ms 2022-11-25T10:49:32.668+08:00 WARN 13105 --- [ main] com.zaxxer.hikari.HikariConfig : HikariPool-1 - idleTimeout is close to or more than maxLifetime, disabling it. 2022-11-25T10:49:32.669+08:00 INFO 13105 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting... 2022-11-25T10:49:32.996+08:00 INFO 13105 --- [ main] com.zaxxer.hikari.pool.PoolBase : HikariPool-1 - Driver does not support get/set network timeout for connections. (feature not supported) 2022-11-25T10:49:32.998+08:00 INFO 13105 --- [ main] com.zaxxer.hikari.pool.HikariPool : HikariPool-1 - Added connection org.hsqldb.jdbc.JDBCConnection@31a2a9fa 2022-11-25T10:49:33.002+08:00 INFO 13105 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed. 2022-11-25T10:49:33.391+08:00 WARN 13105 --- [ main] ocalVariableTableParameterNameDiscoverer : Using deprecated '-debug' fallback for parameter name resolution. Compile the affected code with '-parameters' instead or avoid its introspection: io.pebbletemplates.boot.autoconfigure.PebbleServletWebConfiguration 2022-11-25T10:49:33.398+08:00 WARN 13105 --- [ main] ocalVariableTableParameterNameDiscoverer : Using deprecated '-debug' fallback for parameter name resolution. Compile the affected code with '-parameters' instead or avoid its introspection: io.pebbletemplates.boot.autoconfigure.PebbleAutoConfiguration 2022-11-25T10:49:33.619+08:00 INFO 13105 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '' 2022-11-25T10:49:33.637+08:00 INFO 13105 --- [ main] com.itranswarp.learnjava.Application : Started Application in 3.151 seconds (process running for 3.835)
Spring Boot自动启动了嵌入式Tomcat,当看到Started Application in xxx seconds时,Spring Boot应用启动成功。
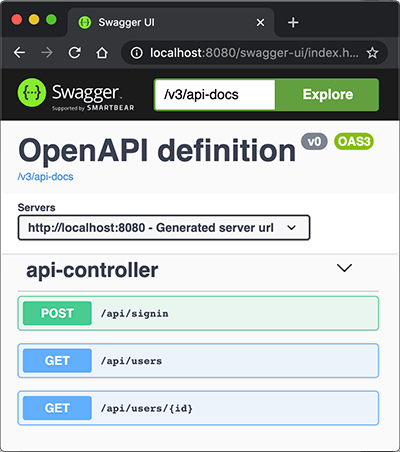
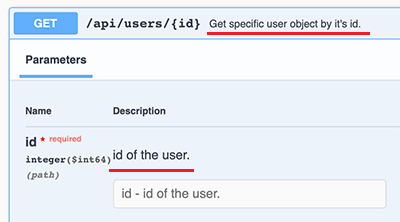
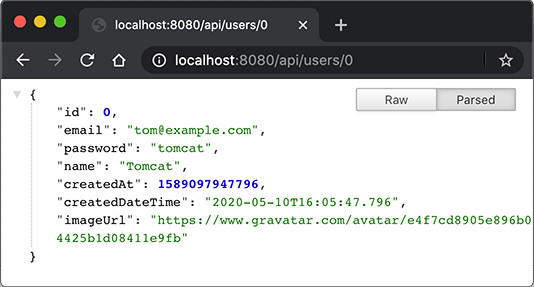
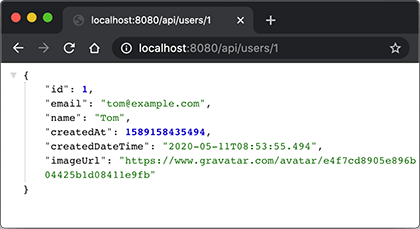
@RestController @RequestMapping("/api") publicclassApiController { ... @Operation(summary = "Get specific user object by it's id.") @GetMapping("/users/{id}") public User user(@Parameter(description = "id of the user.")@PathVariable("id")long id) { return userService.getUserById(id); } ... }
2020-06-02 07:50:21,718 INFO [org.apache.activemq.artemis] AMQ241001: HTTP Server started at http://localhost:8161 2020-06-02 07:50:21,718 INFO [org.apache.activemq.artemis] AMQ241002: Artemis Jolokia REST API available at http://localhost:8161/console/jolokia 2020-06-02 07:50:21,719 INFO [org.apache.activemq.artemis] AMQ241004: Artemis Console available at http://localhost:8161/console
2020-06-02 08:04:27 INFO c.i.learnjava.web.UserController - user registered: bob@example.com 2020-06-02 08:04:27 INFO c.i.l.service.MailMessageListener - received message: ActiveMQMessage[ID:9fc5...]:PERSISTENT/ClientMessageImpl[messageID=983, durable=true, address=jms/queue/mail, ...]] 2020-06-02 08:04:27 INFO c.i.learnjava.service.MailService - [send mail] sending registration mail to bob@example.com... 2020-06-02 08:04:30 INFO c.i.learnjava.service.MailService - [send mail] registration mail was sent to bob@example.com.
2020-06-03 18:47:32 INFO [pool-1-thread-1] c.i.learnjava.service.TaskService - Start check system status... 2020-06-03 18:48:32 INFO [pool-1-thread-1] c.i.learnjava.service.TaskService - Start check system status... 2020-06-03 18:49:32 INFO [pool-1-thread-1] c.i.learnjava.service.TaskService - Start check system status...
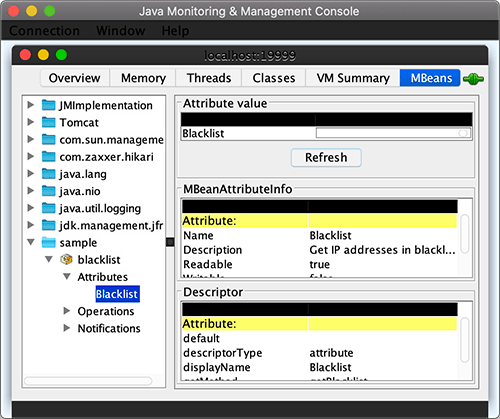
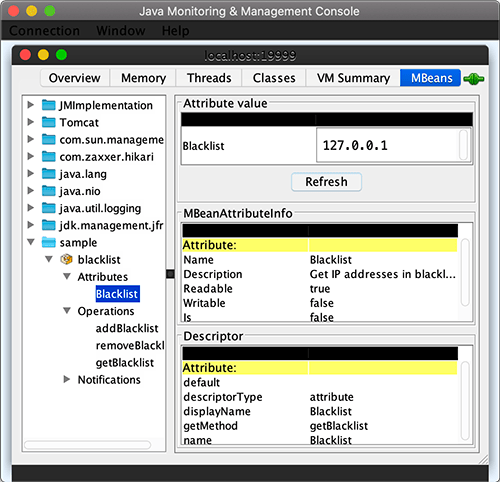
@Component @ManagedResource(objectName = "sample:name=blacklist", description = "Blacklist of IP addresses") publicclassBlacklistMBean { private Set<String> ips = newHashSet<>();
@ManagedAttribute(description = "Get IP addresses in blacklist") public String[] getBlacklist() { return ips.toArray(String[]::new); }
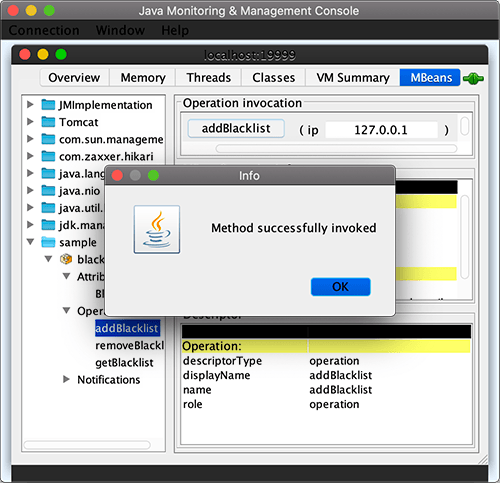
@ManagedOperation @ManagedOperationParameter(name = "ip", description = "Target IP address that will be added to blacklist") publicvoidaddBlacklist(String ip) { ips.add(ip); }
@ManagedOperation @ManagedOperationParameter(name = "ip", description = "Target IP address that will be removed from blacklist") publicvoidremoveBlacklist(String ip) { ips.remove(ip); }
2020-06-06 20:22:12 INFO c.i.l.web.BlacklistInterceptor - check ip address 127.0.0.1... 2020-06-06 20:22:12 WARN c.i.l.web.BlacklistInterceptor - will block ip 127.0.0.1 for it is in blacklist.
2020-05-16 11:22:40 [http-nio-8080-exec-1] INFO c.i.learnjava.web.SyncFilter - start SyncFilter... 2020-05-16 11:22:40 [http-nio-8080-exec-1] INFO c.i.learnjava.web.AsyncFilter - start AsyncFilter... 2020-05-16 11:22:40 [http-nio-8080-exec-1] INFO c.i.learnjava.web.ApiController - get version... 2020-05-16 11:22:40 [http-nio-8080-exec-1] INFO c.i.learnjava.web.AsyncFilter - end AsyncFilter. 2020-05-16 11:22:40 [http-nio-8080-exec-1] INFO c.i.learnjava.web.SyncFilter - end SyncFilter.
可见,每个Filter和ApiController都是由同一个线程执行。
对于异步请求,例如/api/users,我们可以看到如下输出:
1 2 3 4
2020-05-16 11:23:49 [http-nio-8080-exec-4] INFO c.i.learnjava.web.AsyncFilter - start AsyncFilter... 2020-05-16 11:23:49 [http-nio-8080-exec-4] INFO c.i.learnjava.web.ApiController - get users... 2020-05-16 11:23:49 [http-nio-8080-exec-4] INFO c.i.learnjava.web.AsyncFilter - end AsyncFilter. 2020-05-16 11:23:52 [MvcAsync1] INFO c.i.learnjava.web.ApiController - return users...
2020-05-16 11:25:24 [http-nio-8080-exec-8] INFO c.i.learnjava.web.AsyncFilter - start AsyncFilter... 2020-05-16 11:25:24 [http-nio-8080-exec-8] INFO c.i.learnjava.web.AsyncFilter - end AsyncFilter. 2020-05-16 11:25:25 [Thread-2] INFO c.i.learnjava.web.ApiController - deferred result is set.
public User getUserById(long id) { // 注意传入的是ConnectionCallback: return jdbcTemplate.execute((Connection conn) -> { // 可以直接使用conn实例,不要释放它,回调结束后JdbcTemplate自动释放: // 在内部手动创建的PreparedStatement、ResultSet必须用try(...)释放: try (varps= conn.prepareStatement("SELECT * FROM users WHERE id = ?")) { ps.setObject(1, id); try (varrs= ps.executeQuery()) { if (rs.next()) { returnnewUser( // new User object: rs.getLong("id"), // id rs.getString("email"), // email rs.getString("password"), // password rs.getString("name")); // name } thrownewRuntimeException("user not found by id."); } } }); }
public User getUserByName(String name) { // 需要传入SQL语句,以及PreparedStatementCallback: return jdbcTemplate.execute("SELECT * FROM users WHERE name = ?", (PreparedStatement ps) -> { // PreparedStatement实例已经由JdbcTemplate创建,并在回调后自动释放: ps.setObject(1, name); try (varrs= ps.executeQuery()) { if (rs.next()) { returnnewUser( // new User object: rs.getLong("id"), // id rs.getString("email"), // email rs.getString("password"), // password rs.getString("name")); // name } thrownewRuntimeException("user not found by id."); } }); }
public User getUserByEmail(String email) { // 传入SQL,参数和RowMapper实例: return jdbcTemplate.queryForObject("SELECT * FROM users WHERE email = ?", (ResultSet rs, int rowNum) -> { // 将ResultSet的当前行映射为一个JavaBean: returnnewUser( // new User object: rs.getLong("id"), // id rs.getString("email"), // email rs.getString("password"), // password rs.getString("name")); // name }, email); }
publicvoidupdateUser(User user) { // 传入SQL,SQL参数,返回更新的行数: if (1 != jdbcTemplate.update("UPDATE users SET name = ? WHERE id = ?", user.getName(), user.getId())) { thrownewRuntimeException("User not found by id"); } }
@Component @Transactional publicclassUserDaoextendsAbstractDao { public User getById(long id) { return getJdbcTemplate().queryForObject( "SELECT * FROM users WHERE id = ?", newBeanPropertyRowMapper<>(User.class), id ); } ... }
List<User> list = sessionFactory.getCurrentSession() .createQuery("from User u where u.email = ?1 and u.password = ?2", User.class) .setParameter(1, email).setParameter(2, password) .list();
@NamedQueries( @NamedQuery( // 查询名称: name = "login", // 查询语句: query = "SELECT u FROM User u WHERE u.email = :e AND u.password = :pwd" ) ) @Entity publicclassUserextendsAbstractEntity { ... }
public User getUserById(long id) { Useruser=this.em.find(User.class, id); if (user == null) { thrownewRuntimeException("User not found by id: " + id); } return user; }
与HQL查询类似,JPA使用JPQL查询,它的语法和HQL基本差不多:
1 2 3 4 5 6 7 8 9 10
public User fetchUserByEmail(String email) { // JPQL查询: TypedQuery<User> query = em.createQuery("SELECT u FROM User u WHERE u.email = :e", User.class); query.setParameter("e", email); List<User> list = query.getResultList(); if (list.isEmpty()) { returnnull; } return list.get(0); }
同样的,JPA也支持NamedQuery,即先给查询起个名字,再按名字创建查询:
1 2 3 4 5 6 7
public User login(String email, String password) { TypedQuery<User> query = em.createNamedQuery("login", User.class); query.setParameter("e", email); query.setParameter("pwd", password); List<User> list = query.getResultList(); return list.isEmpty() ? null : list.get(0); }
NamedQuery通过注解标注在User类上,它的定义和上一节的User类一样:
1 2 3 4 5 6 7 8 9 10
@NamedQueries( @NamedQuery( name = "login", query = "SELECT u FROM User u WHERE u.email=:e AND u.password=:pwd" ) ) @Entity publicclassUser { ... }
public User getUserById(long id) { // 调用Mapper方法: Useruser= userMapper.getById(id); if (user == null) { thrownewRuntimeException("User not found by id."); } return user; } }
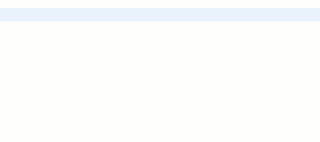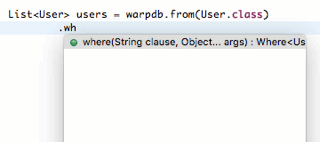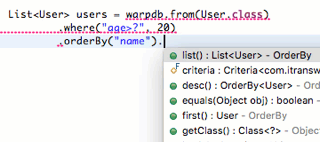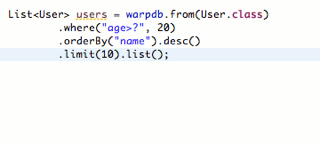
// 按主键查询: SELECT * FROM users WHERE id = ? Useru= db.get(User.class, 123);
// 条件查询唯一记录: SELECT * FROM users WHERE email = ? AND password = ? Useru= db.from(User.class) .where("email=? AND password=?", "bob@example.com", "bob123") .unique();
// 条件查询多条记录: SELECT * FROM users WHERE id < ? ORDER BY email LIMIT ?, ? List<User> us = db.from(User.class) .where("id < ?", 1000) .orderBy("email") .limit(0, 10) .list();
// 查询特定列: SELECT id, name FROM users WHERE email = ? Useru= db.select("id", "name") .from(User.class) .where("email = ?", "bob@example.com") .unique();
Exception in thread "main" java.lang.NullPointerException: zone at java.base/java.util.Objects.requireNonNull(Objects.java:246) at java.base/java.time.Clock.system(Clock.java:203) at java.base/java.time.ZonedDateTime.now(ZonedDateTime.java:216) at com.itranswarp.learnjava.service.MailService.sendMail(MailService.java:19) at com.itranswarp.learnjava.AppConfig.main(AppConfig.java:21)
10:43:09.929 [main] DEBUG org.springframework.aop.framework.CglibAopProxy - Final method [public final java.time.ZoneId xxx.UserService.getFinalZoneId()] cannot get proxied via CGLIB: Calls to this method will NOT be routed to the target instance and might lead to NPEs against uninitialized fields in the proxy instance.