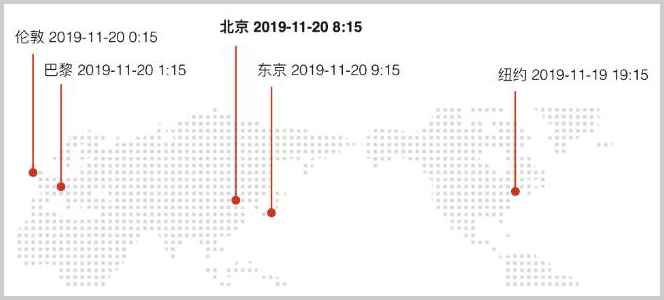
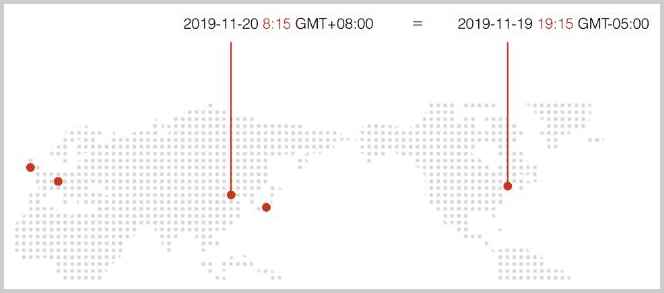
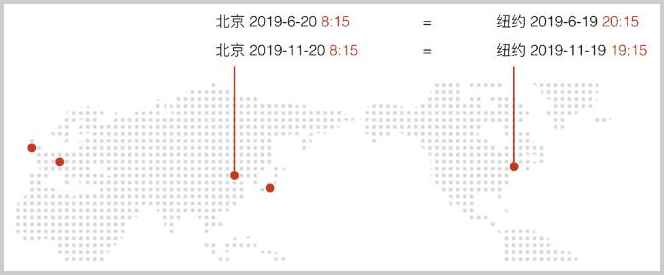
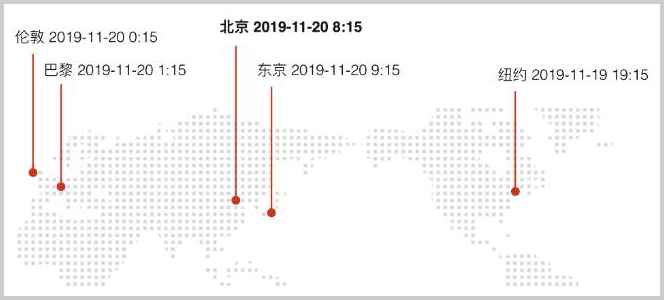
Java集合简介
什么是集合(Collection)?集合就是“由若干个确定的元素所构成的整体”。例如,5只小兔构成的集合:
1 2 3 4 5 6 7 ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐ │ (\_(\ (\_/) (\_/) (\_/) (\(\ │ ( -.-) (•.•) (>.<) (^.^) (='.') │ C(")_(") (")_(") (")_(") (")_(") O(_")") │ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
在数学中,我们经常遇到集合的概念。例如:
有限集合:
一个班所有的同学构成的集合;
一个网站所有的商品构成的集合;
…
无限集合:
全体自然数集合:1,2,3,……
有理数集合;
实数集合;
…
为什么要在计算机中引入集合呢?这是为了便于处理一组类似的数据,例如:
计算所有同学的总成绩和平均成绩;
列举所有的商品名称和价格;
……
在Java中,如果一个Java对象可以在内部持有若干其他Java对象,并对外提供访问接口,我们把这种Java对象称为集合。很显然,Java的数组可以看作是一种集合:
1 2 3 String[] ss = new String [10 ]; ss[0 ] = "Hello" ; String first = ss[0 ];
既然Java提供了数组这种数据类型,可以充当集合,那么,我们为什么还需要其他集合类?这是因为数组有如下限制:
数组初始化后大小不可变;
数组只能按索引顺序存取。
因此,我们需要各种不同类型的集合类来处理不同的数据,例如:
Collection
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合:
List:一种有序列表的集合,例如,按索引排列的Student的List;Set:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;Map:一种通过键值(key-value)查找的映射表集合,例如,根据Student的name查找对应Student的Map。
Java集合的设计有几个特点:一是实现了接口和实现类相分离,例如,有序表的接口是List,具体的实现类有ArrayList,LinkedList等,二是支持泛型,我们可以限制在一个集合中只能放入同一种数据类型的元素,例如:
1 List<String> list = new ArrayList <>();
最后,Java访问集合总是通过统一的方式——迭代器(Iterator)来实现,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。
由于Java的集合设计非常久远,中间经历过大规模改进,我们要注意到有一小部分集合类是遗留类,不应该继续使用:
Hashtable:一种线程安全的Map实现;Vector:一种线程安全的List实现;Stack:基于Vector实现的LIFO的栈。
还有一小部分接口是遗留接口,也不应该继续使用:
Enumeration<E>:已被Iterator<E>取代。
小结
Java的集合类定义在java.util包中,支持泛型,主要提供了3种集合类,包括List,Set和Map。Java集合使用统一的Iterator遍历,尽量不要使用遗留接口。
在集合类中,List是最基础的一种集合:它是一种有序列表。
List的行为和数组几乎完全相同:List内部按照放入元素的先后顺序存放,每个元素都可以通过索引确定自己的位置,List的索引和数组一样,从0开始。
数组和List类似,也是有序结构,如果我们使用数组,在添加和删除元素的时候,会非常不方便。例如,从一个已有的数组{'A', 'B', 'C', 'D', 'E'}中删除索引为2的元素:
1 2 3 4 5 6 7 8 9 10 11 ┌───┬───┬───┬───┬───┬───┐ │ A │ B │ C │ D │ E │ │ └───┴───┴───┴───┴───┴───┘ │ │ ┌───┘ │ │ ┌───┘ │ │ ▼ ▼ ┌───┬───┬───┬───┬───┬───┐ │ A │ B │ D │ E │ │ │ └───┴───┴───┴───┴───┴───┘
这个“删除”操作实际上是把'C'后面的元素依次往前挪一个位置,而“添加”操作实际上是把指定位置以后的元素都依次向后挪一个位置,腾出来的位置给新加的元素。这两种操作,用数组实现非常麻烦。
因此,在实际应用中,需要增删元素的有序列表,我们使用最多的是ArrayList。实际上,ArrayList在内部使用了数组来存储所有元素。例如,一个ArrayList拥有5个元素,实际数组大小为6(即有一个空位):
1 2 3 4 size=5 ┌───┬───┬───┬───┬───┬───┐ │ A │ B │ C │ D │ E │ │ └───┴───┴───┴───┴───┴───┘
当添加一个元素并指定索引到ArrayList时,ArrayList自动移动需要移动的元素:
1 2 3 4 size=5 ┌───┬───┬───┬───┬───┬───┐ │ A │ B │ │ C │ D │ E │ └───┴───┴───┴───┴───┴───┘
然后,往内部指定索引的数组位置添加一个元素,然后把size加1:
1 2 3 4 size=6 ┌───┬───┬───┬───┬───┬───┐ │ A │ B │ F │ C │ D │ E │ └───┴───┴───┴───┴───┴───┘
继续添加元素,但是数组已满,没有空闲位置的时候,ArrayList先创建一个更大的新数组,然后把旧数组的所有元素复制到新数组,紧接着用新数组取代旧数组:
1 2 3 4 size=6 ┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐ │ A │ B │ F │ C │ D │ E │ │ │ │ │ │ │ └───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
现在,新数组就有了空位,可以继续添加一个元素到数组末尾,同时size加1:
1 2 3 4 size=7 ┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐ │ A │ B │ F │ C │ D │ E │ G │ │ │ │ │ │ └───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
可见,ArrayList把添加和删除的操作封装起来,让我们操作List类似于操作数组,却不用关心内部元素如何移动。
我们考察List<E>接口,可以看到几个主要的接口方法:
在末尾添加一个元素:boolean add(E e)
在指定索引添加一个元素:boolean add(int index, E e)
删除指定索引的元素:E remove(int index)
删除某个元素:boolean remove(Object e)
获取指定索引的元素:E get(int index)
获取链表大小(包含元素的个数):int size()
但是,实现List接口并非只能通过数组(即ArrayList的实现方式)来实现,另一种LinkedList通过“链表”也实现了List接口。在LinkedList中,它的内部每个元素都指向下一个元素:
1 2 3 ┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐ HEAD ──▶│ A │ ●─┼──▶│ B │ ●─┼──▶│ C │ ●─┼──▶│ D │ │ └───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
我们来比较一下ArrayList和LinkedList:
ArrayList
LinkedList
获取指定元素
速度很快
需要从头开始查找元素
添加元素到末尾
速度很快
速度很快
在指定位置添加/删除
需要移动元素
不需要移动元素
内存占用
少
较大
通常情况下,我们总是优先使用ArrayList。
List的特点
使用List时,我们要关注List接口的规范。List接口允许我们添加重复的元素,即List内部的元素可以重复:
1 2 3 4 5 6 7 8 9 10 11 12 import java.util.ArrayList;import java.util.List;public class Main { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("apple" ); list.add("pear" ); list.add("apple" ); System.out.println(list.size()); } }
List还允许添加null:
1 2 3 4 5 6 7 8 9 10 11 12 13 import java.util.ArrayList;import java.util.List;public class Main { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("apple" ); list.add(null ); list.add("pear" ); String second = list.get(1 ); System.out.println(second); } }
创建List
除了使用ArrayList和LinkedList,我们还可以通过List接口提供的of()方法,根据给定元素快速创建List:
1 List<Integer> list = List.of(1 , 2 , 5 );
但是List.of()方法不接受null值,如果传入null,会抛出NullPointerException异常。
遍历List
和数组类型类似,我们要遍历一个List,完全可以用for循环根据索引配合get(int)方法遍历:
1 2 3 4 5 6 7 8 9 10 11 import java.util.List;public class Main { public static void main (String[] args) { List<String> list = List.of("apple" , "pear" , "banana" ); for (int i=0 ; i<list.size(); i++) { String s = list.get(i); System.out.println(s); } } }
但这种方式并不推荐,一是代码复杂,二是因为get(int)方法只有ArrayList的实现是高效的,换成LinkedList后,索引越大,访问速度越慢。
所以我们要始终坚持使用迭代器Iterator来访问List。Iterator本身也是一个对象,但它是由List的实例调用iterator()方法的时候创建的。Iterator对象知道如何遍历一个List,并且不同的List类型,返回的Iterator对象实现也是不同的,但总是具有最高的访问效率。
Iterator对象有两个方法:boolean hasNext()判断是否有下一个元素,E next()返回下一个元素。因此,使用Iterator遍历List代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 import java.util.Iterator;import java.util.List;public class Main { public static void main (String[] args) { List<String> list = List.of("apple" , "pear" , "banana" ); for (Iterator<String> it = list.iterator(); it.hasNext(); ) { String s = it.next(); System.out.println(s); } } }
有童鞋可能觉得使用Iterator访问List的代码比使用索引更复杂。但是,要记住,通过Iterator遍历List永远是最高效的方式。并且,由于Iterator遍历是如此常用,所以,Java的for each循环本身就可以帮我们使用Iterator遍历。把上面的代码再改写如下:
1 2 3 4 5 6 7 8 9 10 import java.util.List;public class Main { public static void main (String[] args) { List<String> list = List.of("apple" , "pear" , "banana" ); for (String s : list) { System.out.println(s); } } }
上述代码就是我们编写遍历List的常见代码。
实际上,只要实现了Iterable接口的集合类都可以直接用for each循环来遍历,Java编译器本身并不知道如何遍历集合对象,但它会自动把for each循环变成Iterator的调用,原因就在于Iterable接口定义了一个Iterator<E> iterator()方法,强迫集合类必须返回一个Iterator实例。
List和Array转换
把List变为Array有三种方法,第一种是调用toArray()方法直接返回一个Object[]数组:
1 2 3 4 5 6 7 8 9 10 11 import java.util.List;public class Main { public static void main (String[] args) { List<String> list = List.of("apple" , "pear" , "banana" ); Object[] array = list.toArray(); for (Object s : array) { System.out.println(s); } } }
这种方法会丢失类型信息,所以实际应用很少。
第二种方式是给toArray(T[])传入一个类型相同的Array,List内部自动把元素复制到传入的Array中:
1 2 3 4 5 6 7 8 9 10 11 import java.util.List;public class Main { public static void main (String[] args) { List<Integer> list = List.of(12 , 34 , 56 ); Integer[] array = list.toArray(new Integer [3 ]); for (Integer n : array) { System.out.println(n); } } }
注意到这个toArray(T[])方法的泛型参数<T>并不是List接口定义的泛型参数<E>,所以,我们实际上可以传入其他类型的数组,例如我们传入Number类型的数组,返回的仍然是Number类型:
1 2 3 4 5 6 7 8 9 10 11 import java.util.List;public class Main { public static void main (String[] args) { List<Integer> list = List.of(12 , 34 , 56 ); Number[] array = list.toArray(new Number [3 ]); for (Number n : array) { System.out.println(n); } } }
但是,如果我们传入类型不匹配的数组,例如,String[]类型的数组,由于List的元素是Integer,所以无法放入String数组,这个方法会抛出ArrayStoreException。
如果我们传入的数组大小和List实际的元素个数不一致怎么办?根据List接口 的文档,我们可以知道:
如果传入的数组不够大,那么List内部会创建一个新的刚好够大的数组,填充后返回;如果传入的数组比List元素还要多,那么填充完元素后,剩下的数组元素一律填充null。
实际上,最常用的是传入一个“恰好”大小的数组:
1 Integer[] array = list.toArray(new Integer [list.size()]);
最后一种更简洁的写法是通过List接口定义的T[] toArray(IntFunction<T[]> generator)方法:
1 Integer[] array = list.toArray(Integer[]::new );
这种函数式写法我们会在后续讲到。
反过来,把Array变为List就简单多了,通过List.of(T...)方法最简单:
1 2 Integer[] array = { 1 , 2 , 3 }; List<Integer> list = List.of(array);
对于JDK 11之前的版本,可以使用Arrays.asList(T...)方法把数组转换成List。
要注意的是,返回的List不一定就是ArrayList或者LinkedList,因为List只是一个接口,如果我们调用List.of(),它返回的是一个只读List:
1 2 3 4 5 6 7 8 import java.util.List;public class Main { public static void main (String[] args) { List<Integer> list = List.of(12 , 34 , 56 ); list.add(999 ); } }
对只读List调用add()、remove()方法会抛出UnsupportedOperationException。
练习
给定一组连续的整数,例如:10,11,12,……,20,但其中缺失一个数字,试找出缺失的数字:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import java.util.*;public class Main { public static void main (String[] args) { final int start = 10 ; final int end = 20 ; List<Integer> list = new ArrayList <>(); for (int i = start; i <= end; i++) { list.add(i); } int removed = list.remove((int ) (Math.random() * list.size())); int found = findMissingNumber(start, end, list); System.out.println(list.toString()); System.out.println("missing number: " + found); System.out.println(removed == found ? "测试成功" : "测试失败" ); } static int findMissingNumber (int start, int end, List<Integer> list) { return 0 ; } }
增强版:和上述题目一样,但整数不再有序,试找出缺失的数字:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import java.util.*;public class Main { public static void main (String[] args) { final int start = 10 ; final int end = 20 ; List<Integer> list = new ArrayList <>(); for (int i = start; i <= end; i++) { list.add(i); } Collections.shuffle(list); int removed = list.remove((int ) (Math.random() * list.size())); int found = findMissingNumber(start, end, list); System.out.println(list.toString()); System.out.println("missing number: " + found); System.out.println(removed == found ? "测试成功" : "测试失败" ); } static int findMissingNumber (int start, int end, List<Integer> list) { return 0 ; } }
下载练习
小结
List是按索引顺序访问的长度可变的有序表,优先使用ArrayList而不是LinkedList;
可以直接使用for each遍历List;
List可以和Array相互转换。
我们知道List是一种有序链表:List内部按照放入元素的先后顺序存放,并且每个元素都可以通过索引确定自己的位置。
List还提供了boolean contains(Object o)方法来判断List是否包含某个指定元素。此外,int indexOf(Object o)方法可以返回某个元素的索引,如果元素不存在,就返回-1。
我们来看一个例子:
1 2 3 4 5 6 7 8 9 10 11 import java.util.List;public class Main { public static void main (String[] args) { List<String> list = List.of("A" , "B" , "C" ); System.out.println(list.contains("C" )); System.out.println(list.contains("X" )); System.out.println(list.indexOf("C" )); System.out.println(list.indexOf("X" )); } }
这里我们注意一个问题,我们往List中添加的"C"和调用contains("C")传入的"C"是不是同一个实例?
如果这两个"C"不是同一个实例,这段代码是否还能得到正确的结果?我们可以改写一下代码测试一下:
1 2 3 4 5 6 7 8 9 import java.util.List;public class Main { public static void main (String[] args) { List<String> list = List.of("A" , "B" , "C" ); System.out.println(list.contains(new String ("C" ))); System.out.println(list.indexOf(new String ("C" ))); } }
因为我们传入的是new String("C"),所以一定是不同的实例。结果仍然符合预期,这是为什么呢?
因为List内部并不是通过==判断两个元素是否相等,而是使用equals()方法判断两个元素是否相等,例如contains()方法可以实现如下:
1 2 3 4 5 6 7 8 9 10 11 public class ArrayList { Object[] elementData; public boolean contains (Object o) { for (int i = 0 ; i < elementData.length; i++) { if (o.equals(elementData[i])) { return true ; } } return false ; } }
因此,要正确使用List的contains()、indexOf()这些方法,放入的实例必须正确覆写equals()方法,否则,放进去的实例,查找不到。我们之所以能正常放入String、Integer这些对象,是因为Java标准库定义的这些类已经正确实现了equals()方法。
我们以Person对象为例,测试一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import java.util.List;public class Main { public static void main (String[] args) { List<Person> list = List.of( new Person ("Xiao Ming" ), new Person ("Xiao Hong" ), new Person ("Bob" ) ); System.out.println(list.contains(new Person ("Bob" ))); } } class Person { String name; public Person (String name) { this .name = name; } }
不出意外,虽然放入了new Person("Bob"),但是用另一个new Person("Bob")查询不到,原因就是Person类没有覆写equals()方法。
编写equals
如何正确编写equals()方法?equals()方法要求我们必须满足以下条件:
自反性(Reflexive):对于非null的x来说,x.equals(x)必须返回true;
对称性(Symmetric):对于非null的x和y来说,如果x.equals(y)为true,则y.equals(x)也必须为true;
传递性(Transitive):对于非null的x、y和z来说,如果x.equals(y)为true,y.equals(z)也为true,那么x.equals(z)也必须为true;
一致性(Consistent):对于非null的x和y来说,只要x和y状态不变,则x.equals(y)总是一致地返回true或者false;
对null的比较:即x.equals(null)永远返回false。
上述规则看上去似乎非常复杂,但其实代码实现equals()方法是很简单的,我们以Person类为例:
1 2 3 4 public class Person { public String name; public int age; }
首先,我们要定义“相等”的逻辑含义。对于Person类,如果name相等,并且age相等,我们就认为两个Person实例相等。
因此,编写equals()方法如下:
1 2 3 4 5 6 public boolean equals (Object o) { if (o instanceof Person p) { return this .name.equals(p.name) && this .age == p.age; } return false ; }
对于引用字段比较,我们使用equals(),对于基本类型字段的比较,我们使用==。
如果this.name为null,那么equals()方法会报错,因此,需要继续改写如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 public boolean equals (Object o) { if (o instanceof Person p) { boolean nameEquals = false ; if (this .name == null && p.name == null ) { nameEquals = true ; } if (this .name != null ) { nameEquals = this .name.equals(p.name); } return nameEquals && this .age == p.age; } return false ; }
如果Person有好几个引用类型的字段,上面的写法就太复杂了。要简化引用类型的比较,我们使用Objects.equals()静态方法:
1 2 3 4 5 6 public boolean equals (Object o) { if (o instanceof Person p) { return Objects.equals(this .name, p.name) && this .age == p.age; } return false ; }
因此,我们总结一下equals()方法的正确编写方法:
先确定实例“相等”的逻辑,即哪些字段相等,就认为实例相等;
用instanceof判断传入的待比较的Object是不是当前类型,如果是,继续比较,否则,返回false;
对引用类型用Objects.equals()比较,对基本类型直接用==比较。
使用Objects.equals()比较两个引用类型是否相等的目的是省去了判断null的麻烦。两个引用类型都是null时它们也是相等的。
如果不调用List的contains()、indexOf()这些方法,那么放入的元素就不需要实现equals()方法。
练习
给Person类增加equals方法,使得调用indexOf()方法返回正常:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import java.util.List;import java.util.Objects;public class Main { public static void main (String[] args) { List<Person> list = List.of( new Person ("Xiao" , "Ming" , 18 ), new Person ("Xiao" , "Hong" , 25 ), new Person ("Bob" , "Smith" , 20 ) ); boolean exist = list.contains(new Person ("Bob" , "Smith" , 20 )); System.out.println(exist ? "测试成功!" : "测试失败!" ); } } class Person { String firstName; String lastName; int age; public Person (String firstName, String lastName, int age) { this .firstName = firstName; this .lastName = lastName; this .age = age; } }
下载练习
小结
在List中查找元素时,List的实现类通过元素的equals()方法比较两个元素是否相等,因此,放入的元素必须正确覆写equals()方法,Java标准库提供的String、Integer等已经覆写了equals()方法;
编写equals()方法可借助Objects.equals()判断。
如果不在List中查找元素,就不必覆写equals()方法。
我们知道,List是一种顺序列表,如果有一个存储学生Student实例的List,要在List中根据name查找某个指定的Student的分数,应该怎么办?
最简单的方法是遍历List并判断name是否相等,然后返回指定元素:
1 2 3 4 5 6 7 8 9 List<Student> list = ... Student target = null ;for (Student s : list) { if ("Xiao Ming" .equals(s.name)) { target = s; break ; } } System.out.println(target.score);
这种需求其实非常常见,即通过一个键去查询对应的值。使用List来实现存在效率非常低的问题,因为平均需要扫描一半的元素才能确定,而Map这种键值(key-value)映射表的数据结构,作用就是能高效通过key快速查找value(元素)。
用Map来实现根据name查询某个Student的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import java.util.HashMap;import java.util.Map;public class Main { public static void main (String[] args) { Student s = new Student ("Xiao Ming" , 99 ); Map<String, Student> map = new HashMap <>(); map.put("Xiao Ming" , s); Student target = map.get("Xiao Ming" ); System.out.println(target == s); System.out.println(target.score); Student another = map.get("Bob" ); System.out.println(another); } } class Student { public String name; public int score; public Student (String name, int score) { this .name = name; this .score = score; } }
通过上述代码可知:Map<K, V>是一种键-值映射表,当我们调用put(K key, V value)方法时,就把key和value做了映射并放入Map。当我们调用V get(K key)时,就可以通过key获取到对应的value。如果key不存在,则返回null。和List类似,Map也是一个接口,最常用的实现类是HashMap。
如果只是想查询某个key是否存在,可以调用boolean containsKey(K key)方法。
如果我们在存储Map映射关系的时候,对同一个key调用两次put()方法,分别放入不同的value,会有什么问题呢?例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 import java.util.HashMap;import java.util.Map;public class Main { public static void main (String[] args) { Map<String, Integer> map = new HashMap <>(); map.put("apple" , 123 ); map.put("pear" , 456 ); System.out.println(map.get("apple" )); map.put("apple" , 789 ); System.out.println(map.get("apple" )); } }
重复放入key-value并不会有任何问题,但是一个key只能关联一个value。在上面的代码中,一开始我们把key对象"apple"映射到Integer对象123,然后再次调用put()方法把"apple"映射到789,这时,原来关联的value对象123就被“冲掉”了。实际上,put()方法的签名是V put(K key, V value),如果放入的key已经存在,put()方法会返回被删除的旧的value,否则,返回null。
始终牢记
Map中不存在重复的key,因为放入相同的key,只会把原有的key-value对应的value给替换掉。
此外,在一个Map中,虽然key不能重复,但value是可以重复的:
1 2 3 Map<String, Integer> map = new HashMap <>(); map.put("apple" , 123 ); map.put("pear" , 123 );
遍历Map
对Map来说,要遍历key可以使用for each循环遍历Map实例的keySet()方法返回的Set集合,它包含不重复的key的集合:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import java.util.HashMap;import java.util.Map;public class Main { public static void main (String[] args) { Map<String, Integer> map = new HashMap <>(); map.put("apple" , 123 ); map.put("pear" , 456 ); map.put("banana" , 789 ); for (String key : map.keySet()) { Integer value = map.get(key); System.out.println(key + " = " + value); } } }
同时遍历key和value可以使用for each循环遍历Map对象的entrySet()集合,它包含每一个key-value映射:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import java.util.HashMap;import java.util.Map;public class Main { public static void main (String[] args) { Map<String, Integer> map = new HashMap <>(); map.put("apple" , 123 ); map.put("pear" , 456 ); map.put("banana" , 789 ); for (Map.Entry<String, Integer> entry : map.entrySet()) { String key = entry.getKey(); Integer value = entry.getValue(); System.out.println(key + " = " + value); } } }
Map和List不同的是,Map存储的是key-value的映射关系,并且,它不保证顺序 。在遍历的时候,遍历的顺序既不一定是put()时放入的key的顺序,也不一定是key的排序顺序。使用Map时,任何依赖顺序的逻辑都是不可靠的。以HashMap为例,假设我们放入"A","B","C"这3个key,遍历的时候,每个key会保证被遍历一次且仅遍历一次,但顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历的输出顺序都是不同的!
注意
遍历Map时,不可假设输出的key是有序的!
练习
请编写一个根据name查找score的程序,并利用Map充当缓存,以提高查找效率:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 import java.util.*;public class Main { public static void main (String[] args) { List<Student> list = List.of( new Student ("Bob" , 78 ), new Student ("Alice" , 85 ), new Student ("Brush" , 66 ), new Student ("Newton" , 99 )); var holder = new Students (list); System.out.println(holder.getScore("Bob" ) == 78 ? "测试成功!" : "测试失败!" ); System.out.println(holder.getScore("Alice" ) == 85 ? "测试成功!" : "测试失败!" ); System.out.println(holder.getScore("Tom" ) == -1 ? "测试成功!" : "测试失败!" ); } } class Students { List<Student> list; Map<String, Integer> cache; Students(List<Student> list) { this .list = list; cache = new HashMap <>(); } int getScore (String name) { Integer score = this .cache.get(name); if (score == null ) { } return score == null ? -1 : score.intValue(); } Integer findInList (String name) { for (var ss : this .list) { if (ss.name.equals(name)) { return ss.score; } } return null ; } } class Student { String name; int score; Student(String name, int score) { this .name = name; this .score = score; } }
下载练习
小结
Map是一种映射表,可以通过key快速查找value;
可以通过for each遍历keySet(),也可以通过for each遍历entrySet(),直接获取key-value;
最常用的一种Map实现是HashMap。
我们知道Map是一种键-值(key-value)映射表,可以通过key快速查找对应的value。
以HashMap为例,观察下面的代码:
1 2 3 4 5 6 7 Map<String, Person> map = new HashMap <>(); map.put("a" , new Person ("Xiao Ming" )); map.put("b" , new Person ("Xiao Hong" )); map.put("c" , new Person ("Xiao Jun" )); map.get("a" ); map.get("x" );
HashMap之所以能根据key直接拿到value,原因是它内部通过空间换时间的方法,用一个大数组存储所有value,并根据key直接计算出value应该存储在哪个索引:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌───┐ 0 │ │ ├───┤ 1 │ ●─┼───▶ Person("Xiao Ming") ├───┤ 2 │ │ ├───┤ 3 │ │ ├───┤ 4 │ │ ├───┤ 5 │ ●─┼───▶ Person("Xiao Hong") ├───┤ 6 │ ●─┼───▶ Person("Xiao Jun") ├───┤ 7 │ │ └───┘
如果key的值为"a",计算得到的索引总是1,因此返回value为Person("Xiao Ming"),如果key的值为"b",计算得到的索引总是5,因此返回value为Person("Xiao Hong"),这样,就不必遍历整个数组,即可直接读取key对应的value。
当我们使用key存取value的时候,就会引出一个问题:
我们放入Map的key是字符串"a",但是,当我们获取Map的value时,传入的变量不一定就是放入的那个key对象。
换句话讲,两个key应该是内容相同,但不一定是同一个对象。测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import java.util.HashMap;import java.util.Map;public class Main { public static void main (String[] args) { String key1 = "a" ; Map<String, Integer> map = new HashMap <>(); map.put(key1, 123 ); String key2 = new String ("a" ); map.get(key2); System.out.println(key1 == key2); System.out.println(key1.equals(key2)); } }
因为在Map的内部,对key做比较是通过equals()实现的,这一点和List查找元素需要正确覆写equals()是一样的,即正确使用Map必须保证:作为key的对象必须正确覆写equals()方法。
我们经常使用String作为key,因为String已经正确覆写了equals()方法。但如果我们放入的key是一个自己写的类,就必须保证正确覆写了equals()方法。
我们再思考一下HashMap为什么能通过key直接计算出value存储的索引。相同的key对象(使用equals()判断时返回true)必须要计算出相同的索引,否则,相同的key每次取出的value就不一定对。
通过key计算索引的方式就是调用key对象的hashCode()方法,它返回一个int整数。HashMap正是通过这个方法直接定位key对应的value的索引,继而直接返回value。
因此,正确使用Map必须保证:
作为key的对象必须正确覆写equals()方法,相等的两个key实例调用equals()必须返回true;
作为key的对象还必须正确覆写hashCode()方法,且hashCode()方法要严格遵循以下规范:
如果两个对象相等,则两个对象的hashCode()必须相等;
如果两个对象不相等,则两个对象的hashCode()尽量不要相等。
即对应两个实例a和b:
如果a和b相等,那么a.equals(b)一定为true,则a.hashCode()必须等于b.hashCode();
如果a和b不相等,那么a.equals(b)一定为false,则a.hashCode()和b.hashCode()尽量不要相等。
上述第一条规范是正确性,必须保证实现,否则HashMap不能正常工作。
而第二条如果尽量满足,则可以保证查询效率,因为不同的对象,如果返回相同的hashCode(),会造成Map内部存储冲突,使存取的效率下降。
正确编写equals()的方法我们已经在编写equals方法 一节中讲过了,以Person类为例:
1 2 3 4 5 public class Person { String firstName; String lastName; int age; }
把需要比较的字段找出来:
然后,引用类型使用Objects.equals()比较,基本类型使用==比较。
在正确实现equals()的基础上,我们还需要正确实现hashCode(),即上述3个字段分别相同的实例,hashCode()返回的int必须相同:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Person { String firstName; String lastName; int age; @Override int hashCode () { int h = 0 ; h = 31 * h + firstName.hashCode(); h = 31 * h + lastName.hashCode(); h = 31 * h + age; return h; } }
注意到String类已经正确实现了hashCode()方法,我们在计算Person的hashCode()时,反复使用31*h,这样做的目的是为了尽量把不同的Person实例的hashCode()均匀分布到整个int范围。
和实现equals()方法遇到的问题类似,如果firstName或lastName为null,上述代码工作起来就会抛NullPointerException。为了解决这个问题,我们在计算hashCode()的时候,经常借助Objects.hash()来计算:
1 2 3 int hashCode () { return Objects.hash(firstName, lastName, age); }
所以,编写equals()和hashCode()遵循的原则是:
equals()用到的用于比较的每一个字段,都必须在hashCode()中用于计算;equals()中没有使用到的字段,绝不可放在hashCode()中计算。
另外注意,对于放入HashMap的value对象,没有任何要求。
延伸阅读
既然HashMap内部使用了数组,通过计算key的hashCode()直接定位value所在的索引,那么第一个问题来了:hashCode()返回的int范围高达±21亿,先不考虑负数,HashMap内部使用的数组得有多大?
实际上HashMap初始化时默认的数组大小只有16,任何key,无论它的hashCode()有多大,都可以简单地通过:
1 int index = key.hashCode() & 0xf ;
把索引确定在0 ~ 15,即永远不会超出数组范围,上述算法只是一种最简单的实现。
第二个问题:如果添加超过16个key-value到HashMap,数组不够用了怎么办?
添加超过一定数量的key-value时,HashMap会在内部自动扩容,每次扩容一倍,即长度为16的数组扩展为长度32,相应地,需要重新确定hashCode()计算的索引位置。例如,对长度为32的数组计算hashCode()对应的索引,计算方式要改为:
1 int index = key.hashCode() & 0x1f ;
由于扩容会导致重新分布已有的key-value,所以,频繁扩容对HashMap的性能影响很大。如果我们确定要使用一个容量为10000个key-value的HashMap,更好的方式是创建HashMap时就指定容量:
1 Map<String, Integer> map = new HashMap <>(10000 );
虽然指定容量是10000,但HashMap内部的数组长度总是2n,因此,实际数组长度被初始化为比10000大的16384(214)。
最后一个问题:如果不同的两个key,例如"a"和"b",它们的hashCode()恰好是相同的(这种情况是完全可能的,因为不相等的两个实例,只要求hashCode()尽量不相等),那么,当我们放入:
1 2 map.put("a" , new Person ("Xiao Ming" )); map.put("b" , new Person ("Xiao Hong" ));
时,由于计算出的数组索引相同,后面放入的"Xiao Hong"会不会把"Xiao Ming"覆盖了?
当然不会!使用Map的时候,只要key不相同,它们映射的value就互不干扰。但是,在HashMap内部,确实可能存在不同的key,映射到相同的hashCode(),即相同的数组索引上,肿么办?
我们就假设"a"和"b"这两个key最终计算出的索引都是5,那么,在HashMap的数组中,实际存储的不是一个Person实例,而是一个List,它包含两个Entry,一个是"a"的映射,一个是"b"的映射:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌───┐ 0 │ │ ├───┤ 1 │ │ ├───┤ 2 │ │ ├───┤ 3 │ │ ├───┤ 4 │ │ ├───┤ 5 │ ●─┼───▶ List<Entry<String, Person>> ├───┤ 6 │ │ ├───┤ 7 │ │ └───┘
在查找的时候,例如:
1 Person p = map.get("a" );
HashMap内部通过"a"找到的实际上是List<Entry<String, Person>>,它还需要遍历这个List,并找到一个Entry,它的key字段是"a",才能返回对应的Person实例。
我们把不同的key具有相同的hashCode()的情况称之为哈希冲突。在冲突的时候,一种最简单的解决办法是用List存储hashCode()相同的key-value。显然,如果冲突的概率越大,这个List就越长,Map的get()方法效率就越低,这就是为什么要尽量满足条件二:
提示
如果两个对象不相等,则两个对象的hashCode()尽量不要相等。
hashCode()方法编写得越好,HashMap工作的效率就越高。
小结
要正确使用HashMap,作为key的类必须正确覆写equals()和hashCode()方法;
一个类如果覆写了equals(),就必须覆写hashCode(),并且覆写规则是:
如果equals()返回true,则hashCode()返回值必须相等;
如果equals()返回false,则hashCode()返回值尽量不要相等。
实现hashCode()方法可以通过Objects.hashCode()辅助方法实现。
使用EnumMap
因为HashMap是一种通过对key计算hashCode(),通过空间换时间的方式,直接定位到value所在的内部数组的索引,因此,查找效率非常高。
如果作为key的对象是enum类型,那么,还可以使用Java集合库提供的一种EnumMap,它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
我们以DayOfWeek这个枚举类型为例,为它做一个“翻译”功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.time.DayOfWeek;import java.util.*;public class Main { public static void main (String[] args) { Map<DayOfWeek, String> map = new EnumMap <>(DayOfWeek.class); map.put(DayOfWeek.MONDAY, "星期一" ); map.put(DayOfWeek.TUESDAY, "星期二" ); map.put(DayOfWeek.WEDNESDAY, "星期三" ); map.put(DayOfWeek.THURSDAY, "星期四" ); map.put(DayOfWeek.FRIDAY, "星期五" ); map.put(DayOfWeek.SATURDAY, "星期六" ); map.put(DayOfWeek.SUNDAY, "星期日" ); System.out.println(map); System.out.println(map.get(DayOfWeek.MONDAY)); } }
使用EnumMap的时候,我们总是用Map接口来引用它,因此,实际上把HashMap和EnumMap互换,在客户端看来没有任何区别。
小结
如果Map的key是enum类型,推荐使用EnumMap,既保证速度,也不浪费空间。
使用EnumMap的时候,根据面向抽象编程的原则,应持有Map接口。
我们已经知道,HashMap是一种以空间换时间的映射表,它的实现原理决定了内部的Key是无序的,即遍历HashMap的Key时,其顺序是不可预测的(但每个Key都会遍历一次且仅遍历一次)。
还有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意到SortedMap是接口,它的实现类是TreeMap。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌───┐ │Map│ └───┘ ▲ ┌────┴─────┐ │ │ ┌───────┐ ┌─────────┐ │HashMap│ │SortedMap│ └───────┘ └─────────┘ ▲ │ ┌─────────┐ │ TreeMap │ └─────────┘
SortedMap保证遍历时以Key的顺序来进行排序。例如,放入的Key是"apple"、"pear"、"orange",遍历的顺序一定是"apple"、"orange"、"pear",因为String默认按字母排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.*;public class Main { public static void main (String[] args) { Map<String, Integer> map = new TreeMap <>(); map.put("orange" , 1 ); map.put("apple" , 2 ); map.put("pear" , 3 ); for (String key : map.keySet()) { System.out.println(key); } } }
使用TreeMap时,放入的Key必须实现Comparable接口。String、Integer这些类已经实现了Comparable接口,因此可以直接作为Key使用。作为Value的对象则没有任何要求。
如果作为Key的class没有实现Comparable接口,那么,必须在创建TreeMap时同时指定一个自定义排序算法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import java.util.*;public class Main { public static void main (String[] args) { Map<Person, Integer> map = new TreeMap <>(new Comparator <Person>() { public int compare (Person p1, Person p2) { return p1.name.compareTo(p2.name); } }); map.put(new Person ("Tom" ), 1 ); map.put(new Person ("Bob" ), 2 ); map.put(new Person ("Lily" ), 3 ); for (Person key : map.keySet()) { System.out.println(key); } System.out.println(map.get(new Person ("Bob" ))); } } class Person { public String name; Person(String name) { this .name = name; } public String toString () { return "{Person: " + name + "}" ; } }
注意到Comparator接口要求实现一个比较方法,它负责比较传入的两个元素a和b,如果a<b,则返回负数,通常是-1,如果a==b,则返回0,如果a>b,则返回正数,通常是1。TreeMap内部根据比较结果对Key进行排序。
从上述代码执行结果可知,打印的Key确实是按照Comparator定义的顺序排序的。如果要根据Key查找Value,我们可以传入一个new Person("Bob")作为Key,它会返回对应的Integer值2。
另外,注意到Person类并未覆写equals()和hashCode(),因为TreeMap不使用equals()和hashCode()。
我们来看一个稍微复杂的例子:这次我们定义了Student类,并用分数score进行排序,高分在前:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import java.util.*;public class Main { public static void main (String[] args) { Map<Student, Integer> map = new TreeMap <>(new Comparator <Student>() { public int compare (Student p1, Student p2) { return p1.score > p2.score ? -1 : 1 ; } }); map.put(new Student ("Tom" , 77 ), 1 ); map.put(new Student ("Bob" , 66 ), 2 ); map.put(new Student ("Lily" , 99 ), 3 ); for (Student key : map.keySet()) { System.out.println(key); } System.out.println(map.get(new Student ("Bob" , 66 ))); } } class Student { public String name; public int score; Student(String name, int score) { this .name = name; this .score = score; } public String toString () { return String.format("{%s: score=%d}" , name, score); } }
在for循环中,我们确实得到了正确的顺序。但是,且慢!根据相同的Key:new Student("Bob", 66)进行查找时,结果为null!
这是怎么肥四?难道TreeMap有问题?遇到TreeMap工作不正常时,我们首先回顾Java编程基本规则:出现问题,不要怀疑Java标准库,要从自身代码找原因。
在这个例子中,TreeMap出现问题,原因其实出在这个Comparator上:
1 2 3 public int compare (Student p1, Student p2) { return p1.score > p2.score ? -1 : 1 ; }
在p1.score和p2.score不相等的时候,它的返回值是正确的,但是,在p1.score和p2.score相等的时候,它并没有返回0!这就是为什么TreeMap工作不正常的原因:TreeMap在比较两个Key是否相等时,依赖Key的compareTo()方法或者Comparator.compare()方法。在两个Key相等时,必须返回0。因此,修改代码如下:
1 2 3 4 5 6 public int compare (Student p1, Student p2) { if (p1.score == p2.score) { return 0 ; } return p1.score > p2.score ? -1 : 1 ; }
或者直接借助Integer.compare(int, int)也可以返回正确的比较结果。
注意
使用TreeMap时,对Key的比较需要正确实现相等、大于和小于逻辑!
小结
SortedMap在遍历时严格按照Key的顺序遍历,最常用的实现类是TreeMap;
作为SortedMap的Key必须实现Comparable接口,或者传入Comparator;
要严格按照compare()规范实现比较逻辑,否则,TreeMap将不能正常工作。
在编写应用程序的时候,经常需要读写配置文件。例如,用户的设置:
1 2 3 4 last_open_file =/data/hello.txtauto_save_interval =60
配置文件的特点是,它的Key-Value一般都是String-String类型的,因此我们完全可以用Map<String, String>来表示它。
因为配置文件非常常用,所以Java集合库提供了一个Properties来表示一组“配置”。由于历史遗留原因,Properties内部本质上是一个Hashtable,但我们只需要用到Properties自身关于读写配置的接口。
读取配置文件
用Properties读取配置文件非常简单。Java默认配置文件以.properties为扩展名,每行以key=value表示,以#课开头的是注释。以下是一个典型的配置文件:
1 2 3 4 # setting.properties last_open_file=/data/hello.txt auto_save_interval=60
可以从文件系统读取这个.properties文件:
1 2 3 4 5 6 String f = "setting.properties" ;Properties props = new Properties ();props.load(new java .io.FileInputStream(f)); String filepath = props.getProperty("last_open_file" );String interval = props.getProperty("auto_save_interval" , "120" );
可见,用Properties读取配置文件,一共有三步:
创建Properties实例;
调用load()读取文件;
调用getProperty()获取配置。
调用getProperty()获取配置时,如果key不存在,将返回null。我们还可以提供一个默认值,这样,当key不存在的时候,就返回默认值。
也可以从classpath读取.properties文件,因为load(InputStream)方法接收一个InputStream实例,表示一个字节流,它不一定是文件流,也可以是从jar包中读取的资源流:
1 2 Properties props = new Properties ();props.load(getClass().getResourceAsStream("/common/setting.properties" ));
试试从内存读取一个字节流:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.io.*;import java.util.Properties;public class Main { public static void main (String[] args) throws IOException { String settings = "# test" + "\n" + "course=Java" + "\n" + "last_open_date=2019-08-07T12:35:01" ; ByteArrayInputStream input = new ByteArrayInputStream (settings.getBytes("UTF-8" )); Properties props = new Properties (); props.load(input); System.out.println("course: " + props.getProperty("course" )); System.out.println("last_open_date: " + props.getProperty("last_open_date" )); System.out.println("last_open_file: " + props.getProperty("last_open_file" )); System.out.println("auto_save: " + props.getProperty("auto_save" , "60" )); } }
如果有多个.properties文件,可以反复调用load()读取,后读取的key-value会覆盖已读取的key-value:
1 2 3 Properties props = new Properties ();props.load(getClass().getResourceAsStream("/common/setting.properties" )); props.load(new FileInputStream ("C:\\conf\\setting.properties" ));
上面的代码演示了Properties的一个常用用法:可以把默认配置文件放到classpath中,然后,根据机器的环境编写另一个配置文件,覆盖某些默认的配置。
Properties设计的目的是存储String类型的key-value,但Properties实际上是从Hashtable派生的,它的设计实际上是有问题的,但是为了保持兼容性,现在已经没法修改了。除了getProperty()和setProperty()方法外,还有从Hashtable继承下来的get()和put()方法,这些方法的参数签名是Object,我们在使用Properties的时候,不要去调用这些从Hashtable继承下来的方法。
写入配置文件
如果通过setProperty()修改了Properties实例,可以把配置写入文件,以便下次启动时获得最新配置。写入配置文件使用store()方法:
1 2 3 4 Properties props = new Properties ();props.setProperty("url" , "http://www.liaoxuefeng.com" ); props.setProperty("language" , "Java" ); props.store(new FileOutputStream ("C:\\conf\\setting.properties" ), "这是写入的properties注释" );
编码
早期版本的Java规定.properties文件编码是ASCII编码(ISO8859-1),如果涉及到中文就必须用name=\u4e2d\u6587来表示,非常别扭。从JDK9开始,Java的.properties文件可以使用UTF-8编码了。
不过,需要注意的是,由于load(InputStream)默认总是以ASCII编码读取字节流,所以会导致读到乱码。我们需要用另一个重载方法load(Reader)读取:
1 2 Properties props = new Properties ();props.load(new FileReader ("settings.properties" , StandardCharsets.UTF_8));
就可以正常读取中文。InputStream和Reader的区别是一个是字节流,一个是字符流。字符流在内存中已经以char类型表示了,不涉及编码问题。
小结
Java集合库提供的Properties用于读写配置文件.properties。.properties文件可以使用UTF-8编码;
可以从文件系统、classpath或其他任何地方读取.properties文件;
读写Properties时,注意仅使用getProperty()和setProperty()方法,不要调用继承而来的get()和put()等方法。
我们知道,Map用于存储key-value的映射,对于充当key的对象,是不能重复的,并且,不但需要正确覆写equals()方法,还要正确覆写hashCode()方法。
如果我们只需要存储不重复的key,并不需要存储映射的value,那么就可以使用Set。
Set用于存储不重复的元素集合,它主要提供以下几个方法:
将元素添加进Set<E>:boolean add(E e)
将元素从Set<E>删除:boolean remove(Object e)
判断是否包含元素:boolean contains(Object e)
我们来看几个简单的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.*;public class Main { public static void main (String[] args) { Set<String> set = new HashSet <>(); System.out.println(set.add("abc" )); System.out.println(set.add("xyz" )); System.out.println(set.add("xyz" )); System.out.println(set.contains("xyz" )); System.out.println(set.contains("XYZ" )); System.out.println(set.remove("hello" )); System.out.println(set.size()); } }
Set实际上相当于只存储key、不存储value的Map。我们经常用Set用于去除重复元素。
因为放入Set的元素和Map的key类似,都要正确实现equals()和hashCode()方法,否则该元素无法正确地放入Set。
最常用的Set实现类是HashSet,实际上,HashSet仅仅是对HashMap的一个简单封装,它的核心代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class HashSet <E> implements Set <E> { private HashMap<E, Object> map = new HashMap <>(); private static final Object PRESENT = new Object (); public boolean add (E e) { return map.put(e, PRESENT) == null ; } public boolean contains (Object o) { return map.containsKey(o); } public boolean remove (Object o) { return map.remove(o) == PRESENT; } }
Set接口并不保证有序,而SortedSet接口则保证元素是有序的:
HashSet是无序的,因为它实现了Set接口,并没有实现SortedSet接口;TreeSet是有序的,因为它实现了SortedSet接口。
用一张图表示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌───┐ │Set│ └───┘ ▲ ┌────┴─────┐ │ │ ┌───────┐ ┌─────────┐ │HashSet│ │SortedSet│ └───────┘ └─────────┘ ▲ │ ┌─────────┐ │ TreeSet │ └─────────┘
我们来看HashSet的输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.*;public class Main { public static void main (String[] args) { Set<String> set = new HashSet <>(); set.add("apple" ); set.add("banana" ); set.add("pear" ); set.add("orange" ); for (String s : set) { System.out.println(s); } } }
注意输出的顺序既不是添加的顺序,也不是String排序的顺序,在不同版本的JDK中,这个顺序也可能是不同的。
把HashSet换成TreeSet,在遍历TreeSet时,输出就是有序的,这个顺序是元素的排序顺序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.*;public class Main { public static void main (String[] args) { Set<String> set = new TreeSet <>(); set.add("apple" ); set.add("banana" ); set.add("pear" ); set.add("orange" ); for (String s : set) { System.out.println(s); } } }
使用TreeSet和使用TreeMap的要求一样,添加的元素必须正确实现Comparable接口,如果没有实现Comparable接口,那么创建TreeSet时必须传入一个Comparator对象。
练习
在聊天软件中,发送方发送消息时,遇到网络超时后就会自动重发,因此,接收方可能会收到重复的消息,在显示给用户看的时候,需要首先去重。请练习使用Set去除重复的消息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import java.util.*;public class Main { public static void main (String[] args) { List<Message> received = List.of( new Message (1 , "Hello!" ), new Message (2 , "发工资了吗?" ), new Message (2 , "发工资了吗?" ), new Message (3 , "去哪吃饭?" ), new Message (3 , "去哪吃饭?" ), new Message (4 , "Bye" ) ); List<Message> displayMessages = process(received); for (Message message : displayMessages) { System.out.println(message.text); } } static List<Message> process (List<Message> received) { return received; } } class Message { public final int sequence; public final String text; public Message (int sequence, String text) { this .sequence = sequence; this .text = text; } }
小结
Set用于存储不重复的元素集合:
放入HashSet的元素与作为HashMap的key要求相同;
放入TreeSet的元素与作为TreeMap的Key要求相同。
利用Set可以去除重复元素;
遍历SortedSet按照元素的排序顺序遍历,也可以自定义排序算法。
队列(Queue)是一种经常使用的集合。Queue实际上是实现了一个先进先出(FIFO:First In First Out)的有序表。它和List的区别在于,List可以在任意位置添加和删除元素,而Queue只有两个操作:
超市的收银台就是一个队列:
在Java的标准库中,队列接口Queue定义了以下几个方法:
int size():获取队列长度;boolean add(E)/boolean offer(E):添加元素到队尾;E remove()/E poll():获取队首元素并从队列中删除;E element()/E peek():获取队首元素但并不从队列中删除。
对于具体的实现类,有的Queue有最大队列长度限制,有的Queue没有。注意到添加、删除和获取队列元素总是有两个方法,这是因为在添加或获取元素失败时,这两个方法的行为是不同的。我们用一个表格总结如下:
throw Exception
返回false或null
添加元素到队尾
add(E e)
boolean offer(E e)
取队首元素并删除
E remove()
E poll()
取队首元素但不删除
E element()
E peek()
举个栗子,假设我们有一个队列,对它做一个添加操作,如果调用add()方法,当添加失败时(可能超过了队列的容量),它会抛出异常:
1 2 3 4 5 6 7 Queue<String> q = ... try { q.add("Apple" ); System.out.println("添加成功" ); } catch (IllegalStateException e) { System.out.println("添加失败" ); }
如果我们调用offer()方法来添加元素,当添加失败时,它不会抛异常,而是返回false:
1 2 3 4 5 6 Queue<String> q = ... if (q.offer("Apple" )) { System.out.println("添加成功" ); } else { System.out.println("添加失败" ); }
当我们需要从Queue中取出队首元素时,如果当前Queue是一个空队列,调用remove()方法,它会抛出异常:
1 2 3 4 5 6 7 Queue<String> q = ... try { String s = q.remove(); System.out.println("获取成功" ); } catch (IllegalStateException e) { System.out.println("获取失败" ); }
如果我们调用poll()方法来取出队首元素,当获取失败时,它不会抛异常,而是返回null:
1 2 3 4 5 6 7 Queue<String> q = ... String s = q.poll();if (s != null ) { System.out.println("获取成功" ); } else { System.out.println("获取失败" ); }
因此,两套方法可以根据需要来选择使用。
注意:不要把null添加到队列中,否则poll()方法返回null时,很难确定是取到了null元素还是队列为空。
接下来我们以poll()和peek()为例来说说“获取并删除”与“获取但不删除”的区别。对于Queue来说,每次调用poll(),都会获取队首元素,并且获取到的元素已经从队列中被删除了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.util.LinkedList;import java.util.Queue;public class Main { public static void main (String[] args) { Queue<String> q = new LinkedList <>(); q.offer("apple" ); q.offer("pear" ); q.offer("banana" ); System.out.println(q.poll()); System.out.println(q.poll()); System.out.println(q.poll()); System.out.println(q.poll()); } }
如果用peek(),因为获取队首元素时,并不会从队列中删除这个元素,所以可以反复获取:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import java.util.LinkedList;import java.util.Queue;public class Main { public static void main (String[] args) { Queue<String> q = new LinkedList <>(); q.offer("apple" ); q.offer("pear" ); q.offer("banana" ); System.out.println(q.peek()); System.out.println(q.peek()); System.out.println(q.peek()); } }
从上面的代码中,我们还可以发现,LinkedList即实现了List接口,又实现了Queue接口,但是,在使用的时候,如果我们把它当作List,就获取List的引用,如果我们把它当作Queue,就获取Queue的引用:
1 2 3 4 List<String> list = new LinkedList <>(); Queue<String> queue = new LinkedList <>();
始终按照面向抽象编程的原则编写代码,可以大大提高代码的质量。
小结
队列Queue实现了一个先进先出(FIFO)的数据结构:
通过add()/offer()方法将元素添加到队尾;
通过remove()/poll()从队首获取元素并删除;
通过element()/peek()从队首获取元素但不删除。
要避免把null添加到队列。
我们知道,Queue是一个先进先出(FIFO)的队列。
在银行柜台办业务时,我们假设只有一个柜台在办理业务,但是办理业务的人很多,怎么办?
可以每个人先取一个号,例如:A1、A2、A3……然后,按照号码顺序依次办理,实际上这就是一个Queue。
如果这时来了一个VIP客户,他的号码是V1,虽然当前排队的是A10、A11、A12……但是柜台下一个呼叫的客户号码却是V1。
这个时候,我们发现,要实现“VIP插队”的业务,用Queue就不行了,因为Queue会严格按FIFO的原则取出队首元素。我们需要的是优先队列:PriorityQueue。
PriorityQueue和Queue的区别在于,它的出队顺序与元素的优先级有关,对PriorityQueue调用remove()或poll()方法,返回的总是优先级最高的元素。
要使用PriorityQueue,我们就必须给每个元素定义“优先级”。我们以实际代码为例,先看看PriorityQueue的行为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import java.util.PriorityQueue;import java.util.Queue;public class Main { public static void main (String[] args) { Queue<String> q = new PriorityQueue <>(); q.offer("apple" ); q.offer("pear" ); q.offer("banana" ); System.out.println(q.poll()); System.out.println(q.poll()); System.out.println(q.poll()); System.out.println(q.poll()); } }
我们放入的顺序是"apple"、"pear"、"banana",但是取出的顺序却是"apple"、"banana"、"pear",这是因为从字符串的排序看,"apple"排在最前面,"pear"排在最后面。
因此,放入PriorityQueue的元素,必须实现Comparable接口,PriorityQueue会根据元素的排序顺序决定出队的优先级。
如果我们要放入的元素并没有实现Comparable接口怎么办?PriorityQueue允许我们提供一个Comparator对象来判断两个元素的顺序。我们以银行排队业务为例,实现一个PriorityQueue:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import java.util.Comparator;import java.util.PriorityQueue;import java.util.Queue;public class Main { public static void main (String[] args) { Queue<User> q = new PriorityQueue <>(new UserComparator ()); q.offer(new User ("Bob" , "A1" )); q.offer(new User ("Alice" , "A2" )); q.offer(new User ("Boss" , "V1" )); System.out.println(q.poll()); System.out.println(q.poll()); System.out.println(q.poll()); System.out.println(q.poll()); } } class UserComparator implements Comparator <User> { public int compare (User u1, User u2) { if (u1.number.charAt(0 ) == u2.number.charAt(0 )) { return u1.number.compareTo(u2.number); } if (u1.number.charAt(0 ) == 'V' ) { return -1 ; } else { return 1 ; } } } class User { public final String name; public final String number; public User (String name, String number) { this .name = name; this .number = number; } public String toString () { return name + "/" + number; } }
实现PriorityQueue的关键在于提供的UserComparator对象,它负责比较两个元素的大小(较小的在前)。UserComparator总是把V开头的号码优先返回,只有在开头相同的时候,才比较号码大小。
上面的UserComparator的比较逻辑其实还是有问题的,它会把A10排在A2的前面,请尝试修复该错误。
小结
PriorityQueue实现了一个优先队列:从队首获取元素时,总是获取优先级最高的元素;
PriorityQueue默认按元素比较的顺序排序(必须实现Comparable接口),也可以通过Comparator自定义排序算法(元素就不必实现Comparable接口)。
使用Deque
我们知道,Queue是队列,只能一头进,另一头出。
如果把条件放松一下,允许两头都进,两头都出,这种队列叫双端队列(Double Ended Queue),学名Deque。
Java集合提供了接口Deque来实现一个双端队列,它的功能是:
既可以添加到队尾,也可以添加到队首;
既可以从队首获取,又可以从队尾获取。
我们来比较一下Queue和Deque出队和入队的方法:
Queue
Deque
添加元素到队尾
add(E e) / offer(E e)
addLast(E e) / offerLast(E e)
取队首元素并删除
E remove() / E poll()
E removeFirst() / E pollFirst()
取队首元素但不删除
E element() / E peek()
E getFirst() / E peekFirst()
添加元素到队首
无
addFirst(E e) / offerFirst(E e)
取队尾元素并删除
无
E removeLast() / E pollLast()
取队尾元素但不删除
无
E getLast() / E peekLast()
对于添加元素到队尾的操作,Queue提供了add()/offer()方法,而Deque提供了addLast()/offerLast()方法。添加元素到队首、取队尾元素的操作在Queue中不存在,在Deque中由addFirst()/removeLast()等方法提供。
注意到Deque接口实际上扩展自Queue:
1 2 3 public interface Deque <E> extends Queue <E> { ... }
因此,Queue提供的add()/offer()方法在Deque中也可以使用,但是,使用Deque,最好不要调用offer(),而是调用offerLast():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import java.util.Deque;import java.util.LinkedList;public class Main { public static void main (String[] args) { Deque<String> deque = new LinkedList <>(); deque.offerLast("A" ); deque.offerLast("B" ); deque.offerFirst("C" ); System.out.println(deque.pollFirst()); System.out.println(deque.pollLast()); System.out.println(deque.pollFirst()); System.out.println(deque.pollFirst()); } }
如果直接写deque.offer(),我们就需要思考,offer()实际上是offerLast(),我们明确地写上offerLast(),不需要思考就能一眼看出这是添加到队尾。
因此,使用Deque,推荐总是明确调用offerLast()/offerFirst()或者pollFirst()/pollLast()方法。
Deque是一个接口,它的实现类有ArrayDeque和LinkedList。
我们发现LinkedList真是一个全能选手,它即是List,又是Queue,还是Deque。但是我们在使用的时候,总是用特定的接口来引用它,这是因为持有接口说明代码的抽象层次更高,而且接口本身定义的方法代表了特定的用途。
1 2 3 4 5 6 LinkedList<String> d1 = new LinkedList <>(); d1.offerLast("z" ); Deque<String> d2 = new LinkedList <>(); d2.offerLast("z" );
可见面向抽象编程的一个原则就是:尽量持有接口,而不是具体的实现类。
小结
Deque实现了一个双端队列(Double Ended Queue),它可以:
将元素添加到队尾或队首:addLast()/offerLast()/addFirst()/offerFirst();
从队首/队尾获取元素并删除:removeFirst()/pollFirst()/removeLast()/pollLast();
从队首/队尾获取元素但不删除:getFirst()/peekFirst()/getLast()/peekLast();
总是调用xxxFirst()/xxxLast()以便与Queue的方法区分开;
避免把null添加到队列。
栈(Stack)是一种后进先出(LIFO:Last In First Out)的数据结构。
什么是LIFO呢?我们先回顾一下Queue的特点FIFO:
1 2 3 4 5 ──────────────────────── (\(\ (\(\ (\(\ (\(\ (\(\ (='.') ──▶ (='.') (='.') (='.') ──▶ (='.') O(_")") O(_")") O(_")") O(_")") O(_")") ────────────────────────
所谓FIFO,是最先进队列的元素一定最早出队列,而LIFO是最后进Stack的元素一定最早出Stack。如何做到这一点呢?只需要把队列的一端封死:
1 2 3 4 5 ───────────────────────────────┐ (\(\ (\(\ (\(\ (\(\ (\(\ │ (='.') ◀──▶ (='.') (='.') (='.') (='.')│ O(_")") O(_")") O(_")") O(_")") O(_")")│ ───────────────────────────────┘
因此,Stack是这样一种数据结构:只能不断地往Stack中压入(push)元素,最后进去的必须最早弹出(pop)来:
Stack只有入栈和出栈的操作:
把元素压栈:push(E);
把栈顶的元素“弹出”:pop();
取栈顶元素但不弹出:peek()。
在Java中,我们用Deque可以实现Stack的功能:
把元素压栈:push(E)/addFirst(E);
把栈顶的元素“弹出”:pop()/removeFirst();
取栈顶元素但不弹出:peek()/peekFirst()。
为什么Java的集合类没有单独的Stack接口呢?因为有个遗留类名字就叫Stack,出于兼容性考虑,所以没办法创建Stack接口,只能用Deque接口来“模拟”一个Stack了。
当我们把Deque作为Stack使用时,注意只调用push()/pop()/peek()方法,不要调用addFirst()/removeFirst()/peekFirst()方法,这样代码更加清晰。
Stack的作用
Stack在计算机中使用非常广泛,JVM在处理Java方法调用的时候就会通过栈这种数据结构维护方法调用的层次。例如:
1 2 3 4 5 6 7 8 9 10 11 static void main (String[] args) { foo(123 ); } static String foo (x) { return "F-" + bar(x + 1 ); } static int bar (int x) { return x << 2 ; }
JVM会创建方法调用栈,每调用一个方法时,先将参数压栈,然后执行对应的方法;当方法返回时,返回值压栈,调用方法通过出栈操作获得方法返回值。
因为方法调用栈有容量限制,嵌套调用过多会造成栈溢出,即引发StackOverflowError:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { increase(1 ); } static int increase (int x) { return increase(x) + 1 ; } }
我们再来看一个Stack的用途:对整数进行进制的转换就可以利用栈。
例如,我们要把一个int整数12500转换为十六进制表示的字符串,如何实现这个功能?
首先我们准备一个空栈:
1 2 3 4 5 6 │ │ │ │ │ │ │ │ │ │ └───┘
然后计算12500÷16=781…4,余数是4,把余数4压栈:
1 2 3 4 5 6 │ │ │ │ │ │ │ │ │ 4 │ └───┘
然后计算781÷16=48…13,余数是13,13的十六进制用字母D表示,把余数D压栈:
1 2 3 4 5 6 │ │ │ │ │ │ │ D │ │ 4 │ └───┘
然后计算48÷16=3…0,余数是0,把余数0压栈:
1 2 3 4 5 6 │ │ │ │ │ 0 │ │ D │ │ 4 │ └───┘
最后计算3÷16=0…3,余数是3,把余数3压栈:
1 2 3 4 5 6 │ │ │ 3 │ │ 0 │ │ D │ │ 4 │ └───┘
当商是0的时候,计算结束,我们把栈的所有元素依次弹出,组成字符串30D4,这就是十进制整数12500的十六进制表示的字符串。
计算中缀表达式
在编写程序的时候,我们使用的带括号的数学表达式实际上是中缀表达式,即运算符在中间,例如:1 + 2 * (9 - 5)。
但是计算机执行表达式的时候,它并不能直接计算中缀表达式,而是通过编译器把中缀表达式转换为后缀表达式,例如:1 2 9 5 - * +。
这个编译过程就会用到栈。我们先跳过编译这一步(涉及运算优先级,代码比较复杂),看看如何通过栈计算后缀表达式。
计算后缀表达式不考虑优先级,直接从左到右依次计算,因此计算起来简单。首先准备一个空的栈:
1 2 3 4 5 6 │ │ │ │ │ │ │ │ │ │ └───┘
然后我们依次扫描后缀表达式1 2 9 5 - * +,遇到数字1,就直接扔到栈里:
1 2 3 4 5 6 │ │ │ │ │ │ │ │ │ 1 │ └───┘
紧接着,遇到数字2,9,5,也扔到栈里:
1 2 3 4 5 6 │ │ │ 5 │ │ 9 │ │ 2 │ │ 1 │ └───┘
接下来遇到减号时,弹出栈顶的两个元素,并计算9-5=4,把结果4压栈:
1 2 3 4 5 6 │ │ │ │ │ 4 │ │ 2 │ │ 1 │ └───┘
接下来遇到*号时,弹出栈顶的两个元素,并计算2*4=8,把结果8压栈:
1 2 3 4 5 6 │ │ │ │ │ │ │ 8 │ │ 1 │ └───┘
接下来遇到+号时,弹出栈顶的两个元素,并计算1+8=9,把结果9压栈:
1 2 3 4 5 6 │ │ │ │ │ │ │ │ │ 9 │ └───┘
扫描结束后,没有更多的计算了,弹出栈的唯一一个元素,得到计算结果9。
练习
请利用Stack把一个给定的整数转换为十六进制:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import java.util.*;public class Main { public static void main (String[] args) { String hex = toHex(12500 ); if (hex.equalsIgnoreCase("30D4" )) { System.out.println("测试通过" ); } else { System.out.println("测试失败" ); } } static String toHex (int n) { return "" ; } }
进阶练习:
请利用Stack把字符串中缀表达式编译为后缀表达式,然后再利用栈执行后缀表达式获得计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import java.util.*;public class Main { public static void main (String[] args) { String exp = "1 + 2 * (9 - 5)" ; SuffixExpression se = compile(exp); int result = se.execute(); System.out.println(exp + " = " + result + " " + (result == 1 + 2 * (9 - 5 ) ? "✓" : "✗" )); } static SuffixExpression compile (String exp) { return new SuffixExpression (); } } class SuffixExpression { int execute () { return 0 ; } }
进阶练习2:
请把带变量的中缀表达式编译为后缀表达式,执行后缀表达式时,传入变量的值并获得计算结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import java.util.*;public class Main { public static void main (String[] args) { String exp = "x + 2 * (y - 5)" ; SuffixExpression se = compile(exp); Map<String, Integer> env = Map.of("x" , 1 , "y" , 9 ); int result = se.execute(env); System.out.println(exp + " = " + result + " " + (result == 1 + 2 * (9 - 5 ) ? "✓" : "✗" )); } static SuffixExpression compile (String exp) { return new SuffixExpression (); } } class SuffixExpression { int execute (Map<String, Integer> env) { return 0 ; } }
下载练习
小结
栈(Stack)是一种后进先出(LIFO)的数据结构,操作栈的元素的方法有:
把元素压栈:push(E);
把栈顶的元素“弹出”:pop(E);
取栈顶元素但不弹出:peek(E)。
在Java中,我们用Deque可以实现Stack的功能,注意只调用push()/pop()/peek()方法,避免调用Deque的其他方法;
不要使用遗留类Stack。
Java的集合类都可以使用for each循环,List、Set和Queue会迭代每个元素,Map会迭代每个key。以List为例:
1 2 3 4 List<String> list = List.of("Apple" , "Orange" , "Pear" ); for (String s : list) { System.out.println(s); }
实际上,Java编译器并不知道如何遍历List。上述代码能够编译通过,只是因为编译器把for each循环通过Iterator改写为了普通的for循环:
1 2 3 4 for (Iterator<String> it = list.iterator(); it.hasNext(); ) { String s = it.next(); System.out.println(s); }
我们把这种通过Iterator对象遍历集合的模式称为迭代器。
使用迭代器的好处在于,调用方总是以统一的方式遍历各种集合类型,而不必关心它们内部的存储结构。
例如,我们虽然知道ArrayList在内部是以数组形式存储元素,并且,它还提供了get(int)方法。虽然我们可以用for循环遍历:
1 2 3 for (int i=0 ; i<list.size(); i++) { Object value = list.get(i); }
但是这样一来,调用方就必须知道集合的内部存储结构。并且,如果把ArrayList换成LinkedList,get(int)方法耗时会随着index的增加而增加。如果把ArrayList换成Set,上述代码就无法编译,因为Set内部没有索引。
用Iterator遍历就没有上述问题,因为Iterator对象是集合对象自己在内部创建的,它自己知道如何高效遍历内部的数据集合,调用方则获得了统一的代码,编译器才能把标准的for each循环自动转换为Iterator遍历。
如果我们自己编写了一个集合类,想要使用for each循环,只需满足以下条件:
集合类实现Iterable接口,该接口要求返回一个Iterator对象;
用Iterator对象迭代集合内部数据。
这里的关键在于,集合类通过调用iterator()方法,返回一个Iterator对象,这个对象必须自己知道如何遍历该集合。
一个简单的Iterator示例如下,它总是以倒序遍历集合:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import java.util.*;public class Main { public static void main (String[] args) { ReverseList<String> rlist = new ReverseList <>(); rlist.add("Apple" ); rlist.add("Orange" ); rlist.add("Pear" ); for (String s : rlist) { System.out.println(s); } } } class ReverseList <T> implements Iterable <T> { private List<T> list = new ArrayList <>(); public void add (T t) { list.add(t); } @Override public Iterator<T> iterator () { return new ReverseIterator (list.size()); } class ReverseIterator implements Iterator <T> { int index; ReverseIterator(int index) { this .index = index; } @Override public boolean hasNext () { return index > 0 ; } @Override public T next () { index--; return ReverseList.this .list.get(index); } } }
虽然ReverseList和ReverseIterator的实现类稍微比较复杂,但是,注意到这是底层集合库,只需编写一次。而调用方则完全按for each循环编写代码,根本不需要知道集合内部的存储逻辑和遍历逻辑。
在编写Iterator的时候,我们通常可以用一个内部类来实现Iterator接口,这个内部类可以直接访问对应的外部类的所有字段和方法。例如,上述代码中,内部类ReverseIterator可以用ReverseList.this获得当前外部类的this引用,然后,通过这个this引用就可以访问ReverseList的所有字段和方法。
小结
Iterator是一种抽象的数据访问模型。使用Iterator模式进行迭代的好处有:
对任何集合都采用同一种访问模型;
调用者对集合内部结构一无所知;
集合类返回的Iterator对象知道如何迭代。
Java提供了标准的迭代器模型,即集合类实现java.util.Iterable接口,返回java.util.Iterator实例。
Collections是JDK提供的工具类,同样位于java.util包中。它提供了一系列静态方法,能更方便地操作各种集合。
注意
Collections结尾多了一个s,不是Collection!
我们一般看方法名和参数就可以确认Collections提供的该方法的功能。例如,对于以下静态方法:
1 public static boolean addAll(Collection<? super T> c, T... elements) { ... }
addAll()方法可以给一个Collection类型的集合添加若干元素。因为方法签名是Collection,所以我们可以传入List,Set等各种集合类型。
创建空集合
对于旧版的JDK,可以使用Collections提供的一系列方法来创建空集合:
创建空List:List<T> emptyList()
创建空Map:Map<K, V> emptyMap()
创建空Set:Set<T> emptySet()
要注意到返回的空集合是不可变集合,无法向其中添加或删除元素。
新版的JDK≥9可以直接使用List.of()、Map.of()、Set.of()来创建空集合。
创建单元素集合
对于旧版的JDK,Collections提供了一系列方法来创建一个单元素集合:
创建一个元素的List:List<T> singletonList(T o)
创建一个元素的Map:Map<K, V> singletonMap(K key, V value)
创建一个元素的Set:Set<T> singleton(T o)
要注意到返回的单元素集合也是不可变集合,无法向其中添加或删除元素。
新版的JDK≥9可以直接使用List.of(T...)、Map.of(T...)、Set.of(T...)来创建任意个元素的集合。
排序
Collections可以对List进行排序。因为排序会直接修改List元素的位置,因此必须传入可变List:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import java.util.*;public class Main { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("apple" ); list.add("pear" ); list.add("orange" ); System.out.println(list); Collections.sort(list); System.out.println(list); } }
洗牌
Collections提供了洗牌算法,即传入一个有序的List,可以随机打乱List内部元素的顺序,效果相当于让计算机洗牌:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import java.util.*;public class Main { public static void main (String[] args) { List<Integer> list = new ArrayList <>(); for (int i=0 ; i<10 ; i++) { list.add(i); } System.out.println(list); Collections.shuffle(list); System.out.println(list); } }
不可变集合
Collections还提供了一组方法把可变集合封装成不可变集合:
封装成不可变List:List<T> unmodifiableList(List<? extends T> list)
封装成不可变Set:Set<T> unmodifiableSet(Set<? extends T> set)
封装成不可变Map:Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m)
这种封装实际上是通过创建一个代理对象,拦截掉所有修改方法实现的。我们来看看效果:
1 2 3 4 5 6 7 8 9 10 11 12 import java.util.*;public class Main { public static void main (String[] args) { List<String> mutable = new ArrayList <>(); mutable.add("apple" ); mutable.add("pear" ); List<String> immutable = Collections.unmodifiableList(mutable); immutable.add("orange" ); } }
然而,继续对原始的可变List进行增删是可以的,并且,会直接影响到封装后的“不可变”List:
1 2 3 4 5 6 7 8 9 10 11 12 13 import java.util.*;public class Main { public static void main (String[] args) { List<String> mutable = new ArrayList <>(); mutable.add("apple" ); mutable.add("pear" ); List<String> immutable = Collections.unmodifiableList(mutable); mutable.add("orange" ); System.out.println(immutable); } }
因此,如果我们希望把一个可变List封装成不可变List,那么,返回不可变List后,最好立刻扔掉可变List的引用,这样可以保证后续操作不会意外改变原始对象,从而造成“不可变”List变化了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import java.util.*;public class Main { public static void main (String[] args) { List<String> mutable = new ArrayList <>(); mutable.add("apple" ); mutable.add("pear" ); List<String> immutable = Collections.unmodifiableList(mutable); mutable = null ; System.out.println(immutable); } }
线程安全集合
Collections还提供了一组方法,可以把线程不安全的集合变为线程安全的集合:
变为线程安全的List:List<T> synchronizedList(List<T> list)
变为线程安全的Set:Set<T> synchronizedSet(Set<T> s)
变为线程安全的Map:Map<K,V> synchronizedMap(Map<K,V> m)
多线程的概念我们会在后面讲。因为从Java 5开始,引入了更高效的并发集合类,所以上述这几个同步方法已经没有什么用了。
小结
Collections类提供了一组工具方法来方便使用集合类:
创建空集合;
创建单元素集合;
创建不可变集合;
排序/洗牌等操作。
留言與分享