
在大型应用程序中,配置主从数据库并使用读写分离是常见的设计模式。在Spring应用程序中,要实现读写分离,最好不要对现有代码进行改动,而是在底层透明地支持。
Spring内置了一个AbstractRoutingDataSource,它可以把多个数据源配置成一个Map,然后,根据不同的key返回不同的数据源。因为AbstractRoutingDataSource也是一个DataSource接口,因此,应用程序可以先设置好key, 访问数据库的代码就可以从AbstractRoutingDataSource拿到对应的一个真实的数据源,从而访问指定的数据库。它的结构看起来像这样:
1 | ┌───────────────────────────┐ |
第一步:配置多数据源
首先,我们在SpringBoot中配置两个数据源,其中第二个数据源是ro-datasource:
1 | spring: |
在开发环境下,没有必要配置主从数据库。只需要给数据库设置两个用户,一个rw具有读写权限,一个ro只有SELECT权限,这样就模拟了生产环境下对主从数据库的读写分离。
在SpringBoot的配置代码中,我们初始化两个数据源:
1 |
|
第二步:编写RoutingDataSource
然后,我们用Spring内置的RoutingDataSource,把两个真实的数据源代理为一个动态数据源:
1 | public class RoutingDataSource extends AbstractRoutingDataSource { |
对这个RoutingDataSource,需要在SpringBoot中配置好并设置为主数据源:
1 |
|
现在,RoutingDataSource配置好了,但是,路由的选择是写死的,即永远返回"masterDataSource",
现在问题来了:如何存储动态选择的key以及在哪设置key?
在Servlet的线程模型中,使用ThreadLocal存储key最合适,因此,我们编写一个RoutingDataSourceContext,来设置并动态存储key:
1 | public class RoutingDataSourceContext implements AutoCloseable { |
然后,修改RoutingDataSource,获取key的代码如下:
1 | public class RoutingDataSource extends AbstractRoutingDataSource { |
这样,在某个地方,例如一个Controller的方法内部,就可以动态设置DataSource的Key:
1 |
|
到此为止,我们已经成功实现了数据库的动态路由访问。
这个方法是可行的,但是,需要读从数据库的地方,就需要加上一大段try (RoutingDataSourceContext ctx = ...) {}代码,使用起来十分不便。有没有方法可以简化呢?
有!
我们仔细想想,Spring提供的声明式事务管理,就只需要一个@Transactional()注解,放在某个Java方法上,这个方法就自动具有了事务。
我们也可以编写一个类似的@RoutingWith("slaveDataSource")注解,放到某个Controller的方法上,这个方法内部就自动选择了对应的数据源。代码看起来应该像这样:
1 |
|
这样,完全不修改应用程序的逻辑,只在必要的地方加上注解,自动实现动态数据源切换,这个方法是最简单的。
想要在应用程序中少写代码,我们就得多做一点底层工作:必须使用类似Spring实现声明式事务的机制,即用AOP实现动态数据源切换。
实现这个功能也非常简单,编写一个RoutingAspect,利用AspectJ实现一个Around拦截:
1 |
|
注意方法的第二个参数RoutingWith是Spring传入的注解实例,我们根据注解的value()获取配置的key。编译前需要添加一个Maven依赖:
1 | <dependency> |
到此为止,我们就实现了用注解动态选择数据源的功能。最后一步重构是用字符串常量替换散落在各处的"masterDataSource"和"slaveDataSource"。
使用限制
受Servlet线程模型的局限,动态数据源不能在一个请求内设定后再修改,也就是@RoutingWith不能嵌套。此外,@RoutingWith和@Transactional混用时,要设定AOP的优先级。
本文代码需要SpringBoot支持,JDK 1.8编译并打开-parameters编译参数。
使用Conditional
使用Profile能根据不同的Profile进行条件装配,但是Profile控制比较糙,如果想要精细控制,例如,配置本地存储,AWS存储和阿里云存储,将来很可能会增加Azure存储等,用Profile就很难实现。
Spring本身提供了条件装配@Conditional,但是要自己编写比较复杂的Condition来做判断,比较麻烦。Spring Boot则为我们准备好了几个非常有用的条件:
- @ConditionalOnProperty:如果有指定的配置,条件生效;
- @ConditionalOnBean:如果有指定的Bean,条件生效;
- @ConditionalOnMissingBean:如果没有指定的Bean,条件生效;
- @ConditionalOnMissingClass:如果没有指定的Class,条件生效;
- @ConditionalOnWebApplication:在Web环境中条件生效;
- @ConditionalOnExpression:根据表达式判断条件是否生效。
我们以最常用的@ConditionalOnProperty为例,把上一节的StorageService改写如下。首先,定义配置storage.type=xxx,用来判断条件,默认为local:
1 | storage: |
设定为local时,启用LocalStorageService:
1 |
|
设定为aws时,启用AwsStorageService:
1 |
|
设定为aliyun时,启用AliyunStorageService:
1 |
|
注意到LocalStorageService的注解,当指定配置为local,或者配置不存在,均启用LocalStorageService。
可见,Spring Boot提供的条件装配使得应用程序更加具有灵活性。
练习
使用Spring Boot提供的条件装配。
小结
Spring Boot提供了几个非常有用的条件装配注解,可实现灵活的条件装配。
Profile本身是Spring提供的功能,我们在使用条件装配中已经讲到了,Profile表示一个环境的概念,如开发、测试和生产这3个环境:
- native
- test
- production
或者按git分支定义master、dev这些环境:
- master
- dev
在启动一个Spring应用程序的时候,可以传入一个或多个环境,例如:
1 | -Dspring.profiles.active=test,master |
大多数情况下,使用一个环境就足够了。
Spring Boot对Profiles的支持在于,可以在application.yml中为每个环境进行配置。下面是一个示例配置:
1 | spring: |
注意到分隔符---,最前面的配置是默认配置,不需要指定Profile,后面的每段配置都必须以spring.config.activate.on-profile: xxx开头,表示一个Profile。上述配置默认使用8080端口,但是在test环境下,使用8000端口,在production环境下,使用80端口,并且启用Pebble的缓存。
如果我们不指定任何Profile,直接启动应用程序,那么Profile实际上就是default,可以从Spring Boot启动日志看出:
1 | ... |
上述日志显示未设置Profile,使用默认的Profile为default。
要以test环境启动,可输入如下命令:
1 | $ java -Dspring.profiles.active=test -jar springboot-profiles-1.0-SNAPSHOT.jar |
从日志看到活动的Profile是test,Tomcat的监听端口是8000。
通过Profile可以实现一套代码在不同环境启用不同的配置和功能。假设我们需要一个存储服务,在本地开发时,直接使用文件存储即可,但是,在测试和生产环境,需要存储到云端如S3上,如何通过Profile实现该功能?
首先,我们要定义存储接口StorageService:
1 | public interface StorageService { |
本地存储可通过LocalStorageService实现:
1 |
|
而云端存储可通过CloudStorageService实现:
1 |
|
注意到LocalStorageService使用了条件装配@Profile("default"),即默认启用LocalStorageService,而CloudStorageService使用了条件装配@Profile("!default"),即非default环境时,自动启用CloudStorageService。这样,一套代码,就实现了不同环境启用不同的配置。
练习
使用Profile启动Spring Boot应用。
小结
Spring Boot允许在一个配置文件中针对不同Profile进行配置;
Spring Boot在未指定Profile时默认为default。
使用Actuator
在生产环境中,需要对应用程序的状态进行监控。前面我们已经介绍了使用JMX对Java应用程序包括JVM进行监控,使用JMX需要把一些监控信息以MBean的形式暴露给JMX Server,而Spring Boot已经内置了一个监控功能,它叫Actuator。
使用Actuator非常简单,只需添加如下依赖:
1 | <dependency> |
然后正常启动应用程序,Actuator会把它能收集到的所有信息都暴露给JMX。此外,Actuator还可以通过URL/actuator/挂载一些监控点,例如,输入http://localhost:8080/actuator/health,我们可以查看应用程序当前状态:
1 | { |
许多网关作为反向代理需要一个URL来探测后端集群应用是否存活,这个URL就可以提供给网关使用。
Actuator默认把所有访问点暴露给JMX,但处于安全原因,只有health和info会暴露给Web。Actuator提供的所有访问点均在官方文档列出,要暴露更多的访问点给Web,需要在application.yml中加上配置:
1 | management: |
要特别注意暴露的URL的安全性,例如,/actuator/env可以获取当前机器的所有环境变量,不可暴露给公网。
练习
使用Actuator实现监控。
小结
Spring Boot提供了一个Actuator,可以方便地实现监控,并可通过Web访问特定类型的监控。
打包Spring Boot应用
我们在Maven的使用插件一节中介绍了如何使用maven-shade-plugin打包一个可执行的jar包。在Spring Boot应用中,打包更加简单,因为Spring Boot自带一个更简单的spring-boot-maven-plugin插件用来打包,我们只需要在pom.xml中加入以下配置:
1 | <project ...> |
无需任何配置,Spring Boot的这款插件会自动定位应用程序的入口Class,我们执行以下Maven命令即可打包:
1 | $ mvn clean package |
以springboot-exec-jar项目为例,打包后我们在target目录下可以看到两个jar文件:
1 | $ ls |
其中,springboot-exec-jar-1.0-SNAPSHOT.jar.original是Maven标准打包插件打的jar包,它只包含我们自己的Class,不包含依赖,而springboot-exec-jar-1.0-SNAPSHOT.jar是Spring Boot打包插件创建的包含依赖的jar,可以直接运行:
1 | $ java -jar springboot-exec-jar-1.0-SNAPSHOT.jar |
这样,部署一个Spring Boot应用就非常简单,无需预装任何服务器,只需要上传jar包即可。
在打包的时候,因为打包后的Spring Boot应用不会被修改,因此,默认情况下,spring-boot-devtools这个依赖不会被打包进去。但是要注意,使用早期的Spring Boot版本时,需要配置一下才能排除spring-boot-devtools这个依赖:
1 | <plugin> |
如果不喜欢默认的项目名+版本号作为文件名,可以加一个配置指定文件名:
1 | <project ...> |
这样打包后的文件名就是awesome-app.jar。
练习
使用Spring Boot插件打包可执行jar。
小结
Spring Boot提供了一个Maven插件用于打包所有依赖到单一jar文件,此插件十分易用,无需配置。
在开发阶段,我们经常要修改代码,然后重启Spring Boot应用。经常手动停止再启动,比较麻烦。
Spring Boot提供了一个开发者工具,可以监控classpath路径上的文件。只要源码或配置文件发生修改,Spring Boot应用可以自动重启。在开发阶段,这个功能比较有用。
要使用这一开发者功能,我们只需添加如下依赖到pom.xml:
1 | <dependency> |
然后,没有然后了。直接启动应用程序,然后试着修改源码,保存,观察日志输出,Spring Boot会自动重新加载。
默认配置下,针对/static、/public和/templates目录中的文件修改,不会自动重启,因为禁用缓存后,这些文件的修改可以实时更新。
练习
使用devtools检测修改并自动重启。
小结
Spring Boot提供了一个开发阶段非常有用的spring-boot-devtools,能自动检测classpath路径上文件修改并自动重启。
要了解Spring Boot,我们先来编写第一个Spring Boot应用程序,看看与前面我们编写的Spring应用程序有何异同。
我们新建一个springboot-hello的工程,创建标准的Maven目录结构如下:
1 | springboot-hello |
其中,在src/main/resources目录下,注意到几个文件:
application.yml
这是Spring Boot默认的配置文件,它采用YAML格式而不是.properties格式,文件名必须是application.yml而不是其他名称。
YAML格式比key=value格式的.properties文件更易读。比较一下两者的写法:
使用.properties格式:
1 | # application.properties |
使用YAML格式:
1 | # application.yml |
可见,YAML是一种层级格式,它和.properties很容易互相转换,它的优点是去掉了大量重复的前缀,并且更加易读。
提示
也可以使用application.properties作为配置文件,但不如YAML格式简单。
使用环境变量
在配置文件中,我们经常使用如下的格式对某个key进行配置:
1 | app: |
这种${DB_HOST:localhost}意思是,首先从环境变量查找DB_HOST,如果环境变量定义了,那么使用环境变量的值,否则,使用默认值localhost。
这使得我们在开发和部署时更加方便,因为开发时无需设定任何环境变量,直接使用默认值即本地数据库,而实际线上运行的时候,只需要传入环境变量即可:
1 | $ DB_HOST=10.0.1.123 DB_USER=prod DB_PASSWORD=xxxx java -jar xxx.jar |
logback-spring.xml
这是Spring Boot的logback配置文件名称(也可以使用logback.xml),一个标准的写法如下:
1 |
|
它主要通过<include resource="..." />引入了Spring Boot的一个缺省配置,这样我们就可以引用类似${CONSOLE_LOG_PATTERN}这样的变量。上述配置定义了一个控制台输出和文件输出,可根据需要修改。
static是静态文件目录,templates是模板文件目录,注意它们不再存放在src/main/webapp下,而是直接放到src/main/resources这个classpath目录,因为在Spring Boot中已经不需要专门的webapp目录了。
以上就是Spring Boot的标准目录结构,它完全是一个基于Java应用的普通Maven项目。
我们再来看源码目录结构:
1 | src/main/java |
在存放源码的src/main/java目录中,Spring Boot对Java包的层级结构有一个要求。注意到我们的根package是com.itranswarp.learnjava,下面还有entity、service、web等子package。Spring Boot要求main()方法所在的启动类必须放到根package下,命名不做要求,这里我们以Application.java命名,它的内容如下:
1 |
|
启动Spring Boot应用程序只需要一行代码加上一个注解@SpringBootApplication,该注解实际上又包含了:
- @SpringBootConfiguration
- @Configuration
- @EnableAutoConfiguration
- @AutoConfigurationPackage
- @ComponentScan
这样一个注解就相当于启动了自动配置和自动扫描。
我们再观察pom.xml,它的内容如下:
1 | <project ...> |
使用Spring Boot时,强烈推荐从spring-boot-starter-parent继承,因为这样就可以引入Spring Boot的预置配置。
紧接着,我们引入了依赖spring-boot-starter-web和spring-boot-starter-jdbc,它们分别引入了Spring MVC相关依赖和Spring JDBC相关依赖,无需指定版本号,因为引入的<parent>内已经指定了,只有我们自己引入的某些第三方jar包需要指定版本号。这里我们引入pebble-spring-boot-starter作为View,以及hsqldb作为嵌入式数据库。hsqldb已在spring-boot-starter-jdbc中预置了版本号3.0.0,因此此处无需指定版本号。
根据pebble-spring-boot-starter的文档,加入如下配置到application.yml:
1 | pebble: |
对Application稍作改动,添加WebMvcConfigurer这个Bean:
1 |
|
现在就可以直接运行Application,启动后观察Spring Boot的日志:
1 | . ____ _ __ _ _ |
Spring Boot自动启动了嵌入式Tomcat,当看到Started Application in xxx seconds时,Spring Boot应用启动成功。
现在,我们在浏览器输入localhost:8080就可以直接访问页面。那么问题来了:
前面我们定义的数据源、声明式事务、JdbcTemplate在哪创建的?怎么就可以直接注入到自己编写的UserService中呢?
这些自动创建的Bean就是Spring Boot的特色:AutoConfiguration。
当我们引入spring-boot-starter-jdbc时,启动时会自动扫描所有的XxxAutoConfiguration:
DataSourceAutoConfiguration:自动创建一个DataSource,其中配置项从application.yml的spring.datasource读取;DataSourceTransactionManagerAutoConfiguration:自动创建了一个基于JDBC的事务管理器;JdbcTemplateAutoConfiguration:自动创建了一个JdbcTemplate。
因此,我们自动得到了一个DataSource、一个DataSourceTransactionManager和一个JdbcTemplate。
类似的,当我们引入spring-boot-starter-web时,自动创建了:
ServletWebServerFactoryAutoConfiguration:自动创建一个嵌入式Web服务器,默认是Tomcat;DispatcherServletAutoConfiguration:自动创建一个DispatcherServlet;HttpEncodingAutoConfiguration:自动创建一个CharacterEncodingFilter;WebMvcAutoConfiguration:自动创建若干与MVC相关的Bean。- …
引入第三方pebble-spring-boot-starter时,自动创建了:
PebbleAutoConfiguration:自动创建了一个PebbleViewResolver。
Spring Boot大量使用XxxAutoConfiguration来使得许多组件被自动化配置并创建,而这些创建过程又大量使用了Spring的Conditional功能。例如,我们观察JdbcTemplateAutoConfiguration,它的代码如下:
1 |
|
当满足条件:
@ConditionalOnClass:在classpath中能找到DataSource和JdbcTemplate;@ConditionalOnSingleCandidate(DataSource.class):在当前Bean的定义中能找到唯一的DataSource;
该JdbcTemplateAutoConfiguration就会起作用。实际创建由导入的JdbcTemplateConfiguration完成:
1 |
|
创建JdbcTemplate之前,要满足@ConditionalOnMissingBean(JdbcOperations.class),即不存在JdbcOperations的Bean。
如果我们自己创建了一个JdbcTemplate,例如,在Application中自己写个方法:
1 |
|
那么根据条件@ConditionalOnMissingBean(JdbcOperations.class),Spring Boot就不会再创建一个重复的JdbcTemplate(因为JdbcOperations是JdbcTemplate的父类)。
可见,Spring Boot自动装配功能是通过自动扫描+条件装配实现的,这一套机制在默认情况下工作得很好,但是,如果我们要手动控制某个Bean的创建,就需要详细地了解Spring Boot自动创建的原理,很多时候还要跟踪XxxAutoConfiguration,以便设定条件使得某个Bean不会被自动创建。
练习
使用Spring Boot编写hello应用程序。
小结
Spring Boot是一个基于Spring提供了开箱即用的一组套件,它可以让我们基于很少的配置和代码快速搭建出一个完整的应用程序。
Spring Boot有非常强大的AutoConfiguration功能,它是通过自动扫描+条件装配实现的。
Spring Boot开发
我们已经在前面详细介绍了Spring框架,它的主要功能包括IoC容器、AOP支持、事务支持、MVC开发以及强大的第三方集成功能等。
那么,Spring Boot又是什么?它和Spring是什么关系?
Spring Boot是一个基于Spring的套件,它帮我们预组装了Spring的一系列组件,以便以尽可能少的代码和配置来开发基于Spring的Java应用程序。
以汽车为例,如果我们想组装一辆汽车,我们需要发动机、传动、轮胎、底盘、外壳、座椅、内饰等各种部件,然后把它们装配起来。Spring就相当于提供了一系列这样的部件,但是要装好汽车上路,还需要我们自己动手。而Spring Boot则相当于已经帮我们预装好了一辆可以上路的汽车,如果有特殊的要求,例如把发动机从普通款换成涡轮增压款,可以通过修改配置或编写少量代码完成。
因此,Spring Boot和Spring的关系就是整车和零部件的关系,它们不是取代关系,试图跳过Spring直接学习Spring Boot是不可能的。
Spring Boot的目标就是提供一个开箱即用的应用程序架构,我们基于Spring Boot的预置结构继续开发,省时省力。
本章我们将详细介绍如何使用Spring Boot。
本教程使用的Spring Boot版本是3.x版,如果使用Spring Boot 2.x则需注意,两者有以下不同:
| Spring Boot 2.x | Spring Boot 3.x | |
|---|---|---|
| Spring版本 | Spring 5.x | Spring 6.x |
| JDK版本 | >= 1.8 | >= 17 |
| Tomcat版本 | 9.x | 10.x |
| Annotation包 | javax.annotation | jakarta.annotation |
| Servlet包 | javax.servlet | jakarta.servlet |
| JMS包 | javax.jms | jakarta.jms |
| JavaMail包 | javax.mail | jakarta.mail |
如果使用Spring Boot的其他版本,则需要根据需要调整代码。
Spring Boot的官网入口是这里,建议添加到浏览器收藏夹。
加载配置文件
加载配置文件可以直接使用注解@Value,例如,我们定义了一个最大允许上传的文件大小配置:
1 | storage: |
在某个FileUploader里,需要获取该配置,可使用@Value注入:
1 |
|
在另一个UploadFilter中,因为要检查文件的MD5,同时也要检查输入流的大小,因此,也需要该配置:
1 |
|
多次引用同一个@Value不但麻烦,而且@Value使用字符串,缺少编译器检查,容易造成多处引用不一致(例如,UploadFilter把缺省值误写为100000)。
为了更好地管理配置,Spring Boot允许创建一个Bean,持有一组配置,并由Spring Boot自动注入。
假设我们在application.yml中添加了如下配置:
1 | storage: |
可以首先定义一个Java Bean,持有该组配置:
1 | public class StorageConfiguration { |
保证Java Bean的属性名称与配置一致即可。然后,我们添加两个注解:
1 |
|
注意到@ConfigurationProperties("storage.local")表示将从配置项storage.local读取该项的所有子项配置,并且,@Configuration表示StorageConfiguration也是一个Spring管理的Bean,可直接注入到其他Bean中:
1 |
|
这样一来,引入storage.local的相关配置就很容易了,因为只需要注入StorageConfiguration这个Bean,这样可以由编译器检查类型,无需编写重复的@Value注解。
练习
用Spring Boot加载配置文件。
小结
Spring Boot提供了@ConfigurationProperties注解,可以非常方便地把一段配置加载到一个Bean中。
Spring Boot大量使用自动配置和默认配置,极大地减少了代码,通常只需要加上几个注解,并按照默认规则设定一下必要的配置即可。例如,配置JDBC,默认情况下,只需要配置一个spring.datasource:
1 | spring: |
Spring Boot就会自动创建出DataSource、JdbcTemplate、DataSourceTransactionManager,非常方便。
但是,有时候,我们又必须要禁用某些自动配置。例如,系统有主从两个数据库,而Spring Boot的自动配置只能配一个,怎么办?
这个时候,针对DataSource相关的自动配置,就必须关掉。我们需要用exclude指定需要关掉的自动配置:
1 |
|
现在,Spring Boot不再给我们自动创建DataSource、JdbcTemplate和DataSourceTransactionManager了,要实现主从数据库支持,怎么办?
让我们一步一步开始编写支持主从数据库的功能。首先,我们需要把主从数据库配置写到application.yml中,仍然按照Spring Boot默认的格式写,但datasource改为datasource-master和datasource-slave:
1 | spring: |
注意到两个数据库实际上是同一个库。如果使用MySQL,可以创建一个只读用户,作为datasource-slave的用户来模拟一个从库。
下一步,我们分别创建两个HikariCP的DataSource:
1 | public class MasterDataSourceConfiguration { |
注意到上述class并未添加@Configuration和@Component,要使之生效,可以使用@Import导入:
1 |
|
此外,上述两个DataSource的Bean名称分别为masterDataSource和slaveDataSource,我们还需要一个最终的@Primary标注的DataSource,它采用Spring提供的AbstractRoutingDataSource,代码实现如下:
1 | class RoutingDataSource extends AbstractRoutingDataSource { |
RoutingDataSource本身并不是真正的DataSource,它通过Map关联一组DataSource,下面的代码创建了包含两个DataSource的RoutingDataSource,关联的key分别为masterDataSource和slaveDataSource:
1 | public class RoutingDataSourceConfiguration { |
仍然需要自己创建JdbcTemplate和PlatformTransactionManager,注入的是标记为@Primary的RoutingDataSource。
这样,我们通过如下的代码就可以切换RoutingDataSource底层使用的真正的DataSource:
1 | RoutingDataSourceContext.setDataSourceRoutingKey("slaveDataSource"); |
只不过写代码切换DataSource即麻烦又容易出错,更好的方式是通过注解配合AOP实现自动切换,这样,客户端代码实现如下:
1 |
|
实现上述功能需要编写一个@RoutingWithSlave注解,一个AOP织入和一个ThreadLocal来保存key。由于代码比较简单,这里我们不再详述。
如果我们想要确认是否真的切换了DataSource,可以覆写determineTargetDataSource()方法并打印出DataSource的名称:
1 | class RoutingDataSource extends AbstractRoutingDataSource { |
访问不同的URL,可以在日志中看到两个DataSource,分别是HikariPool-1和hikariPool-2:
1 | 2020-06-14 17:55:21.676 INFO 91561 --- [nio-8080-exec-7] c.i.learnjava.config.RoutingDataSource : determin target datasource: HikariDataSource (HikariPool-1) |
我们用一个图来表示创建的DataSource以及相关Bean的关系:
1 | ┌────────────────────┐ ┌──────────────────┐ |
注意到DataSourceTransactionManager和JdbcTemplate引用的都是RoutingDataSource,所以,这种设计的一个限制就是:在一个请求中,一旦切换了内部数据源,在同一个事务中,不能再切到另一个,否则,DataSourceTransactionManager和JdbcTemplate操作的就不是同一个数据库连接。
练习
禁用DataSourceAutoConfiguration并配置多数据源。
小结
可以通过@EnableAutoConfiguration(exclude = {...})指定禁用的自动配置;
可以通过@Import({...})导入自定义配置。
添加Filter
我们在Spring中已经学过了集成Filter,本质上就是通过代理,把Spring管理的Bean注册到Servlet容器中,不过步骤比较繁琐,需要配置web.xml。
在Spring Boot中,添加一个Filter更简单了,可以做到零配置。我们来看看在Spring Boot中如何添加Filter。
Spring Boot会自动扫描所有的FilterRegistrationBean类型的Bean,然后,将它们返回的Filter自动注册到Servlet容器中,无需任何配置。
我们还是以AuthFilter为例,首先编写一个AuthFilterRegistrationBean,它继承自FilterRegistrationBean:
1 |
|
FilterRegistrationBean本身不是Filter,它实际上是Filter的工厂。Spring Boot会调用getFilter(),把返回的Filter注册到Servlet容器中。因为我们可以在FilterRegistrationBean中注入需要的资源,然后,在返回的AuthFilter中,这个内部类可以引用外部类的所有字段,自然也包括注入的UserService,所以,整个过程完全基于Spring的IoC容器完成。
再注意到AuthFilterRegistrationBean使用了setOrder(10),因为Spring Boot支持给多个Filter排序,数字小的在前面,所以,多个Filter的顺序是可以固定的。
我们再编写一个ApiFilter,专门过滤/api/*这样的URL。首先编写一个ApiFilterRegistrationBean
1 |
|
这个ApiFilterRegistrationBean和AuthFilterRegistrationBean又有所不同。因为我们要过滤URL,而不是针对所有URL生效,因此,在@PostConstruct方法中,通过setFilter()设置一个Filter实例后,再调用setUrlPatterns()传入要过滤的URL列表。
练习
在Spring Boot中添加Filter并指定顺序。
小结
在Spring Boot中添加Filter更加方便,并且支持对多个Filter进行排序。
和Spring相比,使用Spring Boot通过自动配置来集成第三方组件通常来说更简单。
我们将详细介绍如何通过Spring Boot集成常用的第三方组件,包括:
- Open API
- Redis
- Artemis
- RabbitMQ
- Kafka
Open API是一个标准,它的主要作用是描述REST API,既可以作为文档给开发者阅读,又可以让机器根据这个文档自动生成客户端代码等。
在Spring Boot应用中,假设我们编写了一堆REST API,如何添加Open API的支持?
我们只需要在pom.xml中加入以下依赖:
- org.springdoc:springdoc-openapi-starter-webmvc-ui:2.0.0
然后呢?没有然后了,直接启动应用,打开浏览器输入http://localhost:8080/swagger-ui.html:
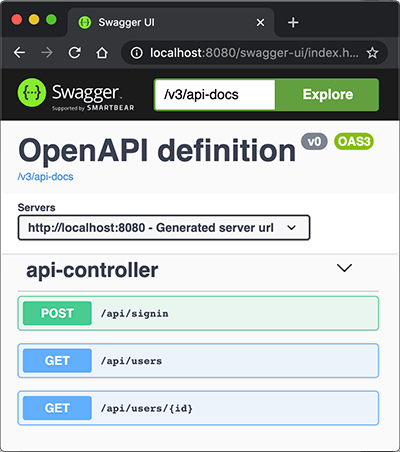
立刻可以看到自动生成的API文档,这里列出了3个API,来自api-controller(因为定义在ApiController这个类中),点击某个API还可以交互,即输入API参数,点“Try it out”按钮,获得运行结果。
是不是太方便了!
因为我们引入springdoc-openapi-ui这个依赖后,它自动引入Swagger UI用来创建API文档。可以给API加入一些描述信息,例如:
1 |
|
@Operation可以对API进行描述,@Parameter可以对参数进行描述,它们的目的是用于生成API文档的描述信息。添加了描述的API文档如下:
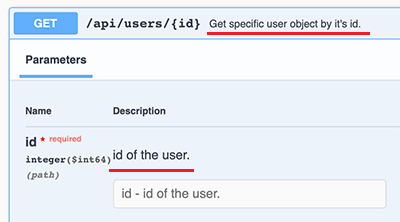
大多数情况下,不需要任何配置,我们就直接得到了一个运行时动态生成的可交互的API文档,该API文档总是和代码保持同步,大大简化了文档的编写工作。
要自定义文档的样式、控制某些API显示等,请参考springdoc文档。
配置反向代理
如果在服务器上,用户访问的域名是https://example.com,但内部是通过类似Nginx这样的反向代理访问实际的Spring Boot应用,比如http://localhost:8080,这个时候,在页面https://example.com/swagger-ui.html上,显示的URL仍然是http://localhost:8080,这样一来,就无法直接在页面执行API,非常不方便。
这是因为Spring Boot内置的Tomcat默认获取的服务器名称是localhost,端口是实际监听端口,而不是对外暴露的域名和80或443端口。要让Tomcat获取到对外暴露的域名等信息,必须在Nginx配置中传入必要的HTTP Header,常用的配置如下:
1 | # Nginx配置 |
然后,在Spring Boot的application.yml中,加入如下配置:
1 | server: |
重启Spring Boot应用,即可在Swagger中显示正确的URL。
练习
利用springdoc实现API文档。
小结
使用springdoc让其自动创建API文档非常容易,引入依赖后无需任何配置即可访问交互式API文档。
可以对API添加注解以便生成更详细的描述。
在Spring Boot中,要访问Redis,可以直接引入spring-boot-starter-data-redis依赖,它实际上是Spring Data的一个子项目——Spring Data Redis,主要用到了这几个组件:
- Lettuce:一个基于Netty的高性能Redis客户端;
- RedisTemplate:一个类似于JdbcTemplate的接口,用于简化Redis的操作。
因为Spring Data Redis引入的依赖项很多,如果只是为了使用Redis,完全可以只引入Lettuce,剩下的操作都自己来完成。
本节我们稍微深入一下Redis的客户端,看看怎么一步一步把一个第三方组件引入到Spring Boot中。
首先,我们添加必要的几个依赖项:
- io.lettuce:lettuce-core
- org.apache.commons:commons-pool2
注意我们并未指定版本号,因为在spring-boot-starter-parent中已经把常用组件的版本号确定下来了。
第一步是在配置文件application.yml中添加Redis的相关配置:
1 | spring: |
然后,通过RedisConfiguration来加载它:
1 |
|
再编写一个@Bean方法来创建RedisClient,可以直接放在RedisConfiguration中:
1 |
|
在启动入口引入该配置:
1 |
|
注意:如果在RedisConfiguration中标注@Configuration,则可通过Spring Boot的自动扫描机制自动加载,否则,使用@Import手动加载。
紧接着,我们用一个RedisService来封装所有的Redis操作。基础代码如下:
1 |
|
注意到上述代码引入了Commons Pool的一个对象池,用于缓存Redis连接。因为Lettuce本身是基于Netty的异步驱动,在异步访问时并不需要创建连接池,但基于Servlet模型的同步访问时,连接池是有必要的。连接池在@PostConstruct方法中初始化,在@PreDestroy方法中关闭。
下一步,是在RedisService中添加Redis访问方法。为了简化代码,我们仿照JdbcTemplate.execute(ConnectionCallback)方法,传入回调函数,可大幅减少样板代码。
首先定义回调函数接口SyncCommandCallback:
1 |
|
编写executeSync方法,在该方法中,获取Redis连接,利用callback操作Redis,最后释放连接,并返回操作结果:
1 | public <T> T executeSync(SyncCommandCallback<T> callback) { |
有的童鞋觉得这样访问Redis的代码太复杂了,实际上我们可以针对常用操作把它封装一下,例如set和get命令:
1 | public String set(String key, String value) { |
类似的,hget和hset操作如下:
1 | public boolean hset(String key, String field, String value) { |
常用命令可以提供方法接口,如果要执行任意复杂的操作,就可以通过executeSync(SyncCommandCallback<T>)来完成。
完成了RedisService后,我们就可以使用Redis了。例如,在UserController中,我们在Session中只存放登录用户的ID,用户信息存放到Redis,提供两个方法用于读写:
1 |
|
用户登录成功后,把ID放入Session,把User实例放入Redis:
1 |
|
需要获取User时,从Redis取出:
1 |
|
从Redis读写Java对象时,序列化和反序列化是应用程序的工作,上述代码使用JSON作为序列化方案,简单可靠。也可将相关序列化操作封装到RedisService中,这样可以提供更加通用的方法:
1 | public <T> T get(String key, Class<T> clazz) { |
练习
在Spring Boot中访问Redis。
小结
Spring Boot默认使用Lettuce作为Redis客户端,同步使用时,应通过连接池提高效率。
集成Artemis
ActiveMQ Artemis是一个JMS服务器,在集成JMS一节中我们已经详细讨论了如何在Spring中集成Artemis,本节我们讨论如何在Spring Boot中集成Artemis。
我们还是以实际工程为例,创建一个springboot-jms工程,引入的依赖除了spring-boot-starter-web,spring-boot-starter-jdbc等以外,新增spring-boot-starter-artemis:
1 | <dependency> |
同样无需指定版本号。
如何创建Artemis服务器我们已经在集成JMS一节中详细讲述了,此处不再重复。创建Artemis服务器后,我们在application.yml中加入相关配置:
1 | spring: |
和Spring版本的JMS代码相比,使用Spring Boot集成JMS时,只要引入了spring-boot-starter-artemis,Spring Boot会自动创建JMS相关的ConnectionFactory、JmsListenerContainerFactory、JmsTemplate等,无需我们再手动配置了。
发送消息时只需要引入JmsTemplate:
1 |
|
接收消息时只需要标注@JmsListener:
1 |
|
可见,应用程序收发消息的逻辑和Spring中使用JMS完全相同,只是通过Spring Boot,我们把工程简化到只需要设定Artemis相关配置。
练习
在Spring Boot中使用Artemis。
小结
在Spring Boot中使用Artemis作为JMS服务时,只需引入spring-boot-starter-artemis依赖,即可直接使用JMS。
前面我们讲了ActiveMQ Artemis,它实现了JMS的消息服务协议。JMS是JavaEE的消息服务标准接口,但是,如果Java程序要和另一种语言编写的程序通过消息服务器进行通信,那么JMS就不太适合了。
AMQP是一种使用广泛的独立于语言的消息协议,它的全称是Advanced Message Queuing Protocol,即高级消息队列协议,它定义了一种二进制格式的消息流,任何编程语言都可以实现该协议。实际上,Artemis也支持AMQP,但实际应用最广泛的AMQP服务器是使用Erlang编写的RabbitMQ。
安装RabbitMQ
我们先从RabbitMQ的官网下载并安装RabbitMQ,安装和启动RabbitMQ请参考官方文档。要验证启动是否成功,可以访问RabbitMQ的管理后台http://localhost:15672,如能看到登录界面表示RabbitMQ启动成功:
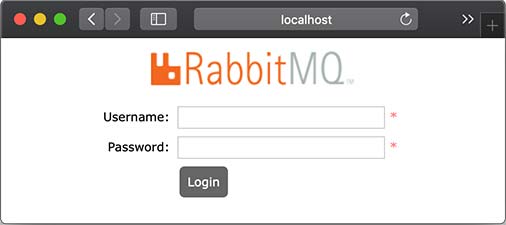
RabbitMQ后台管理的默认用户名和口令均为guest。
AMQP协议
AMQP协议和前面我们介绍的JMS协议有所不同。在JMS中,有两种类型的消息通道:
- 点对点的Queue,即Producer发送消息到指定的Queue,接收方从Queue收取消息;
- 一对多的Topic,即Producer发送消息到指定的Topic,任意多个在线的接收方均可从Topic获得一份完整的消息副本。
但是AMQP协议比JMS要复杂一点,它只有Queue,没有Topic,并且引入了Exchange的概念。当Producer想要发送消息的时候,它将消息发送给Exchange,由Exchange将消息根据各种规则投递到一个或多个Queue:
1 | ┌───────┐ |
如果某个Exchange总是把消息发送到固定的Queue,那么这个消息通道就相当于JMS的Queue。如果某个Exchange把消息发送到多个Queue,那么这个消息通道就相当于JMS的Topic。和JMS的Topic相比,Exchange的投递规则更灵活,比如一个“登录成功”的消息被投递到Queue-1和Queue-2,而“登录失败”的消息则被投递到Queue-3。这些路由规则称之为Binding,通常都在RabbitMQ的管理后台设置。
我们以具体的业务为例子,在RabbitMQ中,首先创建3个Queue,分别用于发送邮件、短信和App通知:
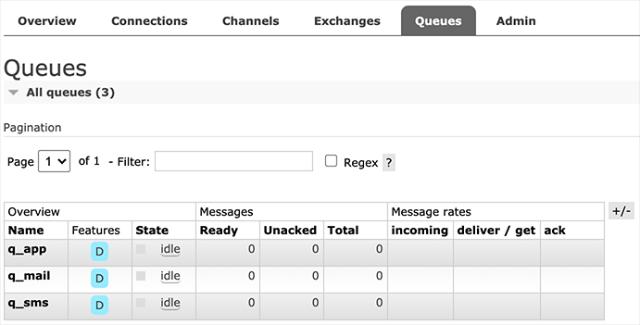
创建Queue时注意到可配置为持久化(Durable)和非持久化(Transient),当Consumer不在线时,持久化的Queue会暂存消息,非持久化的Queue会丢弃消息。
紧接着,我们在Exchanges中创建一个Direct类型的Exchange,命名为registration,并添加如下两个Binding:
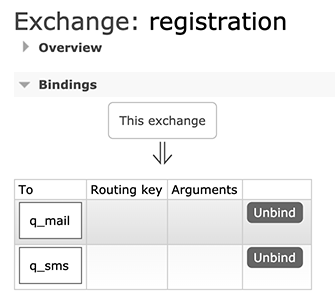
上述Binding的规则就是:凡是发送到registration这个Exchange的消息,均被发送到q_mail和q_sms这两个Queue。
我们再创建一个Direct类型的Exchange,命名为login,并添加如下Binding:
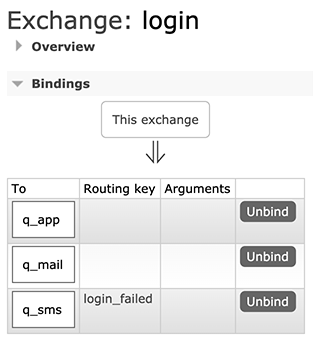
上述Binding的规则稍微复杂一点,当发送消息给login这个Exchange时,如果消息没有指定Routing Key,则被投递到q_app和q_mail,如果消息指定了Routing Key=“login_failed”,那么消息被投递到q_sms。
配置好RabbitMQ后,我们就可以基于Spring Boot开发AMQP程序。
使用RabbitMQ
我们首先创建Spring Boot工程springboot-rabbitmq,并添加如下依赖引入RabbitMQ:
1 | <dependency> |
然后在application.yml中添加RabbitMQ相关配置:
1 | spring: |
我们还需要在Application中添加一个MessageConverter:
1 | import org.springframework.amqp.support.converter.MessageConverter; |
MessageConverter用于将Java对象转换为RabbitMQ的消息。默认情况下,Spring Boot使用SimpleMessageConverter,只能发送String和byte[]类型的消息,不太方便。使用Jackson2JsonMessageConverter,我们就可以发送JavaBean对象,由Spring Boot自动序列化为JSON并以文本消息传递。
因为引入了starter,所有RabbitMQ相关的Bean均自动装配,我们需要在Producer注入的是RabbitTemplate:
1 |
|
发送消息时,使用convertAndSend(exchange, routingKey, message)可以指定Exchange、Routing Key以及消息本身。这里传入JavaBean后会自动序列化为JSON文本。上述代码将RegistrationMessage发送到registration,将LoginMessage发送到login,并根据登录是否成功来指定Routing Key。
接收消息时,需要在消息处理的方法上标注@RabbitListener:
1 |
|
上述代码一共定义了5个Consumer,监听3个Queue。
启动应用程序,我们注册一个新用户,然后发送一条RegistrationMessage消息。此时,根据registration这个Exchange的设定,我们会在两个Queue收到消息:
1 | ... c.i.learnjava.service.UserService : try register by bob@example.com... |
当我们登录失败时,发送LoginMessage并设定Routing Key为login_failed,此时,只有q_sms会收到消息:
1 | ... c.i.learnjava.service.UserService : try login by bob@example.com... |
登录成功后,发送LoginMessage,此时,q_mail和q_app将收到消息:
1 | ... c.i.learnjava.service.UserService : try login by bob@example.com... |
RabbitMQ还提供了使用Topic的Exchange(此Topic指消息的标签,并非JMS的Topic概念),可以使用*进行匹配并路由。可见,掌握RabbitMQ的核心是理解其消息的路由规则。
直接指定一个Queue并投递消息也是可以的,此时指定Routing Key为Queue的名称即可,因为RabbitMQ提供了一个default exchange用于根据Routing Key查找Queue并直接投递消息到指定的Queue。但是要实现一对多的投递就必须自己配置Exchange。
练习
在Spring Boot中使用RabbitMQ。
小结
Spring Boot提供了AMQP的集成,默认使用RabbitMQ作为AMQP消息服务器。
使用RabbitMQ发送消息时,理解Exchange如何路由至一个或多个Queue至关重要。
我们在前面已经介绍了JMS和AMQP,JMS是JavaEE的标准消息接口,Artemis是一个JMS实现产品,AMQP是跨语言的一个标准消息接口,RabbitMQ是一个AMQP实现产品。
Kafka也是一个消息服务器,它的特点一是快,二是有巨大的吞吐量,那么Kafka实现了什么标准消息接口呢?
Kafka没有实现任何标准的消息接口,它自己提供的API就是Kafka的接口。
哥没有实现任何标准,哥自己就是标准。
—— Kafka
Kafka本身是Scala编写的,运行在JVM之上。Producer和Consumer都通过Kafka的客户端使用网络来与之通信。从逻辑上讲,Kafka设计非常简单,它只有一种类似JMS的Topic的消息通道:
1 | ┌──────────┐ |
那么Kafka如何支持十万甚至百万的并发呢?答案是分区。Kafka的一个Topic可以有一个至多个Partition,并且可以分布到多台机器上:
1 | ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐ |
Kafka只保证在一个Partition内部,消息是有序的,但是,存在多个Partition的情况下,Producer发送的3个消息会依次发送到Partition-1、Partition-2和Partition-3,Consumer从3个Partition接收的消息并不一定是Producer发送的顺序,因此,多个Partition只能保证接收消息大概率按发送时间有序,并不能保证完全按Producer发送的顺序。这一点在使用Kafka作为消息服务器时要特别注意,对发送顺序有严格要求的Topic只能有一个Partition。
Kafka的另一个特点是消息发送和接收都尽量使用批处理,一次处理几十甚至上百条消息,比一次一条效率要高很多。
最后要注意的是消息的持久性。Kafka总是将消息写入Partition对应的文件,消息保存多久取决于服务器的配置,可以按照时间删除(默认3天),也可以按照文件大小删除,因此,只要Consumer在离线期内的消息还没有被删除,再次上线仍然可以接收到完整的消息流。这一功能实际上是客户端自己实现的,客户端会存储它接收到的最后一个消息的offsetId,再次上线后按上次的offsetId查询。offsetId是Kafka标识某个Partion的每一条消息的递增整数,客户端通常将它存储在ZooKeeper中。
有了Kafka消息设计的基本概念,我们来看看如何在Spring Boot中使用Kafka。
安装Kafka
首先从Kafka官网下载最新版Kafaka,解压后在bin目录找到两个文件:
zookeeper-server-start.sh:启动ZooKeeper(已内置在Kafka中);kafka-server-start.sh:启动Kafka。
先启动ZooKeeper:
1 | $ ./zookeeper-server-start.sh ../config/zookeeper.properties |
再启动Kafka:
1 | ./kafka-server-start.sh ../config/server.properties |
看到如下输出表示启动成功:
1 | ... INFO [KafkaServer id=0] started (kafka.server.KafkaServer) |
如果要关闭Kafka和ZooKeeper,依次按Ctrl-C退出即可。注意这是在本地开发时使用Kafka的方式,线上Kafka服务推荐使用云服务厂商托管模式(AWS的MSK,阿里云的消息队列Kafka版)。
使用Kafka
在Spring Boot中使用Kafka,首先要引入依赖:
1 | <dependency> |
注意这个依赖是spring-kafka项目提供的。
然后,在application.yml中添加Kafka配置:
1 | spring: |
除了bootstrap-servers必须指定外,consumer相关的配置项均为调优选项。例如,max-poll-records表示一次最多抓取100条消息。配置名称去哪里看?IDE里定义一个KafkaProperties.Consumer的变量:
1 | KafkaProperties.Consumer c = null; |
然后按住Ctrl查看源码即可。
发送消息
Spring Boot自动为我们创建一个KafkaTemplate用于发送消息。注意到这是一个泛型类,而默认配置总是使用String作为Kafka消息的类型,所以注入KafkaTemplate<String, String>即可:
1 |
|
发送消息时,需指定Topic名称,消息正文。为了发送一个JavaBean,这里我们没有使用MessageConverter来转换JavaBean,而是直接把消息类型作为Header添加到消息中,Header名称为type,值为Class全名。消息正文是序列化的JSON。
接收消息
接收消息可以使用@KafkaListener注解:
1 |
|
在接收消息的方法中,使用@Payload表示传入的是消息正文,使用@Header可传入消息的指定Header,这里传入@Header("type"),就是我们发送消息时指定的Class全名。接收消息时,我们需要根据Class全名来反序列化获得JavaBean。
上述代码一共定义了3个Listener,其中有两个方法监听的是同一个Topic,但它们的Group ID不同。假设Producer发送的消息流是A、B、C、D,Group ID不同表示这是两个不同的Consumer,它们将分别收取完整的消息流,即各自均收到A、B、C、D。Group ID相同的多个Consumer实际上被视作一个Consumer,即如果有两个Group ID相同的Consumer,那么它们各自收到的很可能是A、C和B、D。
运行应用程序,注册新用户后,观察日志输出:
1 | ... c.i.learnjava.service.UserService : try register by bob@example.com... |
用户登录后,观察日志输出:
1 | ... c.i.learnjava.service.UserService : try login by bob@example.com... |
因为Group ID不同,同一个消息被两个Consumer分别独立接收。如果把Group ID改为相同,那么同一个消息只会被两者之一接收。
有细心的童鞋可能会问,在Kafka中是如何创建Topic的?又如何指定某个Topic的分区数量?
实际上开发使用的Kafka默认允许自动创建Topic,创建Topic时默认的分区数量是2,可以通过server.properties修改默认分区数量。
在生产环境中通常会关闭自动创建功能,Topic需要由运维人员先创建好。和RabbitMQ相比,Kafka并不提供网页版管理后台,管理Topic需要使用命令行,比较繁琐,只有云服务商通常会提供更友好的管理后台。
练习
在Spring Boot中使用Kafka。
小结
Spring Boot通过KafkaTemplate发送消息,通过@KafkaListener接收消息;
配置Consumer时,指定Group ID非常重要。
Spring框架不仅提供了标准的IoC容器、AOP支持、数据库访问以及WebMVC等标准功能,还可以非常方便地集成许多常用的第三方组件:
- 可以集成JavaMail发送邮件;
- 可以集成JMS消息服务;
- 可以集成Quartz实现定时任务;
- 可以集成Redis等服务。
本章我们介绍如何在Spring中简单快捷地集成这些第三方组件。
我们在发送Email和接收Email中已经介绍了如何通过JavaMail来收发电子邮件。在Spring中,同样可以集成JavaMail。
因为在服务器端,主要以发送邮件为主,例如在注册成功、登录时、购物付款后通知用户,基本上不会遇到接收用户邮件的情况,所以本节我们只讨论如何在Spring中发送邮件。
在Spring中,发送邮件最终也是需要JavaMail,Spring只对JavaMail做了一点简单的封装,目的是简化代码。为了在Spring中集成JavaMail,我们在pom.xml中添加以下依赖:
- org.springframework:spring-context-support:6.0.0
- jakarta.mail:jakarta.mail-api:2.0.1
- com.sun.mail:jakarta.mail:2.0.1
以及其他Web相关依赖。
我们希望用户在注册成功后能收到注册邮件,为此,我们先定义一个JavaMailSender的Bean:
1 |
|
这个JavaMailSender接口的实现类是JavaMailSenderImpl,初始化时,传入的参数与JavaMail是完全一致的。
另外注意到需要注入的属性是从smtp.properties中读取的,因此,AppConfig导入的就不止一个.properties文件,可以导入多个:
1 |
|
下一步是封装一个MailService,并定义sendRegistrationMail()方法:
1 |
|
观察上述代码,MimeMessage是JavaMail的邮件对象,而MimeMessageHelper是Spring提供的用于简化设置MimeMessage的类,比如我们设置HTML邮件就可以直接调用setText(String text, boolean html)方法,而不必再调用比较繁琐的JavaMail接口方法。
最后一步是调用JavaMailSender.send()方法把邮件发送出去。
在MVC的某个Controller方法中,当用户注册成功后,我们就启动一个新线程来异步发送邮件:
1 | User user = userService.register(email, password, name); |
因为发送邮件是一种耗时的任务,从几秒到几分钟不等,因此,异步发送是保证页面能快速显示的必要措施。这里我们直接启动了一个新的线程,但实际上还有更优化的方法,我们在下一节讨论。
练习
使用Spring发送邮件。
小结
Spring可以集成JavaMail,通过简单的封装,能简化邮件发送代码。其核心是定义一个JavaMailSender的Bean,然后调用其send()方法。
JMS即Java Message Service,是JavaEE的消息服务接口。JMS主要有两个版本:1.1和2.0。2.0和1.1相比,主要是简化了收发消息的代码。
所谓消息服务,就是两个进程之间,通过消息服务器传递消息:
1 | ┌────────┐ ┌──────────────┐ ┌────────┐ |
使用消息服务,而不是直接调用对方的API,它的好处是:
- 双方各自无需知晓对方的存在,消息可以异步处理,因为消息服务器会在Consumer离线的时候自动缓存消息;
- 如果Producer发送的消息频率高于Consumer的处理能力,消息可以积压在消息服务器,不至于压垮Consumer;
- 通过一个消息服务器,可以连接多个Producer和多个Consumer。
因为消息服务在各类应用程序中非常有用,所以JavaEE专门定义了JMS规范。注意到JMS是一组接口定义,如果我们要使用JMS,还需要选择一个具体的JMS产品。常用的JMS服务器有开源的ActiveMQ,商业服务器如WebLogic、WebSphere等也内置了JMS支持。这里我们选择开源的ActiveMQ作为JMS服务器,因此,在开发JMS之前我们必须首先安装ActiveMQ。
现在问题来了:从官网下载ActiveMQ时,蹦出一个页面,让我们选择ActiveMQ Classic或者ActiveMQ Artemis,这两个是什么关系,又有什么区别?
实际上ActiveMQ Classic原来就叫ActiveMQ,是Apache开发的基于JMS 1.1的消息服务器,目前稳定版本号是5.x,而ActiveMQ Artemis是由RedHat捐赠的HornetQ服务器代码的基础上开发的,目前稳定版本号是2.x。和ActiveMQ Classic相比,Artemis版的代码与Classic完全不同,并且,它支持JMS 2.0,使用基于Netty的异步IO,大大提升了性能。此外,Artemis不仅提供了JMS接口,它还提供了AMQP接口,STOMP接口和物联网使用的MQTT接口。选择Artemis,相当于一鱼四吃。
所以,我们这里直接选择ActiveMQ Artemis。从官网下载最新的2.x版本,解压后设置环境变量ARTEMIS_HOME,指向Artemis根目录,例如C:\Apps\artemis,然后,把ARTEMIS_HOME/bin加入PATH环境变量:
- Windows下添加
%ARTEMIS_HOME%\bin到Path路径; - Mac和Linux下添加
$ARTEMIS_HOME/bin到PATH路径。
Artemis有个很好的设计,就是它把程序和数据完全分离了。我们解压后的ARTEMIS_HOME目录是程序目录,要启动一个Artemis服务,还需要创建一个数据目录。我们把数据目录直接设定在项目spring-integration-jms的jms-data目录下。执行命令artemis create jms-data:
1 | $ pwd |
在创建过程中,会要求输入连接用户和口令,这里我们设定admin和password,以及是否允许匿名访问(这里选择N)。
此数据目录jms-data不仅包含消息数据、日志,还自动创建了两个启动服务的命令bin/artemis和bin/artemis-service,前者在前台启动运行,按Ctrl+C结束,后者会一直在后台运行。
我们把目录切换到jms-data/bin,直接运行artemis run即可启动Artemis服务:
1 | $ ./artemis run |
启动成功后,Artemis提示可以通过URLhttp://localhost:8161/console访问管理后台。注意不要关闭命令行窗口。
注意
如果Artemis启动时显示警告:AMQ222212: Disk Full! … Clients will report blocked.这是因为磁盘空间不够,可以在etc/broker.xml配置中找到并改为99。
在编写JMS代码之前,我们首先得理解JMS的消息模型。JMS把生产消息的一方称为Producer,处理消息的一方称为Consumer。有两种类型的消息通道,一种是Queue:
1 | ┌────────┐ ┌────────┐ ┌────────┐ |
一种是Topic:
1 | ┌────────┐ |
它们的区别在于,Queue是一种一对一的通道,如果Consumer离线无法处理消息时,Queue会把消息存起来,等Consumer再次连接的时候发给它。设定了持久化机制的Queue不会丢失消息。如果有多个Consumer接入同一个Queue,那么它们等效于以集群方式处理消息,例如,发送方发送的消息是A,B,C,D,E,F,两个Consumer可能分别收到A,C,E和B,D,F,即每个消息只会交给其中一个Consumer处理。
Topic则是一种一对多通道。一个Producer发出的消息,会被多个Consumer同时收到,即每个Consumer都会收到一份完整的消息流。那么问题来了:如果某个Consumer暂时离线,过一段时间后又上线了,那么在它离线期间产生的消息还能不能收到呢?
这取决于消息服务器对Topic类型消息的持久化机制。如果消息服务器不存储Topic消息,那么离线的Consumer会丢失部分离线时期的消息,如果消息服务器存储了Topic消息,那么离线的Consumer可以收到自上次离线时刻开始后产生的所有消息。JMS规范通过Consumer指定一个持久化订阅可以在上线后收取所有离线期间的消息,如果指定的是非持久化订阅,那么离线期间的消息会全部丢失。
细心的童鞋可以看出来,如果一个Topic的消息全部都持久化了,并且只有一个Consumer,那么它和Queue其实是一样的。实际上,很多消息服务器内部都只有Topic类型的消息架构,Queue可以通过Topic“模拟”出来。
无论是Queue还是Topic,对Producer没有什么要求。多个Producer也可以写入同一个Queue或者Topic,此时消息服务器内部会自动排序确保消息总是有序的。
以上是消息服务的基本模型。具体到某个消息服务器时,Producer和Consumer通常是通过TCP连接消息服务器,在编写JMS程序时,又会遇到ConnectionFactory、Connection、Session等概念,其实这和JDBC连接是类似的:
- ConnectionFactory:代表一个到消息服务器的连接池,类似JDBC的DataSource;
- Connection:代表一个到消息服务器的连接,类似JDBC的Connection;
- Session:代表一个经过认证后的连接会话;
- Message:代表一个消息对象。
在JMS 1.1中,发送消息的典型代码如下:
1 | try { |
JMS 2.0改进了一些API接口,发送消息变得更简单:
1 | try (JMSContext context = connectionFactory.createContext()) { |
JMSContext实现了AutoCloseable接口,可以使用try(resource)语法,代码更简单。
有了以上预备知识,我们就可以开始开发JMS应用了。
首先,我们在pom.xml中添加如下依赖:
- org.springframework:spring-jms:6.0.0
- org.apache.activemq:artemis-jakarta-client:2.27.0
Artemis的Client接口依赖了jakarta.jms:jakarta.jms-api,因此不必再引入JMS API的依赖。
在AppConfig中,通过@EnableJms让Spring自动扫描JMS相关的Bean,并加载JMS配置文件jms.properties:
1 |
|
首先要创建的Bean是ConnectionFactory,即连接消息服务器的连接池:
1 |
|
因为我们使用的消息服务器是ActiveMQ Artemis,所以ConnectionFactory的实现类就是消息服务器提供的ActiveMQJMSConnectionFactory,它需要的参数均由配置文件读取后传入,并设置了默认值。
我们再创建一个JmsTemplate,它是Spring提供的一个工具类,和JdbcTemplate类似,可以简化发送消息的代码:
1 |
|
下一步要创建的是JmsListenerContainerFactory,
1 |
|
除了必须指定Bean的名称为jmsListenerContainerFactory外,这个Bean的作用是处理和Consumer相关的Bean。我们先跳过它的原理,继续编写MessagingService来发送消息:
1 |
|
JMS的消息类型支持以下几种:
- TextMessage:文本消息;
- BytesMessage:二进制消息;
- MapMessage:包含多个Key-Value对的消息;
- ObjectMessage:直接序列化Java对象的消息;
- StreamMessage:一个包含基本类型序列的消息。
最常用的是发送基于JSON的文本消息,上述代码通过JmsTemplate创建一个TextMessage并发送到名称为jms/queue/mail的Queue。
注意:Artemis消息服务器默认配置下会自动创建Queue,因此不必手动创建一个名为jms/queue/mail的Queue,但不是所有的消息服务器都会自动创建Queue,生产环境的消息服务器通常会关闭自动创建功能,需要手动创建Queue。
再注意到MailMessage是我们自己定义的一个JavaBean,真正的JMS消息是创建的TextMessage,它的内容是JSON。
当用户注册成功后,我们就调用MessagingService.sendMailMessage()发送一条JMS消息,此代码十分简单,这里不再贴出。
下面我们要详细讨论的是如何处理消息,即编写Consumer。从理论上讲,可以创建另一个Java进程来处理消息,但对于我们这个简单的Web程序来说没有必要,直接在同一个Web应用中接收并处理消息即可。
处理消息的核心代码是编写一个Bean,并在处理方法上标注@JmsListener:
1 |
|
注意到@JmsListener指定了Queue的名称,因此,凡是发到此Queue的消息都会被这个onMailMessageReceived()方法处理,方法参数是JMS的Message接口,我们通过强制转型为TextMessage并提取JSON,反序列化后获得自定义的JavaBean,也就获得了发送邮件所需的所有信息。
下面问题来了:Spring处理JMS消息的流程是什么?
如果我们直接调用JMS的API来处理消息,那么编写的代码大致如下:
1 | // 创建JMS连接: |
我们自己编写的MailMessageListener.onMailMessageReceived()相当于消息处理器:
1 | consumer.setMessageListener(new MessageListener() { |
所以,Spring根据AppConfig的注解@EnableJms自动扫描带有@JmsListener的Bean方法,并为其创建一个MessageListener把它包装起来。
注意到前面我们还创建了一个JmsListenerContainerFactory的Bean,它的作用就是为每个MessageListener创建MessageConsumer并启动消息接收循环。
再注意到@JmsListener还有一个concurrency参数,10表示可以最多同时并发处理10个消息,5-10表示并发处理的线程可以在5~10之间调整。
因此,Spring在通过MessageListener接收到消息后,并不是直接调用mailMessageListener.onMailMessageReceived(),而是用线程池调用,因此,要时刻牢记,onMailMessageReceived()方法可能被多线程并发执行,一定要保证线程安全。
我们总结一下Spring接收消息的步骤:
通过JmsListenerContainerFactory配合@EnableJms扫描所有@JmsListener方法,自动创建MessageConsumer、MessageListener以及线程池,启动消息循环接收处理消息,最终由我们自己编写的@JmsListener方法处理消息,可能会由多线程同时并发处理。
要验证消息发送和处理,我们注册一个新用户,可以看到如下日志输出:
1 | 2020-06-02 08:04:27 INFO c.i.learnjava.web.UserController - user registered: bob.com |
可见,消息被成功发送到Artemis,然后在很短的时间内被接收处理了。
使用消息服务对发送Email进行改造的好处是,发送Email的能力通常是有限的,通过JMS消息服务,如果短时间内需要给大量用户发送Email,可以先把消息堆积在JMS服务器上慢慢发送,对于批量发送邮件、短信等尤其有用。
练习
使用JMS。
小结
JMS是Java消息服务,可以通过JMS服务器实现消息的异步处理。
消息服务主要解决Producer和Consumer生产和处理速度不匹配的问题。
在很多应用程序中,经常需要执行定时任务。例如,每天或每月给用户发送账户汇总报表,定期检查并发送系统状态报告,等等。
定时任务我们在使用线程池一节中已经讲到了,Java标准库本身就提供了定时执行任务的功能。在Spring中,使用定时任务更简单,不需要手写线程池相关代码,只需要两个注解即可。
我们还是以实际代码为例,建立工程spring-integration-schedule,无需额外的依赖,我们可以直接在AppConfig中加上@EnableScheduling就开启了定时任务的支持:
1 |
|
接下来,我们可以直接在一个Bean中编写一个public void无参数方法,然后加上@Scheduled注解:
1 |
|
上述注解指定了启动延迟60秒,并以60秒的间隔执行任务。现在,我们直接运行应用程序,就可以在控制台看到定时任务打印的日志:
1 | 2020-06-03 18:47:32 INFO [pool-1-thread-1] c.i.learnjava.service.TaskService - Start check system status... |
如果没有看到定时任务的日志,需要检查:
- 是否忘记了在
AppConfig中标注@EnableScheduling; - 是否忘记了在定时任务的方法所在的class标注
@Component。
除了可以使用fixedRate外,还可以使用fixedDelay,两者的区别我们已经在使用线程池一节中讲过,这里不再重复。
有的童鞋在实际开发中会遇到一个问题,因为Java的注解全部是常量,写死了fixedDelay=30000,如果根据实际情况要改成60秒怎么办,只能重新编译?
我们可以把定时任务的配置放到配置文件中,例如task.properties:
1 | task.checkDiskSpace=30000 |
这样就可以随时修改配置文件而无需动代码。但是在代码中,我们需要用fixedDelayString取代fixedDelay:
1 |
|
注意到上述代码的注解参数fixedDelayString是一个属性占位符,并配有默认值30000,Spring在处理@Scheduled注解时,如果遇到String,会根据占位符自动用配置项替换,这样就可以灵活地修改定时任务的配置。
此外,fixedDelayString还可以使用更易读的Duration,例如:
1 |
以字符串PT2M30S表示的Duration就是2分30秒,请参考LocalDateTime一节的Duration相关部分。
多个@Scheduled方法完全可以放到一个Bean中,这样便于统一管理各类定时任务。
使用Cron任务
还有一类定时任务,它不是简单的重复执行,而是按时间触发,我们把这类任务称为Cron任务,例如:
- 每天凌晨2:15执行报表任务;
- 每个工作日12:00执行特定任务;
- ……
Cron源自Unix/Linux系统自带的crond守护进程,以一个简洁的表达式定义任务触发时间。在Spring中,也可以使用Cron表达式来执行Cron任务,在Spring中,它的格式是:
1 | 秒 分 小时 天 月份 星期 年 |
年是可以忽略的,通常不写。每天凌晨2:15执行的Cron表达式就是:
1 | 0 15 2 * * * |
每个工作日12:00执行的Cron表达式就是:
1 | 0 0 12 * * MON-FRI |
每个月1号,2号,3号和10号12:00执行的Cron表达式就是:
1 | 0 0 12 1-3,10 * * |
在Spring中,我们定义一个每天凌晨2:15执行的任务:
1 |
|
Cron任务同样可以使用属性占位符,这样修改起来更加方便。
Cron表达式还可以表达每10分钟执行,例如:
1 | 0 */10 * * * * |
这样,在每个小时的0:00,10:00,20:00,30:00,40:00,50:00均会执行任务,实际上它可以取代fixedRate类型的定时任务。
集成Quartz
在Spring中使用定时任务和Cron任务都十分简单,但是要注意到,这些任务的调度都是在每个JVM进程中的。如果在本机启动两个进程,或者在多台机器上启动应用,这些进程的定时任务和Cron任务都是独立运行的,互不影响。
如果一些定时任务要以集群的方式运行,例如每天23:00执行检查任务,只需要集群中的一台运行即可,这个时候,可以考虑使用Quartz。
Quartz可以配置一个JDBC数据源,以便存储所有的任务调度计划以及任务执行状态。也可以使用内存来调度任务,但这样配置就和使用Spring的调度没啥区别了,额外集成Quartz的意义就不大。
Quartz的JDBC配置比较复杂,Spring对其也有一定的支持。要详细了解Quartz的集成,请参考Spring的文档。
思考:如果不使用Quartz的JDBC配置,多个Spring应用同时运行时,如何保证某个任务只在某一台机器执行?
练习
使用Scheduler执行定时任务。
小结
Spring内置定时任务和Cron任务的支持,编写调度任务十分方便。
在Spring中,可以方便地集成JMX。
那么第一个问题来了:什么是JMX?
JMX是Java Management Extensions,它是一个Java平台的管理和监控接口。为什么要搞JMX呢?因为在所有的应用程序中,对运行中的程序进行监控都是非常重要的,Java应用程序也不例外。我们肯定希望知道Java应用程序当前的状态,例如,占用了多少内存,分配了多少内存,当前有多少活动线程,有多少休眠线程等等。如何获取这些信息呢?
为了标准化管理和监控,Java平台使用JMX作为管理和监控的标准接口,任何程序,只要按JMX规范访问这个接口,就可以获取所有管理与监控信息。
实际上,常用的运维监控如Zabbix、Nagios等工具对JVM本身的监控都是通过JMX获取的信息。
因为JMX是一个标准接口,不但可以用于管理JVM,还可以管理应用程序自身。下图是JMX的架构:
1 | ┌─────────┐ ┌─────────┐ |
JMX把所有被管理的资源都称为MBean(Managed Bean),这些MBean全部由MBeanServer管理,如果要访问MBean,可以通过MBeanServer对外提供的访问接口,例如通过RMI或HTTP访问。
注意到使用JMX不需要安装任何额外组件,也不需要第三方库,因为MBeanServer已经内置在JavaSE标准库中了。JavaSE还提供了一个jconsole程序,用于通过RMI连接到MBeanServer,这样就可以管理整个Java进程。
除了JVM会把自身的各种资源以MBean注册到JMX中,我们自己的配置、监控信息也可以作为MBean注册到JMX,这样,管理程序就可以直接控制我们暴露的MBean。因此,应用程序使用JMX,只需要两步:
- 编写MBean提供管理接口和监控数据;
- 注册MBean。
在Spring应用程序中,使用JMX只需要一步:
- 编写MBean提供管理接口和监控数据。
第二步注册的过程由Spring自动完成。我们以实际工程为例,首先在AppConfig中加上@EnableMBeanExport注解,告诉Spring自动注册MBean:
1 |
|
剩下的全部工作就是编写MBean。我们以实际问题为例,假设我们希望给应用程序添加一个IP黑名单功能,凡是在黑名单中的IP禁止访问,传统的做法是定义一个配置文件,启动的时候读取:
1 | # blacklist.txt |
如果要修改黑名单怎么办?修改配置文件,然后重启应用程序。
但是每次都重启应用程序实在是太麻烦了,能不能不重启应用程序?可以自己写一个定时读取配置文件的功能,检测到文件改动时自动重新读取。
上述需求本质上是在应用程序运行期间对参数、配置等进行热更新并要求尽快生效。如果以JMX的方式实现,我们不必自己编写自动重新读取等任何代码,只需要提供一个符合JMX标准的MBean来存储配置即可。
还是以IP黑名单为例,JMX的MBean通常以MBean结尾,因此我们遵循标准命名规范,首先编写一个BlacklistMBean:
1 | public class BlacklistMBean { |
这个MBean没什么特殊的,它的逻辑和普通Java类没有任何区别。
下一步,我们要使用JMX的客户端来实时热更新这个MBean,所以要给它加上一些注解,让Spring能根据注解自动把相关方法注册到MBeanServer中:
1 |
|
观察上述代码,BlacklistMBean首先是一个标准的Spring管理的Bean,其次,添加了@ManagedResource表示这是一个MBean,将要被注册到JMX。objectName指定了这个MBean的名字,通常以company:name=Xxx来分类MBean。
对于属性,使用@ManagedAttribute注解标注。上述MBean只有get属性,没有set属性,说明这是一个只读属性。
对于操作,使用@ManagedOperation注解标准。上述MBean定义了两个操作:addBlacklist()和removeBlacklist(),其他方法如shouldBlock()不会被暴露给JMX。
使用MBean和普通Bean是完全一样的。例如,我们在BlacklistInterceptor对IP进行黑名单拦截:
1 |
|
下一步就是正常启动Web应用程序,不要关闭它,我们打开另一个命令行窗口,输入jconsole启动JavaSE自带的一个JMX客户端程序:
通过jconsole连接到一个Java进程最简单的方法是直接在Local Process中找到正在运行的AppConfig,点击Connect即可连接到我们当前正在运行的Web应用,在jconsole中可直接看到内存、CPU等资源的监控。
我们点击MBean,左侧按分类列出所有MBean,可以在java.lang查看内存等信息:
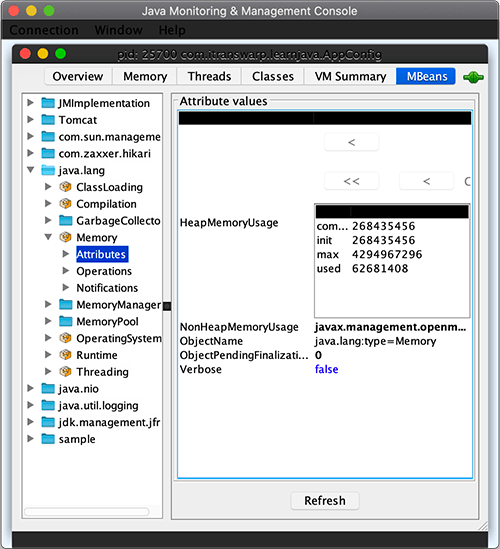
细心的童鞋可以看到HikariCP连接池也是通过JMX监控的。
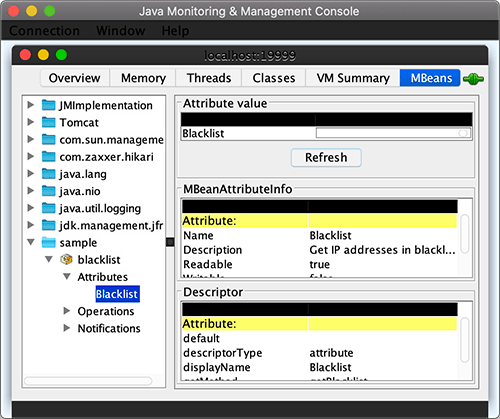
在sample中可以看到我们自己的MBean,点击可查看属性blacklist:
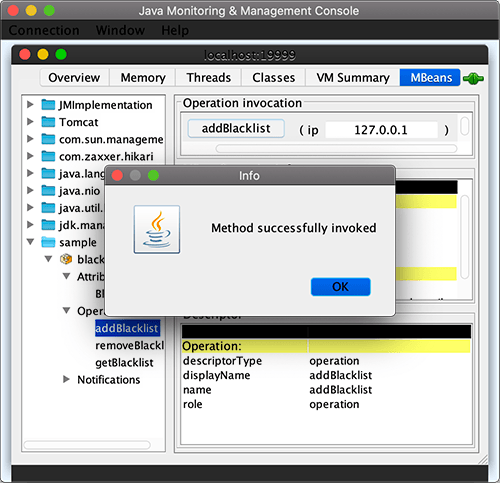
点击Operations-addBlacklist,可以填入127.0.0.1并点击addBlacklist按钮,相当于jconsole通过JMX接口,调用了我们自己的BlacklistMBean的addBlacklist()方法,传入的参数就是填入的127.0.0.1:
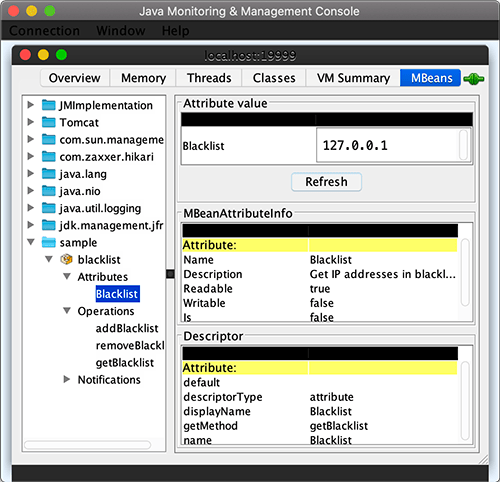
再次查看属性blacklist,可以看到结果已经更新了:
我们可以在浏览器中测试一下黑名单功能是否已生效:
可见,127.0.0.1确实被添加到了黑名单,后台日志打印如下:
1 | 2020-06-06 20:22:12 INFO c.i.l.web.BlacklistInterceptor - check ip address 127.0.0.1... |
注意:如果使用IPv6,那么需要把0:0:0:0:0:0:0:1这个本机地址加到黑名单。
如果从jconsole中调用removeBlacklist移除127.0.0.1,刷新浏览器可以看到又允许访问了。
使用jconsole直接通过Local Process连接JVM有个限制,就是jconsole和正在运行的JVM必须在同一台机器。如果要远程连接,首先要打开JMX端口。我们在启动AppConfig时,需要传入以下JVM启动参数:
- -Dcom.sun.management.jmxremote.port=19999
- -Dcom.sun.management.jmxremote.authenticate=false
- -Dcom.sun.management.jmxremote.ssl=false
第一个参数表示在19999端口监听JMX连接,第二个和第三个参数表示无需验证,不使用SSL连接,在开发测试阶段比较方便,生产环境必须指定验证方式并启用SSL。详细参数可参考Oracle官方文档。这样jconsole可以用ip:19999的远程方式连接JMX。连接后的操作是完全一样的。
许多JavaEE服务器如JBoss的管理后台都是通过JMX提供管理接口,并由Web方式访问,对用户更加友好。
在实际项目中,通过JMX实现配置的实时更新其实并不常用,JMX更多地用于收集JVM的运行状态和应用程序的性能数据,然后通过监控服务器汇总数据后实现监控与报警。一个典型的监控系统架构如下:
1 | ┌───────────────┐ ┌───────────────┐ |
其中,App自身和JVM的的统计数据都通过JMX收集并发送给本机的一个Agent,Agent再将数据发送至监控服务器,最后以可视化的形式将监控数据通过Web等形式展示给用户。常用的监控系统有开源的Prometheus和以云服务方式提供的DataDog等。
练习
编写一个MBean统计当前注册用户数量,并在jconsole中查看:
小结
在Spring中使用JMX需要:
- 通过
@EnableMBeanExport启用自动注册MBean; - 编写MBean并实现管理属性和管理操作。
在Web开发一章中,我们已经详细介绍了JavaEE中Web开发的基础:Servlet。具体地说,有以下几点:
- Servlet规范定义了几种标准组件:Servlet、JSP、Filter和Listener;
- Servlet的标准组件总是运行在Servlet容器中,如Tomcat、Jetty、WebLogic等。
直接使用Servlet进行Web开发好比直接在JDBC上操作数据库,比较繁琐,更好的方法是在Servlet基础上封装MVC框架,基于MVC开发Web应用,大部分时候,不需要接触Servlet API,开发省时省力。
我们在MVC开发和MVC高级开发已经由浅入深地介绍了如何编写MVC框架。当然,自己写的MVC主要是理解原理,要实现一个功能全面的MVC需要大量的工作以及广泛的测试。
因此,开发Web应用,首先要选择一个优秀的MVC框架。常用的MVC框架有:
- Struts:最古老的一个MVC框架,目前版本是2,和1.x有很大的区别;
- WebWork:一个比Struts设计更优秀的MVC框架,但不知道出于什么原因,从2.0开始把自己的代码全部塞给Struts 2了;
- Turbine:一个重度使用Velocity,强调布局的MVC框架;
- 其他100+MVC框架……(略)
Spring虽然都可以集成任何Web框架,但是,Spring本身也开发了一个MVC框架,就叫Spring MVC。这个MVC框架设计得足够优秀以至于我们已经不想再费劲去集成类似Struts这样的框架了。
本章我们会详细介绍如何基于Spring MVC开发Web应用。
我们已经介绍了Java Web的基础:Servlet容器,以及标准的Servlet组件:
- Servlet:能处理HTTP请求并将HTTP响应返回;
- JSP:一种嵌套Java代码的HTML,将被编译为Servlet;
- Filter:能过滤指定的URL以实现拦截功能;
- Listener:监听指定的事件,如ServletContext、HttpSession的创建和销毁。
此外,Servlet容器为每个Web应用程序自动创建一个唯一的ServletContext实例,这个实例就代表了Web应用程序本身。
在MVC高级开发中,我们手撸了一个MVC框架,接口和Spring MVC类似。如果直接使用Spring MVC,我们写出来的代码类似:
1 |
|
但是,Spring提供的是一个IoC容器,所有的Bean,包括Controller,都在Spring IoC容器中被初始化,而Servlet容器由JavaEE服务器提供(如Tomcat),Servlet容器对Spring一无所知,他们之间到底依靠什么进行联系,又是以何种顺序初始化的?
在理解上述问题之前,我们先把基于Spring MVC开发的项目结构搭建起来。首先创建基于Web的Maven工程,引入如下依赖:
- org.springframework:spring-context:6.0.0
- org.springframework:spring-webmvc:6.0.0
- org.springframework:spring-jdbc:6.0.0
- jakarta.annotation:jakarta.annotation-api:2.1.1
- io.pebbletemplates:pebble-spring6:3.2.0
- ch.qos.logback:logback-core:1.4.4
- ch.qos.logback:logback-classic:1.4.4
- com.zaxxer:HikariCP:5.0.1
- org.hsqldb:hsqldb:2.7.0
以及provided依赖:
- org.apache.tomcat.embed:tomcat-embed-core:10.1.1
- org.apache.tomcat.embed:tomcat-embed-jasper:10.1.1
这个标准的Maven Web工程目录结构如下:
1 | spring-web-mvc |
其中,src/main/webapp是标准web目录,WEB-INF存放web.xml,编译的class,第三方jar,以及不允许浏览器直接访问的View模版,static目录存放所有静态文件。
在src/main/resources目录中存放的是Java程序读取的classpath资源文件,除了JDBC的配置文件jdbc.properties外,我们又新增了一个logback.xml,这是Logback的默认查找的配置文件:
1 |
|
上面给出了一个写入到标准输出的Logback配置,可以基于上述配置添加写入到文件的配置。
在src/main/java中就是我们编写的Java代码了。
配置Spring MVC
和普通Spring配置一样,我们编写正常的AppConfig后,只需加上@EnableWebMvc注解,就“激活”了Spring MVC:
1 |
|
除了创建DataSource、JdbcTemplate、PlatformTransactionManager外,AppConfig需要额外创建几个用于Spring MVC的Bean:
1 |
|
WebMvcConfigurer并不是必须的,但我们在这里创建一个默认的WebMvcConfigurer,只覆写addResourceHandlers(),目的是让Spring MVC自动处理静态文件,并且映射路径为/static/**。
另一个必须要创建的Bean是ViewResolver,因为Spring MVC允许集成任何模板引擎,使用哪个模板引擎,就实例化一个对应的ViewResolver:
1 |
|
ViewResolver通过指定prefix和suffix来确定如何查找View。上述配置使用Pebble引擎,指定模板文件存放在/WEB-INF/templates/目录下。
剩下的Bean都是普通的@Component,但Controller必须标记为@Controller,例如:
1 | // Controller使用@Controller标记而不是@Component: |
如果是普通的Java应用程序,我们通过main()方法可以很简单地创建一个Spring容器的实例:
1 | public static void main(String[] args) { |
但是问题来了,现在是Web应用程序,而Web应用程序总是由Servlet容器创建,那么,Spring容器应该由谁创建?在什么时候创建?Spring容器中的Controller又是如何通过Servlet调用的?
在Web应用中启动Spring容器有很多种方法,可以通过Listener启动,也可以通过Servlet启动,可以使用XML配置,也可以使用注解配置。这里,我们只介绍一种最简单的启动Spring容器的方式。
第一步,我们在web.xml中配置Spring MVC提供的DispatcherServlet:
1 |
|
初始化参数contextClass指定使用注解配置的AnnotationConfigWebApplicationContext,配置文件的位置参数contextConfigLocation指向AppConfig的完整类名,最后,把这个Servlet映射到/*,即处理所有URL。
上述配置可以看作一个样板配置,有了这个配置,Servlet容器会首先初始化Spring MVC的DispatcherServlet,在DispatcherServlet启动时,它根据配置AppConfig创建了一个类型是WebApplicationContext的IoC容器,完成所有Bean的初始化,并将容器绑到ServletContext上。
因为DispatcherServlet持有IoC容器,能从IoC容器中获取所有@Controller的Bean,因此,DispatcherServlet接收到所有HTTP请求后,根据Controller方法配置的路径,就可以正确地把请求转发到指定方法,并根据返回的ModelAndView决定如何渲染页面。
最后,我们在AppConfig中通过main()方法启动嵌入式Tomcat:
1 | public static void main(String[] args) throws Exception { |
上述Web应用程序就是我们使用Spring MVC时的一个最小启动功能集。由于使用了JDBC和数据库,用户的注册、登录信息会被持久化:
编写Controller
有了Web应用程序的最基本的结构,我们的重点就可以放在如何编写Controller上。Spring MVC对Controller没有固定的要求,也不需要实现特定的接口。以UserController为例,编写Controller只需要遵循以下要点:
总是标记@Controller而不是@Component:
1 |
|
一个方法对应一个HTTP请求路径,用@GetMapping或@PostMapping表示GET或POST请求:
1 |
|
需要接收的HTTP参数以@RequestParam()标注,可以设置默认值。如果方法参数需要传入HttpServletRequest、HttpServletResponse或者HttpSession,直接添加这个类型的参数即可,Spring MVC会自动按类型传入。
返回的ModelAndView通常包含View的路径和一个Map作为Model,但也可以没有Model,例如:
1 | return new ModelAndView("signin.html"); // 仅View,没有Model |
返回重定向时既可以写new ModelAndView("redirect:/signin"),也可以直接返回String:
1 | public String index() { |
如果在方法内部直接操作HttpServletResponse发送响应,返回null表示无需进一步处理:
1 | public ModelAndView download(HttpServletResponse response) { |
对URL进行分组,每组对应一个Controller是一种很好的组织形式,并可以在Controller的class定义出添加URL前缀,例如:
1 |
|
实际方法的URL映射总是前缀+路径,这种形式还可以有效避免不小心导致的重复的URL映射。
可见,Spring MVC允许我们编写既简单又灵活的Controller实现。
练习
使用Spring MVC,在注册、登录等功能的基础上增加一个修改口令的页面。
小结
使用Spring MVC时,整个Web应用程序按如下顺序启动:
- 启动Tomcat服务器;
- Tomcat读取
web.xml并初始化DispatcherServlet; DispatcherServlet创建IoC容器并自动注册到ServletContext中。
启动后,浏览器发出的HTTP请求全部由DispatcherServlet接收,并根据配置转发到指定Controller的指定方法处理。
使用Spring MVC开发Web应用程序的主要工作就是编写Controller逻辑。在Web应用中,除了需要使用MVC给用户显示页面外,还有一类API接口,我们称之为REST,通常输入输出都是JSON,便于第三方调用或者使用页面JavaScript与之交互。
直接在Controller中处理JSON是可以的,因为Spring MVC的@GetMapping和@PostMapping都支持指定输入和输出的格式。如果我们想接收JSON,输出JSON,那么可以这样写:
1 |
|
对应的Maven工程需要加入Jackson这个依赖:com.fasterxml.jackson.core:jackson-databind:2.14.0
注意到@PostMapping使用consumes声明能接收的类型,使用produces声明输出的类型,并且额外加了@ResponseBody表示返回的String无需额外处理,直接作为输出内容写入HttpServletResponse。输入的JSON则根据注解@RequestBody直接被Spring反序列化为User这个JavaBean。
使用curl命令测试一下:
1 | $ curl -v -H "Content-Type: application/json" -d '{"email":"bob@example.com"}' http://localhost:8080/rest |
输出正是我们写入的字符串。
直接用Spring的Controller配合一大堆注解写REST太麻烦了,因此,Spring还额外提供了一个@RestController注解,使用@RestController替代@Controller后,每个方法自动变成API接口方法。我们还是以实际代码举例,编写ApiController如下:
1 |
|
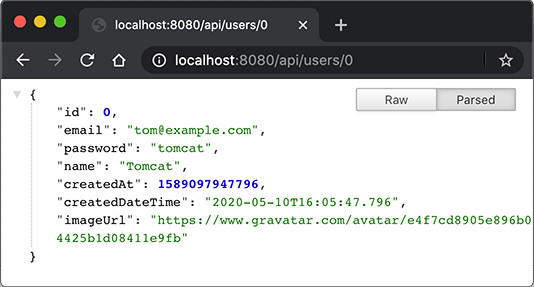
编写REST接口只需要定义@RestController,然后,每个方法都是一个API接口,输入和输出只要能被Jackson序列化或反序列化为JSON就没有问题。我们用浏览器测试GET请求,可直接显示JSON响应:
要测试POST请求,可以用curl命令:
1 | $ curl -v -H "Content-Type: application/json" -d '{"email":"bob@example.com","password":"bob123"}' http://localhost:8080/api/signin |
注意观察上述JSON的输出,User能被正确地序列化为JSON,但暴露了password属性,这是我们不期望的。要避免输出password属性,可以把User复制到另一个UserBean对象,该对象只持有必要的属性,但这样做比较繁琐。另一种简单的方法是直接在User的password属性定义处加上@JsonIgnore表示完全忽略该属性:
1 | public class User { |
但是这样一来,如果写一个register(User user)方法,那么该方法的User对象也拿不到注册时用户传入的密码了。如果要允许输入password,但不允许输出password,即在JSON序列化和反序列化时,允许写属性,禁用读属性,可以更精细地控制如下:
1 | public class User { |
同样的,可以使用@JsonProperty(access = Access.READ_ONLY)允许输出,不允许输入。
练习
使用REST实现API。
小结
使用@RestController可以方便地编写REST服务,Spring默认使用JSON作为输入和输出。
要控制序列化和反序列化,可以使用Jackson提供的@JsonIgnore和@JsonProperty注解。
在Spring MVC中,DispatcherServlet只需要固定配置到web.xml中,剩下的工作主要是专注于编写Controller。
但是,在Servlet规范中,我们还可以使用Filter。如果要在Spring MVC中使用Filter,应该怎么做?
有的童鞋在上一节的Web应用中可能发现了,如果注册时输入中文会导致乱码,因为Servlet默认按非UTF-8编码读取参数。为了修复这一问题,我们可以简单地使用一个EncodingFilter,在全局范围类给HttpServletRequest和HttpServletResponse强制设置为UTF-8编码。
可以自己编写一个EncodingFilter,也可以直接使用Spring MVC自带的一个CharacterEncodingFilter。配置Filter时,只需在web.xml中声明即可:
1 | <web-app> |
因为这种Filter和我们业务关系不大,注意到CharacterEncodingFilter其实和Spring的IoC容器没有任何关系,两者均互不知晓对方的存在,因此,配置这种Filter十分简单。
我们再考虑这样一个问题:如果允许用户使用Basic模式进行用户验证,即在HTTP请求中添加头Authorization: Basic email:password,这个需求如何实现?
编写一个AuthFilter是最简单的实现方式:
1 |
|
现在问题来了:在Spring中创建的这个AuthFilter是一个普通Bean,Servlet容器并不知道,所以它不会起作用。
如果我们直接在web.xml中声明这个AuthFilter,注意到AuthFilter的实例将由Servlet容器而不是Spring容器初始化,因此,@Autowire根本不生效,用于登录的UserService成员变量永远是null。
所以,得通过一种方式,让Servlet容器实例化的Filter,间接引用Spring容器实例化的AuthFilter。Spring MVC提供了一个DelegatingFilterProxy,专门来干这个事情:
1 | <web-app> |
我们来看实现原理:
- Servlet容器从
web.xml中读取配置,实例化DelegatingFilterProxy,注意命名是authFilter; - Spring容器通过扫描
@Component实例化AuthFilter。
当DelegatingFilterProxy生效后,它会自动查找注册在ServletContext上的Spring容器,再试图从容器中查找名为authFilter的Bean,也就是我们用@Component声明的AuthFilter。
DelegatingFilterProxy将请求代理给AuthFilter,核心代码如下:
1 | public class DelegatingFilterProxy implements Filter { |
这就是一个代理模式的简单应用。我们画个图表示它们之间的引用关系如下:
1 | ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ |
如果在web.xml中配置的Filter名字和Spring容器的Bean的名字不一致,那么需要指定Bean的名字:
1 | <filter> |
实际应用时,尽量保持名字一致,以减少不必要的配置。
要使用Basic模式的用户认证,我们可以使用curl命令测试。例如,用户登录名是tom@example.com,口令是tomcat,那么先构造一个使用URL编码的用户名:口令的字符串:
1 | tom%40example.com:tomcat |
对其进行Base64编码,最终构造出的Header如下:
1 | Authorization: Basic dG9tJTQwZXhhbXBsZS5jb206dG9tY2F0 |
使用如下的curl命令并获得响应如下:
1 | $ curl -v -H 'Authorization: Basic dG9tJTQwZXhhbXBsZS5jb206dG9tY2F0' http://localhost:8080/profile |
上述响应说明AuthFilter已生效。
注意
Basic认证模式并不安全,本节只用来作为使用Filter的示例。
练习
使用DelegatingFilterProxy实现AuthFilter。
小结
当一个Filter作为Spring容器管理的Bean存在时,可以通过DelegatingFilterProxy间接地引用它并使其生效。
在Web程序中,注意到使用Filter的时候,Filter由Servlet容器管理,它在Spring MVC的Web应用程序中作用范围如下:
1 | │ ▲ |
上图虚线框就是Filter2的拦截范围,Filter组件实际上并不知道后续内部处理是通过Spring MVC提供的DispatcherServlet还是其他Servlet组件,因为Filter是Servlet规范定义的标准组件,它可以应用在任何基于Servlet的程序中。
如果只基于Spring MVC开发应用程序,还可以使用Spring MVC提供的一种功能类似Filter的拦截器:Interceptor。和Filter相比,Interceptor拦截范围不是后续整个处理流程,而是仅针对Controller拦截:
1 | │ ▲ |
上图虚线框就是Interceptor的拦截范围,注意到Controller的处理方法一般都类似这样:
1 |
|
所以,Interceptor的拦截范围其实就是Controller方法,它实际上就相当于基于AOP的方法拦截。因为Interceptor只拦截Controller方法,所以要注意,返回ModelAndView并渲染后,后续处理就脱离了Interceptor的拦截范围。
使用Interceptor的好处是Interceptor本身是Spring管理的Bean,因此注入任意Bean都非常简单。此外,可以应用多个Interceptor,并通过简单的@Order指定顺序。我们先写一个LoggerInterceptor:
1 |
|
一个Interceptor必须实现HandlerInterceptor接口,可以选择实现preHandle()、postHandle()和afterCompletion()方法。preHandle()是Controller方法调用前执行,postHandle()是Controller方法正常返回后执行,而afterCompletion()无论Controller方法是否抛异常都会执行,参数ex就是Controller方法抛出的异常(未抛出异常是null)。
在preHandle()中,也可以直接处理响应,然后返回false表示无需调用Controller方法继续处理了,通常在认证或者安全检查失败时直接返回错误响应。在postHandle()中,因为捕获了Controller方法返回的ModelAndView,所以可以继续往ModelAndView里添加一些通用数据,很多页面需要的全局数据如Copyright信息等都可以放到这里,无需在每个Controller方法中重复添加。
我们再继续添加一个AuthInterceptor,用于替代上一节使用AuthFilter进行Basic认证的功能:
1 |
|
这个AuthInterceptor是由Spring容器直接管理的,因此注入UserService非常方便。
最后,要让拦截器生效,我们在WebMvcConfigurer中注册所有的Interceptor:
1 |
|
注意
如果拦截器没有生效,请检查是否忘了在WebMvcConfigurer中注册。
处理异常
在Controller中,Spring MVC还允许定义基于@ExceptionHandler注解的异常处理方法。我们来看具体的示例代码:
1 |
|
异常处理方法没有固定的方法签名,可以传入Exception、HttpServletRequest等,返回值可以是void,也可以是ModelAndView,上述代码通过@ExceptionHandler(RuntimeException.class)表示当发生RuntimeException的时候,就自动调用此方法处理。
注意到我们返回了一个新的ModelAndView,这样在应用程序内部如果发生了预料之外的异常,可以给用户显示一个出错页面,而不是简单的500 Internal Server Error或404 Not Found。例如B站的错误页:
可以编写多个错误处理方法,每个方法针对特定的异常。例如,处理LoginException使得页面可以自动跳转到登录页。
使用ExceptionHandler时,要注意它仅作用于当前的Controller,即ControllerA中定义的一个ExceptionHandler方法对ControllerB不起作用。如果我们有很多Controller,每个Controller都需要处理一些通用的异常,例如LoginException,思考一下应该怎么避免重复代码?
练习
使用Interceptor。
小结
Spring MVC提供了Interceptor组件来拦截Controller方法,使用时要注意Interceptor的作用范围。
在开发REST应用时,很多时候,是通过页面的JavaScript和后端的REST API交互。
在JavaScript与REST交互的时候,有很多安全限制。默认情况下,浏览器按同源策略放行JavaScript调用API,即:
- 如果A站在域名
a.com页面的JavaScript调用A站自己的API时,没有问题; - 如果A站在域名
a.com页面的JavaScript调用B站b.com的API时,将被浏览器拒绝访问,因为不满足同源策略。
同源要求域名要完全相同(a.com和www.a.com不同),协议要相同(http和https不同),端口要相同 。
那么,在域名a.com页面的JavaScript要调用B站b.com的API时,还有没有办法?
办法是有的,那就是CORS,全称Cross-Origin Resource Sharing,是HTML5规范定义的如何跨域访问资源。如果A站的JavaScript访问B站API的时候,B站能够返回响应头Access-Control-Allow-Origin: http://a.com,那么,浏览器就允许A站的JavaScript访问B站的API。
注意到跨域访问能否成功,取决于B站是否愿意给A站返回一个正确的Access-Control-Allow-Origin响应头,所以决定权永远在提供API的服务方手中。
关于CORS的详细信息可以参考MDN文档,这里不再详述。
使用Spring的@RestController开发REST应用时,同样会面对跨域问题。如果我们允许指定的网站通过页面JavaScript访问这些REST API,就必须正确地设置CORS。
有好几种方法设置CORS,我们来一一介绍。
使用@CrossOrigin
第一种方法是使用@CrossOrigin注解,可以在@RestController的class级别或方法级别定义一个@CrossOrigin,例如:
1 |
|
上述定义在ApiController处的@CrossOrigin指定了只允许来自local.liaoxuefeng.com跨域访问,允许多个域访问需要写成数组形式,例如origins = {"http://a.com", "https://www.b.com"})。如果要允许任何域访问,写成origins = "*"即可。
如果有多个REST Controller都需要使用CORS,那么,每个Controller都必须标注@CrossOrigin注解。
使用CorsRegistry
第二种方法是在WebMvcConfigurer中定义一个全局CORS配置,下面是一个示例:
1 |
|
这种方式可以创建一个全局CORS配置,如果仔细地设计URL结构,那么可以一目了然地看到各个URL的CORS规则,推荐使用这种方式配置CORS。
使用CorsFilter
第三种方法是使用Spring提供的CorsFilter,我们在集成Filter中详细介绍了将Spring容器内置的Bean暴露为Servlet容器的Filter的方法,由于这种配置方式需要修改web.xml,也比较繁琐,所以推荐使用第二种方式。
测试
当我们配置好CORS后,可以在浏览器中测试一下规则是否生效。
我们先用http://localhost:8080在Chrome浏览器中打开首页,然后打开Chrome的开发者工具,切换到Console,输入一个JavaScript语句来跨域访问API:
1 | $.getJSON("http://local.liaoxuefeng.com:8080/api/users", (data) => console.log(JSON.stringify(data))); |
上述源站的域是http://localhost:8080,跨域访问的是http://local.liaoxuefeng.com:8080,因为配置的CORS不允许localhost访问,所以不出意外地得到一个错误:
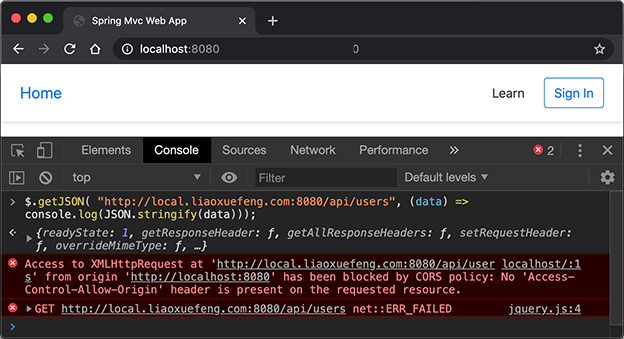
浏览题打印了错误原因就是been blocked by CORS policy。
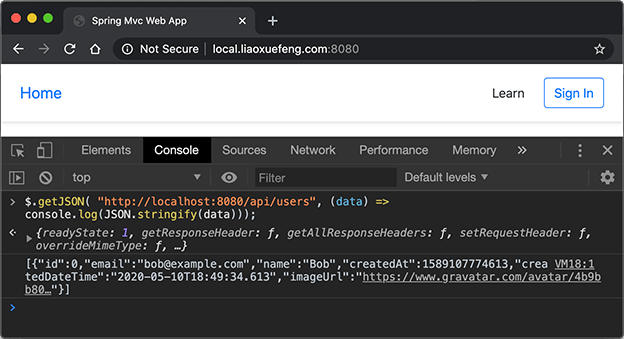
我们再用http://local.liaoxuefeng.com:8080在Chrome浏览器中打开首页,在Console中执行JavaScript访问localhost:
1 | $.getJSON("http://localhost:8080/api/users", (data) => console.log(JSON.stringify(data))); |
因为CORS规则允许来自http://local.liaoxuefeng.com:8080的访问,因此访问成功,打印出API的返回值:
练习
使用CORS控制跨域。
小结
CORS可以控制指定域的页面JavaScript能否访问API。
在开发应用程序的时候,经常会遇到支持多语言的需求,这种支持多语言的功能称之为国际化,英文是internationalization,缩写为i18n(因为首字母i和末字母n中间有18个字母)。
还有针对特定地区的本地化功能,英文是localization,缩写为L10n,本地化是指根据地区调整类似姓名、日期的显示等。
也有把上面两者合称为全球化,英文是globalization,缩写为g11n。
在Java中,支持多语言和本地化是通过MessageFormat配合Locale实现的:
1 | // MessageFormat |
对于Web应用程序,要实现国际化功能,主要是渲染View的时候,要把各种语言的资源文件提出来,这样,不同的用户访问同一个页面时,显示的语言就是不同的。
我们来看看在Spring MVC应用程序中如何实现国际化。
获取Locale
实现国际化的第一步是获取到用户的Locale。在Web应用程序中,HTTP规范规定了浏览器会在请求中携带Accept-Language头,用来指示用户浏览器设定的语言顺序,如:
1 | Accept-Language: zh-CN,zh;q=0.8,en;q=0.2 |
上述HTTP请求头表示优先选择简体中文,其次选择中文,最后选择英文。q表示权重,解析后我们可获得一个根据优先级排序的语言列表,把它转换为Java的Locale,即获得了用户的Locale。大多数框架通常只返回权重最高的Locale。
Spring MVC通过LocaleResolver来自动从HttpServletRequest中获取Locale。有多种LocaleResolver的实现类,其中最常用的是CookieLocaleResolver:
1 |
|
CookieLocaleResolver从HttpServletRequest中获取Locale时,首先根据一个特定的Cookie判断是否指定了Locale,如果没有,就从HTTP头获取,如果还没有,就返回默认的Locale。
当用户第一次访问网站时,CookieLocaleResolver只能从HTTP头获取Locale,即使用浏览器的默认语言。通常网站也允许用户自己选择语言,此时,CookieLocaleResolver就会把用户选择的语言存放到Cookie中,下一次访问时,就会返回用户上次选择的语言而不是浏览器默认语言。
提取资源文件
第二步是把写死在模板中的字符串以资源文件的方式存储在外部。对于多语言,主文件名如果命名为messages,那么资源文件必须按如下方式命名并放入classpath中:
- 默认语言,文件名必须为
messages.properties; - 简体中文,Locale是
zh_CN,文件名必须为messages_zh_CN.properties; - 日文,Locale是
ja_JP,文件名必须为messages_ja_JP.properties; - 其它更多语言……
每个资源文件都有相同的key,例如,默认语言是英文,文件messages.properties内容如下:
1 | language.select=Language |
文件messages_zh_CN.properties内容如下:
1 | language.select=语言 |
创建MessageSource
第三步是创建一个Spring提供的MessageSource实例,它自动读取所有的.properties文件,并提供一个统一接口来实现“翻译”:
1 | // code, arguments, locale: |
其中,signin是我们在.properties文件中定义的key,第二个参数是Object[]数组作为格式化时传入的参数,最后一个参数就是获取的用户Locale实例。
创建MessageSource如下:
1 |
|
注意到ResourceBundleMessageSource会自动根据主文件名自动把所有相关语言的资源文件都读进来。
再注意到Spring容器会创建不只一个MessageSource实例,我们自己创建的这个MessageSource是专门给页面国际化使用的,因此命名为i18n,不会与其它MessageSource实例冲突。
实现多语言
要在View中使用MessageSource加上Locale输出多语言,我们通过编写一个MvcInterceptor,把相关资源注入到ModelAndView中:
1 |
|
不要忘了在WebMvcConfigurer中注册MvcInterceptor。现在,就可以在View中调用MessageSource.getMessage()方法来实现多语言:
1 | <a href="/signin">{{ __messageSource__.getMessage('signin', null, __locale__) }}</a> |
上述这种写法虽然可行,但格式太复杂了。使用View时,要根据每个特定的View引擎定制国际化函数。在Pebble中,我们可以封装一个国际化函数,名称就是下划线_,改造一下创建ViewResolver的代码:
1 |
|
这样,我们可以把多语言页面改写为:
1 | <a href="/signin">{{ _('signin') }}</a> |
如果是带参数的多语言,需要把参数传进去:
1 | <h5>{{ _('copyright', 2020) }}</h5> |
使用其它View引擎时,也应当根据引擎接口实现更方便的语法。
切换Locale
最后,我们需要允许用户手动切换Locale,编写一个LocaleController来实现该功能:
1 |
|
在页面设计中,通常在右上角给用户提供一个语言选择列表,来看看效果:
切换到中文:
练习
在Spring MVC程序中实现国际化。
小结
多语言支持需要从HTTP请求中解析用户的Locale,然后针对不同Locale显示不同的语言;
Spring MVC应用程序通过MessageSource和LocaleResolver,配合View实现国际化。
在Servlet模型中,每个请求都是由某个线程处理,然后,将响应写入IO流,发送给客户端。从开始处理请求,到写入响应完成,都是在同一个线程中处理的。
实现Servlet容器的时候,只要每处理一个请求,就创建一个新线程处理它,就能保证正确实现了Servlet线程模型。在实际产品中,例如Tomcat,总是通过线程池来处理请求,它仍然符合一个请求从头到尾都由某一个线程处理。
这种线程模型非常重要,因为Spring的JDBC事务是基于ThreadLocal实现的,如果在处理过程中,一会由线程A处理,一会又由线程B处理,那事务就全乱套了。此外,很多安全认证,也是基于ThreadLocal实现的,可以保证在处理请求的过程中,各个线程互不影响。
但是,如果一个请求处理的时间较长,例如几秒钟甚至更长,那么,这种基于线程池的同步模型很快就会把所有线程耗尽,导致服务器无法响应新的请求。如果把长时间处理的请求改为异步处理,那么线程池的利用率就会大大提高。Servlet从3.0规范开始添加了异步支持,允许对一个请求进行异步处理。
我们先来看看在Spring MVC中如何实现对请求进行异步处理的逻辑。首先建立一个Web工程,然后编辑web.xml文件如下:
1 | <web-app> |
和前面普通的MVC程序相比,这个web.xml主要对DispatcherServlet的配置多了一个<async-supported>,默认值是false,必须明确写成true,这样Servlet容器才会支持async处理。
下一步就是在Controller中编写async处理逻辑。我们以ApiController为例,演示如何异步处理请求。
第一种async处理方式是返回一个Callable,Spring MVC自动把返回的Callable放入线程池执行,等待结果返回后再写入响应:
1 |
|
第二种async处理方式是返回一个DeferredResult对象,然后在另一个线程中,设置此对象的值并写入响应:
1 |
|
使用DeferredResult时,可以设置超时,超时会自动返回超时错误响应。在另一个线程中,可以调用setResult()写入结果,也可以调用setErrorResult()写入一个错误结果。
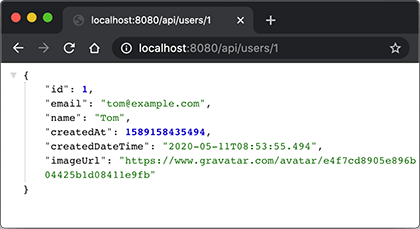
运行程序,当我们访问http://localhost:8080/api/users/1时,假定用户存在,则浏览器在1秒后返回结果:
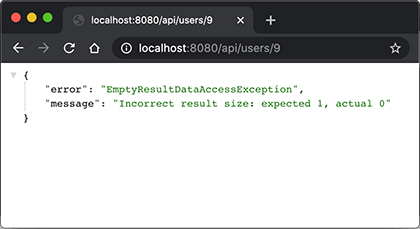
访问一个不存在的User ID,则等待1秒后返回错误结果:
使用Filter
当我们使用async模式处理请求时,原有的Filter也可以工作,但我们必须在web.xml中添加<async-supported>并设置为true。我们用两个Filter:SyncFilter和AsyncFilter分别测试:
1 | <web-app ...> |
一个声明为支持<async-supported>的Filter既可以过滤async处理请求,也可以过滤正常的同步处理请求,而未声明<async-supported>的Filter无法支持async请求,如果一个普通的Filter遇到async请求时,会直接报错,因此,务必注意普通Filter的<url-pattern>不要匹配async请求路径。
在logback.xml配置文件中,我们把输出格式加上[%thread],可以输出当前线程的名称:
1 |
|
对于同步请求,例如/api/version,我们可以看到如下输出:
1 | 2020-05-16 11:22:40 [http-nio-8080-exec-1] INFO c.i.learnjava.web.SyncFilter - start SyncFilter... |
可见,每个Filter和ApiController都是由同一个线程执行。
对于异步请求,例如/api/users,我们可以看到如下输出:
1 | 2020-05-16 11:23:49 [http-nio-8080-exec-4] INFO c.i.learnjava.web.AsyncFilter - start AsyncFilter... |
可见,AsyncFilter和ApiController是由同一个线程执行的,但是,返回响应的是另一个线程。
对DeferredResult测试,可以看到如下输出:
1 | 2020-05-16 11:25:24 [http-nio-8080-exec-8] INFO c.i.learnjava.web.AsyncFilter - start AsyncFilter... |
同样,返回响应的是另一个线程。
在实际使用时,经常用到的就是DeferredResult,因为返回DeferredResult时,可以设置超时、正常结果和错误结果,易于编写比较灵活的逻辑。
使用async异步处理响应时,要时刻牢记,在另一个异步线程中的事务和Controller方法中执行的事务不是同一个事务,在Controller中绑定的ThreadLocal信息也无法在异步线程中获取。
此外,Servlet 3.0规范添加的异步支持是针对同步模型打了一个“补丁”,虽然可以异步处理请求,但高并发异步请求时,它的处理效率并不高,因为这种异步模型并没有用到真正的“原生”异步。Java标准库提供了封装操作系统的异步IO包java.nio,是真正的多路复用IO模型,可以用少量线程支持大量并发。使用NIO编程复杂度比同步IO高很多,因此我们很少直接使用NIO。相反,大部分需要高性能异步IO的应用程序会选择Netty这样的框架,它基于NIO提供了更易于使用的API,方便开发异步应用程序。
练习
使用Spring MVC实现异步处理请求。
小结
在Spring MVC中异步处理请求需要正确配置web.xml,并返回Callable或DeferredResult对象。
WebSocket是一种基于HTTP的长链接技术。传统的HTTP协议是一种请求-响应模型,如果浏览器不发送请求,那么服务器无法主动给浏览器推送数据。如果需要定期给浏览器推送数据,例如股票行情,或者不定期给浏览器推送数据,例如在线聊天,基于HTTP协议实现这类需求,只能依靠浏览器的JavaScript定时轮询,效率很低且实时性不高。
因为HTTP本身是基于TCP连接的,所以,WebSocket在HTTP协议的基础上做了一个简单的升级,即建立TCP连接后,浏览器发送请求时,附带几个头:
1 | GET /chat HTTP/1.1 |
就表示客户端希望升级连接,变成长连接的WebSocket,服务器返回升级成功的响应:
1 | HTTP/1.1 101 Switching Protocols |
收到成功响应后表示WebSocket“握手”成功,这样,代表WebSocket的这个TCP连接将不会被服务器关闭,而是一直保持,服务器可随时向浏览器推送消息,浏览器也可随时向服务器推送消息。双方推送的消息既可以是文本消息,也可以是二进制消息,一般来说,绝大部分应用程序会推送基于JSON的文本消息。
现代浏览器都已经支持WebSocket协议,服务器则需要底层框架支持。Java的Servlet规范从3.1开始支持WebSocket,所以,必须选择支持Servlet 3.1或更高规范的Servlet容器,才能支持WebSocket。最新版本的Tomcat、Jetty等开源服务器均支持WebSocket。
我们以实际代码演示如何在Spring MVC中实现对WebSocket的支持。首先,我们需要在pom.xml中加入以下依赖:
- org.apache.tomcat.embed:tomcat-embed-websocket:10.1.1
- org.springframework:spring-websocket:6.0.0
第一项是嵌入式Tomcat支持WebSocket的组件,第二项是Spring封装的支持WebSocket的接口。
接下来,我们需要在AppConfig中加入Spring Web对WebSocket的配置,先增加一个@EnableWebSocket注解,然后创建一个WebSocketConfigurer实例:
1 |
|
此实例在内部通过WebSocketHandlerRegistry注册能处理WebSocket的WebSocketHandler,以及可选的WebSocket拦截器HandshakeInterceptor。我们注入的这两个类都是自己编写的业务逻辑,后面我们详细讨论如何编写它们,这里只需关注浏览器连接到WebSocket的URL是/chat。
处理WebSocket连接
和处理普通HTTP请求不同,没法用一个方法处理一个URL。Spring提供了TextWebSocketHandler和BinaryWebSocketHandler分别处理文本消息和二进制消息,这里我们选择文本消息作为聊天室的协议,因此,ChatHandler需要继承自TextWebSocketHandler:
1 |
|
当浏览器请求一个WebSocket连接后,如果成功建立连接,Spring会自动调用afterConnectionEstablished()方法,任何原因导致WebSocket连接中断时,Spring会自动调用afterConnectionClosed方法,因此,覆写这两个方法即可处理连接成功和结束后的业务逻辑:
1 |
|
每个WebSocket会话以WebSocketSession表示,且已分配唯一ID。和WebSocket相关的数据,例如用户名称等,均可放入关联的getAttributes()中。
用实例变量clients持有当前所有的WebSocketSession是为了广播,即向所有用户推送同一消息时,可以这么写:
1 | String json = ... |
我们发送的消息是序列化后的JSON,可以用ChatMessage表示:
1 | public class ChatMessage { |
每收到一个用户的消息后,我们就需要广播给所有用户:
1 |
|
如果要推送给指定的几个用户,那就需要在clients中根据条件查找出某些WebSocketSession,然后发送消息。
注意到我们在注册WebSocket时还传入了一个ChatHandshakeInterceptor,这个类实际上可以从HttpSessionHandshakeInterceptor继承,它的主要作用是在WebSocket建立连接后,把HttpSession的一些属性复制到WebSocketSession,例如,用户的登录信息等:
1 |
|
这样,在ChatHandler中,可以从WebSocketSession.getAttributes()中获取到复制过来的属性。
客户端开发
在完成了服务器端的开发后,我们还需要在页面编写一点JavaScript逻辑:
1 | // 创建WebSocket连接: |
用户可以在连接成功后任何时候给服务器发送消息:
1 | var inputText = 'Hello, WebSocket.'; |
最后,连调浏览器和服务器端,如果一切无误,可以开多个不同的浏览器测试WebSocket的推送和广播。
和上一节我们介绍的异步处理类似,Servlet的线程模型并不适合大规模的长链接。基于NIO的Netty等框架更适合处理WebSocket长链接,我们将在后面介绍。
练习
使用WebSocket编写一个聊天室。
小结
在Servlet中使用WebSocket需要3.1及以上版本;
通过spring-websocket可以简化WebSocket的开发。
数据库基本上是现代应用程序的标准存储,绝大多数程序都把自己的业务数据存储在关系数据库中,可见,访问数据库几乎是所有应用程序必备能力。
我们在前面已经介绍了Java程序访问数据库的标准接口JDBC,它的实现方式非常简洁,即:Java标准库定义接口,各数据库厂商以“驱动”的形式实现接口。应用程序要使用哪个数据库,就把该数据库厂商的驱动以jar包形式引入进来,同时自身仅使用JDBC接口,编译期并不需要特定厂商的驱动。
使用JDBC虽然简单,但代码比较繁琐。Spring为了简化数据库访问,主要做了以下几点工作:
- 提供了简化的访问JDBC的模板类,不必手动释放资源;
- 提供了一个统一的DAO类以实现Data Access Object模式;
- 把
SQLException封装为DataAccessException,这个异常是一个RuntimeException,并且让我们能区分SQL异常的原因,例如,DuplicateKeyException表示违反了一个唯一约束; - 能方便地集成Hibernate、JPA和MyBatis这些数据库访问框架。
本章我们将详细讲解在Spring中访问数据库的最佳实践。
我们在前面介绍JDBC编程时已经讲过,Java程序使用JDBC接口访问关系数据库的时候,需要以下几步:
- 创建全局
DataSource实例,表示数据库连接池; - 在需要读写数据库的方法内部,按如下步骤访问数据库:
- 从全局
DataSource实例获取Connection实例; - 通过
Connection实例创建PreparedStatement实例; - 执行SQL语句,如果是查询,则通过
ResultSet读取结果集,如果是修改,则获得int结果。
- 从全局
正确编写JDBC代码的关键是使用try ... finally释放资源,涉及到事务的代码需要正确提交或回滚事务。
在Spring使用JDBC,首先我们通过IoC容器创建并管理一个DataSource实例,然后,Spring提供了一个JdbcTemplate,可以方便地让我们操作JDBC,因此,通常情况下,我们会实例化一个JdbcTemplate。顾名思义,这个类主要使用了Template模式。
编写示例代码或者测试代码时,我们强烈推荐使用HSQLDB这个数据库,它是一个用Java编写的关系数据库,可以以内存模式或者文件模式运行,本身只有一个jar包,非常适合演示代码或者测试代码。
我们以实际工程为例,先创建Maven工程spring-data-jdbc,然后引入以下依赖:
- org.springframework:spring-context:6.0.0
- org.springframework:spring-jdbc:6.0.0
- jakarta.annotation:jakarta.annotation-api:2.1.1
- com.zaxxer:HikariCP:5.0.1
- org.hsqldb:hsqldb:2.7.1
在AppConfig中,我们需要创建以下几个必须的Bean:
1 |
|
在上述配置中:
- 通过
@PropertySource("jdbc.properties")读取数据库配置文件; - 通过
@Value("${jdbc.url}")注入配置文件的相关配置; - 创建一个DataSource实例,它的实际类型是
HikariDataSource,创建时需要用到注入的配置; - 创建一个JdbcTemplate实例,它需要注入
DataSource,这是通过方法参数完成注入的。
最后,针对HSQLDB写一个配置文件jdbc.properties:
1 | # 数据库文件名为testdb: |
可以通过HSQLDB自带的工具来初始化数据库表,这里我们写一个Bean,在Spring容器启动时自动创建一个users表:
1 |
|
现在,所有准备工作都已完毕。我们只需要在需要访问数据库的Bean中,注入JdbcTemplate即可:
1 |
|
JdbcTemplate用法
Spring提供的JdbcTemplate采用Template模式,提供了一系列以回调为特点的工具方法,目的是避免繁琐的try...catch语句。
我们以具体的示例来说明JdbcTemplate的用法。
首先我们看T execute(ConnectionCallback<T> action)方法,它提供了Jdbc的Connection供我们使用:
1 | public User getUserById(long id) { |
也就是说,上述回调方法允许获取Connection,然后做任何基于Connection的操作。
我们再看T execute(String sql, PreparedStatementCallback<T> action)的用法:
1 | public User getUserByName(String name) { |
最后,我们看T queryForObject(String sql, RowMapper<T> rowMapper, Object... args)方法:
1 | public User getUserByEmail(String email) { |
在queryForObject()方法中,传入SQL以及SQL参数后,JdbcTemplate会自动创建PreparedStatement,自动执行查询并返回ResultSet,我们提供的RowMapper需要做的事情就是把ResultSet的当前行映射成一个JavaBean并返回。整个过程中,使用Connection、PreparedStatement和ResultSet都不需要我们手动管理。
RowMapper不一定返回JavaBean,实际上它可以返回任何Java对象。例如,使用SELECT COUNT(*)查询时,可以返回Long:
1 | public long getUsers() { |
如果我们期望返回多行记录,而不是一行,可以用query()方法:
1 | public List<User> getUsers(int pageIndex) { |
上述query()方法传入的参数仍然是SQL、SQL参数以及RowMapper实例。这里我们直接使用Spring提供的BeanPropertyRowMapper。如果数据库表的结构恰好和JavaBean的属性名称一致,那么BeanPropertyRowMapper就可以直接把一行记录按列名转换为JavaBean。
如果我们执行的不是查询,而是插入、更新和删除操作,那么需要使用update()方法:
1 | public void updateUser(User user) { |
只有一种INSERT操作比较特殊,那就是如果某一列是自增列(例如自增主键),通常,我们需要获取插入后的自增值。JdbcTemplate提供了一个KeyHolder来简化这一操作:
1 | public User register(String email, String password, String name) { |
JdbcTemplate还有许多重载方法,这里我们不一一介绍。需要强调的是,JdbcTemplate只是对JDBC操作的一个简单封装,它的目的是尽量减少手动编写try(resource) {...}的代码,对于查询,主要通过RowMapper实现了JDBC结果集到Java对象的转换。
我们总结一下JdbcTemplate的用法,那就是:
- 针对简单查询,优选
query()和queryForObject(),因为只需提供SQL语句、参数和RowMapper; - 针对更新操作,优选
update(),因为只需提供SQL语句和参数; - 任何复杂的操作,最终也可以通过
execute(ConnectionCallback)实现,因为拿到Connection就可以做任何JDBC操作。
实际上我们使用最多的仍然是各种查询。如果在设计表结构的时候,能够和JavaBean的属性一一对应,那么直接使用BeanPropertyRowMapper就很方便。如果表结构和JavaBean不一致怎么办?那就需要稍微改写一下查询,使结果集的结构和JavaBean保持一致。
例如,表的列名是office_address,而JavaBean属性是workAddress,就需要指定别名,改写查询如下:
1 | SELECT id, email, office_address AS workAddress, name FROM users WHERE email = ? |
练习
使用JdbcTemplate。
小结
Spring提供了JdbcTemplate来简化JDBC操作;
使用JdbcTemplate时,根据需要优先选择高级方法;
任何JDBC操作都可以使用保底的execute(ConnectionCallback)方法。
使用Spring操作JDBC虽然方便,但是我们在前面讨论JDBC的时候,讲到过JDBC事务,如果要在Spring中操作事务,没必要手写JDBC事务,可以使用Spring提供的高级接口来操作事务。
Spring提供了一个PlatformTransactionManager来表示事务管理器,所有的事务都由它负责管理。而事务由TransactionStatus表示。如果手写事务代码,使用try...catch如下:
1 | TransactionStatus tx = null; |
Spring为啥要抽象出PlatformTransactionManager和TransactionStatus?原因是JavaEE除了提供JDBC事务外,它还支持分布式事务JTA(Java Transaction API)。分布式事务是指多个数据源(比如多个数据库,多个消息系统)要在分布式环境下实现事务的时候,应该怎么实现。分布式事务实现起来非常复杂,简单地说就是通过一个分布式事务管理器实现两阶段提交,但本身数据库事务就不快,基于数据库事务实现的分布式事务就慢得难以忍受,所以使用率不高。
Spring为了同时支持JDBC和JTA两种事务模型,就抽象出PlatformTransactionManager。因为我们的代码只需要JDBC事务,因此,在AppConfig中,需要再定义一个PlatformTransactionManager对应的Bean,它的实际类型是DataSourceTransactionManager:
1 |
|
使用编程的方式使用Spring事务仍然比较繁琐,更好的方式是通过声明式事务来实现。使用声明式事务非常简单,除了在AppConfig中追加一个上述定义的PlatformTransactionManager外,再加一个@EnableTransactionManagement就可以启用声明式事务:
1 |
|
然后,对需要事务支持的方法,加一个@Transactional注解:
1 |
|
或者更简单一点,直接在Bean的class处加上,表示所有public方法都具有事务支持:
1 |
|
Spring对一个声明式事务的方法,如何开启事务支持?原理仍然是AOP代理,即通过自动创建Bean的Proxy实现:
1 | public class UserService$$EnhancerBySpringCGLIB extends UserService { |
注意:声明了@EnableTransactionManagement后,不必额外添加@EnableAspectJAutoProxy。
回滚事务
默认情况下,如果发生了RuntimeException,Spring的声明式事务将自动回滚。在一个事务方法中,如果程序判断需要回滚事务,只需抛出RuntimeException,例如:
1 |
|
如果要针对Checked Exception回滚事务,需要在@Transactional注解中写出来:
1 |
|
上述代码表示在抛出RuntimeException或IOException时,事务将回滚。
为了简化代码,我们强烈建议业务异常体系从RuntimeException派生,这样就不必声明任何特殊异常即可让Spring的声明式事务正常工作:
1 | public class BusinessException extends RuntimeException { |
事务边界
在使用事务的时候,明确事务边界非常重要。对于声明式事务,例如,下面的register()方法:
1 |
|
它的事务边界就是register()方法开始和结束。
类似的,一个负责给用户增加积分的addBonus()方法:
1 |
|
它的事务边界就是addBonus()方法开始和结束。
在现实世界中,问题总是要复杂一点点。用户注册后,能自动获得100积分,因此,实际代码如下:
1 |
|
现在问题来了:调用方(比如RegisterController)调用UserService.register()这个事务方法,它在内部又调用了BonusService.addBonus()这个事务方法,一共有几个事务?如果addBonus()抛出了异常需要回滚事务,register()方法的事务是否也要回滚?
问题的复杂度是不是一下子提高了10倍?
事务传播
要解决上面的问题,我们首先要定义事务的传播模型。
假设用户注册的入口是RegisterController,它本身没有事务,仅仅是调用UserService.register()这个事务方法:
1 |
|
因此,UserService.register()这个事务方法的起始和结束,就是事务的范围。
我们需要关心的问题是,在UserService.register()这个事务方法内,调用BonusService.addBonus(),我们期待的事务行为是什么:
1 |
|
对于大多数业务来说,我们期待BonusService.addBonus()的调用,和UserService.register()应当融合在一起,它的行为应该如下:
UserService.register()已经开启了一个事务,那么在内部调用BonusService.addBonus()时,BonusService.addBonus()方法就没必要再开启一个新事务,直接加入到BonusService.register()的事务里就好了。
其实就相当于:
UserService.register()先执行了一条INSERT语句:INSERT INTO users ...BonusService.addBonus()再执行一条INSERT语句:INSERT INTO bonus ...
因此,Spring的声明式事务为事务传播定义了几个级别,默认传播级别就是REQUIRED,它的意思是,如果当前没有事务,就创建一个新事务,如果当前有事务,就加入到当前事务中执行。
我们观察UserService.register()方法,它在RegisterController中执行,因为RegisterController没有事务,因此,UserService.register()方法会自动创建一个新事务。
在UserService.register()方法内部,调用BonusService.addBonus()方法时,因为BonusService.addBonus()检测到当前已经有事务了,因此,它会加入到当前事务中执行。
因此,整个业务流程的事务边界就清晰了:它只有一个事务,并且范围就是UserService.register()方法。
有的童鞋会问:把BonusService.addBonus()方法的@Transactional去掉,变成一个普通方法,那不就规避了复杂的传播模型吗?
去掉BonusService.addBonus()方法的@Transactional,会引来另一个问题,即其他地方如果调用BonusService.addBonus()方法,那就没法保证事务了。例如,规定用户登录时积分+5:
1 |
|
可见,BonusService.addBonus()方法必须要有@Transactional,否则,登录后积分就无法添加了。
默认的事务传播级别是REQUIRED,它满足绝大部分的需求。还有一些其他的传播级别:
SUPPORTS:表示如果有事务,就加入到当前事务,如果没有,那也不开启事务执行。这种传播级别可用于查询方法,因为SELECT语句既可以在事务内执行,也可以不需要事务;
MANDATORY:表示必须要存在当前事务并加入执行,否则将抛出异常。这种传播级别可用于核心更新逻辑,比如用户余额变更,它总是被其他事务方法调用,不能直接由非事务方法调用;
REQUIRES_NEW:表示不管当前有没有事务,都必须开启一个新的事务执行。如果当前已经有事务,那么当前事务会挂起,等新事务完成后,再恢复执行;
NOT_SUPPORTED:表示不支持事务,如果当前有事务,那么当前事务会挂起,等这个方法执行完成后,再恢复执行;
NEVER:和NOT_SUPPORTED相比,它不但不支持事务,而且在监测到当前有事务时,会抛出异常拒绝执行;
NESTED:表示如果当前有事务,则开启一个嵌套级别事务,如果当前没有事务,则开启一个新事务。
上面这么多种事务的传播级别,其实默认的REQUIRED已经满足绝大部分需求,SUPPORTS和REQUIRES_NEW在少数情况下会用到,其他基本不会用到,因为把事务搞得越复杂,不仅逻辑跟着复杂,而且速度也会越慢。
定义事务的传播级别也是写在@Transactional注解里的:
1 |
|
现在只剩最后一个问题了:Spring是如何传播事务的?
我们在JDBC中使用事务的时候,是这么个写法:
1 | Connection conn = openConnection(); |
Spring使用声明式事务,最终也是通过执行JDBC事务来实现功能的,那么,一个事务方法,如何获知当前是否存在事务?
答案是使用ThreadLocal。Spring总是把JDBC相关的Connection和TransactionStatus实例绑定到ThreadLocal。如果一个事务方法从ThreadLocal未取到事务,那么它会打开一个新的JDBC连接,同时开启一个新的事务,否则,它就直接使用从ThreadLocal获取的JDBC连接以及TransactionStatus。
因此,事务能正确传播的前提是,方法调用是在一个线程内才行。如果像下面这样写:
1 |
|
在另一个线程中调用BonusService.addBonus(),它根本获取不到当前事务,因此,UserService.register()和BonusService.addBonus()两个方法,将分别开启两个完全独立的事务。
换句话说,事务只能在当前线程传播,无法跨线程传播。
那如果我们想实现跨线程传播事务呢?原理很简单,就是要想办法把当前线程绑定到ThreadLocal的Connection和TransactionStatus实例传递给新线程,但实现起来非常复杂,根据异常回滚更加复杂,不推荐自己去实现。
练习
使用声明式事务。
小结
Spring提供的声明式事务极大地方便了在数据库中使用事务,正确使用声明式事务的关键在于确定好事务边界,理解事务传播级别。
在传统的多层应用程序中,通常是Web层调用业务层,业务层调用数据访问层。业务层负责处理各种业务逻辑,而数据访问层只负责对数据进行增删改查。因此,实现数据访问层就是用JdbcTemplate实现对数据库的操作。
编写数据访问层的时候,可以使用DAO模式。DAO即Data Access Object的缩写,它没有什么神秘之处,实现起来基本如下:
1 | public class UserDao { |
Spring提供了一个JdbcDaoSupport类,用于简化DAO的实现。这个JdbcDaoSupport没什么复杂的,核心代码就是持有一个JdbcTemplate:
1 | public abstract class JdbcDaoSupport extends DaoSupport { |
它的意图是子类直接从JdbcDaoSupport继承后,可以随时调用getJdbcTemplate()获得JdbcTemplate的实例。那么问题来了:因为JdbcDaoSupport的jdbcTemplate字段没有标记@Autowired,所以,子类想要注入JdbcTemplate,还得自己想个办法:
1 |
|
有的童鞋可能看出来了:既然UserDao都已经注入了JdbcTemplate,那再把它放到父类里,通过getJdbcTemplate()访问岂不是多此一举?
如果使用传统的XML配置,并不需要编写@Autowired JdbcTemplate jdbcTemplate,但是考虑到现在基本上是使用注解的方式,我们可以编写一个AbstractDao,专门负责注入JdbcTemplate:
1 | public abstract class AbstractDao extends JdbcDaoSupport { |
这样,子类的代码就非常干净,可以直接调用getJdbcTemplate():
1 |
|
倘若肯再多写一点样板代码,就可以把AbstractDao改成泛型,并实现getById(),getAll(),deleteById()这样的通用方法:
1 | public abstract class AbstractDao<T> extends JdbcDaoSupport { |
这样,每个子类就自动获得了这些通用方法:
1 |
|
可见,DAO模式就是一个简单的数据访问模式,是否使用DAO,根据实际情况决定,因为很多时候,直接在Service层操作数据库也是完全没有问题的。
练习
使用DAO模式访问数据库。
小结
Spring提供了JdbcDaoSupport来便于我们实现DAO模式;
可以基于泛型实现更通用、更简洁的DAO模式。
使用JdbcTemplate的时候,我们用得最多的方法就是List<T> query(String, RowMapper, Object...)。这个RowMapper的作用就是把ResultSet的一行记录映射为Java Bean。
这种把关系数据库的表记录映射为Java对象的过程就是ORM:Object-Relational Mapping。ORM既可以把记录转换成Java对象,也可以把Java对象转换为行记录。
使用JdbcTemplate配合RowMapper可以看作是最原始的ORM。如果要实现更自动化的ORM,可以选择成熟的ORM框架,例如Hibernate。
我们来看看如何在Spring中集成Hibernate。
Hibernate作为ORM框架,它可以替代JdbcTemplate,但Hibernate仍然需要JDBC驱动,所以,我们需要引入JDBC驱动、连接池,以及Hibernate本身。在Maven中,我们加入以下依赖项:
- org.springframework:spring-context:6.0.0
- org.springframework:spring-orm:6.0.0
- jakarta.annotation:jakarta.annotation-api:2.1.1
- jakarta.persistence:jakarta.persistence-api:3.1.0
- org.hibernate:hibernate-core:6.1.4.Final
- com.zaxxer:HikariCP:5.0.1
- org.hsqldb:hsqldb:2.7.1
在AppConfig中,我们仍然需要创建DataSource、引入JDBC配置文件,以及启用声明式事务:
1 |
|
为了启用Hibernate,我们需要创建一个LocalSessionFactoryBean:
1 | public class AppConfig { |
注意我们在定制Bean中讲到过FactoryBean,LocalSessionFactoryBean是一个FactoryBean,它会再自动创建一个SessionFactory,在Hibernate中,Session是封装了一个JDBC Connection的实例,而SessionFactory是封装了JDBC DataSource的实例,即SessionFactory持有连接池,每次需要操作数据库的时候,SessionFactory创建一个新的Session,相当于从连接池获取到一个新的Connection。SessionFactory就是Hibernate提供的最核心的一个对象,但LocalSessionFactoryBean是Spring提供的为了让我们方便创建SessionFactory的类。
注意到上面创建LocalSessionFactoryBean的代码,首先用Properties持有Hibernate初始化SessionFactory时用到的所有设置,常用的设置请参考Hibernate文档,这里我们只定义了3个设置:
hibernate.hbm2ddl.auto=update:表示自动创建数据库的表结构,注意不要在生产环境中启用;hibernate.dialect=org.hibernate.dialect.HSQLDialect:指示Hibernate使用的数据库是HSQLDB。Hibernate使用一种HQL的查询语句,它和SQL类似,但真正在“翻译”成SQL时,会根据设定的数据库“方言”来生成针对数据库优化的SQL;hibernate.show_sql=true:让Hibernate打印执行的SQL,这对于调试非常有用,我们可以方便地看到Hibernate生成的SQL语句是否符合我们的预期。
除了设置DataSource和Properties之外,注意到setPackagesToScan()我们传入了一个package名称,它指示Hibernate扫描这个包下面的所有Java类,自动找出能映射为数据库表记录的JavaBean。后面我们会仔细讨论如何编写符合Hibernate要求的JavaBean。
紧接着,我们还需要创建HibernateTransactionManager:
1 | public class AppConfig { |
HibernateTransactionManager是配合Hibernate使用声明式事务所必须的。到此为止,所有的配置都定义完毕,我们来看看如何将数据库表结构映射为Java对象。
考察如下的数据库表:
1 | CREATE TABLE user |
其中,id是自增主键,email、password、name是VARCHAR类型,email带唯一索引以确保唯一性,createdAt存储整型类型的时间戳。用JavaBean表示如下:
1 | public class User { |
这种映射关系十分易懂,但我们需要添加一些注解来告诉Hibernate如何把User类映射到表记录:
1 |
|
如果一个JavaBean被用于映射,我们就标记一个@Entity。默认情况下,映射的表名是user,如果实际的表名不同,例如实际表名是users,可以追加一个@Table(name="users")表示:
1 |
|
每个属性到数据库列的映射用@Column()标识,nullable指示列是否允许为NULL,updatable指示该列是否允许被用在UPDATE语句,length指示String类型的列的长度(如果没有指定,默认是255)。
对于主键,还需要用@Id标识,自增主键再追加一个@GeneratedValue,以便Hibernate能读取到自增主键的值。
细心的童鞋可能还注意到,主键id定义的类型不是long,而是Long。这是因为Hibernate如果检测到主键为null,就不会在INSERT语句中指定主键的值,而是返回由数据库生成的自增值,否则,Hibernate认为我们的程序指定了主键的值,会在INSERT语句中直接列出。long型字段总是具有默认值0,因此,每次插入的主键值总是0,导致除第一次外后续插入都将失败。
createdAt虽然是整型,但我们并没有使用long,而是Long,这是因为使用基本类型会导致findByExample查询会添加意外的条件,这里只需牢记,作为映射使用的JavaBean,所有属性都使用包装类型而不是基本类型。
注意
使用Hibernate时,不要使用基本类型的属性,总是使用包装类型,如Long或Integer。
类似的,我们再定义一个Book类:
1 |
|
如果仔细观察User和Book,会发现它们定义的id、createdAt属性是一样的,这在数据库表结构的设计中很常见:对于每个表,通常我们会统一使用一种主键生成机制,并添加createdAt表示创建时间,updatedAt表示修改时间等通用字段。
不必在User和Book中重复定义这些通用字段,我们可以把它们提到一个抽象类中:
1 |
|
对于AbstractEntity来说,我们要标注一个@MappedSuperclass表示它用于继承。此外,注意到我们定义了一个@Transient方法,它返回一个“虚拟”的属性。因为getCreatedDateTime()是计算得出的属性,而不是从数据库表读出的值,因此必须要标注@Transient,否则Hibernate会尝试从数据库读取名为createdDateTime这个不存在的字段从而出错。
再注意到@PrePersist标识的方法,它表示在我们将一个JavaBean持久化到数据库之前(即执行INSERT语句),Hibernate会先执行该方法,这样我们就可以自动设置好createdAt属性。
有了AbstractEntity,我们就可以大幅简化User和Book:
1 |
|
注意到使用的所有注解均来自jakarta.persistence,它是JPA规范的一部分。这里我们只介绍使用注解的方式配置Hibernate映射关系,不再介绍传统的比较繁琐的XML配置。通过Spring集成Hibernate时,也不再需要hibernate.cfg.xml配置文件,用一句话总结:
提示
使用Spring集成Hibernate,配合JPA注解,无需任何额外的XML配置。
类似User、Book这样的用于ORM的Java Bean,我们通常称之为Entity Bean。
最后,我们来看看如果对user表进行增删改查。因为使用了Hibernate,因此,我们要做的,实际上是对User这个JavaBean进行“增删改查”。我们编写一个UserService,注入SessionFactory:
1 |
|
Insert操作
要持久化一个User实例,我们只需调用persist()方法。以register()方法为例,代码如下:
1 | public User register(String email, String password, String name) { |
Delete操作
删除一个User相当于从表中删除对应的记录。注意Hibernate总是用id来删除记录,因此,要正确设置User的id属性才能正常删除记录:
1 | public boolean deleteUser(Long id) { |
通过主键删除记录时,一个常见的用法是先根据主键加载该记录,再删除。注意到当记录不存在时,load()返回null。
Update操作
更新记录相当于先更新User的指定属性,然后调用merge()方法:
1 | public void updateUser(Long id, String name) { |
前面我们在定义User时,对有的属性标注了@Column(updatable=false)。Hibernate在更新记录时,它只会把@Column(updatable=true)的属性加入到UPDATE语句中,这样可以提供一层额外的安全性,即如果不小心修改了User的email、createdAt等属性,执行update()时并不会更新对应的数据库列。但也必须牢记:这个功能是Hibernate提供的,如果绕过Hibernate直接通过JDBC执行UPDATE语句仍然可以更新数据库的任意列的值。
最后,我们编写的大部分方法都是各种各样的查询。根据id查询我们可以直接调用load(),如果要使用条件查询,例如,假设我们想执行以下查询:
1 | SELECT * FROM user WHERE email = ? AND password = ? |
我们来看看可以使用什么查询。
使用HQL查询
一种常用的查询是直接编写Hibernate内置的HQL查询:
1 | List<User> list = sessionFactory.getCurrentSession() |
和SQL相比,HQL使用类名和属性名,由Hibernate自动转换为实际的表名和列名。详细的HQL语法可以参考Hibernate文档。
除了可以直接传入HQL字符串外,Hibernate还可以使用一种NamedQuery,它给查询起个名字,然后保存在注解中。使用NamedQuery时,我们要先在User类标注:
1 |
|
注意到引入的NamedQuery是jakarta.persistence.NamedQuery,它和直接传入HQL有点不同的是,占位符使用:e和:pwd。
使用NamedQuery只需要引入查询名和参数:
1 | public User login(String email, String password) { |
直接写HQL和使用NamedQuery各有优劣。前者可以在代码中直观地看到查询语句,后者可以在User类统一管理所有相关查询。
练习
集成Hibernate操作数据库。
小结
在Spring中集成Hibernate需要配置的Bean如下:
- DataSource;
- LocalSessionFactory;
- HibernateTransactionManager。
推荐使用Annotation配置所有的Entity Bean。
上一节我们讲了在Spring中集成Hibernate。Hibernate是第一个被广泛使用的ORM框架,但是很多小伙伴还听说过JPA:Java Persistence API,这又是啥?
在讨论JPA之前,我们要注意到JavaEE早在1999年就发布了,并且有Servlet、JMS等诸多标准。和其他平台不同,Java世界早期非常热衷于标准先行,各家跟进:大家先坐下来把接口定了,然后,各自回家干活去实现接口,这样,用户就可以在不同的厂家提供的产品进行选择,还可以随意切换,因为用户编写代码的时候只需要引用接口,并不需要引用具体的底层实现(想想JDBC)。
JPA就是JavaEE的一个ORM标准,它的实现其实和Hibernate没啥本质区别,但是用户如果使用JPA,那么引用的就是jakarta.persistence这个“标准”包,而不是org.hibernate这样的第三方包。因为JPA只是接口,所以,还需要选择一个实现产品,跟JDBC接口和MySQL驱动一个道理。
我们使用JPA时也完全可以选择Hibernate作为底层实现,但也可以选择其它的JPA提供方,比如EclipseLink。Spring内置了JPA的集成,并支持选择Hibernate或EclipseLink作为实现。这里我们仍然以主流的Hibernate作为JPA实现为例子,演示JPA的基本用法。
和使用Hibernate一样,我们只需要引入如下依赖:
- org.springframework:spring-context:6.0.0
- org.springframework:spring-orm:6.0.0
- jakarta.annotation:jakarta.annotation-api:2.1.1
- jakarta.persistence:jakarta.persistence-api:3.1.0
- org.hibernate:hibernate-core:6.1.4.Final
- com.zaxxer:HikariCP:5.0.1
- org.hsqldb:hsqldb:2.7.1
实际上我们这里引入的依赖和上一节集成Hibernate引入的依赖完全一样,因为Hibernate既提供了它自己的接口,也提供了JPA接口,我们用JPA接口就相当于通过JPA操作Hibernate。
然后,在AppConfig中启用声明式事务管理,创建DataSource:
1 |
|
使用Hibernate时,我们需要创建一个LocalSessionFactoryBean,并让它再自动创建一个SessionFactory。使用JPA也是类似的,我们也创建一个LocalContainerEntityManagerFactoryBean,并让它再自动创建一个EntityManagerFactory:
1 |
|
观察上述代码,除了需要注入DataSource和设定自动扫描的package外,还需要指定JPA的提供商,这里使用Spring提供的一个HibernateJpaVendorAdapter,最后,针对Hibernate自己需要的配置,以Properties的形式注入。
最后,我们还需要实例化一个JpaTransactionManager,以实现声明式事务:
1 |
|
这样,我们就完成了JPA的全部初始化工作。有些童鞋可能从网上搜索得知JPA需要persistence.xml配置文件,以及复杂的orm.xml文件。这里我们负责地告诉大家,使用Spring+Hibernate作为JPA实现,无需任何配置文件。
所有Entity Bean的配置和上一节完全相同,全部采用Annotation标注。我们现在只需关心具体的业务类如何通过JPA接口操作数据库。
还是以UserService为例,除了标注@Component和@Transactional外,我们需要注入一个EntityManager,但是不要使用Autowired,而是@PersistenceContext:
1 |
|
我们回顾一下JDBC、Hibernate和JPA提供的接口,实际上,它们的关系如下:
| JDBC | Hibernate | JPA |
|---|---|---|
| DataSource | SessionFactory | EntityManagerFactory |
| Connection | Session | EntityManager |
SessionFactory和EntityManagerFactory相当于DataSource,Session和EntityManager相当于Connection。每次需要访问数据库的时候,需要获取新的Session和EntityManager,用完后再关闭。
但是,注意到UserService注入的不是EntityManagerFactory,而是EntityManager,并且标注了@PersistenceContext。难道使用JPA可以允许多线程操作同一个EntityManager?
实际上这里注入的并不是真正的EntityManager,而是一个EntityManager的代理类,相当于:
1 | public class EntityManagerProxy implements EntityManager { |
Spring遇到标注了@PersistenceContext的EntityManager会自动注入代理,该代理会在必要的时候自动打开EntityManager。换句话说,多线程引用的EntityManager虽然是同一个代理类,但该代理类内部针对不同线程会创建不同的EntityManager实例。
简单总结一下,标注了@PersistenceContext的EntityManager可以被多线程安全地共享。
因此,在UserService的每个业务方法里,直接使用EntityManager就很方便。以主键查询为例:
1 | public User getUserById(long id) { |
与HQL查询类似,JPA使用JPQL查询,它的语法和HQL基本差不多:
1 | public User fetchUserByEmail(String email) { |
同样的,JPA也支持NamedQuery,即先给查询起个名字,再按名字创建查询:
1 | public User login(String email, String password) { |
NamedQuery通过注解标注在User类上,它的定义和上一节的User类一样:
1 |
|
对数据库进行增删改的操作,可以分别使用persist()、remove()和merge()方法,参数均为Entity Bean本身,使用非常简单,这里不再多述。
练习
使用JPA操作数据库。
小结
在Spring中集成JPA要选择一个实现,可以选择Hibernate或EclipseLink;
使用JPA与Hibernate类似,但注入的核心资源是带有@PersistenceContext注解的EntityManager代理类。
使用Hibernate或JPA操作数据库时,这类ORM干的主要工作就是把ResultSet的每一行变成Java Bean,或者把Java Bean自动转换到INSERT或UPDATE语句的参数中,从而实现ORM。
而ORM框架之所以知道如何把行数据映射到Java Bean,是因为我们在Java Bean的属性上给了足够的注解作为元数据,ORM框架获取Java Bean的注解后,就知道如何进行双向映射。
那么,ORM框架是如何跟踪Java Bean的修改,以便在update()操作中更新必要的属性?
答案是使用Proxy模式,从ORM框架读取的User实例实际上并不是User类,而是代理类,代理类继承自User类,但针对每个setter方法做了覆写:
1 | public class UserProxy extends User { |
这样,代理类可以跟踪到每个属性的变化。
针对一对多或多对一关系时,代理类可以直接通过getter方法查询数据库:
1 | public class UserProxy extends User { |
为了实现这样的查询,UserProxy必须保存Hibernate的当前Session。但是,当事务提交后,Session自动关闭,此时再获取getAddress()将无法访问数据库,或者获取的不是事务一致的数据。因此,ORM框架总是引入了Attached/Detached状态,表示当前此Java Bean到底是在Session的范围内,还是脱离了Session变成了一个“游离”对象。很多初学者无法正确理解状态变化和事务边界,就会造成大量的PersistentObjectException异常。这种隐式状态使得普通Java Bean的生命周期变得复杂。
此外,Hibernate和JPA为了实现兼容多种数据库,它使用HQL或JPQL查询,经过一道转换,变成特定数据库的SQL,理论上这样可以做到无缝切换数据库,但这一层自动转换除了少许的性能开销外,给SQL级别的优化带来了麻烦。
最后,ORM框架通常提供了缓存,并且还分为一级缓存和二级缓存。一级缓存是指在一个Session范围内的缓存,常见的情景是根据主键查询时,两次查询可以返回同一实例:
1 | User user1 = session.load(User.class, 123); |
二级缓存是指跨Session的缓存,一般默认关闭,需要手动配置。二级缓存极大的增加了数据的不一致性,原因在于SQL非常灵活,常常会导致意外的更新。例如:
1 | // 线程1读取: |
当二级缓存生效的时候,两个线程读取的User实例是一样的,但是,数据库对应的行记录完全可能被修改,例如:
1 | -- 给老用户增加100积分: |
ORM无法判断id=123的用户是否受该UPDATE语句影响。考虑到数据库通常会支持多个应用程序,此UPDATE语句可能由其他进程执行,ORM框架就更不知道了。
我们把这种ORM框架称之为全自动ORM框架。
对比Spring提供的JdbcTemplate,它和ORM框架相比,主要有几点差别:
- 查询后需要手动提供Mapper实例以便把ResultSet的每一行变为Java对象;
- 增删改操作所需的参数列表,需要手动传入,即把User实例变为[user.id, user.name, user.email]这样的列表,比较麻烦。
但是JdbcTemplate的优势在于它的确定性:即每次读取操作一定是数据库操作而不是缓存,所执行的SQL是完全确定的,缺点就是代码比较繁琐,构造INSERT INTO users VALUES (?,?,?)更是复杂。
所以,介于全自动ORM如Hibernate和手写全部如JdbcTemplate之间,还有一种半自动的ORM,它只负责把ResultSet自动映射到Java Bean,或者自动填充Java Bean参数,但仍需自己写出SQL。MyBatis就是这样一种半自动化ORM框架。
我们来看看如何在Spring中集成MyBatis。
首先,我们要引入MyBatis本身,其次,由于Spring并没有像Hibernate那样内置对MyBatis的集成,所以,我们需要再引入MyBatis官方自己开发的一个与Spring集成的库:
- org.mybatis:mybatis:3.5.11
- org.mybatis:mybatis-spring:3.0.0
和前面一样,先创建DataSource是必不可少的:
1 |
|
再回顾一下Hibernate和JPA的SessionFactory与EntityManagerFactory,MyBatis与之对应的是SqlSessionFactory和SqlSession:
| JDBC | Hibernate | JPA | MyBatis |
|---|---|---|---|
| DataSource | SessionFactory | EntityManagerFactory | SqlSessionFactory |
| Connection | Session | EntityManager | SqlSession |
可见,ORM的设计套路都是类似的。使用MyBatis的核心就是创建SqlSessionFactory,这里我们需要创建的是SqlSessionFactoryBean:
1 |
|
因为MyBatis可以直接使用Spring管理的声明式事务,因此,创建事务管理器和使用JDBC是一样的:
1 |
|
和Hibernate不同的是,MyBatis使用Mapper来实现映射,而且Mapper必须是接口。我们以User类为例,在User类和users表之间映射的UserMapper编写如下:
1 | public interface UserMapper { |
注意:这里的Mapper不是JdbcTemplate的RowMapper的概念,它是定义访问users表的接口方法。比如我们定义了一个User getById(long)的主键查询方法,不仅要定义接口方法本身,还要明确写出查询的SQL,这里用注解@Select标记。SQL语句的任何参数,都与方法参数按名称对应。例如,方法参数id的名字通过注解@Param()标记为id,则SQL语句里将来替换的占位符就是#{id}。
如果有多个参数,那么每个参数命名后直接在SQL中写出对应的占位符即可:
1 |
|
注意:MyBatis执行查询后,将根据方法的返回类型自动把ResultSet的每一行转换为User实例,转换规则当然是按列名和属性名对应。如果列名和属性名不同,最简单的方式是编写SELECT语句的别名:
1 | -- 列名是created_time,属性名是createdAt: |
执行INSERT语句就稍微麻烦点,因为我们希望传入User实例,因此,定义的方法接口与@Insert注解如下:
1 |
|
上述方法传入的参数名称是user,参数类型是User类,在SQL中引用的时候,以#{obj.property}的方式写占位符。和Hibernate这样的全自动化ORM相比,MyBatis必须写出完整的INSERT语句。
如果users表的id是自增主键,那么,我们在SQL中不传入id,但希望获取插入后的主键,需要再加一个@Options注解:
1 |
|
keyProperty和keyColumn分别指出JavaBean的属性和数据库的主键列名。
执行UPDATE和DELETE语句相对比较简单,我们定义方法如下:
1 |
|
有了UserMapper接口,还需要对应的实现类才能真正执行这些数据库操作的方法。虽然可以自己写实现类,但我们除了编写UserMapper接口外,还有BookMapper、BonusMapper……一个一个写太麻烦,因此,MyBatis提供了一个MapperFactoryBean来自动创建所有Mapper的实现类。可以用一个简单的注解来启用它:
1 |
|
有了@MapperScan,就可以让MyBatis自动扫描指定包的所有Mapper并创建实现类。在真正的业务逻辑中,我们可以直接注入:
1 |
|
可见,业务逻辑主要就是通过XxxMapper定义的数据库方法来访问数据库。
XML配置
上述在Spring中集成MyBatis的方式,我们只需要用到注解,并没有任何XML配置文件。MyBatis也允许使用XML配置映射关系和SQL语句,例如,更新User时根据属性值构造动态SQL:
1 | <update id="updateUser"> |
编写XML配置的优点是可以组装出动态SQL,并且把所有SQL操作集中在一起。缺点是配置起来太繁琐,调用方法时如果想查看SQL还需要定位到XML配置中。这里我们不介绍XML的配置方式,需要了解的童鞋请自行阅读官方文档。
使用MyBatis最大的问题是所有SQL都需要全部手写,优点是执行的SQL就是我们自己写的SQL,对SQL进行优化非常简单,也可以编写任意复杂的SQL,或者使用数据库的特定语法,但切换数据库可能就不太容易。好消息是大部分项目并没有切换数据库的需求,完全可以针对某个数据库编写尽可能优化的SQL。
练习
集成MyBatis操作数据库。
小结
MyBatis是一个半自动化的ORM框架,需要手写SQL语句,没有自动加载一对多或多对一关系的功能。
我们从前几节可以看到,所谓ORM,也是建立在JDBC的基础上,通过ResultSet到JavaBean的映射,实现各种查询。有自动跟踪Entity修改的全自动化ORM如Hibernate和JPA,需要为每个Entity创建代理,也有完全自己映射,连INSERT和UPDATE语句都需要手动编写的MyBatis,但没有任何透明的Proxy。
而查询是涉及到数据库使用最广泛的操作,需要最大的灵活性。各种ORM解决方案各不相同,Hibernate和JPA自己实现了HQL和JPQL查询语法,用以生成最终的SQL,而MyBatis则完全手写,每增加一个查询都需要先编写SQL并增加接口方法。
还有一种Hibernate和JPA支持的Criteria查询,用Hibernate写出来类似:
1 | DetachedCriteria criteria = DetachedCriteria.forClass(User.class); |
上述Criteria查询写法复杂,但和JPA相比,还是小巫见大巫了:
1 | var cb = em.getCriteriaBuilder(); |
此外,是否支持自动读取一对多和多对一关系也是全自动化ORM框架的一个重要功能。
如果我们自己来设计并实现一个ORM,应该吸取这些ORM的哪些特色,然后高效实现呢?
设计ORM接口
任何设计,都必须明确设计目标。这里我们准备实现的ORM并不想要全自动ORM那种自动读取一对多和多对一关系的功能,也不想给Entity加上复杂的状态,因此,对于Entity来说,它就是纯粹的JavaBean,没有任何Proxy。
此外,ORM要兼顾易用性和适用性。易用性是指能覆盖95%的应用场景,但总有一些复杂的SQL,很难用ORM去自动生成,因此,也要给出原生的JDBC接口,能支持5%的特殊需求。
最后,我们希望设计的接口要易于编写,并使用流式API便于阅读。为了配合编译器检查,还应该支持泛型,避免强制转型。
以User类为例,我们设计的查询接口如下:
1 | // 按主键查询: SELECT * FROM users WHERE id = ? |
这样的流式API便于阅读,也非常容易推导出最终生成的SQL。
对于插入、更新和删除操作,就相对比较简单:
1 | // 插入User: |
对于Entity来说,通常一个表对应一个。手动列出所有Entity是非常麻烦的,一定要传入package自动扫描。
最后,ORM总是需要元数据才能知道如何映射。我们不想编写复杂的XML配置,也没必要自己去定义一套规则,直接使用JPA的注解就行。
实现ORM
我们并不需要从JDBC底层开始编写,并且,还要考虑到事务,最好能直接使用Spring的声明式事务。实际上,我们可以设计一个全局DbTemplate,它注入了Spring的JdbcTemplate,涉及到数据库操作时,全部通过JdbcTemplate完成,自然天生支持Spring的声明式事务,因为这个ORM只是在JdbcTemplate的基础上做了一层封装。
在AppConfig中,我们初始化所有Bean如下:
1 |
|
以上就是我们所需的所有配置。
编写业务逻辑,例如UserService,写出来像这样:
1 |
|
上述代码给出了ORM的接口,以及如何在业务逻辑中使用ORM。下一步,就是如何实现这个DbTemplate。这里我们只给出框架代码,有兴趣的童鞋可以自己实现核心代码:
1 | public class DbTemplate { |
实现链式API的核心代码是第一步从DbTemplate调用select()或from()时实例化一个CriteriaQuery实例,并在后续的链式调用中设置它的字段:
1 | public class DbTemplate { |
然后以此定义Select、From、Where、OrderBy、Limit等。在From中可以设置Class类型、表名等:
1 | public final class From<T> extends CriteriaQuery<T> { |
在Where中可以设置条件参数:
1 | public final class Where<T> extends CriteriaQuery<T> { |
最后,链式调用的尽头是调用list()返回一组结果,调用unique()返回唯一结果,调用first()返回首个结果。
在IDE中,可以非常方便地实现链式调用:
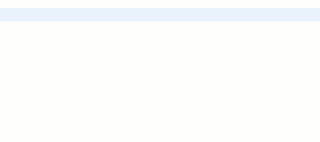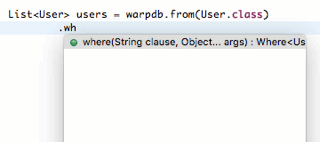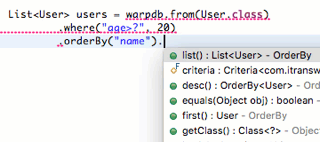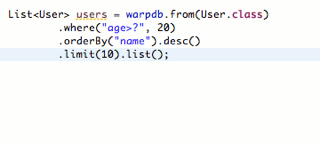
需要复杂查询的时候,总是可以使用JdbcTemplate执行任意复杂的SQL。
练习
设计并实现一个微型ORM。
小结
ORM框架就是自动映射数据库表结构到JavaBean的工具,设计并实现一个简单高效的ORM框架并不困难。
AOP是Aspect Oriented Programming,即面向切面编程。
那什么是AOP?
我们先回顾一下OOP:Object Oriented Programming,OOP作为面向对象编程的模式,获得了巨大的成功,OOP的主要功能是数据封装、继承和多态。
而AOP是一种新的编程方式,它和OOP不同,OOP把系统看作多个对象的交互,AOP把系统分解为不同的关注点,或者称之为切面(Aspect)。
要理解AOP的概念,我们先用OOP举例,比如一个业务组件BookService,它有几个业务方法:
- createBook:添加新的Book;
- updateBook:修改Book;
- deleteBook:删除Book。
对每个业务方法,例如,createBook(),除了业务逻辑,还需要安全检查、日志记录和事务处理,它的代码像这样:
1 | public class BookService { |
继续编写updateBook(),代码如下:
1 | public class BookService { |
对于安全检查、日志、事务等代码,它们会重复出现在每个业务方法中。使用OOP,我们很难将这些四处分散的代码模块化。
考察业务模型可以发现,BookService关心的是自身的核心逻辑,但整个系统还要求关注安全检查、日志、事务等功能,这些功能实际上“横跨”多个业务方法,为了实现这些功能,不得不在每个业务方法上重复编写代码。
一种可行的方式是使用Proxy模式,将某个功能,例如,权限检查,放入Proxy中:
1 | public class SecurityCheckBookService implements BookService { |
这种方式的缺点是比较麻烦,必须先抽取接口,然后,针对每个方法实现Proxy。
另一种方法是,既然SecurityCheckBookService的代码都是标准的Proxy样板代码,不如把权限检查视作一种切面(Aspect),把日志、事务也视为切面,然后,以某种自动化的方式,把切面织入到核心逻辑中,实现Proxy模式。
如果我们以AOP的视角来编写上述业务,可以依次实现:
- 核心逻辑,即BookService;
- 切面逻辑,即:
- 权限检查的Aspect;
- 日志的Aspect;
- 事务的Aspect。
然后,以某种方式,让框架来把上述3个Aspect以Proxy的方式“织入”到BookService中,这样一来,就不必编写复杂而冗长的Proxy模式。
AOP原理
如何把切面织入到核心逻辑中?这正是AOP需要解决的问题。换句话说,如果客户端获得了BookService的引用,当调用bookService.createBook()时,如何对调用方法进行拦截,并在拦截前后进行安全检查、日志、事务等处理,就相当于完成了所有业务功能。
在Java平台上,对于AOP的织入,有3种方式:
- 编译期:在编译时,由编译器把切面调用编译进字节码,这种方式需要定义新的关键字并扩展编译器,AspectJ就扩展了Java编译器,使用关键字aspect来实现织入;
- 类加载器:在目标类被装载到JVM时,通过一个特殊的类加载器,对目标类的字节码重新“增强”;
- 运行期:目标对象和切面都是普通Java类,通过JVM的动态代理功能或者第三方库实现运行期动态织入。
最简单的方式是第三种,Spring的AOP实现就是基于JVM的动态代理。由于JVM的动态代理要求必须实现接口,如果一个普通类没有业务接口,就需要通过CGLIB或者Javassist这些第三方库实现。
AOP技术看上去比较神秘,但实际上,它本质就是一个动态代理,让我们把一些常用功能如权限检查、日志、事务等,从每个业务方法中剥离出来。
需要特别指出的是,AOP对于解决特定问题,例如事务管理非常有用,这是因为分散在各处的事务代码几乎是完全相同的,并且它们需要的参数(JDBC的Connection)也是固定的。另一些特定问题,如日志,就不那么容易实现,因为日志虽然简单,但打印日志的时候,经常需要捕获局部变量,如果使用AOP实现日志,我们只能输出固定格式的日志,因此,使用AOP时,必须适合特定的场景。
在AOP编程中,我们经常会遇到下面的概念:
- Aspect:切面,即一个横跨多个核心逻辑的功能,或者称之为系统关注点;
- Joinpoint:连接点,即定义在应用程序流程的何处插入切面的执行;
- Pointcut:切入点,即一组连接点的集合;
- Advice:增强,指特定连接点上执行的动作;
- Introduction:引介,指为一个已有的Java对象动态地增加新的接口;
- Weaving:织入,指将切面整合到程序的执行流程中;
- Interceptor:拦截器,是一种实现增强的方式;
- Target Object:目标对象,即真正执行业务的核心逻辑对象;
- AOP Proxy:AOP代理,是客户端持有的增强后的对象引用。
看完上述术语,是不是感觉对AOP有了进一步的困惑?其实,我们不用关心AOP创造的“术语”,只需要理解AOP本质上只是一种代理模式的实现方式,在Spring的容器中实现AOP特别方便。
我们以UserService和MailService为例,这两个属于核心业务逻辑,现在,我们准备给UserService的每个业务方法执行前添加日志,给MailService的每个业务方法执行前后添加日志,在Spring中,需要以下步骤:
首先,我们通过Maven引入Spring对AOP的支持:
- org.springframework:spring-aspects:6.0.0
上述依赖会自动引入AspectJ,使用AspectJ实现AOP比较方便,因为它的定义比较简单。
然后,我们定义一个LoggingAspect:
1 |
|
观察doAccessCheck()方法,我们定义了一个@Before注解,后面的字符串是告诉AspectJ应该在何处执行该方法,这里写的意思是:执行UserService的每个public方法前执行doAccessCheck()代码。
再观察doLogging()方法,我们定义了一个@Around注解,它和@Before不同,@Around可以决定是否执行目标方法,因此,我们在doLogging()内部先打印日志,再调用方法,最后打印日志后返回结果。
在LoggingAspect类的声明处,除了用@Component表示它本身也是一个Bean外,我们再加上@Aspect注解,表示它的@Before标注的方法需要注入到UserService的每个public方法执行前,@Around标注的方法需要注入到MailService的每个public方法执行前后。
紧接着,我们需要给@Configuration类加上一个@EnableAspectJAutoProxy注解:
1 |
|
Spring的IoC容器看到这个注解,就会自动查找带有@Aspect的Bean,然后根据每个方法的@Before、@Around等注解把AOP注入到特定的Bean中。执行代码,我们可以看到以下输出:
1 | [Before] do access check... |
这说明执行业务逻辑前后,确实执行了我们定义的Aspect(即LoggingAspect的方法)。
有些童鞋会问,LoggingAspect定义的方法,是如何注入到其他Bean的呢?
其实AOP的原理非常简单。我们以LoggingAspect.doAccessCheck()为例,要把它注入到UserService的每个public方法中,最简单的方法是编写一个子类,并持有原始实例的引用:
1 | public UserServiceAopProxy extends UserService { |
这些都是Spring容器启动时为我们自动创建的注入了Aspect的子类,它取代了原始的UserService(原始的UserService实例作为内部变量隐藏在UserServiceAopProxy中)。如果我们打印从Spring容器获取的UserService实例类型,它类似UserService$$EnhancerBySpringCGLIB$$1f44e01c,实际上是Spring使用CGLIB动态创建的子类,但对于调用方来说,感觉不到任何区别。
注意
Spring对接口类型使用JDK动态代理,对普通类使用CGLIB创建子类。如果一个Bean的class是final,Spring将无法为其创建子类。
可见,虽然Spring容器内部实现AOP的逻辑比较复杂(需要使用AspectJ解析注解,并通过CGLIB实现代理类),但我们使用AOP非常简单,一共需要三步:
- 定义执行方法,并在方法上通过AspectJ的注解告诉Spring应该在何处调用此方法;
- 标记
@Component和@Aspect; - 在
@Configuration类上标注@EnableAspectJAutoProxy。
至于AspectJ的注入语法则比较复杂,请参考Spring文档。
Spring也提供其他方法来装配AOP,但都没有使用AspectJ注解的方式来得简洁明了,所以我们不再作介绍。
拦截器类型
顾名思义,拦截器有以下类型:
- @Before:这种拦截器先执行拦截代码,再执行目标代码。如果拦截器抛异常,那么目标代码就不执行了;
- @After:这种拦截器先执行目标代码,再执行拦截器代码。无论目标代码是否抛异常,拦截器代码都会执行;
- @AfterReturning:和@After不同的是,只有当目标代码正常返回时,才执行拦截器代码;
- @AfterThrowing:和@After不同的是,只有当目标代码抛出了异常时,才执行拦截器代码;
- @Around:能完全控制目标代码是否执行,并可以在执行前后、抛异常后执行任意拦截代码,可以说是包含了上面所有功能。
练习
使用AOP实现日志。
小结
在Spring容器中使用AOP非常简单,只需要定义执行方法,并用AspectJ的注解标注应该在何处触发并执行。
Spring通过CGLIB动态创建子类等方式来实现AOP代理模式,大大简化了代码。
上一节我们讲解了使用AspectJ的注解,并配合一个复杂的execution(* xxx.Xyz.*(..))语法来定义应该如何装配AOP。
在实际项目中,这种写法其实很少使用。假设你写了一个SecurityAspect:
1 |
|
基本能实现无差别全覆盖,即某个包下面的所有Bean的所有方法都会被这个check()方法拦截。
还有的童鞋喜欢用方法名前缀进行拦截:
1 |
|
这种非精准打击误伤面更大,因为从方法前缀区分是否是数据库操作是非常不可取的。
我们在使用AOP时,要注意到虽然Spring容器可以把指定的方法通过AOP规则装配到指定的Bean的指定方法前后,但是,如果自动装配时,因为不恰当的范围,容易导致意想不到的结果,即很多不需要AOP代理的Bean也被自动代理了,并且,后续新增的Bean,如果不清楚现有的AOP装配规则,容易被强迫装配。
使用AOP时,被装配的Bean最好自己能清清楚楚地知道自己被安排了。例如,Spring提供的@Transactional就是一个非常好的例子。如果我们自己写的Bean希望在一个数据库事务中被调用,就标注上@Transactional:
1 |
|
或者直接在class级别注解,表示“所有public方法都被安排了”:
1 |
|
通过@Transactional,某个方法是否启用了事务就一清二楚了。因此,装配AOP的时候,使用注解是最好的方式。
我们以一个实际例子演示如何使用注解实现AOP装配。为了监控应用程序的性能,我们定义一个性能监控的注解:
1 |
|
在需要被监控的关键方法上标注该注解:
1 |
|
然后,我们定义MetricAspect:
1 |
|
注意metric()方法标注了@Around("@annotation(metricTime)"),它的意思是,符合条件的目标方法是带有@MetricTime注解的方法,因为metric()方法参数类型是MetricTime(注意参数名是metricTime不是MetricTime),我们通过它获取性能监控的名称。
有了@MetricTime注解,再配合MetricAspect,任何Bean,只要方法标注了@MetricTime注解,就可以自动实现性能监控。运行代码,输出结果如下:
1 | Welcome, Bob! |
练习
使用注解+AOP实现性能监控。
小结
使用注解实现AOP需要先定义注解,然后使用@Around("@annotation(name)")实现装配;
使用注解既简单,又能明确标识AOP装配,是使用AOP推荐的方式。
无论是使用AspectJ语法,还是配合Annotation,使用AOP,实际上就是让Spring自动为我们创建一个Proxy,使得调用方能无感知地调用指定方法,但运行期却动态“织入”了其他逻辑,因此,AOP本质上就是一个代理模式。
因为Spring使用了CGLIB来实现运行期动态创建Proxy,如果我们没能深入理解其运行原理和实现机制,就极有可能遇到各种诡异的问题。
我们来看一个实际的例子。
假设我们定义了一个UserService的Bean:
1 |
|
再写个MailService,并注入UserService:
1 |
|
最后用main()方法测试一下:
1 |
|
查看输出,一切正常:
1 | UserService(): init... |
下一步,我们给UserService加上AOP支持,就添加一个最简单的LoggingAspect:
1 |
|
别忘了在AppConfig上加上@EnableAspectJAutoProxy。再次运行,不出意外的话,会得到一个NullPointerException:
1 | Exception in thread "main" java.lang.NullPointerException: zone |
仔细跟踪代码,会发现null值出现在MailService.sendMail()内部的这一行代码:
1 |
|
我们还故意在UserService中特意用final修饰了一下成员变量:
1 |
|
用final标注的成员变量为null?逗我呢?
怎么肥四?
为什么加了AOP就报NPE,去了AOP就一切正常?final字段不执行,难道JVM有问题?为了解答这个诡异的问题,我们需要深入理解Spring使用CGLIB生成Proxy的原理:
第一步,正常创建一个UserService的原始实例,这是通过反射调用构造方法实现的,它的行为和我们预期的完全一致;
第二步,通过CGLIB创建一个UserService的子类,并引用了原始实例和LoggingAspect:
1 | public UserService$$EnhancerBySpringCGLIB extends UserService { |
如果我们观察Spring创建的AOP代理,它的类名总是类似UserService$$EnhancerBySpringCGLIB$$1c76af9d(你没看错,Java的类名实际上允许$字符)。为了让调用方获得UserService的引用,它必须继承自UserService。然后,该代理类会覆写所有public和protected方法,并在内部将调用委托给原始的UserService实例。
这里出现了两个UserService实例:
一个是我们代码中定义的原始实例,它的成员变量已经按照我们预期的方式被初始化完成:
1 | UserService original = new UserService(); |
第二个UserService实例实际上类型是UserService$$EnhancerBySpringCGLIB,它引用了原始的UserService实例:
1 | UserService$$EnhancerBySpringCGLIB proxy = new UserService$$EnhancerBySpringCGLIB(); |
注意到这种情况仅出现在启用了AOP的情况,此刻,从ApplicationContext中获取的UserService实例是proxy,注入到MailService中的UserService实例也是proxy。
那么最终的问题来了:proxy实例的成员变量,也就是从UserService继承的zoneId,它的值是null。
原因在于,UserService成员变量的初始化:
1 | public class UserService { |
在UserService$$EnhancerBySpringCGLIB中,并未执行。原因是,没必要初始化proxy的成员变量,因为proxy的目的是代理方法。
实际上,成员变量的初始化是在构造方法中完成的。这是我们看到的代码:
1 | public class UserService { |
这是编译器实际编译的代码:
1 | public class UserService { |
然而,对于Spring通过CGLIB动态创建的UserService$$EnhancerBySpringCGLIB代理类,它的构造方法中,并未调用super(),因此,从父类继承的成员变量,包括final类型的成员变量,统统都没有初始化。
有的童鞋会问:Java语言规定,任何类的构造方法,第一行必须调用super(),如果没有,编译器会自动加上,怎么Spring的CGLIB就可以搞特殊?
这是因为自动加super()的功能是Java编译器实现的,它发现你没加,就自动给加上,发现你加错了,就报编译错误。但实际上,如果直接构造字节码,一个类的构造方法中,不一定非要调用super()。Spring使用CGLIB构造的Proxy类,是直接生成字节码,并没有源码-编译-字节码这个步骤,因此:
注意
Spring通过CGLIB创建的代理类,不会初始化代理类自身继承的任何成员变量,包括final类型的成员变量!
再考察MailService的代码:
1 |
|
如果没有启用AOP,注入的是原始的UserService实例,那么一切正常,因为UserService实例的zoneId字段已经被正确初始化了。
如果启动了AOP,注入的是代理后的UserService$$EnhancerBySpringCGLIB实例,那么问题大了:获取的UserService$$EnhancerBySpringCGLIB实例的zoneId字段,永远为null。
那么问题来了:启用了AOP,如何修复?
修复很简单,只需要把直接访问字段的代码,改为通过方法访问:
1 |
|
无论注入的UserService是原始实例还是代理实例,getZoneId()都能正常工作,因为代理类会覆写getZoneId()方法,并将其委托给原始实例:
1 | public UserService$$EnhancerBySpringCGLIB extends UserService { |
注意到我们还给UserService添加了一个public+final的方法:
1 |
|
如果在MailService中,调用的不是getZoneId(),而是getFinalZoneId(),又会出现NullPointerException,这是因为,代理类无法覆写final方法(这一点绕不过JVM的ClassLoader检查),该方法返回的是代理类的zoneId字段,即null。
实际上,如果我们加上日志,Spring在启动时会打印一个警告:
1 | 10:43:09.929 [main] DEBUG org.springframework.aop.framework.CglibAopProxy - Final method [public final java.time.ZoneId xxx.UserService.getFinalZoneId()] cannot get proxied via CGLIB: Calls to this method will NOT be routed to the target instance and might lead to NPEs against uninitialized fields in the proxy instance. |
上面的日志大意就是,因为被代理的UserService有一个final方法getFinalZoneId(),这会导致其他Bean如果调用此方法,无法将其代理到真正的原始实例,从而可能发生NPE异常。
因此,正确使用AOP,我们需要一个避坑指南:
- 访问被注入的Bean时,总是调用方法而非直接访问字段;
- 编写Bean时,如果可能会被代理,就不要编写
public final方法。
这样才能保证有没有AOP,代码都能正常工作。
思考
为什么Spring刻意不初始化Proxy继承的字段?
如果一个Bean不允许任何AOP代理,应该怎么做来“保护”自己在运行期不会被代理?
练习
修复启用AOP导致的NPE。
小结
由于Spring通过CGLIB实现代理类,我们要避免直接访问Bean的字段,以及由final方法带来的“未代理”问题。
遇到CglibAopProxy的相关日志,务必要仔细检查,防止因为AOP出现NPE异常。
在学习Spring框架时,我们遇到的第一个也是最核心的概念就是容器。
什么是容器?容器是一种为某种特定组件的运行提供必要支持的一个软件环境。例如,Tomcat就是一个Servlet容器,它可以为Servlet的运行提供运行环境。类似Docker这样的软件也是一个容器,它提供了必要的Linux环境以便运行一个特定的Linux进程。
通常来说,使用容器运行组件,除了提供一个组件运行环境之外,容器还提供了许多底层服务。例如,Servlet容器底层实现了TCP连接,解析HTTP协议等非常复杂的服务,如果没有容器来提供这些服务,我们就无法编写像Servlet这样代码简单,功能强大的组件。早期的JavaEE服务器提供的EJB容器最重要的功能就是通过声明式事务服务,使得EJB组件的开发人员不必自己编写冗长的事务处理代码,所以极大地简化了事务处理。
Spring的核心就是提供了一个IoC容器,它可以管理所有轻量级的JavaBean组件,提供的底层服务包括组件的生命周期管理、配置和组装服务、AOP支持,以及建立在AOP基础上的声明式事务服务等。
本章我们讨论的IoC容器,主要介绍Spring容器如何对组件进行生命周期管理和配置组装服务。
Spring提供的容器又称为IoC容器,什么是IoC?
IoC全称Inversion of Control,直译为控制反转。那么何谓IoC?在理解IoC之前,我们先看看通常的Java组件是如何协作的。
我们假定一个在线书店,通过BookService获取书籍:
1 | public class BookService { |
为了从数据库查询书籍,BookService持有一个DataSource。为了实例化一个HikariDataSource,又不得不实例化一个HikariConfig。
现在,我们继续编写UserService获取用户:
1 | public class UserService { |
因为UserService也需要访问数据库,因此,我们不得不也实例化一个HikariDataSource。
在处理用户购买的CartServlet中,我们需要实例化UserService和BookService:
1 | public class CartServlet extends HttpServlet { |
类似的,在购买历史HistoryServlet中,也需要实例化UserService和BookService:
1 | public class HistoryServlet extends HttpServlet { |
上述每个组件都采用了一种简单的通过new创建实例并持有的方式。仔细观察,会发现以下缺点:
- 实例化一个组件其实很难,例如,
BookService和UserService要创建HikariDataSource,实际上需要读取配置,才能先实例化HikariConfig,再实例化HikariDataSource。 - 没有必要让
BookService和UserService分别创建DataSource实例,完全可以共享同一个DataSource,但谁负责创建DataSource,谁负责获取其他组件已经创建的DataSource,不好处理。类似的,CartServlet和HistoryServlet也应当共享BookService实例和UserService实例,但也不好处理。 - 很多组件需要销毁以便释放资源,例如
DataSource,但如果该组件被多个组件共享,如何确保它的使用方都已经全部被销毁? - 随着更多的组件被引入,例如,书籍评论,需要共享的组件写起来会更困难,这些组件的依赖关系会越来越复杂。
- 测试某个组件,例如
BookService,是复杂的,因为必须要在真实的数据库环境下执行。
从上面的例子可以看出,如果一个系统有大量的组件,其生命周期和相互之间的依赖关系如果由组件自身来维护,不但大大增加了系统的复杂度,而且会导致组件之间极为紧密的耦合,继而给测试和维护带来了极大的困难。
因此,核心问题是:
- 谁负责创建组件?
- 谁负责根据依赖关系组装组件?
- 销毁时,如何按依赖顺序正确销毁?
解决这一问题的核心方案就是IoC。
传统的应用程序中,控制权在程序本身,程序的控制流程完全由开发者控制,例如:
CartServlet创建了BookService,在创建BookService的过程中,又创建了DataSource组件。这种模式的缺点是,一个组件如果要使用另一个组件,必须先知道如何正确地创建它。
在IoC模式下,控制权发生了反转,即从应用程序转移到了IoC容器,所有组件不再由应用程序自己创建和配置,而是由IoC容器负责,这样,应用程序只需要直接使用已经创建好并且配置好的组件。为了能让组件在IoC容器中被“装配”出来,需要某种“注入”机制,例如,BookService自己并不会创建DataSource,而是等待外部通过setDataSource()方法来注入一个DataSource:
1 | public class BookService { |
不直接new一个DataSource,而是注入一个DataSource,这个小小的改动虽然简单,却带来了一系列好处:
BookService不再关心如何创建DataSource,因此,不必编写读取数据库配置之类的代码;DataSource实例被注入到BookService,同样也可以注入到UserService,因此,共享一个组件非常简单;- 测试
BookService更容易,因为注入的是DataSource,可以使用内存数据库,而不是真实的MySQL配置。
因此,IoC又称为依赖注入(DI:Dependency Injection),它解决了一个最主要的问题:将组件的创建+配置与组件的使用相分离,并且,由IoC容器负责管理组件的生命周期。
因为IoC容器要负责实例化所有的组件,因此,有必要告诉容器如何创建组件,以及各组件的依赖关系。一种最简单的配置是通过XML文件来实现,例如:
1 | <beans> |
上述XML配置文件指示IoC容器创建3个JavaBean组件,并把id为dataSource的组件通过属性dataSource(即调用setDataSource()方法)注入到另外两个组件中。
在Spring的IoC容器中,我们把所有组件统称为JavaBean,即配置一个组件就是配置一个Bean。
依赖注入方式
我们从上面的代码可以看到,依赖注入可以通过set()方法实现。但依赖注入也可以通过构造方法实现。
很多Java类都具有带参数的构造方法,如果我们把BookService改造为通过构造方法注入,那么实现代码如下:
1 | public class BookService { |
Spring的IoC容器同时支持属性注入和构造方法注入,并允许混合使用。
无侵入容器
在设计上,Spring的IoC容器是一个高度可扩展的无侵入容器。所谓无侵入,是指应用程序的组件无需实现Spring的特定接口,或者说,组件根本不知道自己在Spring的容器中运行。这种无侵入的设计有以下好处:
- 应用程序组件既可以在Spring的IoC容器中运行,也可以自己编写代码自行组装配置;
- 测试的时候并不依赖Spring容器,可单独进行测试,大大提高了开发效率。
我们前面讨论了为什么要使用Spring的IoC容器,因为让容器来为我们创建并装配Bean能获得很大的好处,那么到底如何使用IoC容器?装配好的Bean又如何使用?
我们来看一个具体的用户注册登录的例子。整个工程的结构如下:
1 | spring-ioc-appcontext |
首先,我们用Maven创建工程并引入spring-context依赖:
- org.springframework:spring-context:6.0.0
我们先编写一个MailService,用于在用户登录和注册成功后发送邮件通知:
1 | public class MailService { |
再编写一个UserService,实现用户注册和登录:
1 | public class UserService { |
注意到UserService通过setMailService()注入了一个MailService。
然后,我们需要编写一个特定的application.xml配置文件,告诉Spring的IoC容器应该如何创建并组装Bean:
1 |
|
注意观察上述配置文件,其中与XML Schema相关的部分格式是固定的,我们只关注两个<bean ...>的配置:
- 每个
<bean ...>都有一个id标识,相当于Bean的唯一ID; - 在
userServiceBean中,通过<property name="..." ref="..." />注入了另一个Bean; - Bean的顺序不重要,Spring根据依赖关系会自动正确初始化。
把上述XML配置文件用Java代码写出来,就像这样:
1 | UserService userService = new UserService(); |
只不过Spring容器是通过读取XML文件后使用反射完成的。
如果注入的不是Bean,而是boolean、int、String这样的数据类型,则通过value注入,例如,创建一个HikariDataSource:
1 | <bean id="dataSource" class="com.zaxxer.hikari.HikariDataSource"> |
最后一步,我们需要创建一个Spring的IoC容器实例,然后加载配置文件,让Spring容器为我们创建并装配好配置文件中指定的所有Bean,这只需要一行代码:
1 | ApplicationContext context = new ClassPathXmlApplicationContext("application.xml"); |
接下来,我们就可以从Spring容器中“取出”装配好的Bean然后使用它:
1 | // 获取Bean: |
完整的main()方法如下:
1 | public class Main { |
ApplicationContext
我们从创建Spring容器的代码:
1 | ApplicationContext context = new ClassPathXmlApplicationContext("application.xml"); |
可以看到,Spring容器就是ApplicationContext,它是一个接口,有很多实现类,这里我们选择ClassPathXmlApplicationContext,表示它会自动从classpath中查找指定的XML配置文件。
获得了ApplicationContext的实例,就获得了IoC容器的引用。从ApplicationContext中我们可以根据Bean的ID获取Bean,但更多的时候我们根据Bean的类型获取Bean的引用:
1 | UserService userService = context.getBean(UserService.class); |
Spring还提供另一种IoC容器叫BeanFactory,使用方式和ApplicationContext类似:
1 | BeanFactory factory = new XmlBeanFactory(new ClassPathResource("application.xml")); |
BeanFactory和ApplicationContext的区别在于,BeanFactory的实现是按需创建,即第一次获取Bean时才创建这个Bean,而ApplicationContext会一次性创建所有的Bean。实际上,ApplicationContext接口是从BeanFactory接口继承而来的,并且,ApplicationContext提供了一些额外的功能,包括国际化支持、事件和通知机制等。通常情况下,我们总是使用ApplicationContext,很少会考虑使用BeanFactory。
练习
在上述示例的基础上,继续给UserService注入DataSource,并把注册和登录功能通过数据库实现。
小结
Spring的IoC容器接口是ApplicationContext,并提供了多种实现类;
通过XML配置文件创建IoC容器时,使用ClassPathXmlApplicationContext;
持有IoC容器后,通过getBean()方法获取Bean的引用。
使用Spring的IoC容器,实际上就是通过类似XML这样的配置文件,把我们自己的Bean的依赖关系描述出来,然后让容器来创建并装配Bean。一旦容器初始化完毕,我们就直接从容器中获取Bean使用它们。
使用XML配置的优点是所有的Bean都能一目了然地列出来,并通过配置注入能直观地看到每个Bean的依赖。它的缺点是写起来非常繁琐,每增加一个组件,就必须把新的Bean配置到XML中。
有没有其他更简单的配置方式呢?
有!我们可以使用Annotation配置,可以完全不需要XML,让Spring自动扫描Bean并组装它们。
我们把上一节的示例改造一下,先删除XML配置文件,然后,给UserService和MailService添加几个注解。
首先,我们给MailService添加一个@Component注解:
1 |
|
这个@Component注解就相当于定义了一个Bean,它有一个可选的名称,默认是mailService,即小写开头的类名。
然后,我们给UserService添加一个@Component注解和一个@Autowired注解:
1 |
|
使用@Autowired就相当于把指定类型的Bean注入到指定的字段中。和XML配置相比,@Autowired大幅简化了注入,因为它不但可以写在set()方法上,还可以直接写在字段上,甚至可以写在构造方法中:
1 |
|
我们一般把@Autowired写在字段上,通常使用package权限的字段,便于测试。
最后,编写一个AppConfig类启动容器:
1 |
|
除了main()方法外,AppConfig标注了@Configuration,表示它是一个配置类,因为我们创建ApplicationContext时:
1 | ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); |
使用的实现类是AnnotationConfigApplicationContext,必须传入一个标注了@Configuration的类名。
此外,AppConfig还标注了@ComponentScan,它告诉容器,自动搜索当前类所在的包以及子包,把所有标注为@Component的Bean自动创建出来,并根据@Autowired进行装配。
整个工程结构如下:
1 | spring-ioc-annoconfig |
使用Annotation配合自动扫描能大幅简化Spring的配置,我们只需要保证:
- 每个Bean被标注为
@Component并正确使用@Autowired注入; - 配置类被标注为
@Configuration和@ComponentScan; - 所有Bean均在指定包以及子包内。
使用@ComponentScan非常方便,但是,我们也要特别注意包的层次结构。通常来说,启动配置AppConfig位于自定义的顶层包(例如com.itranswarp.learnjava),其他Bean按类别放入子包。
思考
如果我们想给UserService注入HikariDataSource,但是这个类位于com.zaxxer.hikari包中,并且HikariDataSource也不可能有@Component注解,如何告诉IoC容器创建并配置HikariDataSource?或者换个说法,如何创建并配置一个第三方Bean?
练习
使用Annotation配置IoC容器。
小结
使用Annotation可以大幅简化配置,每个Bean通过@Component和@Autowired注入;
必须合理设计包的层次结构,才能发挥@ComponentScan的威力。
Scope
对于Spring容器来说,当我们把一个Bean标记为@Component后,它就会自动为我们创建一个单例(Singleton),即容器初始化时创建Bean,容器关闭前销毁Bean。在容器运行期间,我们调用getBean(Class)获取到的Bean总是同一个实例。
还有一种Bean,我们每次调用getBean(Class),容器都返回一个新的实例,这种Bean称为Prototype(原型),它的生命周期显然和Singleton不同。声明一个Prototype的Bean时,需要添加一个额外的@Scope注解:
1 |
|
注入List
有些时候,我们会有一系列接口相同,不同实现类的Bean。例如,注册用户时,我们要对email、password和name这3个变量进行验证。为了便于扩展,我们先定义验证接口:
1 | public interface Validator { |
然后,分别使用3个Validator对用户参数进行验证:
1 |
|
最后,我们通过一个Validators作为入口进行验证:
1 |
|
注意到Validators被注入了一个List<Validator>,Spring会自动把所有类型为Validator的Bean装配为一个List注入进来,这样一来,我们每新增一个Validator类型,就自动被Spring装配到Validators中了,非常方便。
因为Spring是通过扫描classpath获取到所有的Bean,而List是有序的,要指定List中Bean的顺序,可以加上@Order注解:
1 |
|
可选注入
默认情况下,当我们标记了一个@Autowired后,Spring如果没有找到对应类型的Bean,它会抛出NoSuchBeanDefinitionException异常。
可以给@Autowired增加一个required = false的参数:
1 |
|
这个参数告诉Spring容器,如果找到一个类型为ZoneId的Bean,就注入,如果找不到,就忽略。
这种方式非常适合有定义就使用定义,没有就使用默认值的情况。
创建第三方Bean
如果一个Bean不在我们自己的package管理之内,例如ZoneId,如何创建它?
答案是我们自己在@Configuration类中编写一个Java方法创建并返回它,注意给方法标记一个@Bean注解:
1 |
|
Spring对标记为@Bean的方法只调用一次,因此返回的Bean仍然是单例。
初始化和销毁
有些时候,一个Bean在注入必要的依赖后,需要进行初始化(监听消息等)。在容器关闭时,有时候还需要清理资源(关闭连接池等)。我们通常会定义一个init()方法进行初始化,定义一个shutdown()方法进行清理,然后,引入JSR-250定义的Annotation:
- jakarta.annotation:jakarta.annotation-api:2.1.1
在Bean的初始化和清理方法上标记@PostConstruct和@PreDestroy:
1 |
|
Spring容器会对上述Bean做如下初始化流程:
- 调用构造方法创建
MailService实例; - 根据
@Autowired进行注入; - 调用标记有
@PostConstruct的init()方法进行初始化。
而销毁时,容器会首先调用标记有@PreDestroy的shutdown()方法。
Spring只根据Annotation查找无参数方法,对方法名不作要求。
使用别名
默认情况下,对一种类型的Bean,容器只创建一个实例。但有些时候,我们需要对一种类型的Bean创建多个实例。例如,同时连接多个数据库,就必须创建多个DataSource实例。
如果我们在@Configuration类中创建了多个同类型的Bean:
1 |
|
Spring会报NoUniqueBeanDefinitionException异常,意思是出现了重复的Bean定义。
这个时候,需要给每个Bean添加不同的名字:
1 |
|
可以用@Bean("name")指定别名,也可以用@Bean+@Qualifier("name")指定别名。
存在多个同类型的Bean时,注入ZoneId又会报错:
1 | NoUniqueBeanDefinitionException: No qualifying bean of type 'java.time.ZoneId' available: expected single matching bean but found 2 |
意思是期待找到唯一的ZoneId类型Bean,但是找到两。因此,注入时,要指定Bean的名称:
1 |
|
还有一种方法是把其中某个Bean指定为@Primary:
1 |
|
这样,在注入时,如果没有指出Bean的名字,Spring会注入标记有@Primary的Bean。这种方式也很常用。例如,对于主从两个数据源,通常将主数据源定义为@Primary:
1 |
|
其他Bean默认注入的就是主数据源。如果要注入从数据源,那么只需要指定名称即可。
使用FactoryBean
我们在设计模式的工厂方法中讲到,很多时候,可以通过工厂模式创建对象。Spring也提供了工厂模式,允许定义一个工厂,然后由工厂创建真正的Bean。
用工厂模式创建Bean需要实现FactoryBean接口。我们观察下面的代码:
1 |
|
当一个Bean实现了FactoryBean接口后,Spring会先实例化这个工厂,然后调用getObject()创建真正的Bean。getObjectType()可以指定创建的Bean的类型,因为指定类型不一定与实际类型一致,可以是接口或抽象类。
因此,如果定义了一个FactoryBean,要注意Spring创建的Bean实际上是这个FactoryBean的getObject()方法返回的Bean。为了和普通Bean区分,我们通常都以XxxFactoryBean命名。
由于可以用@Bean方法创建第三方Bean,本质上@Bean方法就是工厂方法,所以,FactoryBean已经用得越来越少了。
练习
定制Bean。
小结
Spring默认使用Singleton创建Bean,也可指定Scope为Prototype;
可将相同类型的Bean注入List或数组;
可用@Autowired(required=false)允许可选注入;
可用带@Bean标注的方法创建Bean;
可使用@PostConstruct和@PreDestroy对Bean进行初始化和清理;
相同类型的Bean只能有一个指定为@Primary,其他必须用@Qualifier("beanName")指定别名;
注入时,可通过别名@Qualifier("beanName")指定某个Bean;
可以定义FactoryBean来使用工厂模式创建Bean。
使用Resource
在Java程序中,我们经常会读取配置文件、资源文件等。使用Spring容器时,我们也可以把“文件”注入进来,方便程序读取。
例如,AppService需要读取logo.txt这个文件,通常情况下,我们需要写很多繁琐的代码,主要是为了定位文件,打开InputStream。
Spring提供了一个org.springframework.core.io.Resource(注意不是jarkata.annotation.Resource或javax.annotation.Resource),它可以像String、int一样使用@Value注入:
1 |
|
注入Resource最常用的方式是通过classpath,即类似classpath:/logo.txt表示在classpath中搜索logo.txt文件,然后,我们直接调用Resource.getInputStream()就可以获取到输入流,避免了自己搜索文件的代码。
也可以直接指定文件的路径,例如:
1 |
|
但使用classpath是最简单的方式。上述工程结构如下:
1 | spring-ioc-resource |
使用Maven的标准目录结构,所有资源文件放入src/main/resources即可。
练习
使用Spring的Resource注入app.properties文件,然后读取该配置文件。
小结
Spring提供了Resource类便于注入资源文件。
最常用的注入是通过classpath以classpath:/path/to/file的形式注入。
注入配置
在开发应用程序时,经常需要读取配置文件。最常用的配置方法是以key=value的形式写在.properties文件中。
例如,MailService根据配置的app.zone=Asia/Shanghai来决定使用哪个时区。要读取配置文件,我们可以使用上一节讲到的Resource来读取位于classpath下的一个app.properties文件。但是,这样仍然比较繁琐。
Spring容器还提供了一个更简单的@PropertySource来自动读取配置文件。我们只需要在@Configuration配置类上再添加一个注解:
1 |
|
Spring容器看到@PropertySource("app.properties")注解后,自动读取这个配置文件,然后,我们使用@Value正常注入:
1 |
|
注意注入的字符串语法,它的格式如下:
"${app.zone}"表示读取key为app.zone的value,如果key不存在,启动将报错;"${app.zone:Z}"表示读取key为app.zone的value,但如果key不存在,就使用默认值Z。
这样一来,我们就可以根据app.zone的配置来创建ZoneId。
还可以把注入的注解写到方法参数中:
1 |
|
可见,先使用@PropertySource读取配置文件,然后通过@Value以${key:defaultValue}的形式注入,可以极大地简化读取配置的麻烦。
另一种注入配置的方式是先通过一个简单的JavaBean持有所有的配置,例如,一个SmtpConfig:
1 |
|
然后,在需要读取的地方,使用#{smtpConfig.host}注入:
1 |
|
注意观察#{}这种注入语法,它和${key}不同的是,#{}表示从JavaBean读取属性。"#{smtpConfig.host}"的意思是,从名称为smtpConfig的Bean读取host属性,即调用getHost()方法。一个Class名为SmtpConfig的Bean,它在Spring容器中的默认名称就是smtpConfig,除非用@Qualifier指定了名称。
使用一个独立的JavaBean持有所有属性,然后在其他Bean中以#{bean.property}注入的好处是,多个Bean都可以引用同一个Bean的某个属性。例如,如果SmtpConfig决定从数据库中读取相关配置项,那么MailService注入的@Value("#{smtpConfig.host}")仍然可以不修改正常运行。
练习
注入SMTP配置。
小结
Spring容器可以通过@PropertySource自动读取配置,并以@Value("${key}")的形式注入;
可以通过${key:defaultValue}指定默认值;
以#{bean.property}形式注入时,Spring容器自动把指定Bean的指定属性值注入。
开发应用程序时,我们会使用开发环境,例如,使用内存数据库以便快速启动。而运行在生产环境时,我们会使用生产环境,例如,使用MySQL数据库。如果应用程序可以根据自身的环境做一些适配,无疑会更加灵活。
Spring为应用程序准备了Profile这一概念,用来表示不同的环境。例如,我们分别定义开发、测试和生产这3个环境:
- native
- test
- production
创建某个Bean时,Spring容器可以根据注解@Profile来决定是否创建。例如,以下配置:
1 |
|
如果当前的Profile设置为test,则Spring容器会调用createZoneIdForTest()创建ZoneId,否则,调用createZoneId()创建ZoneId。注意到@Profile("!test")表示非test环境。
在运行程序时,加上JVM参数-Dspring.profiles.active=test就可以指定以test环境启动。
实际上,Spring允许指定多个Profile,例如:
1 | -Dspring.profiles.active=test,master |
可以表示test环境,并使用master分支代码。
要满足多个Profile条件,可以这样写:
1 |
|
使用Conditional
除了根据@Profile条件来决定是否创建某个Bean外,Spring还可以根据@Conditional决定是否创建某个Bean。
例如,我们对SmtpMailService添加如下注解:
1 |
|
它的意思是,如果满足OnSmtpEnvCondition的条件,才会创建SmtpMailService这个Bean。OnSmtpEnvCondition的条件是什么呢?我们看一下代码:
1 | public class OnSmtpEnvCondition implements Condition { |
因此,OnSmtpEnvCondition的条件是存在环境变量smtp,值为true。这样,我们就可以通过环境变量来控制是否创建SmtpMailService。
Spring只提供了@Conditional注解,具体判断逻辑还需要我们自己实现。Spring Boot提供了更多使用起来更简单的条件注解,例如,如果配置文件中存在app.smtp=true,则创建MailService:
1 |
|
如果当前classpath中存在类javax.mail.Transport,则创建MailService:
1 |
|
后续我们会介绍Spring Boot的条件装配。我们以文件存储为例,假设我们需要保存用户上传的头像,并返回存储路径,在本地开发运行时,我们总是存储到文件:
1 |
|
在生产环境运行时,我们会把文件存储到类似AWS S3上:
1 |
|
其他需要存储的服务则注入Uploader:
1 |
|
当应用程序检测到配置文件存在app.storage=s3时,自动使用S3Uploader,如果存在配置app.storage=file,或者配置app.storage不存在,则使用FileUploader。
可见,使用条件注解,能更灵活地装配Bean。
练习
使用@Profile进行条件装配。
小结
Spring允许通过@Profile配置不同的Bean;
Spring还提供了@Conditional来进行条件装配,Spring Boot在此基础上进一步提供了基于配置、Class、Bean等条件进行装配。
Spring开发
什么是Spring?
Spring是一个支持快速开发Java EE应用程序的框架。它提供了一系列底层容器和基础设施,并可以和大量常用的开源框架无缝集成,可以说是开发Java EE应用程序的必备。

Spring最早是由Rod Johnson这哥们在他的《Expert One-on-One J2EE Development without EJB》一书中提出的用来取代EJB的轻量级框架。随后这哥们又开始专心开发这个基础框架,并起名为Spring Framework。
随着Spring越来越受欢迎,在Spring Framework基础上,又诞生了Spring Boot、Spring Cloud、Spring Data、Spring Security等一系列基于Spring Framework的项目。本章我们只介绍Spring Framework,即最核心的Spring框架。后续章节我们还会涉及Spring Boot、Spring Cloud等其他框架。
Spring Framework
Spring Framework主要包括几个模块:
- 支持IoC和AOP的容器;
- 支持JDBC和ORM的数据访问模块;
- 支持声明式事务的模块;
- 支持基于Servlet的MVC开发;
- 支持基于Reactive的Web开发;
- 以及集成JMS、JavaMail、JMX、缓存等其他模块。
我们会依次介绍Spring Framework的主要功能。
本教程使用的Spring版本是6.x版,如果使用Spring 5.x则需注意,两者有以下不同:
| Spring 5.x | Spring 6.x | |
|---|---|---|
| JDK版本 | >= 1.8 | >= 17 |
| Tomcat版本 | 9.x | 10.x |
| Annotation包 | javax.annotation | jakarta.annotation |
| Servlet包 | javax.servlet | jakarta.servlet |
| JMS包 | javax.jms | jakarta.jms |
| JavaMail包 | javax.mail | jakarta.mail |
如果使用Spring的其他版本,则需要根据需要调整代码。
Spring官网是spring.io,要注意官网有许多项目,我们这里说的Spring是指Spring Framework,可以直接从这里访问最新版以及文档,建议添加到浏览器收藏夹。