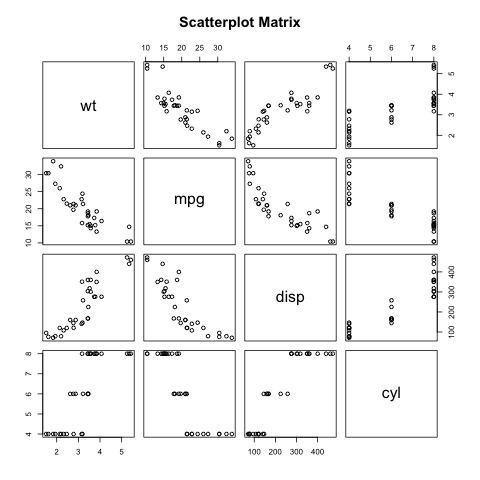
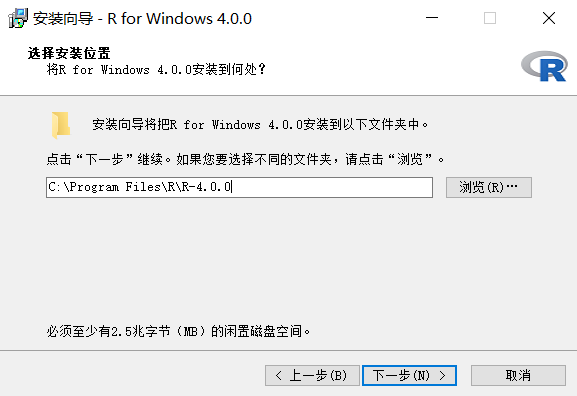
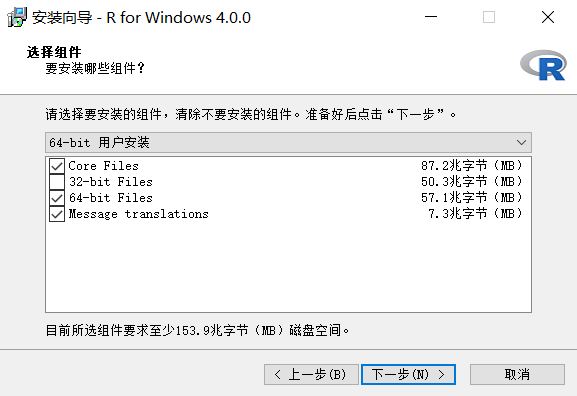
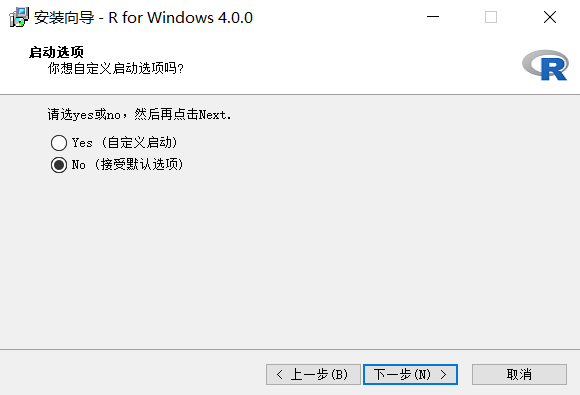
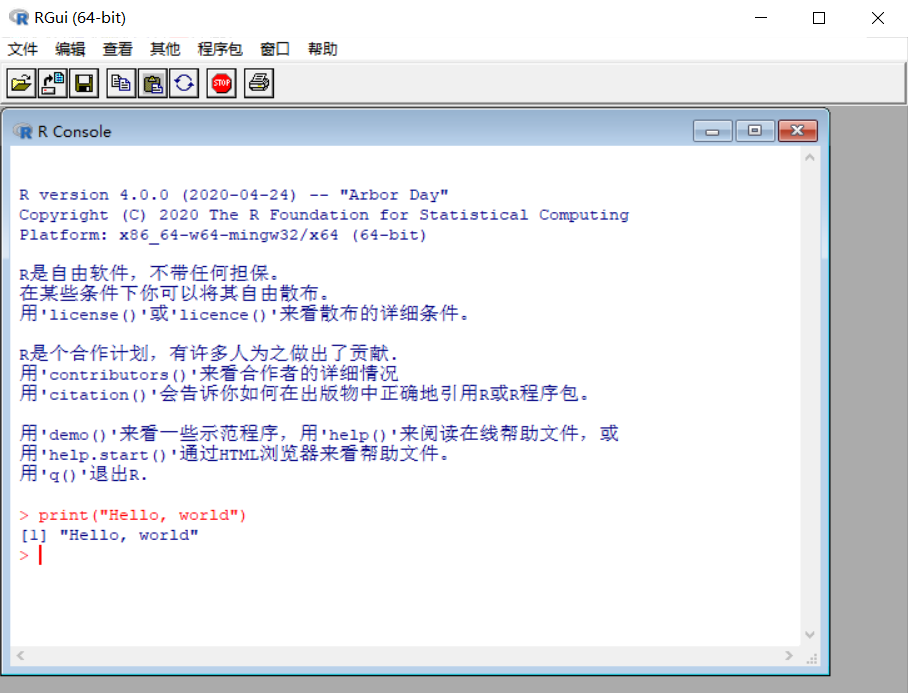
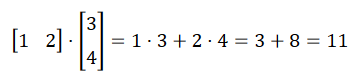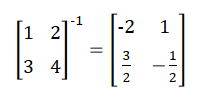R 语言基础
一门新的语言学习一般是从输出 “Hello, World!” 程序开始,R 语言的 “Hello, World!” 程序代码如下:
实例(helloworld.R)
1 2 3 myString <- "Hello, World!" print ( myString )
运行实例 »
以上实例将字符串 “Hello, World!” 赋值给 myString 变量,然后使用 print() 函数输出。
**注意:**R 语言赋值使用的是左箭头 <- 符号,不过一些新版本也支持等号 = 。
变量
R 语言的有效的变量名称由字母,数字以及点号 . 或下划线 _ 组成。
变量名称以字母或点开头。
变量名
是否正确
原因
var_name2.
正确
字符开头,并由字母、数字、下划线和点号组成
var_name%
错误
% 是非法字符
2var_name
错误
不能数字开头
.var_name,var.name
正确
可以 . 号开头,但是要注意 . 号开头后面不能跟着数字
.2var_name
错误
. 号开头后面不能跟着数字
_var_name
错误
不能以下划线 _ 开头
变量赋值
最新版本的 R 语言的赋值可以使用左箭头 <-、等号 = 、右箭头 -> 赋值:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 \# 使用等号 = 号赋值 \> var.1 \= c(0,1,2,3) \> print(var.1) \[1\] 0 1 2 3 \# 使用左箭头 <-赋值 \> var.2 <- c("learn","R") \> print(var.2) \[1\] "learn" "R" \# 使用右箭头 -> 赋值 \> c(TRUE,1) \-> var.3 \> print(var.3) \[1\] 1 1
查看已定义的变量可以使用 ls() 函数:
实例
1 2 \> print(ls()) \[1\] "var.1" "var.2" "var.3"
删除变量可以使用 rm() 函数:
实例
1 2 3 4 \> rm(var.3) \> print(ls()) \[1\] "var.1" "var.2" \>
上一章节中我们已经学会来如何安装 R 的编程环境,接下来我们将为大家介绍 R 语言的交互式编程与文件脚本编程。
交互式编程
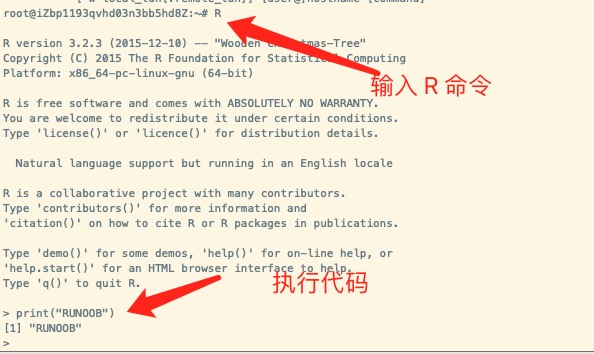
我们只需要在命令行中执行 R 命令就可以进入交互式的编程窗口:
执行完这个命令后会调出 R 语言的解释器,我们在 > 符后面输入代码即可。
交互式命令可以通过输入 q() 来退出:
1 2 > q() Save workspace image? [y/n/c]: y
文件脚本
R 语言文件后缀为 .R。
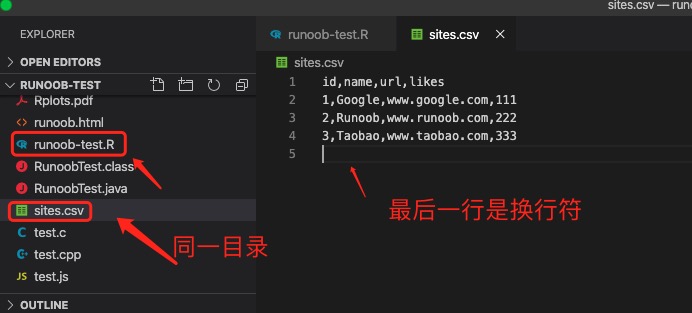
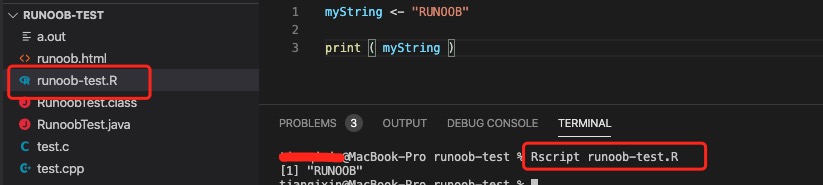
接下来我们创建一个 runoob-test.R 文件:代码如下:
runoob-test.R 文件
myString <- “RUNOOB”
print ( myString )
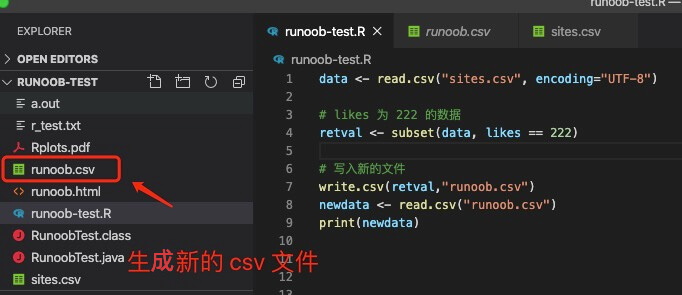
接下来我们在命令行窗口使用 Rscript 来执行该脚本:
输出结果如下:
输入输出
print() 输出
print() 是 R 语言的输出函数。
和其他编程语言一样,R 语言支持数字、字符等输出。
输出的语句十分简单:
1 2 3 print("RUNOOB") print(123) print(3e2)
执行结果:
1 2 3 [1] "RUNOOB" [1] 123 [1] 300
R 语言与 node.js 和 Python 一样,是解释型的语言,所以我们往往可以像使用命令行一样使用 R 语言。
如果我们在一行上进输入一个值,那么 R 也会把它直接标准化输出:
cat() 函数
如果需要输出结果的拼接,我们可以使用 cat() 函数:
实例
1 2 \> cat(1, "加", 1, "等于", 2, '\\n') 1 加 1 等于 2
cat() 函数会在每两个拼接元素之间自动加上空格。
输出内容到文件
R 语言输出到文件的方法十分多样,而且很方便。
cat() 函数支持直接输出结果到文件:
1 cat("RUNOOB", file="/Users/runoob/runoob-test/r_test.txt")
这个语句不会在控制台产生结果,而是把 “RUNOOB” 输出到 “/Users/runoob/runoob-test/r_test.txt” 文件中去。
file 参数可以是绝对路径或相对路径,建议使用绝对路径,Windows 路径格式为 D:\\r_test.txt。
1 cat("RUNOOB", file="D:\\r_test.txt")
注意:这个操作是"覆盖写入"操作,请谨慎使用,因为它会将输出文件的原有数据清除。如果想"追加写入",请不要忘记设置 append 参数:
1 cat("GOOGLE", file="/Users/runoob/runoob-test/r_test.txt", append=TRUE)
执行以上代码后,打开 r_test.txt 文件内容如下:
sink()
sink() 函数可以把控制台输出的文字直接输出到文件中去:
1 sink("/Users/runoob/runoob-test/r_test.txt")
这条语句执行以后,任何控制台上的输出都会被写入到 “/Users/runoob/runoob-test/r_test.txt” 文件中去,控制台将不会显示输出。
注意:这个操作也是"覆盖写入"操作,会直接清除原有的文件内容。
如果我们依然想保留控制台的输出,可以设置 split 属性:
1 sink("/Users/runoob/runoob-test/r_test.txt", split=TRUE)
如果想取消输出到文件,可以调用无参数的 sink :
实例
1 2 3 4 5 6 7 sink("r\_test.txt", split\=TRUE) \# 控制台同样输出 for (i in 1:5) print(i) sink() \# 取消输出到文件 sink("r\_test.txt", append\=TRUE) \# 控制台不输出,追加写入文件 print("RUNOOB")
执行以上代码,当前目录下会生存一个 r_test.txt 文件,打开文件内容如下:
1 2 3 4 5 6 [1] 1 [1] 2 [1] 3 [1] 4 [1] 5 [1] "RUNOOB"
控制台输出为:
1 2 3 4 5 [1] 1 [1] 2 [1] 3 [1] 4 [1] 5
文字输入
可能我们会联想到 C 语言中的 scanf 、Java 中的 java.util.Scanner,如果你学习过 Python 可能对 input() 函数更熟悉。但是 R 语言本身作为一种解释型的语言,更类似于一些终端脚本语言(比如 bash 或者 PowerShell),这些语言是基于命令系统的,本身就需要输入和输出且不适合开发面向用户的应用程序(因为他们本身就是给最终用户使用的)。因此 R 语言没有专门再从控制台读取的函数,文字输入在 R 的使用中一直在进行。
从文件读入文字
R 语言中有丰富的文件读取函数,但是如果纯粹的想将某个文件中的内容读取为字符串,可以使用 readLines 函数:
1 readLines("/Users/runoob/runoob-test/r_test.txt")
执行结果:
读取结果是两个字符串,分别是所读取的文件包含的两行内容。
**注意:**所读取的文本文件每一行 (包括最后一行) 的结束必须有换行符,否则会报错。
其他方式
除了文字的简单输入输出以外,R 还提供了很多输入数据和输出数据的方法,R 语言最方便的地方就是可以将数据结构直接保存到文件中去,而且支持保存为 CSV、Excel 表格等形式,并且支持直接地读取。这对于数学研究者来说无疑是非常方便的。但是这些功能对于 R 语言的学习影响不大,我们将在之后的章节提到。
工作目录
对于文件操作,我们需要设置文件的路径,R 语言可以通过以下两个函数来获取和设置当前的工作目录:
getwd() : 获取当前工作目录setwd() : 设置当前工作目录
实例
1 2 3 4 5 6 7 8 \# 当前工作目录 print(getwd()) \# 设置当前工作目录 setwd("/Users/runoob/runoob-test2") \# 查看当前工作目录 print(getwd())
执行以上代码输出结果为:
1 2 [1] "/Users/runoob/runoob-test" [1] "/Users/tianqixin/runoob-test2"
R 注释
注释主要用于一段代码的解析,可以让阅读者更易理解,编程语言的注释会被编译器忽略掉,且不会影响代码的执行。
一般编程语言的注释分为单行注释与多行注释,但是 R 语言只支持单行注释,注释符号为 #。
其实如果有多行注释我们只需要在每一行添加 # 号就好了。
单行注释
1 2 3 4 \# 这是我的第一个编程代码 myString <- "Hello, World!" print ( myString )
多行注释
1 2 3 4 5 6 7 8 \# R 语言实现两个数相加 \# 变量赋值 a <- 9 b <- 4 \# 输出结果 print(a + b)
其实多行注释还有一个变通的写法,就是使用 if 语言,如下实例:
多行注释
1 2 3 4 5 6 7 8 9 if(FALSE) { " 这是一个多行注释的实例 注释内容放在单引号或双引号之间 " } myString <- "Hello, World!" print ( myString)
R 基础运算
本章介绍 R 语言的简单运算。
赋值
一般语言的赋值是 = 号,但是 R 语言是数学语言,所以赋值符号与我们数学书上的伪代码很相似,是一个左箭头 <- :
实例
1 2 3 a <- 123 b <- 456 print(a + b)
以上代码执行结果:
这个赋值符号是 R 语言的一个形式上的优点和操作上的缺点:形式上更适合数学工作者,毕竟不是所有的数学工作者都习惯于使用 = 作为赋值符号。
操作上来讲,< 符号和 - 符号都不是很好打的字符,这会让很多程序员不适应。因此,R 语言的比较新的版本也支持 = 作为赋值符:
1 2 3 a = 123 b = 456 print(a + b)
这也是合法的 R 程序。
**注意:**很难考证从 R 的哪个版本开始支持了 = 赋值,但是本教程习用的 R 版本是 4.0.0。
数学运算符
下表列出了主要的数学运算符以及他们的运算顺序:
优先级
符号
含义
1
()
括号
2
^
乘方运算
3
%%
整除求余
%/%
整除
4
*
乘法
/
除法
5
+
加法
-
减法
以下实例演示了简单的数学运算:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \> 1 + 2 \* 3 \[1\] 7 \> (1 + 2) \* 3 \[1\] 9 \> 3 / 4 \[1\] 0.75 \> 3.4 \- 1.2 \[1\] 2.2 \> 1 \- 4 \* 0.5^3 \[1\] 0.5 \> 8 / 3 %% 2 \[1\] 8 \> 8 / 4 %% 2 \[1\] Inf \> 3 %% 2^2 \[1\] 3 \> 10 / 3 %/% 2 \[1\] 10
关系运算符
下表列出了 R 语言支持的关系运算符,关系运算符比较两个向量,将第一向量与第二向量的每个元素进行比较,结果返回一个布尔值。
运算符
描述
>
判断第一个向量的每个元素是否大于第二个向量的相对应元素。
<
判断第一个向量的每个元素是否小于第二个向量的相对应元素。
==
判断第一个向量的每个元素是否等于第二个向量的相对应元素。
!=
判断第一个向量的每个元素是否不等于第二个向量的相对应元素。
>=
判断第一个向量的每个元素是否大于等于第二个向量的相对应元素。
<=
判断第一个向量的每个元素是否小于等于第二个向量的相对应元素。
实例
1 2 3 4 5 6 7 8 v <- c(2,4,6,9) t <- c(1,4,7,9) print(v\>t) print(v < t) print(v \== t) print(v!=t) print(v\>=t) print(v<=t)
执行以上代码输出结果为:
1 2 3 4 5 6 [1] TRUE FALSE FALSE FALSE [1] FALSE FALSE TRUE FALSE [1] FALSE TRUE FALSE TRUE [1] TRUE FALSE TRUE FALSE [1] TRUE TRUE FALSE TRUE [1] FALSE TRUE TRUE TRUE
逻辑运算符
下表列出了 R 语言支持的逻辑运算符,可用于数字、逻辑和复数类型的向量。
非 0 的数字(正数或负数)都为 TRUE。
逻辑运算符比较两个向量,将第一向量与第二向量的每个元素进行比较,结果返回一个布尔值。
运算符
描述
&
元素逻辑与运算符,将第一个向量的每个元素与第二个向量的相对应元素进行组合,如果两个元素都为 TRUE,则结果为 TRUE,否则为 FALSE。
|
元素逻辑或运算符,将第一个向量的每个元素与第二个向量的相对应元素进行组合,如果两个元素中有一个为 TRUE,则结果为 TRUE,如果都为 FALSE,则返回 FALSE。
!
逻辑非运算符,返回向量每个元素相反的逻辑值,如果元素为 TRUE 则返回 FALSE,如果元素为 FALSE 则返回 TRUE。
&&
逻辑与运算符,只对两个向量对第一个元素进行判断,如果两个元素都为 TRUE,则结果为 TRUE,否则为 FALSE。
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 v <- c(3,1,TRUE,2+3i) t <- c(4,1,FALSE,2+3i) print(v&t) print(v|t) print(!v) \# &&、||只对第一个元素进行比较 v <- c(3,0,TRUE,2+2i) t <- c(1,3,TRUE,2+3i) print(v&&t) v <- c(0,0,TRUE,2+2i) t <- c(0,3,TRUE,2+3i) print(v||t)
执行以上代码输出结果为:
1 2 3 4 5 [1] TRUE TRUE FALSE TRUE [1] TRUE TRUE TRUE TRUE [1] FALSE FALSE FALSE FALSE [1] TRUE [1] FALSE
赋值运算符
R 语言变量可以使用向左,向右或等于操作符来赋值。
下表列出了 R 语言支持的赋值运算符。
运算符
描述
<−, =,<<−向左赋值。
−>, −>>向右赋值。
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 \# 向左赋值 v1 <- c(3,1,TRUE,"runoob") v2 <<- c(3,1,TRUE,"runoob") v3 \= c(3,1,TRUE,"runoob") print(v1) print(v2) print(v3) \# 向右赋值 c(3,1,TRUE,"runoob") \-> v1 c(3,1,TRUE,"runoob") \->> v2 print(v1) print(v2)
执行以上代码输出结果为:
1 2 3 4 5 [1] "3" "1" "TRUE" "runoob" [1] "3" "1" "TRUE" "runoob" [1] "3" "1" "TRUE" "runoob" [1] "3" "1" "TRUE" "runoob" [1] "3" "1" "TRUE" "runoob"
其他运算符
R 语言还包含了一些特别的运算符。
运算符
描述
:
冒号运算符,用于创建一系列数字的向量。
%in%
用于判断元素是否在向量里,返回布尔值,有的话返回 TRUE,没有返回 FALSE。
%*%
用于矩阵与它转置的矩阵相乘。
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 \# 1 到 10 的向量 v <- 1:10 print(v) \# 判断数字是否在向量 v 中 v1 <- 3 v2 <- 15 print(v1 %in% v) print(v2 %in% v) \# 矩阵与它转置的矩阵相乘 M \= matrix( c(2,6,5,1,10,4), nrow \= 2,ncol \= 3,byrow \= TRUE) t \= M %\*% t(M) print(t)
执行以上代码输出结果为:
1 2 3 4 5 6 [1] 1 2 3 4 5 6 7 8 9 10 [1] TRUE [1] FALSE [,1] [,2] [1,] 65 82 [2,] 82 117
数学函数
常见对一些数学函数有:
函数
说明
sqrt(n)
n的平方根
exp(n)
自然常数e的n次方,
log(m,n)
m的对数函数,返回n的几次方等于m
log10(m)
相当于log(m,10)
以下实例演示了数学函数的应用:
实例
1 2 3 4 5 6 7 8 9 10 \> sqrt(4) \[1\] 2 \> exp(1) \[1\] 2.718282 \> exp(2) \[1\] 7.389056 \> log(2,4) \[1\] 0.5 \> log10(10000) \[1\] 4
取整函数:
名称
参数模型
含义
round
(n)
对 n 四舍五入取整
(n, m)
对 n 保留 m 位小数四舍五入
ceiling
(n)
对 n 向上取整
floor
(n)
对 n 向下取整
以下实例演示了取整函数的应用:
实例
1 2 3 4 5 6 7 8 \> round(1.5) \[1\] 2 \> round(2.5) \[1\] 2 \> round(3.5) \[1\] 4 \> round(4.5) \[1\] 4
注意 :R 中的 round 函数有些情况下可能会"舍掉五"。
当取整位是偶数的时候,五也会被舍去,这一点与 C 语言有所不同。
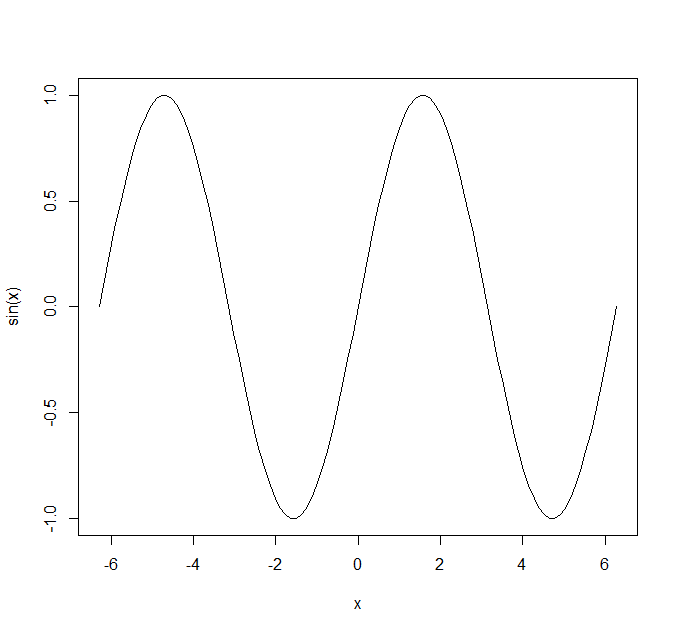
R 的三角函数是弧度制:
实例
1 2 3 4 5 6 \> sin(pi/6) \[1\] 0.5 \> cos(pi/4) \[1\] 0.7071068 \> tan(pi/3) \[1\] 1.732051
反三角函数:
实例
1 2 3 4 5 6 \> asin(0.5) \[1\] 0.5235988 \> acos(0.7071068) \[1\] 0.7853981 \> atan(1.732051) \[1\] 1.047198
如果学习过概率论和统计学,应该对以下的概率分布函数比较了解,因为 R 语言为数学工作者设计,所以经常会用到:
实例
1 2 3 4 5 6 7 8 \> dnorm(0) \[1\] 0.3989423 \> pnorm(0) \[1\] 0.5 \> qnorm(0.95) \[1\] 1.644854 \> rnorm(3, 5, 2) \# 产生 3 个平均值为 5,标准差为 2 的正态随机数 \[1\] 4.177589 6.413927 4.206032
这四个都是用来计算正态分布的函数。它们的名字都以 norm 结尾,代表"正态分布"。
分布函数名字的前缀有四种:
d - 概率密度函数p - 概率密度积分函数(从无限小到 x 的积分)q - 分位数函数r - 随机数函数(常用于概率仿真)
注 :由于本教程不是阐述数学专业理论的教程,所以对有关概率分布的数学理论不作详细解释。R 语言除了含有正态分布函数以外还有泊松分布 (pois, Poisson) 等常见分布函数,如果想详细了解可以学习"概率论与数理统计"。
R 数据类型
数据类型指的是用于声明不同类型的变量或函数的一个广泛的系统。
变量的类型决定了变量存储占用的空间,以及如何解释存储的位模式。
R 语言中的最基本数据类型主要有三种:
数字常量主要有两种:
一般型
123 -0.125
科学计数法
1.23e2 -1.25E-1
逻辑类型在许多其他编程语言中常称为布尔型(Boolean),常量值只有 TRUE 和 FALSE 。
**注意:**R 语言区分大小写,true 或 True 不能代表 TRUE。
最直观的数据类型就是文本类型。文本就是其它语言中常出现的字符串(String),常量用双引号包含。在 R 语言中,文本常量既可以用单引号包含,也可以用双引号包含,例如:
实例
1 2 \> 'runoob' \== "runoob" \[1\] TRUE
有关于 R 语言的变量定义,并不像一些强类型语言中的语法规则,需要专门为变量设置名称和数据类型,每当在 R 中使用赋值运算符时,实际上就是定义了一个新的变量:
实例
1 2 3 a \= 1 b <- TRUE b \= "abc"
按对象类型来分是以下 6 种(后面会详细介绍这几种类型):
向量
向量(Vector)在 Java、Rust、C# 这些专门编程的的语言的标准库里往往会提供,这是因为向量在数学运算中是不可或缺的工具——我们最常见的向量是二维向量,这种向量在平面坐标系中必然会用到。
向量从数据结构上看就是一个线性表,可以看成一个数组。
R 语言中向量作为一种类型存在可以让向量的操作变得更加容易:
实例
1 2 3 4 5 \> a \= c(3, 4) \> b \= c(5, 0) \> a + b \[1\] 8 4 \>
c() 是一个创造向量的函数。
这里把两个二维向量相加,得到一个新的二维向量 (8, 4)。如果将一个二维向量和三维向量做运算,将失去数学意义,虽然不会停止运行,但会被警告。
我建议大家从习惯上杜绝这种情况的出现。
向量中的每一个元素可以通过下标单独取出:
实例
1 2 3 \> a \= c(10, 20, 30, 40, 50) \> a\[2\] \[1\] 20
**注意:**R 语言中的"下标"不代表偏移量,而代表第几个,也就是说是从 1 开始的!
R 也可以方便的取出向量的一部分:
实例
1 2 3 4 5 6 \> a\[1:4\] \# 取出第 1 到 4 项,包含第 1 和第 4 项 \[1\] 10 20 30 40 \> a\[c(1, 3, 5)\] \# 取出第 1, 3, 5 项 \[1\] 10 30 50 \> a\[c(\-1, \-5)\] \# 去掉第 1 和第 5 项 \[1\] 20 30 40
这三种部分取出方法是最常用的。
向量支持标量计算:
实例
1 2 3 4 5 \> c(1.1, 1.2, 1.3) \- 0.5 \[1\] 0.6 0.7 0.8 \> a \= c(1,2) \> a ^ 2 \[1\] 1 4
之前讲述的常用的数学运算函数,如 sqrt 、exp 等,同样可以用于对向量作标量运算。
"向量"作为线性表结构,应该具备一些常用的线性表处理函数,R 确实具备这些函数:
向量排序:
实例
1 2 3 4 5 6 7 8 9 \> a \= c(1, 3, 5, 2, 4, 6) \> sort(a) \[1\] 1 2 3 4 5 6 \> rev(a) \[1\] 6 4 2 5 3 1 \> order(a) \[1\] 1 4 2 5 3 6 \> a\[order(a)\] \[1\] 1 2 3 4 5 6
order() 函数返回的是一个向量排序之后的下标向量。
向量统计
R 中有十分完整的统计学函数:
函数名 含义
sum
求和
mean
求平均值
var
方差
sd
标准差
min
最小值
max
最大值
range
取值范围(二维向量,最大值和最小值)
向量统计实例:
实例
1 2 3 4 5 6 \> sum(1:5) \[1\] 15 \> sd(1:5) \[1\] 1.581139 \> range(1:5) \[1\] 1 5
向量生成
向量的生成可以用 c() 函数生成,也可以用 min:max 运算符生成连续的序列。
如果想生成有间隙的等差数列,可以用 seq 函数:
1 2 > seq(1, 9, 2) [1] 1 3 5 7 9
seq 还可以生成从 m 到 n 的等差数列,只需要指定 m, n 以及数列的长度:
1 2 > seq(0, 1, length.out=3) [1] 0.0 0.5 1.0
rep 是 repeat(重复)的意思,可以用于产生重复出现的数字序列:
1 2 > rep(0, 5) [1] 0 0 0 0 0
向量中常会用到 NA 和 NULL ,这里介绍一下这两个词语与区别:
NA 代表的是"缺失",NULL 代表的是"不存在"。
NA 缺失就像占位符,代表这里没有一个值,但位置存在。
NULL 代表的就是数据不存在。
实例说明:
实例
1 2 3 4 \> length(c(NA, NA, NULL)) \[1\] 2 \> c(NA, NA, NULL, NA) \[1\] NA NA NA
很显然, NULL 在向量中没有任何意义。
逻辑型
逻辑向量主要用于向量的逻辑运算,例如:
实例
1 2 \> c(11, 12, 13) \> 12 \[1\] FALSE FALSE TRUE
which 函数是十分常见的逻辑型向量处理函数,可以用于筛选我们需要的数据的下标:
实例
1 2 3 4 5 6 \> a \= c(11, 12, 13) \> b \= a \> 12 \> print(b) \[1\] FALSE FALSE TRUE \> which(b) \[1\] 3
例如我们需要从一个线性表中筛选大于等于 60 且小于 70 的数据:
实例
1 2 3 \> vector \= c(10, 40, 78, 64, 53, 62, 69, 70) \> print(vector\[which(vector \>= 60 & vector < 70)\]) \[1\] 64 62 69
类似的函数还有 all 和 any:
实例
1 2 3 4 5 6 7 8 \> all(c(TRUE, TRUE, TRUE)) \[1\] TRUE \> all(c(TRUE, TRUE, FALSE)) \[1\] FALSE \> any(c(TRUE, FALSE, FALSE)) \[1\] TRUE \> any(c(FALSE, FALSE, FALSE)) \[1\] FALSE
all() 用于检查逻辑向量是否全部为 TRUE,any() 用于检查逻辑向量是否含有 TRUE。
字符串
字符串数据类型本身并不复杂,这里注重介绍字符串的操作函数:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 \> toupper("Runoob") \# 转换为大写 \[1\] "RUNOOB" \> tolower("Runoob") \# 转换为小写 \[1\] "runoob" \> nchar("中文", type\="bytes") \# 统计字节长度 \[1\] 4 \> nchar("中文", type\="char") \# 总计字符数量 \[1\] 2 \> substr("123456789", 1, 5) \# 截取字符串,从 1 到 5 \[1\] "12345" \> substring("1234567890", 5) \# 截取字符串,从 5 到结束 \[1\] "567890" \> as.numeric("12") \# 将字符串转换为数字 \[1\] 12 \> as.character(12.34) \# 将数字转换为字符串 \[1\] "12.34" \> strsplit("2019;10;1", ";") \# 分隔符拆分字符串 \[\[1\]\] \[1\] "2019" "10" "1" \> gsub("/", "-", "2019/10/1") \# 替换字符串 \[1\] "2019-10-1"
在 Windows 计算机上实现,使用的是 GBK 编码标准,所以一个中文字符是两个字节,如果在 UTF-8 编码的计算机上运行,单个中文字符的字节长度应该是 3。
R 支持 perl 语言格式的正则表达式:
实例
1 2 \> gsub("\[\[:alpha:\]\]+", "$", "Two words") \[1\] "$ $"
更多字符串内容参考:R 语言字符串介绍 。
矩阵
R 语言为线性代数的研究提供了矩阵类型,这种数据结构很类似于其它语言中的二维数组,但 R 提供了语言级的矩阵运算支持。
首先看看矩阵的生成:
实例
1 2 3 4 5 \> vector\=c(1, 2, 3, 4, 5, 6) \> matrix(vector, 2, 3) \[,1\] \[,2\] \[,3\] \[1,\] 1 3 5 \[2,\] 2 4 6
矩阵初始化内容是由一个向量来传递的,其次要表达一个矩阵有几行、有几列。
向量中的值会一列一列的填充到矩阵中。如果想按行填充,需要指定 byrow 属性:
实例
1 2 3 4 \> matrix(vector, 2, 3, byrow\=TRUE) \[,1\] \[,2\] \[,3\] \[1,\] 1 2 3 \[2,\] 4 5 6
矩阵中的每一个值都可以被直接访问:
实例
1 2 3 4 5 \> m1 \= matrix(vector, 2, 3, byrow\=TRUE) \> m1\[1,1\] \# 第 1 行 第 1 列 \[1\] 1 \> m1\[1,3\] \# 第 1 行 第 3 列 \[1\] 3
R 中的矩阵的每一个列和每一行都可以设定名称,这个过程通过字符串向量批量完成:
实例
1 2 3 4 5 6 7 8 9 \> colnames(m1) \= c("x", "y", "z") \> rownames(m1) \= c("a", "b") \> m1 x y z a 1 2 3 b 4 5 6 \> m1\["a", \] x y z 1 2 3
矩阵的四则运算与向量基本一致,既可以与标量做运算,也可以与同规模的矩阵做对应位置的运算。
矩阵乘法运算:
实例
1 2 3 4 5 \> m1 \= matrix(c(1, 2), 1, 2) \> m2 \= matrix(c(3, 4), 2, 1) \> m1 %\*% m2 \[,1\] \[1,\] 11
逆矩阵:
实例
1 2 3 4 5 \> A \= matrix(c(1, 3, 2, 4), 2, 2) \> solve(A) \[,1\] \[,2\] \[1,\] \-2.0 1.0 \[2,\] 1.5 \-0.5
solve() 函数用于求解线性代数方程,基本用法是 solve(A,b),其中,A 为方程组的系数矩阵,b 方程的向量或矩阵。
apply() 函数可以将矩阵的每一行或每一列当作向量来进行操作:
实例
1 2 3 4 5 6 7 8 \> (A \= matrix(c(1, 3, 2, 4), 2, 2)) \[,1\] \[,2\] \[1,\] 1 2 \[2,\] 3 4 \> apply(A, 1, sum) \# 第二个参数为 1 按行操作,用 sum() 函数 \[1\] 3 7 \> apply(A, 2, sum) \# 第二个参数为 2 按列操作 \[1\] 4 6
更多矩阵内容参考:R 矩阵 。
R 判断语句
判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的)。
下面是大多数编程语言中典型的判断结构的一般形式:
R 语言提供了以下类型的判断语句:
if 语句
if…else 语句
switch 语句
if 语句
一个 if 语句 由一个布尔表达式后跟一个或多个语句组成。
语法格式如下:
1 2 3 if(boolean_expression) { // 布尔表达式为真将执行的语句 }
如果布尔表达式 boolean_expression 为 ture 执行这里面的代码,如果 为 false 则不执行。
实例
1 2 3 4 x <- 50L if(is.integer(x)) { print("X 是一个整数") }
执行以上代码,输出结果为:
if…else 语句
一个 if 语句 后可跟一个可选的 else 语句,else 语句在布尔表达式为假时执行。
语法格式如下:
1 2 3 4 5 if(boolean_expression) { // 如果布尔表达式为真将执行的语句 } else { // 如果布尔表达式为假将执行的语句 }
如果布尔表达式 boolean_expression 为 true,则执行 if 块内的代码。如果布尔表达式为 false,则执行 else 块内的代码。
实例
1 2 3 4 5 6 7 x <- c("google","runoob","taobao") if("runoob" %in% x) { print("包含 runoob") } else { print("不包含 runoob") }
执行以上代码,输出结果为:
如果有多个条件判断,可以使用 if…else if…else:
1 2 3 4 5 6 7 8 9 if(boolean_expression 1) { // 如果布尔表达式 boolean_expression 1 为真将执行的语句 } else if( boolean_expression 2) { // 如果布尔表达式 boolean_expression 2 为真将执行的语句 } else if( boolean_expression 3) { // 如果布尔表达式 boolean_expression 3 为真将执行的语句 } else { // 以上所有的布尔表达式都为 false 时执行 }
实例
1 2 3 4 5 6 7 8 9 x <- c("google","runoob","taobao") if("weibo" %in% x) { print("第一个 if 包含 weibo") } else if ("runoob" %in% x) { print("第二个 if 包含 runoob") } else { print("没有找到") }
执行以上代码,输出结果为:
switch 语句
一个 switch 语句允许测试一个变量等于多个值时的情况。每个值称为一个 case。
语法格式如下:
1 switch(expression, case1, case2, case3....)
switch 语句必须遵循下面的规则:
switch 语句中的 expression 是一个常量表达式,可以是整数或字符串,如果是整数则返回对应的 case 位置值,如果整数不在位置的范围内则返回 NULL。如果匹配到多个值则返回第一个。
expression 如果是字符串,则对应的是 case 中的变量名对应的值,没有匹配则没有返回值。switch 没有默认参数可用。
以下实例返回第三个值:
实例
1 2 3 4 5 6 7 8 x <- switch( 3, "google", "runoob", "taobao", "weibo" ) print(x)
执行以上代码,输出结果为:
如果是字符串返回字符串变量对应的值:
实例
1 2 you.like<-"runoob" switch(you.like, google\="www.google.com", runoob \= "www.runoob.com", taobao \= "www.taobao.com")
执行以上代码,输出结果为:
如果整数不在范围内的则返回 NULL
实例
1 2 3 4 5 6 \> x <- switch(4,"google","runoob","taobao") \> x NULL \> x <- switch(4,"google","runoob","taobao") \> x NULL
R 循环
有的时候,我们可能需要多次执行同一块代码。一般情况下,语句是按顺序执行的:函数中的第一个语句先执行,接着是第二个语句,依此类推。
编程语言提供了更为复杂执行路径的多种控制结构。
循环语句允许我们多次执行一个语句或语句组,下面是大多数编程语言中循环语句的�流程图:
R 语言提供的循环类型有:
repeat 循环
while 循环
for 循环
R 语言提供的循环控制语句有:
循环控制语句改变你代码的执行顺序,通过它你可以实现代码的跳转。
循环类型
repeat
repeat 循环会一直执行代码,直到条件语句为 true 时才退出循环,退出要使用到 break 语句。
语法格式如下:
1 2 3 4 5 6 repeat { // 相关代码 if(condition) { break } }
以下实例在变量 cnt 为 5 时退出循环,cnt 为计数变量:
实例
1 2 3 4 5 6 7 8 9 10 11 v <- c("Google","Runoob") cnt <- 2 repeat { print(v) cnt <- cnt+1 if(cnt \> 5) { break } }
执行以上代码,输入结果为:
1 2 3 4 [1] "Google" "Runoob" [1] "Google" "Runoob" [1] "Google" "Runoob" [1] "Google" "Runoob"
while
只要给定的条件为 true,R 语言中的 while 循环语句会重复执行一个目标语句。
语法格式如下:
1 2 3 4 while(condition) { statement(s); }
在这里,statement(s) 可以是一个单独的语句,也可以是几个语句组成的代码块。
condition 可以是任意的表达式,当为任意非零值时都为 true。当条件为 true 时执行循环。 当条件为 false 时,退出循环,程序流将继续执行紧接着循环的下一条语句。
以下实例在在变量 cnt 小于 7 时输出 while 语句块中的内容,cnt 为计数变量:
实例
1 2 3 4 5 6 7 v <- c("Google","Runoob") cnt <- 2 while (cnt < 7) { print(v) cnt \= cnt + 1 }
执行以上代码,输入结果为:
1 2 3 4 5 [1] "Google" "Runoob" [1] "Google" "Runoob" [1] "Google" "Runoob" [1] "Google" "Runoob" [1] "Google" "Runoob"
for
R 编程语言中 for 循环语句可以重复执行指定语句,重复次数可在 for 语句中控制。
语法格式如下:
1 2 3 for (value in vector) { statements }
R 语言的 for 循环特别灵活,不仅可以循环整数变量,还可以对字符向量,逻辑向量,列表等数据类型进行迭代。
以下实例输出 26 个字母对前面四个字母:
实例
1 2 3 4 v <- LETTERS\[1:4\] for ( i in v) { print(i) }
执行以上代码,输入结果为:
1 2 3 4 [1] "A" [1] "B" [1] "C" [1] "D"
循环控制
break
R 语言的 break 语句插入在循环体中,用于退出当前循环或语句,并开始脚本执行紧接着的语句。
如果你使用循环嵌套,break 语句将停止最内层循环的执行,并开始执行的外层的循环语句。
break 也常用于 switch 语句中。
语法格式如下:
以下实例在变量 cnt 为 5 时使用 break 退出循环,cnt 为计数变量:
实例
1 2 3 4 5 6 7 8 9 10 11 v <- c("Google","Runoob") cnt <- 2 repeat { print(v) cnt <- cnt+1 if(cnt \> 5) { break } }
执行以上代码,输入结果为:
1 2 3 4 [1] "Google" "Runoob" [1] "Google" "Runoob" [1] "Google" "Runoob" [1] "Google" "Runoob"
next
next 语句用于跳过当前循环,开始下一次循环(类似其他语言的 continue)。
语法格式如下:
以下实例输出 26 个字母的前面 6 个字母,在字母为 D 的时候跳过当前的循环,进行下一次循环:
实例
1 2 3 4 5 6 7 8 v <- LETTERS\[1:6\] for ( i in v) { if (i \== "D") { \# D 不会输出,跳过这次循环,进入下一次 next } print(i) }
执行以上代码,输入结果为:
1 2 3 4 5 [1] "A" [1] "B" [1] "C" [1] "E" [1] "F"
R 函数
函数是一组一起执行一个任务的语句。R 语言本身提供了很多的内置函数,当然我们也可以自己创建函数。
您可以把代码划分到不同的函数中。如何划分代码到不同的函数中是由您来决定的,但在逻辑上,划分通常是根据每个函数执行一个特定的任务来进行的。
函数声明 告诉编译器函数的名称、返回类型和参数。函数定义 提供了函数的实际主体。
R 语言中函数是一个对象,可以拥有属性。
定义函数
函数定义通常由以下几个部分组成:
函数名: 为函数指定一个唯一的名称,以便在调用时使用。参数: 定义函数接受的输入值。参数是可选的,可以有多个。函数体: 包含实际执行的代码块,用大括号 {} 括起来。返回值: 指定函数的输出结果,使用关键字return。
R 语言中的函数定义使用 function 关键字,一般形式如下:
1 2 3 4 5 function_name <- function(arg_1, arg_2, ...) { # 函数体 # 执行的代码块 return(output) }
说明:
function_name : 为函数名
arg_1, arg_2, … : 形式参数列表
函数返回值使用 return()。
以下是一个简单的例子,展示如何定义和使用函数:
实例
1 2 3 4 5 6 7 8 9 \# 定义一个加法函数 add\_numbers <- function(x, y) { result <- x + y return(result) } \# 调用函数 sum\_result <- add\_numbers(3, 4) print(sum\_result) \# 输出 7
以上代码中,我们定义了一个名为 add_numbers 的函数,它接受两个参数 x 和 y 。函数体中的代码将这两个参数相加,并将结果存储在变量 result 中。最后,使用 return 关键字返回结果。
要调用函数,我们使用函数名后跟参数列表的形式,将参数的值传递给函数。在本例中,我们调用 add_numbers 函数,并传递参数 3 和 4。函数执行后,返回结果 7,我们将其存储在变量 sum_result 中,并打印输出。
自定义函数
我们可以自己创建函数,用于特定到功能,定义后可以向内置函数一样使用它们。
下面演示两如何自定义函数:
实例
1 2 3 4 5 6 7 \# 定义一个函数,用于计数一个系列到平方值 new.function <- function(a) { for(i in 1:a) { b <- i^2 print(b) } }
接下来我们可以调用函数:
实例
1 2 3 4 5 6 7 8 9 new.function <- function(a) { for(i in 1:a) { b <- i^2 print(b) } } \# 调用函数,并传递参数 new.function(6)
执行以上代码,输出结果为:
1 2 3 4 5 6 [1] 1 [1] 4 [1] 9 [1] 16 [1] 25 [1] 36
我们也可以创建一个不带参数的函数:
实例
1 2 3 4 5 6 7 8 new.function <- function() { for(i in 1:5) { print(i^2) } } \# 调用函数,不需要传递参数 new.function()
执行以上代码,输出结果为:
1 2 3 4 5 [1] 1 [1] 4 [1] 9 [1] 16 [1] 25
带有参数值的函数
函数参数,可以按函数创建时的顺序来传递,也可以不按顺序,但需要指定参数名:
实例
1 2 3 4 5 6 7 8 9 10 11 \# 创建函数 new.function <- function(a,b,c) { result <- a \* b + c print(result) } \# 不带参数名 new.function(5,3,11) \# 带参数名 new.function(a \= 11, b \= 5, c \= 3)
执行以上代码,输出结果为:
函数创建时也可以为参数指定默认值,如果调用的时候不传递参数就会使用默认值:
实例
1 2 3 4 5 6 7 8 9 10 11 \# 创建带默认参数的函数 new.function <- function(a \= 3, b \= 6) { result <- a \* b print(result) } \# 调用函数,但不传递参数,会使用默认的 new.function() \# 调用函数,传递参数 new.function(9,5)
执行以上代码,输出结果为:
[1] 18 [1] 45
懒惰计算的函数
懒惰计算将推迟计算工作直到系统需要这些计算的结果。如果不需要结果,将不用进行计算。
默认情况下,R 函数对参数的计算是懒惰的,就是只有我们在计算它的时候才会调用:
实例
1 2 3 4 f <- function(x) { 10 } f()
执行以上代码,输出结果为:
以上代码执行,并没有报错,虽然我们没有传入参数,但函数体内没有使用参数 x,所以不会去调用它,也不会报错。
实例
1 2 3 4 5 6 7 8 new.function <- function(a, b) { print(a^2) print(a) print(b) \# 使用到 b,但未传入,所以会报错 } \# 传入一个参数 new.function(6)
执行以上代码,输出结果为:
1 2 3 4 5 [1] 36 [1] 6 Error in print(b) : 缺少参数"b",也没有缺省值 Calls: new.function -> print 停止执行
内置函数
R 语言提供了很多有用的内置函数,我们无需定义它就可以直接使用。
例如:seq(), mean(), max(), sum(x) 以及 paste(…) 等。
实例
1 2 3 4 5 6 7 8 \# 输出 32 到 44 到的所有数字 print(seq(32,44)) \# 计算两个数的平均数 print(mean(25:82)) \# 计算 41 到 68 所有数字之和 print(sum(41:68))
执行以上代码,输出结果为:
1 2 3 [1] 32 33 34 35 36 37 38 39 40 41 42 43 44 [1] 53.5 [1] 1526
sum(): 计算向量或矩阵的总和。
实例
1 2 3 4 5 6 7 8 9 \# 向量求和 x <- c(1, 2, 3, 4, 5) total <- sum(x) print(total) \# 输出 15 \# 矩阵求和 matrix <- matrix(1:9, nrow \= 3) total <- sum(matrix) print(total) \# 输出 45
mean(): 计算向量或矩阵的平均值。
实例
1 2 3 4 5 6 7 8 9 \# 向量平均值 x <- c(1, 2, 3, 4, 5) avg <- mean(x) print(avg) \# 输出 3 \# 矩阵平均值 matrix <- matrix(1:9, nrow \= 3) avg <- mean(matrix) print(avg) \# 输出 5
paste(): 将多个字符串连接成一个字符串。
实例
1 2 3 4 x <- "Hello" y <- "World" result <- paste(x, y) print(result) \# 输出 "Hello World"
length(): 返回向量的长度或对象的元素个数。
实例
1 2 3 4 5 6 7 x <- c(1, 2, 3, 4, 5) length\_x <- length(x) print(length\_x) \# 输出 5 matrix <- matrix(1:9, nrow \= 3) length\_matrix <- length(matrix) print(length\_matrix) \# 输出 9
str(): 显示对象的结构和内容摘要。
实例
1 2 3 4 5 6 7 8 9 x <- c(1, 2, 3, 4, 5) str(x) \# 输出: \# num \[1:5\] 1 2 3 4 5 matrix <- matrix(1:9, nrow \= 3) str(matrix) \# 输出: \# int \[1:3, 1:3\] 1 2 3 4 5 6 7 8 9
以上只列举了一小部分的 R 语言函数实例,R 有大量的内置函数和扩展包提供的函数,可以满足各种数据处理、统计分析、绘图等需求,您可以查阅 R 语言的官方文档获得更详细的函数列表和使用说明。
R 字符串
R 语言中,字符串是一种表示文本数据的数据类型,它由字符(字符向量)组成,可以包含字母、数字、符号和空格等字符。
R 语言字符串可以使用一对单引号 ’ ’ 或一对双引号 " " 来表示。
单引号字符串中可以包含双引号。
单引号字符串中不可以包含单引号。
双引号字符串中可以包含单引号。
双引号字符串中不可以包含双引号。
**创建字符串:**您可以使用单引号或双引号来创建字符串。
以下实例演示来字符串的使用:
实例
1 2 3 4 5 6 7 8 9 10 11 a <- '使用单引号' print(a) b <- "使用双引号" print(b) c <- "双引号字符串中可以包含单引号(') " print(c) d <- '单引号字符串中可以包含双引号(") ' print(d)
执行以上代码输出结果为:
1 2 3 4 [1] "使用单引号" [1] "使用双引号" [1] "双引号字符串中可以包含单引号(') " [1] "单引号字符串中可以包含双引号(\") "
字符串操作
R 语言提供了多种操作字符串的函数和操作符,使得处理和操作文本数据变得方便。
以下我们来看下 R 语言一些内置函数对字符串对操作。
paste() 函数
paste() 函数用于使用指定对分隔符来对字符串进行连接,默认的分隔符为空格。
语法格式:
1 paste(..., sep = " ", collapse = NULL)
参数说明:
… : 字符串列表
sep : 分隔符,默认为空格
collapse : 两个或者更多字符串对象根据元素对应关系拼接到一起,在字符串进行连接后,再使用 collapse 指定对连接符进行连接
实例
1 2 3 4 5 6 7 8 9 10 a <- "Google" b <- 'Runoob' c <- "Taobao" print(paste(a,b,c)) print(paste(a,b,c, sep \= "-")) print(paste(letters\[1:6\],1:6, sep \= "", collapse \= "=")) paste(letters\[1:6\],1:6, collapse \= ".")
执行以上代码输出结果为:
1 2 3 4 [1] "Google Runoob Taobao" [1] "Google-Runoob-Taobao" [1] "a1=b2=c3=d4=e5=f6" [1] "a 1.b 2.c 3.d 4.e 5.f 6"
format() 函数用于格式化字符串,format() 可作用于字符串或数字。
语法格式:
1 format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))
参数说明:
x : 输入对向量
digits : 显示的位数
nsmall : 小数点右边显示的最少位数
scientific : 设置科学计数法
width : 通过开头填充空白来显示最小的宽度
justify:设置位置,显示可以是左边、右边、中间等。
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 \# 显示 9 位,最后一位四舍五入 result <- format(23.123456789, digits \= 9) print(result) \# 使用科学计数法显示 result <- format(c(6, 13.14521), scientific \= TRUE) print(result) \# 小数点右边最小显示 5 位,没有的以 0 补充 result <- format(23.47, nsmall \= 5) print(result) \# 将数字转为字符串 result <- format(6) print(result) \# 宽度为 6 位,不够的在开头添加空格 result <- format(13.7, width \= 6) print(result) \# 左对齐字符串 result <- format("Runoob", width \= 9, justify \= "l") print(result) \# 居中显示 result <- format("Runoob", width \= 10, justify \= "c") print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 7 [1] "23.1234568" [1] "6.000000e+00" "1.314521e+01" [1] "23.47000" [1] "6" [1] " 13.7" [1] "Runoob " [1] " Runoob "
nchar() 函数
nchar() 函数用于计数字符串或数字列表的长度。
语法格式:
参数说明:
实例
1 2 result <- nchar("Google Runoob Taobao") print(result)
执行以上代码输出结果为:
toupper() & tolower() 函数
toupper() & tolower() 函数用于将字符串的字母转化为大写或者小写。
语法格式:
参数说明:
# 转大写
实例
1 2 3 4 5 6 result <- toupper("Runoob") print(result) \# 转小写 result <- tolower("Runoob") print(result)
执行以上代码输出结果为:
1 2 [1] "RUNOOB" [1] "runoob"
substring() 函数
substring() 函数用于截取字符串。
语法格式:
参数说明:
x : 向量或字符串
first : 开始截取的位置
last: 结束截取的位置
实例
1 2 3 \# 从第 2 位截取到第 5 位 result <- substring("Runoob", 2, 5) print(result)
执行以上代码输出结果为:
字符串替换
使用 gsub() 函数来替换字符串中的特定字符或模式。
实例
1 2 3 str <- "Hello, World!" new\_str <- gsub("World", "R", str) \# 输出: "Hello, R!"
字符串拆分
使用 strsplit() 函数将字符串拆分为子字符串。
实例
1 2 3 4 5 str <- "Hello, World!" split\_str <- strsplit(str, ",") \# 输出: List of 1 \# \[\[1\]\] \# \[1\] "Hello" " World!"
以上只列举了一小部分的 R 语言字符串操作实例,R 有大量的字符串处理函数和操作符,例如模式匹配、大小写转换、字符串比较等,您可以查阅 R 语言的官方文档获得更多字符串操作函数列表和使用说明。
R 列表
列表是 R 语言的对象集合,可以用来保存不同类型的数据,可以是数字、字符串、向量、另一个列表、矩阵、数据框等,当然还可以包含矩阵和函数。
列表是一种灵活的数据结构,可以存储和操作多种类型的数据对象。
创建列表
R 语言创建列表使用 list() 函数。
如下实例,我们创建一个列表,包含了字符串、向量和数字:
实例
1 2 list\_data <- list("runoob", "google", c(11,22,33), 123, 51.23, 119.1) print(list\_data)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [[1]] [1] "runoob" [[2]] [1] "google" [[3]] [1] 11 22 33 [[4]] [1] 123 [[5]] [1] 51.23 [[6]] [1] 119.1
我们也可以使用 c() 函数来创建列表,也可以使用该函数将多个对象合并为一个列表,例如:
1 my_list <- c(object1, object2, object3)
实例
1 2 3 4 5 6 7 8 9 10 11 \# 创建包含数字的向量 numbers <- c(1, 2, 3, 4, 5) \# 创建包含字符的向量 characters <- c("apple", "banana", "orange") \# 合并两个数字向量 merged\_vector <- c(numbers, c(6, 7, 8)) \# 合并两个字符向量 merged\_characters <- c(characters, c("grape", "melon"))
我们可以使用 names() 函数给列表的元素命名:
实例
1 2 3 4 5 6 7 8 9 \# 列表包含向量、矩阵、列表 list\_data <- list(c("Google","Runoob","Taobao"), matrix(c(1,2,3,4,5,6), nrow \= 2), list("runoob",12.3)) \# 给列表元素设置名字 names(list\_data) <- c("Sites", "Numbers", "Lists") \# 显示列表 print(list\_data)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $Sites [1] "Google" "Runoob" "Taobao" $Numbers [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 $Lists $Lists[[1]] [1] "runoob" $Lists[[2]] [1] 12.3
访问列表
列表中的元素可以使用索引来访问,如果使用来 names() 函数命名后,我们还可以使用对应名字来访问:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 \# 列表包含向量、矩阵、列表 list\_data <- list(c("Google","Runoob","Taobao"), matrix(c(1,2,3,4,5,6), nrow \= 2), list("runoob",12.3)) \# 给列表元素设置名字 names(list\_data) <- c("Sites", "Numbers", "Lists") \# 显示列表 print(list\_data\[1\]) \# 访问列表的第三个元素 print(list\_data\[3\]) \# 访问第一个向量元素 print(list\_data$Numbers)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $Sites [1] "Google" "Runoob" "Taobao" $Lists $Lists[[1]] [1] "runoob" $Lists[[2]] [1] 12.3 [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6
操作列表元素
我们可以对列表进行添加、删除、更新的操作,如下实例:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 \# 列表包含向量、矩阵、列表 list\_data <- list(c("Google","Runoob","Taobao"), matrix(c(1,2,3,4,5,6), nrow \= 2), list("runoob",12.3)) \# 给列表元素设置名字 names(list\_data) <- c("Sites", "Numbers", "Lists") \# 添加元素 list\_data\[4\] <- "新元素" print(list\_data\[4\]) \# 删除元素 list\_data\[4\] <- NULL \# 删除后输出为 NULL print(list\_data\[4\]) \# 更新元素 list\_data\[3\] <- "我替换来第三个元素" print(list\_data\[3\])
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 [[1]] [1] "新元素" $<NA> NULL $Lists [1] "我替换来第三个元素"
使用 for 循环遍历列表时:
实例
1 2 3 4 5 6 7 \# 创建一个包含数字和字符的列表 my\_list <- list(1, 2, 3, "a", "b", "c") \# 使用 for 循环遍历列表中的每个元素 for (element in my\_list) { print(element) }
在以上代码中,for 循环会依次遍历列表 my_list 中的每个元素,并将每个元素存储在变量 element 中。然后,我们可以在循环体内对每个元素执行特定的操作,例如使用 print() 函数打印元素的值。
for 循环遍历列表时,每次循环都将当前元素赋值给变量 element。因此,在循环体内可以对 element 进行任何需要的操作,例如计算、条件判断等。
需要注意的是,使用 for 循环遍历列表时,循环变量 element 将依次取到列表中的每个元素,但不能直接修改列表元素本身。如果需要修改列表中的元素值,可以通过索引来实现,例如 my_list[[index]] <- new_value。
执行以上代码输出结果为:
1 2 3 4 5 6 [1] 1 [1] 2 [1] 3 [1] "a" [1] "b" [1] "c"
合并列表
我们可以使用 c() 函数将多个列表合并为一个列表:
实例
1 2 3 4 5 6 7 8 9 \# 创建两个列表 list1 <- list(1,2,3) list2 <- list("Google","Runoob","Taobao") \# 合并列表 merged.list <- c(list1,list2) \# 显示合并后的列表 print(merged.list)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [[1]] [1] 1 [[2]] [1] 2 [[3]] [1] 3 [[4]] [1] "Google" [[5]] [1] "Runoob" [[6]] [1] "Taobao"
列表转换为向量
要将列表转换为向量可以使用 unlist() 函数,将列表转换为向量,可以方便我们进行算术运算:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 \# 创建列表 list1 <- list(1:5) print(list1) list2 <-list(10:14) print(list2) \# 转换为向量 v1 <- unlist(list1) v2 <- unlist(list2) print(v1) print(v2) \# 两个向量相加 result <- v1+v2 print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 [[1]] [1] 1 2 3 4 5 [[1]] [1] 10 11 12 13 14 [1] 1 2 3 4 5 [1] 10 11 12 13 14 [1] 11 13 15 17 19
归纳总结
以下是一些常用的 R 语言列表操作和函数:
创建列表:
使用 c() 函数:例如,list1 <- c(1, 2, 3) 创建一个包含 1、2 和 3 的列表。
使用 list() 函数:例如,list2 <- list(1, “a”, TRUE) 创建一个包含不同类型元素的列表。
访问列表元素:
使用索引:通过索引访问列表中的元素。例如,list1[1] 返回列表中的第一个元素。
使用元素名称:如果列表中的元素有名称,可以使用名称来访问它们。例如,list3 <- list(a = 1, b = 2) 可以通过 list3a 和 list3b 来访问元素。
列表操作:
长度:使用 length() 函数获取列表的长度。例如,length(list1) 返回列表 list1 的长度。
合并:使用 c() 函数或 append() 函数将两个或多个列表合并为一个列表。例如,list4 <- c(list1, list2) 合并列表 list1 和 list2。
增加元素:使用 c() 函数将元素添加到现有列表中。例如,list1 <- c(list1, 4) 将 4 添加到列表 list1 的末尾。
删除元素:使用索引和负索引操作符 - 删除列表中的元素。例如,list1 <- list1[-2] 删除列表 list1 中的第二个元素。
列表循环:
for 循环:使用 for 循环遍历列表中的元素。例如,for (element in list1) { … } 遍历列表 list1 中的每个元素。
lapply() 函数:将一个函数应用于列表中的每个元素,并返回结果列表。例如,new_list <- lapply(list1, function(x) x * 2) 将列表 list1 中的每个元素乘以 2。
R 矩阵
R 语言为线性代数的研究提供了矩阵类型,这种数据结构很类似于其它语言中的二维数组,但 R 提供了语言级的矩阵运算支持。
矩阵里的元素可以是数字、符号或数学式。
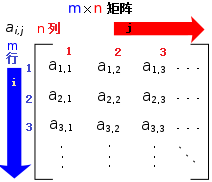
一个 M x N 的矩阵是一个由 M(row) 行 和 **N 列(column)**元素排列成的矩形阵列。
以下是一个由 6 个数字元素构成的 2 行 3 列的矩阵:
R 语言的矩阵可以使用 matrix() 函数来创建,语法格式如下:
1 matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE,dimnames = NULL)
参数说明:
创建一个数字矩阵:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 \# byrow 为 TRUE 元素按行排列 M <- matrix(c(3:14), nrow \= 4, byrow \= TRUE) print(M) \# Ebyrow 为 FALSE 元素按列排列 N <- matrix(c(3:14), nrow \= 4, byrow \= FALSE) print(N) \# 定义行和列的名称 rownames \= c("row1", "row2", "row3", "row4") colnames \= c("col1", "col2", "col3") P <- matrix(c(3:14), nrow \= 4, byrow \= TRUE, dimnames \= list(rownames, colnames)) print(P)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [,1] [,2] [,3] [1,] 3 4 5 [2,] 6 7 8 [3,] 9 10 11 [4,] 12 13 14 [,1] [,2] [,3] [1,] 3 7 11 [2,] 4 8 12 [3,] 5 9 13 [4,] 6 10 14 col1 col2 col3 row1 3 4 5 row2 6 7 8 row3 9 10 11 row4 12 13 14
转置矩阵
R 语言矩阵提供了 t() 函数,可以实现矩阵的行列互换。
例如有个 m 行 n 列的矩阵,使用 t() 函数就能转换为 n 行 m 列的矩阵。
实例
1 2 3 4 5 6 7 8 \# 创建一个 2 行 3 列的矩阵 M \= matrix( c(2,6,5,1,10,4), nrow \= 2,ncol \= 3,byrow \= TRUE) print(M) \[,1\] \[,2\] \[,3\] \[1,\] 2 6 5 \[2,\] 1 10 4 \# 转换为 3 行 2 列的矩阵 print(t(M))
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 [,1] [,2] [,3] [1,] 2 6 5 [2,] 1 10 4 [1] "-----转换-----" [,1] [,2] [1,] 2 1 [2,] 6 10 [3,] 5 4
访问矩阵元素
如果想获取矩阵元素,可以通过使用元素的列索引和行索引,类似坐标形式。
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \# 定义行和列的名称 rownames \= c("row1", "row2", "row3", "row4") colnames \= c("col1", "col2", "col3") \# 创建矩阵 P <- matrix(c(3:14), nrow \= 4, byrow \= TRUE, dimnames \= list(rownames, colnames)) print(P) \# 获取第一行第三列的元素 print(P\[1,3\]) \# 获取第四行第二列的元素 print(P\[4,2\]) \# 获取第二行 print(P\[2,\]) \# 获取第三列 print(P\[,3\])
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 col1 col2 col3 row1 3 4 5 row2 6 7 8 row3 9 10 11 row4 12 13 14 [1] 5 [1] 13 col1 col2 col3 6 7 8 row1 row2 row3 row4 5 8 11 14
矩阵计算
大小相同(行数列数都相同)的矩阵之间可以相互加减,具体是对每个位置上的元素做加减法。矩阵的乘法则较为复杂。两个矩阵可以相乘,当且仅当第一个矩阵的列数等于第二个矩阵的行数。
矩阵加减法
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 \# 创建 2 行 3 列的矩阵 matrix1 <- matrix(c(7, 9, \-1, 4, 2, 3), nrow \= 2) print(matrix1) matrix2 <- matrix(c(6, 1, 0, 9, 3, 2), nrow \= 2) print(matrix2) \# 两个矩阵相加 result <- matrix1 + matrix2 cat("相加结果:","\\n") print(result) \# 两个矩阵相减 result <- matrix1 \- matrix2 cat("相减结果:","\\n") print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [,1] [,2] [,3] [1,] 7 -1 2 [2,] 9 4 3 [,1] [,2] [,3] [1,] 6 0 3 [2,] 1 9 2 相加结果: [,1] [,2] [,3] [1,] 13 -1 5 [2,] 10 13 5 相减结果: [,1] [,2] [,3] [1,] 1 -1 -1 [2,] 8 -5 1
矩阵乘除法
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 \# 创建 2 行 3 列的矩阵 matrix1 <- matrix(c(7, 9, \-1, 4, 2, 3), nrow \= 2) print(matrix1) matrix2 <- matrix(c(6, 1, 0, 9, 3, 2), nrow \= 2) print(matrix2) \# 两个矩阵相乘 result <- matrix1 \* matrix2 cat("相乘结果:","\\n") print(result) \# 两个矩阵相除 result <- matrix1 / matrix2 cat("相除结果:","\\n") print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [,1] [,2] [,3] [1,] 7 -1 2 [2,] 9 4 3 [,1] [,2] [,3] [1,] 6 0 3 [2,] 1 9 2 相乘结果: [,1] [,2] [,3] [1,] 42 0 6 [2,] 9 36 6 相除结果: [,1] [,2] [,3] [1,] 1.166667 -Inf 0.6666667 [2,] 9.000000 0.4444444 1.5000000
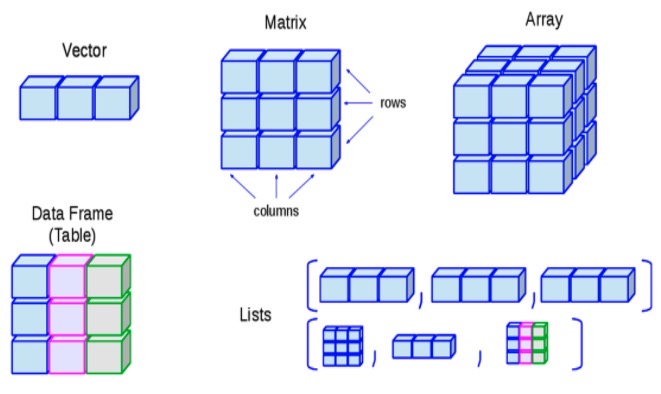
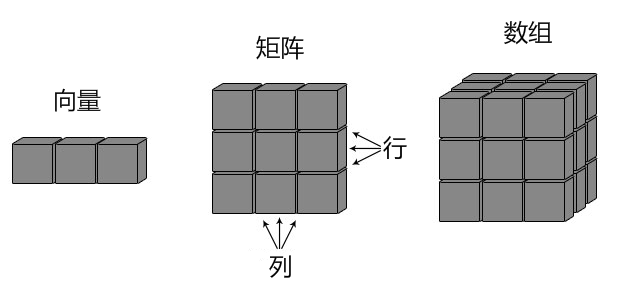
R 数组
数组也是 R 语言的对象,R 语言可以创建一维或多维数组。
R 语言数组是一个同一类型的集合,前面我们学的矩阵 matrix 其实就是一个二维数组。
向量、矩阵、数组关系可以看下图:
R 语言数组创建使用 array() 函数,该函数使用向量作为输入参数,可以使用 dim 设置数组维度。
array() 函数语法格式如下:
1 array(data = NA, dim = length(data), dimnames = NULL)
参数说明:
data - 指定数组的数据源,可以是一个向量、矩阵或列表。dim - 指定数组的维度,可以是一个整数向量或一个表示维度的元组,默认是一维数组。例如,dim = c(2, 3, 4) 表示创建一个 2x3x4 的三维数组。dimnames - 可选参数,用于指定数组每个维度的名称,可以是一个包含维度名称的列表。
在 R 中,数组索引是从 1 开始的,与其他编程语言的习惯有所不同。
此外,R 还提供了丰富的函数和操作符用于处理数组数据,如索引、切片、重塑、聚合等。
在 R 中,可以使用矩阵(Matrix) 或列表(List) 来表示多维数组。
**矩阵(Matrix):**矩阵是 R 中最常用的表示数组的形式,它是一个二维的结构,具有固定的行数和列数。
可以使用 matrix() 函数创建矩阵,指定数据元素和维度。
实例
1 2 3 \# 创建一个3x3的矩阵 my\_matrix <- matrix(c(1, 2, 3, 4, 5, 6, 7, 8, 9), nrow \= 3, ncol \= 3) print(my\_matrix)
列表(List) :列表是 R 中更通用的多维数组形式,它可以包含不同类型的元素,并且每个元素可以是一个矩阵、向量或其他数据结构。
实例
1 2 3 \# 创建一个包含矩阵和向量的列表 my\_list <- list(matrix(c(1, 2, 3, 4), nrow \= 2), c(5, 6, 7)) print(my\_list)
实例
1 2 3 \# 创建一个包含矩阵和向量的列表 my\_list <- list(matrix(c(1, 2, 3, 4), nrow \= 2), c(5, 6, 7)) print(my\_list)
除了矩阵和列表,R 还提供了其他数据结构来表示多维数组,如数组(Array)和数据帧(Data Frame)。
实例
下面是一些示例来演示 array() 函数的使用:
使用向量创建一维数组:
实例
1 2 3 my\_vector <- c(1, 2, 3, 4) my\_array <- array(my\_vector, dim \= c(4)) print(my\_array)
以下实例我们创建一个 3 行 3 列的的二维数组:
实例
1 2 3 4 5 6 7 \# 创建两个不同长度的向量 vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) \# 创建数组 result <- array(c(vector1,vector2),dim \= c(3,3,2)) print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 , , 1 [,1] [,2] [,3] [1,] 5 10 13 [2,] 9 11 14 [3,] 3 12 15 , , 2 [,1] [,2] [,3] [1,] 5 10 13 [2,] 9 11 14 [3,] 3 12 15
使用 dimnames 参数来设置各个维度的名称::
实例
1 2 3 4 5 6 7 8 9 10 \# 创建两个不同长度的向量 vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) column.names <- c("COL1","COL2","COL3") row.names <- c("ROW1","ROW2","ROW3") matrix.names <- c("Matrix1","Matrix2") \# 创建数组,并设置各个维度的名称 result <- array(c(vector1,vector2),dim \= c(3,3,2),dimnames \= list(row.names,column.names,matrix.names)) print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 , , Matrix1 COL1 COL2 COL3 ROW1 5 10 13 ROW2 9 11 14 ROW3 3 12 15 , , Matrix2 COL1 COL2 COL3 ROW1 5 10 13 ROW2 9 11 14 ROW3 3 12 15
访问数组元素
在 R 语言中,可以使用索引操作符 [ ] 来访问多维数组的元素。
索引操作符允许您按照指定的索引位置获取数组中的特定元素。
如果想获取数组元素,可以通过使用元素的列索引和行索引,类似坐标形式。
访问单个元素:
实例
1 2 3 my\_array <- array(1:12, dim \= c(2, 3, 2)) \# 创建一个3维数组 element <- my\_array\[1, 2, 1\] \# 访问第一个维度为1,第二个维度为2,第三个维度为1的元素 print(element)
访问多个元素:
实例
1 2 3 my\_array <- array(1:12, dim \= c(2, 3, 2)) \# 创建一个3维数组 elements <- my\_array\[c(1, 2), c(2, 3), c(1, 2)\] \# 访问多个元素,其中每个维度的索引分别为1和2 print(elements)
访问二维数组的元素:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \# 创建两个不同长度的向量 vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) column.names <- c("COL1","COL2","COL3") row.names <- c("ROW1","ROW2","ROW3") matrix.names <- c("Matrix1","Matrix2") \# 创建数组 result <- array(c(vector1,vector2),dim \= c(3,3,2),dimnames \= list(row.names, column.names, matrix.names)) \# 显示数组第二个矩阵中第三行的元素 print(result\[3,,2\]) \# 显示数组第一个矩阵中第一行第三列的元素 print(result\[1,3,1\]) \# 输出第二个矩阵 print(result\[,,2\])
执行以上代码输出结果为:
1 2 3 4 5 6 7 COL1 COL2 COL3 3 12 15 [1] 13 COL1 COL2 COL3 ROW1 5 10 13 ROW2 9 11 14 ROW3 3 12 15
使用逻辑条件进行筛选:
实例
1 2 3 my\_array <- array(1:12, dim \= c(2, 3, 2)) \# 创建一个3维数组 filtered\_elements <- my\_array\[my\_array \> 5\] \# 选择大于5的元素 print(filtered\_elements) \# 输出:6 7 8 9 10 11 12
操作数组元素
由于数组是由多个维度的矩阵组成,所以我们可以通过访问矩阵的元素来访问数组元素。
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 \# 创建两个不同长度的向量 vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) \# 创建数组 array1 <- array(c(vector1,vector2),dim \= c(3,3,2)) \# 创建两个不同长度的向量 vector3 <- c(9,1,0) vector4 <- c(6,0,11,3,14,1,2,6,9) array2 <- array(c(vector3,vector4),dim \= c(3,3,2)) \# 从数组中创建矩阵 matrix1 <- array1\[,,2\] matrix2 <- array2\[,,2\] \# 矩阵相加 result <- matrix1+matrix2 print(result)
执行以上代码输出结果为:
1 2 3 4 [,1] [,2] [,3] [1,] 7 19 19 [2,] 15 12 14 [3,] 12 12 26
另外我们可以使用 apply() 元素对数组元素进行跨维度计算,语法格式如下:
1 apply(X, MARGIN, FUN, ...)
参数说明:
X:要应用函数的数组或矩阵。MARGIN:指定应用函数的维度,可以是1表示行,2表示列,或者c(1, 2)表示同时应用于行和列。FUN:要应用的函数,可以是内置函数(如mean、sum等)或自定义函数。...:可选参数,用于传递给函数的其他参数。
以下我们使用 apply() 函数来计算数组两个矩阵中每一行对数字之和。
实例
1 2 3 4 5 6 7 8 9 10 11 \# 创建两个不同长度的向量 vector1 <- c(5,9,3) vector2 <- c(10,11,12,13,14,15) \# 创建数组 new.array <- array(c(vector1,vector2),dim \= c(3,3,2)) print(new.array) \# 计算数组中所有矩阵第一行的数字之和 result <- apply(new.array, c(1), sum) print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 , , 1 [,1] [,2] [,3] [1,] 5 10 13 [2,] 9 11 14 [3,] 3 12 15 , , 2 [,1] [,2] [,3] [1,] 5 10 13 [2,] 9 11 14 [3,] 3 12 15 [1] 56 68 60
对矩阵的行或列应用内置函数:
实例
1 2 3 4 5 \# 创建一个3x3的矩阵 my\_matrix <- matrix(1:9, nrow \= 3) \# 对每列应用sum函数 col\_sums <- apply(my\_matrix, 2, sum) print(col\_sums)
执行以上代码输出结果为:
对矩阵的行或列应用自定义函数:
实例
1 2 3 4 5 6 7 8 9 \# 创建一个3x3的矩阵 my\_matrix <- matrix(1:9, nrow \= 3) \# 自定义函数:计算每行的平均值 row\_mean <- function(x) { return(mean(x)) } \# 对每行应用row\_mean函数 row\_means <- apply(my\_matrix, 1, row\_mean) print(row\_means)
执行以上代码输出结果为:
对数组的多个维度同时应用函数:
实例
1 2 3 4 5 \# 创建一个3维数组 my\_array <- array(1:12, dim \= c(2, 3, 2)) \# 对第一个和第三个维度同时应用mean函数 result <- apply(my\_array, c(1, 3), mean) print(result)
执行以上代码输出结果为:
1 2 3 [,1] [,2] [1,] 3 9 [2,] 4 10
R 因子
因子用于存储不同类别的数据类型,例如人的性别有男和女两个类别,年龄来分可以有未成年人和成年人。
R 语言创建因子使用 factor() 函数,向量作为输入参数。
factor() 函数语法格式:
1 2 factor(x = character(), levels, labels = levels, exclude = NA, ordered = is.ordered(x), nmax = NA)
参数说明:
x:向量。
levels:指定各水平值, 不指定时由x的不同值来求得。
labels:水平的标签, 不指定时用各水平值的对应字符串。
exclude:排除的字符。
ordered:逻辑值,用于指定水平是否有序。
nmax:水平的上限数量。
以下实例把字符型向量转换成因子:
实例
1 2 3 4 x <- c("男", "女", "男", "男", "女") sex <- factor(x) print(sex) print(is.factor(sex))
执行以上代码输出结果为:
1 2 3 [1] 男 女 男 男 女 Levels: 男 女 [1] TRUE
以下实例设置因子水平为 c(‘男’,‘女’):
实例
1 2 3 4 x <- c("男", "女", "男", "男", "女",levels\=c('男','女')) sex <- factor(x) print(sex) print(is.factor(sex))
执行以上代码输出结果为:
1 2 3 4 levels1 levels2 男 女 男 男 女 男 女 Levels: 男 女 [1] TRUE
因子水平标签
接下来我们使用 labels 参数为每个因子水平添加标签,labels 参数的字符顺序,要和 levels 参数的字符顺序保持一致,例如:
实例
1 2 sex\=factor(c('f','m','f','f','m'),levels\=c('f','m'),labels\=c('female','male'),ordered\=TRUE) print(sex)
执行以上代码输出结果为:
1 2 [1] female male female female male Levels: female < male
生成因子水平
我们可以使用 gl() 函数来生成因子水平,语法格式如下:
1 gl(n, k, length = n*k, labels = seq_len(n), ordered = FALSE)
参数说明:
n : 设置 level 的个数k : 设置每个 level 重复的次数length : 设置长度labels : 设置 level 的值ordered : 设置是否 level 是排列好顺序的,布尔值。
实例
1 2 v <- gl(3, 4, labels \= c("Google", "Runoob","Taobao")) print(v)
执行以上代码输出结果为:
1 2 3 [1] Google Google Google Google Runoob Runoob Runoob Runoob Taobao Taobao [11] Taobao Taobao Levels: Google Runoob Taobao
R 数据框
数据框(Data frame)可以理解成我们常说的"表格"。
数据框是 R 语言的数据结构,是特殊的二维列表。
数据框每一列都有一个唯一的列名,长度都是相等的,同一列的数据类型需要一致,不同列的数据类型可以不一样。
R 语言数据框使用 data.frame() 函数来创建,语法格式如下:
1 2 3 data.frame(…, row.names = NULL, check.rows = FALSE, check.names = TRUE, fix.empty.names = TRUE, stringsAsFactors = default.stringsAsFactors())
… : 列向量,可以是任何类型(字符型、数值型、逻辑型),一般以 tag = value 的形式表示,也可以是 value。row.names : 行名,默认为 NULL,可以设置为单个数字、字符串或字符串和数字的向量。check.rows : 检测行的名称和长度是否一致。check.names : 检测数据框的变量名是否合法。fix.empty.names : 设置未命名的参数是否自动设置名字。stringsAsFactors : 布尔值,字符是否转换为因子,factory-fresh 的默认值是 TRUE,可以通过设置选项(stringsAsFactors=FALSE)来修改。
以下创建一个简单的数据框,包含姓名、工号、月薪:
实例
1 2 3 4 5 6 7 table \= data.frame( 姓名 \= c("张三", "李四"), 工号 \= c("001","002"), 月薪 \= c(1000, 2000) ) print(table) \# 查看 table 数据
执行以上代码输出结果为:
1 2 3 姓名 工号 月薪 1 张三 001 1000 2 李四 002 2000
数据框的数据结构可以通过 str() 函数来展示:
实例
1 2 3 4 5 6 7 table \= data.frame( 姓名 \= c("张三", "李四"), 工号 \= c("001","002"), 月薪 \= c(1000, 2000) ) \# 获取数据结构 str(table)
执行以上代码输出结果为:
1 2 3 4 'data.frame': 2 obs. of 3 variables: $ 姓名: chr "张三" "李四" $ 工号: chr "001" "002" $ 月薪: num 1000 2000
summary() 可以显示数据框的概要信息:
实例
1 2 3 4 5 6 7 8 table \= data.frame( 姓名 \= c("张三", "李四"), 工号 \= c("001","002"), 月薪 \= c(1000, 2000) ) \# 显示概要 print(summary(table))
执行以上代码输出结果为:
1 2 3 4 5 6 7 姓名 工号 月薪 Length:2 Length:2 Min. :1000 Class :character Class :character 1st Qu.:1250 Mode :character Mode :character Median :1500 Mean :1500 3rd Qu.:1750 Max. :2000
我们也可以提取指定的列:
实例
1 2 3 4 5 6 7 8 table \= data.frame( 姓名 \= c("张三", "李四"), 工号 \= c("001","002"), 月薪 \= c(1000, 2000) ) \# 提取指定的列 result <- data.frame(table$姓名,table$月薪) print(result)
执行以上代码输出结果为:
1 2 3 table.姓名 table.月薪 1 张三 1000 2 李四 2000
以下形式显示前面两行:
实例
1 2 3 4 5 6 7 8 9 10 table \= data.frame( 姓名 \= c("张三", "李四","王五"), 工号 \= c("001","002","003"), 月薪 \= c(1000, 2000,3000) ) print(table) \# 提取前面两行 print("---输出前面两行----") result <- table\[1:2,\] print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 姓名 工号 月薪 1 张三 001 1000 2 李四 002 2000 3 王五 003 3000 [1] "---输出前面两行----" 姓名 工号 月薪 1 张三 001 1000 2 李四 002 2000
我们可以通过类似坐标的形式读取指定行的某一列的数据,以下我们读取第 2 、3 行的第 1 、2 列数据:
实例
1 2 3 4 5 6 7 8 table \= data.frame( 姓名 \= c("张三", "李四","王五"), 工号 \= c("001","002","003"), 月薪 \= c(1000, 2000,3000) ) \# 读取第 2 、3 行的第 1 、2 列数据: result <- table\[c(2,3),c(1,2)\] print(result)
执行以上代码输出结果为:
扩展数据框
我们可以对已有的数据框进行扩展,以下实例我们添加部门列:
实例
1 2 3 4 5 6 7 8 9 table \= data.frame( 姓名 \= c("张三", "李四","王五"), 工号 \= c("001","002","003"), 月薪 \= c(1000, 2000,3000) ) \# 添加部门列 table$部门 <- c("运营","技术","编辑") print(table)
执行以上代码输出结果为:
1 2 3 4 姓名 工号 月薪 部门 1 张三 001 1000 运营 2 李四 002 2000 技术 3 王五 003 3000 编辑
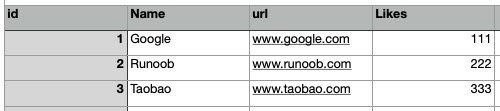
我们可以使用 cbind() 函数将多个向量合成一个数据框:
实例
1 2 3 4 5 6 7 8 9 10 \# 创建向量 sites <- c("Google","Runoob","Taobao") likes <- c(222,111,123) url <- c("www.google.com","www.runoob.com","www.taobao.com") \# 将向量组合成数据框 addresses <- cbind(sites,likes,url) \# 查看数据框 print(addresses)
执行以上代码输出结果为:
1 2 3 4 sites likes url [1,] "Google" "222" "www.google.com" [2,] "Runoob" "111" "www.runoob.com" [3,] "Taobao" "123" "www.taobao.com"
如果要对两个数据框进行合并可以使用 rbind() 函数:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 table \= data.frame( 姓名 \= c("张三", "李四","王五"), 工号 \= c("001","002","003"), 月薪 \= c(1000, 2000,3000) ) newtable \= data.frame( 姓名 \= c("小明", "小白"), 工号 \= c("101","102"), 月薪 \= c(5000, 7000) ) \# 合并两个数据框 result <- rbind(table,newtable) print(result)
执行以上代码输出结果为:
1 2 3 4 5 6 姓名 工号 月薪 1 张三 001 1000 2 李四 002 2000 3 王五 003 3000 4 小明 101 5000 5 小白 102 7000
R 数据重塑
合并数据框
R 语言合并数据框使用 merge() 函数。
merge() 函数语法格式如下:
1 2 3 4 5 6 7 8 # S3 方法 merge(x, y, …) # data.frame 的 S3 方法 merge(x, y, by = intersect(names(x), names(y)), by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all, sort = TRUE, suffixes = c(".x",".y"), no.dups = TRUE, incomparables = NULL, …)
常用参数说明:
x, y: 数据框
by, by.x, by.y:指定两个数据框中匹配列名称,默认情况下使用两个数据框中相同列名称。
all:逻辑值; all = L 是 all.x = L 和 all.y = L 的简写,L 可以是 TRUE 或 FALSE。
all.x:逻辑值,默认为 FALSE。如果为 TRUE, 显示 x 中匹配的行,即便 y 中没有对应匹配的行,y 中没有匹配的行用 NA 来表示。
all.y:逻辑值,默认为 FALSE。如果为 TRUE, 显示 y 中匹配的行,即便 x 中没有对应匹配的行,x 中没有匹配的行用 NA 来表示。
sort:逻辑值,是否对列进行排序。
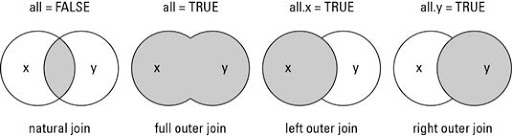
merge() 函数和 SQL 的 JOIN 功能很相似:
Natural join 或 INNER JOIN :如果表中有至少一个匹配,则返回行Left outer join 或 LEFT JOIN :即使右表中没有匹配,也从左表返回所有的行Right outer join 或 RIGHT JOIN :即使左表中没有匹配,也从右表返回所有的行Full outer join 或 FULL JOIN :只要其中一个表中存在匹配,则返回行
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 \# data frame 1 df1 \= data.frame(SiteId \= c(1:6), Site \= c("Google","Runoob","Taobao","Facebook","Zhihu","Weibo")) \# data frame 2 df2 \= data.frame(SiteId \= c(2, 4, 6, 7, 8), Country \= c("CN","USA","CN","USA","IN")) \# INNER JOIN df1 \= merge(x\=df1,y\=df2,by\="SiteId") print("----- INNER JOIN -----") print(df1) \# FULL JOIN df2 \= merge(x\=df1,y\=df2,by\="SiteId",all\=TRUE) print("----- FULL JOIN -----") print(df2) \# LEFT JOIN df3 \= merge(x\=df1,y\=df2,by\="SiteId",all.x\=TRUE) print("----- LEFT JOIN -----") print(df3) \# RIGHT JOIN df4 \= merge(x\=df1,y\=df2,by\="SiteId",all.y\=TRUE) print("----- RIGHT JOIN -----") print(df4)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [1] "----- INNER JOIN -----" SiteId Site Country 1 2 Runoob CN 2 4 Facebook USA 3 6 Weibo CN [1] "----- FULL JOIN -----" SiteId Site Country.x Country.y 1 2 Runoob CN CN 2 4 Facebook USA USA 3 6 Weibo CN CN 4 7 <NA> <NA> USA 5 8 <NA> <NA> IN [1] "----- LEFT JOIN -----" SiteId Site.x Country Site.y Country.x Country.y 1 2 Runoob CN Runoob CN CN 2 4 Facebook USA Facebook USA USA 3 6 Weibo CN Weibo CN CN [1] "----- RIGHT JOIN -----" SiteId Site.x Country Site.y Country.x Country.y 1 2 Runoob CN Runoob CN CN 2 4 Facebook USA Facebook USA USA 3 6 Weibo CN Weibo CN CN 4 7 <NA> <NA> <NA> <NA> USA 5 8 <NA> <NA> <NA> <NA> IN
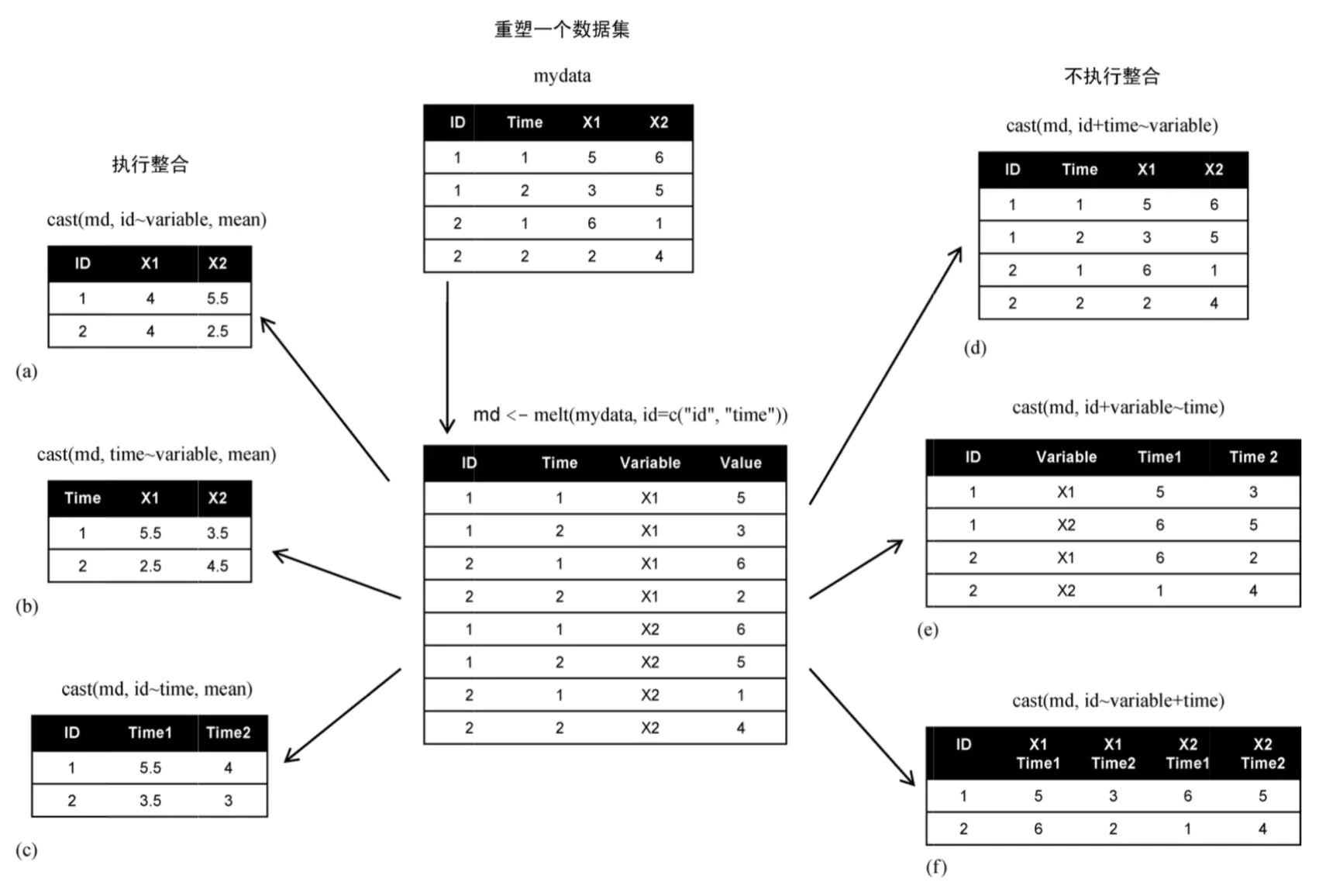
数据整合和拆分
R 语言使用 melt() 和 cast() 函数来对数据进行整合和拆分。
melt() :宽格式数据转化成长格式。
cast() :长格式数据转化成宽格式。
下图很好展示来 melt() 和 cast() 函数的功能(后面实例会详细说明):
melt() 将数据集的每个列堆叠到一个列中,函数语法格式:
1 melt(data, ..., na.rm = FALSE, value.name = "value")
参数说明:
data:数据集。
…:传递给其他方法或来自其他方法的其他参数。
na.rm:是否删除数据集中的 NA 值。
value.name 变量名称,用于存储值。
进行以下操作之前,我们先安装依赖包:
1 2 3 4 5 6 # 安装库,MASS 包含很多统计相关的函数,工具和数据集 install.packages("MASS", repos = "https://mirrors.ustc.edu.cn/CRAN/") # melt() 和 cast() 函数需要对库 install.packages("reshape2", repos = "https://mirrors.ustc.edu.cn/CRAN/") install.packages("reshape", repos = "https://mirrors.ustc.edu.cn/CRAN/")
测试实例:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 \# 载入库 library(MASS) library(reshape2) library(reshape) \# 创建数据框 id<\- c(1, 1, 2, 2) time <\- c(1, 2, 1, 2) x1 <\- c(5, 3, 6, 2) x2 <\- c(6, 5, 1, 4) mydata <\- data.frame(id, time, x1, x2) \# 原始数据框 cat("原始数据框:\\n") print(mydata) \# 整合 md <\- melt(mydata, id = c("id","time")) cat("\\n整合后:\\n") print(md)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 原始数据框: id time x1 x2 1 1 1 5 6 2 1 2 3 5 3 2 1 6 1 4 2 2 2 4 整合后: id time variable value 1 1 1 x1 5 2 1 2 x1 3 3 2 1 x1 6 4 2 2 x1 2 5 1 1 x2 6 6 1 2 x2 5 7 2 1 x2 1 8 2 2 x2 4
cast 函数用于对合并对数据框进行还原,dcast() 返回数据框,acast() 返回一个向量/矩阵/数组。
cast() 函数语法格式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 dcast( data, formula, fun.aggregate = NULL, ..., margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data) ) acast( data, formula, fun.aggregate = NULL, ..., margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data) )
参数说明:
data:合并的数据框。
formula:重塑的数据的格式,类似 x ~ y 格式,x 为行标签,y 为列标签 。
fun.aggregate:聚合函数,用于对 value 值进行处理。
margins:变量名称的向量(可以包含"grand\_col" 和 “grand\_row”),用于计算边距,设置 TURE 计算所有边距。
subset:对结果进行条件筛选,格式类似 subset = .(variable==“length”) 。
drop:是否保留默认值。
value.var:后面跟要处理的字段。
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 \# 载入库 library(MASS) library(reshape2) library(reshape) \# 创建数据框 id<- c(1, 1, 2, 2) time <- c(1, 2, 1, 2) x1 <- c(5, 3, 6, 2) x2 <- c(6, 5, 1, 4) mydata <- data.frame(id, time, x1, x2) \# 整合 md <- melt(mydata, id \= c("id","time")) \# Print recasted dataset using cast() function cast.data <- cast(md, id~variable, mean) print(cast.data) cat("\\n") time.cast <- cast(md, time~variable, mean) print(time.cast) cat("\\n") id.time <- cast(md, id~time, mean) print(id.time) cat("\\n") id.time.cast <- cast(md, id+time~variable) print(id.time.cast) cat("\\n") id.variable.time <- cast(md, id+variable~time) print(id.variable.time) cat("\\n") id.variable.time2 <- cast(md, id~variable+time) print(id.variable.time2)
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 id x1 x2 1 1 4 5.5 2 2 4 2.5 time x1 x2 1 1 5.5 3.5 2 2 2.5 4.5 id 1 2 1 1 5.5 4 2 2 3.5 3 id time x1 x2 1 1 1 5 6 2 1 2 3 5 3 2 1 6 1 4 2 2 2 4 id variable 1 2 1 1 x1 5 3 2 1 x2 6 5 3 2 x1 6 2 4 2 x2 1 4 id x1_1 x1_2 x2_1 x2_2 1 1 5 3 6 5 2 2 6 2 1 4
R 包
包是 R 函数、实例数据、预编译代码的集合,包括 R 程序,注释文档、实例、测试数据等。
R 语言相关的包一般存储安装目录下对 “library” 目录,默认情况在 R 语言安装完成已经自带来一些常用对包,当然我们也可以在后期自定义添加一些要使用的包。
R 语言完整的相关包可以查阅:https://cran.r-project.org/web/packages/available_packages_by_name.html
接下来我们主要介绍如何安装 R 语言的包。
查看 R 包的安装目录
我们可以使用以下函数来查看 R 包的安装目录:
实例
1 2 3 \> .libPaths() \[1\] "/Library/Frameworks/R.framework/Versions/4.0/Resources/library" \>
查看已安装的包
我们可以使用以下函数来查看已安装的包:
输出结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 base The R Base Package boot Bootstrap Functions (Originally by Angelo Canty for S) class Functions for Classification cluster "Finding Groups in Data": Cluster Analysis Extended Rousseeuw et al. codetools Code Analysis Tools for R compiler The R Compiler Package datasets The R Datasets Package foreign Read Data Stored by 'Minitab', 'S', 'SAS', 'SPSS', 'Stata', 'Systat', 'Weka', 'dBase', ... graphics The R Graphics Package grDevices The R Graphics Devices and Support for Colours and Fonts grid The Grid Graphics Package KernSmooth Functions for Kernel Smoothing Supporting Wand & Jones (1995) lattice Trellis Graphics for R MASS Support Functions and Datasets for Venables and Ripley's MASS
查看已载入的包
我们可以使用以下函数来查看编译环境已载入的包:
实例
1 2 3 4 \> search() \[1\] ".GlobalEnv" "package:stats" "package:graphics" \[4\] "package:grDevices" "package:utils" "package:datasets" \[7\] "package:methods" "Autoloads" "package:base"
安装新包
安装新包可以使用 install.packages() 函数,格式如下:
1 install.packages("要安装的包名")
我们可以直接设置包名,从 CRAN 网站上获取包,如下实例我们载入 XML 包:
1 2 # 安装 XML 包 install.packages("XML")
或者我们可以直接在 CRAN 上下载相关包,直接在本地安装:
1 install.packages("./XML_3.98-1.3.zip")
我们国内一般建议大家使用国内镜像,以下实例使用中国科学技术大学源进行安装:
1 2 # 安装 XML 包 install.packages("XML", repos = "https://mirrors.ustc.edu.cn/CRAN/")
CRAN (The Comprehensive R Archive Network) 镜像源配置文件之一是 .Rprofile (linux 下位于 ~/.Rprofile )。
在文末添加如下语句:
1 options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
打开 R 即可使用该 CRAN 镜像源安装 R 软件包。
使用包
新安装的包需要先载入 R 编译环境中才可以使用,格式如下:
以下实例载入 XML 包:
留言與分享

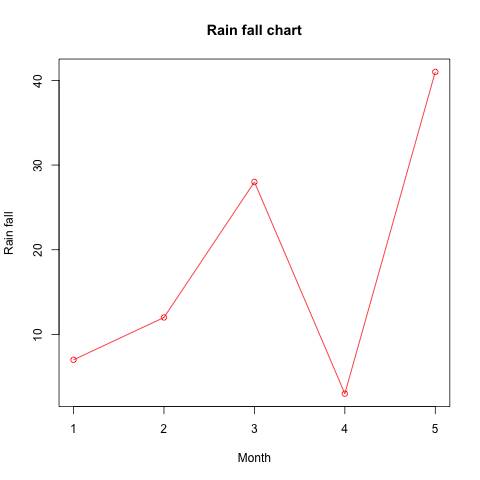
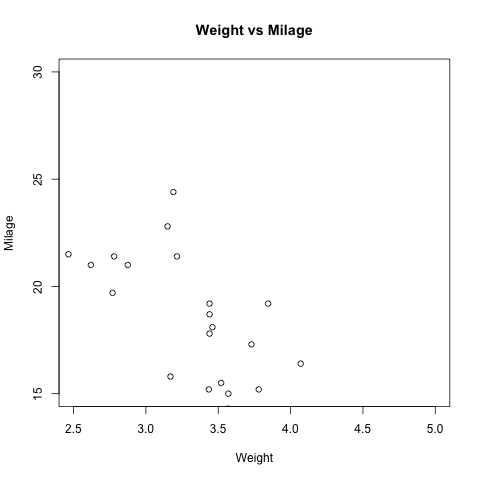
 R 语言实例
R 语言实例