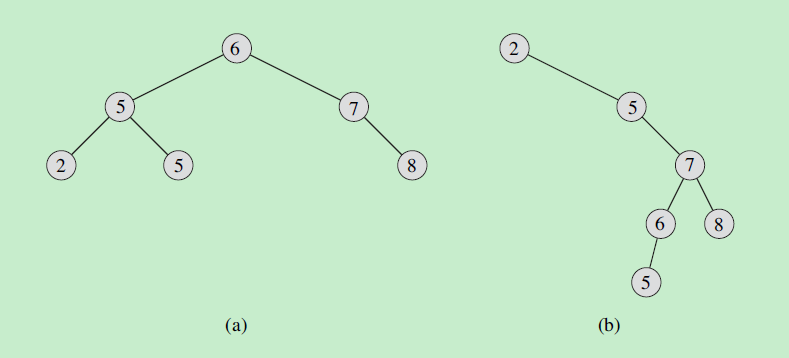
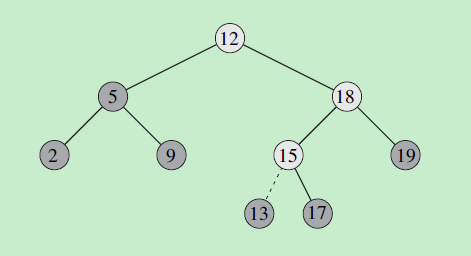
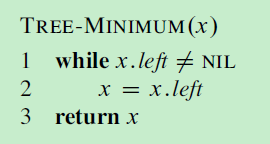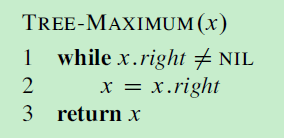13. 红黑树
二叉搜索树的各种操作时间复杂度为,但是树的高度h不可控,最差的情况为n。
而平衡搜索树能将树的高度控制在。
常见的平衡搜索树有:
- AVL树
- 红黑树
- treap (tree + heap,给每个元素随机的priority,从而间接的实现随机插入,使得树的期望高度为)
- B树 (十八章介绍)
- 2-3-4树
本章重点讨论红黑树,以及习题中出现的AVL树。AVL树较为简单所以先介绍AVL树。
AVL树
AVL树由Adel’son-Vel’skii & Landis 在1962年发明,由他们的名字命名。
比较一般的二叉搜索树,每个结点额外存储它的高度,nil的高度为0,其他节点的高度为Height(x) = max(Height(x->left), Height(x->right)) + 1。每个结点两个孩子的高度差不能超过1。
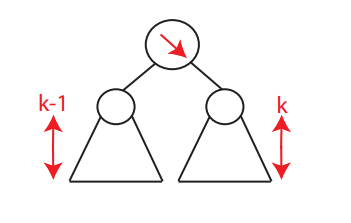
当右子树的高度比左子树的高度高时,我们称right-heavy(如下图),反之这称left-heavy。
AVL树的各种查询操作都和普通二叉搜索树无异,所以我们只需关注会改变树结构的Insert操作和Delete操作。
在一般的Insert或者Delete操作后,结点的高度会变,所以有可能会违反AVL树的性质,这时候我们需要引入一个操作Rotate(旋转)
Rotate
旋转分为两种,左旋(LEFT-ROTATE)和右旋(RIGHT-ROTATE)。下图右测变为左侧的情况称为对x结点左旋,左侧变为右侧的情况称为对y结点做右旋。

我们可以发现旋转操作并不会影响二叉搜索树的性质。
旋转前后都会保持α <= x <= β <= y <= γ
下面是左旋的伪代码,右旋的操作和左旋对称,不再赘述。

Ref:AVLTree::LeftRotate & AVLTree::RightRotate in AVLTree.h
AVL树平衡调整(ADJUST_FROM(x))
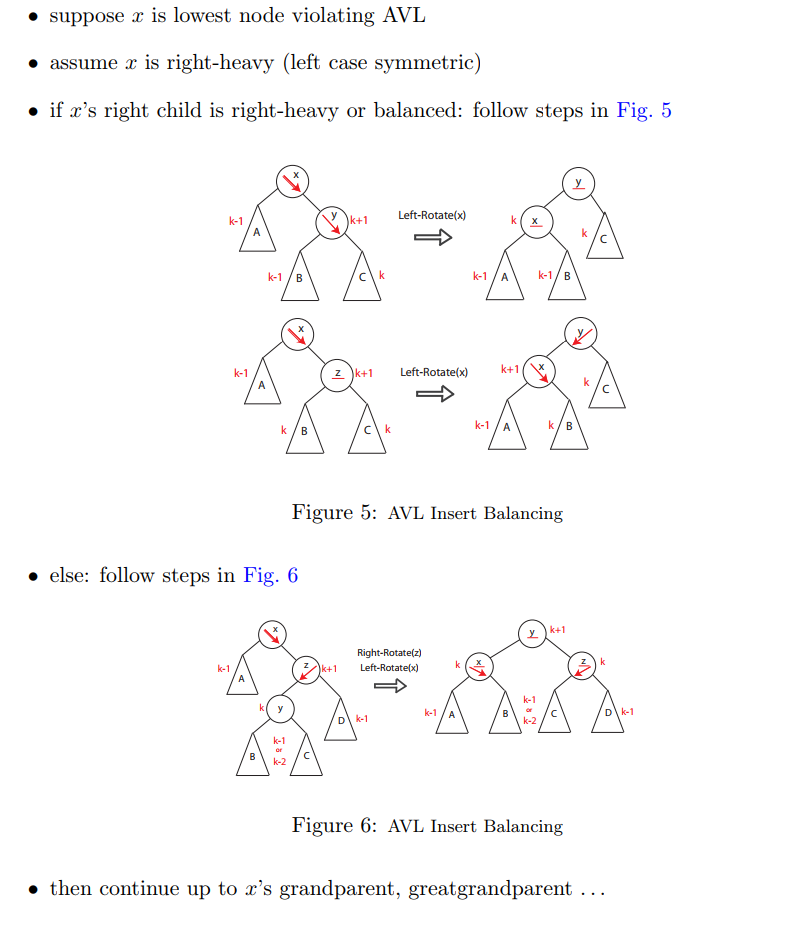
当Insert或者Delete一个元素后,平衡有可能被破坏,假设x是最底层被破坏性质的节点,而且是right-heavy时(left-heavy是对称的):
- Balance
- 如果x的右孩子y是平衡的或者right-heavy的(Figure 5)
- 我们对x做LEFT-ROTATE操作可使其恢复平衡
- 然后重新计算x和y的高度
- 如果x的右孩子z是left-heavy的(Figure 6)
- 我们先对z做RIGHT_ROTATE,然后对x做LEFT-ROTATE,可使其恢复平衡
- 然后重新计算x,y,z的高度
- 如果x的右孩子y是平衡的或者right-heavy的(Figure 5)
- Loop
- 重新计算x的高度,并使得x=x->p继续循环,直到根节点
- 若图中发现某节点不平衡的用1. Balance
Ref:AVLTree::AdjustFrom in AVLTree.h
AVL树 Insert
因为插入的节点肯定是叶子节点,所以直接对插入节点调用ADJUST_FROM(x)即可。
Ref:AVLTree::Insert in AVLTree.h
AVL树 Delete
删除操作略为复杂,可能会影响子节点的平衡。
- 当被删除节点只有一个孩子,或者没有孩子时,被删除节点的孩子不会被应用
- 这时对删除节点原来的父节点调用ADJUST_FROM(x)即可
- 当被删除节点有两个孩子时
- 如果被删除节点右子树的最小节点min的父节点为被删除节点,这时对min调用ADJUST_FROM(x)
- 其他情况,对min原来的父节点调用ADJUST_FROM(x)
Ref:AVLTree::Delete in AVLTree.h
红黑树
红黑树也是一种平衡二叉树。它在每个节点上增加一个存储位color来表示节点的颜色,节点的颜色为RED或者BLACK。通过对任何一条从根节点到叶子节点的颜色进行约束,红黑树确保没有一条路径会比其他路径长出2倍,所以是近似于平衡的。
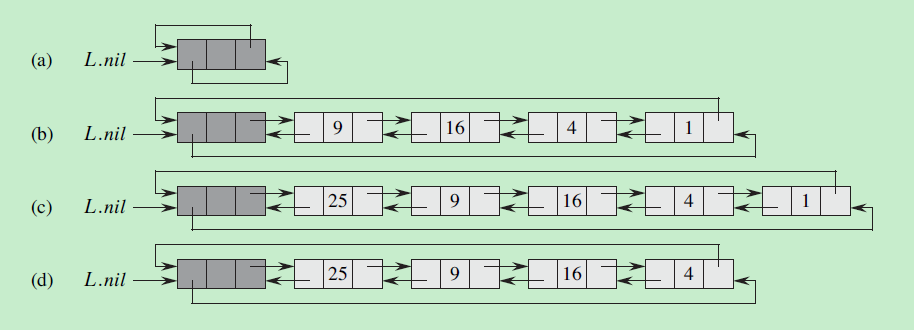
红黑树还定义一种NIL节点,NIL节点是红黑树的叶子结点(外部节点),真实的数据组成树的内部节点(如下图a所示)。
红黑树的具体性质如下:
- 每个节点不是红色的就是黑色的
- 根节点是黑色的
- 每个叶结点(NIL)是黑色的
- 如果一个结点是红色的,那么它的两个孩子都是黑色的
- 对于每个结点,从该结点到其所有后代叶结点的简单路径上,黑色结点的数量相同
为了方便处理,使用一个哨兵来替代NIL结点。对于一颗红黑树T,哨兵T.nil是一个普通结点。它的color为BLACK,用哨兵T.nil替换图a中的所有NIL,这样就形如下图b所示,T.nil的p, left, right, key属性我们并不关心,所以方便起见程序中可以对其值随意设定。
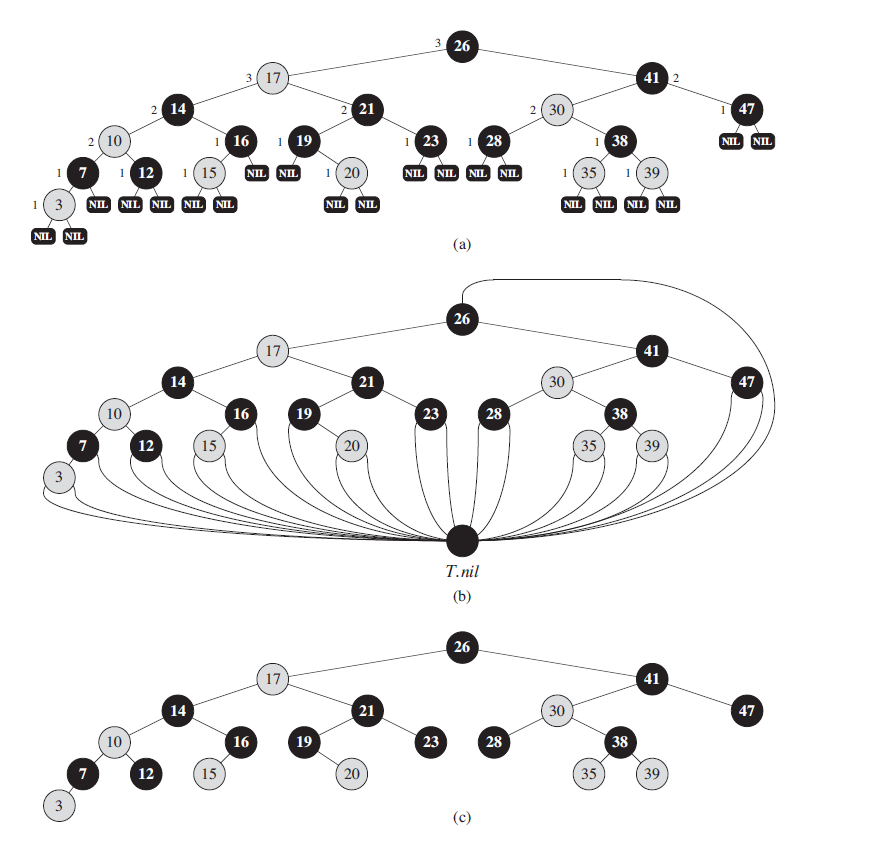
为了方便起见,我们在图中省去T.nil,这样就变成了图c的样子。
NULL -> T.nil
红黑树与普通二叉搜索树相比,用T.nil替代了空指针。
所以所有操作中用到空指针的地方,需要换成T.nil。后面不做赘述。
红黑树 Insert
红黑树的插入操作,除了一般的操作外,还需要把插入结点的颜色设为RED。因为插入了一个红色的结点,所以有可能触犯红黑树的一些性质(1,4),所以我们要调用RB-INSERT-FIXUP将其修正。
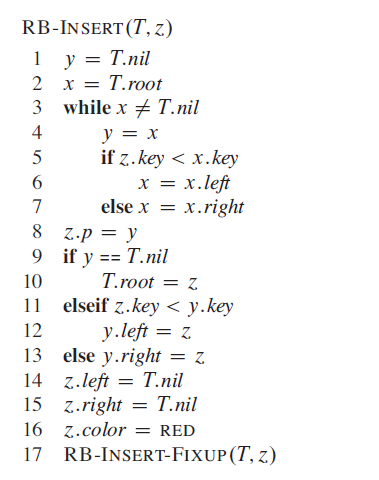

RB-INSERT-FIXUP会循环的查看z的父结点是否违反性质4,如果违反,则将其修正。如果修正后仍然有可能违反性质4,则继续循环查看其爷结点。(本文只讨论插入结点的父结点为爷结点的左孩子的情况,右孩子的情况与其对称,不再赘述。)
修正过程有三种情况:
- Case 1. z的叔结点为红色
- Case 2. z的叔结点为黑色,且z是父亲的右孩子
- Case 3. z的叔结点为黑色,且z是父亲的左孩子
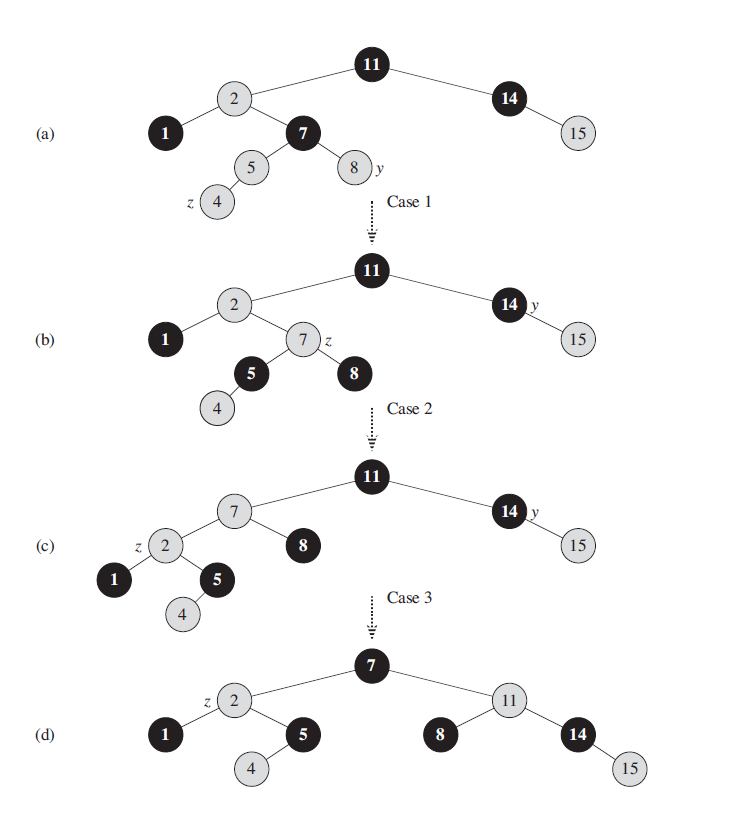
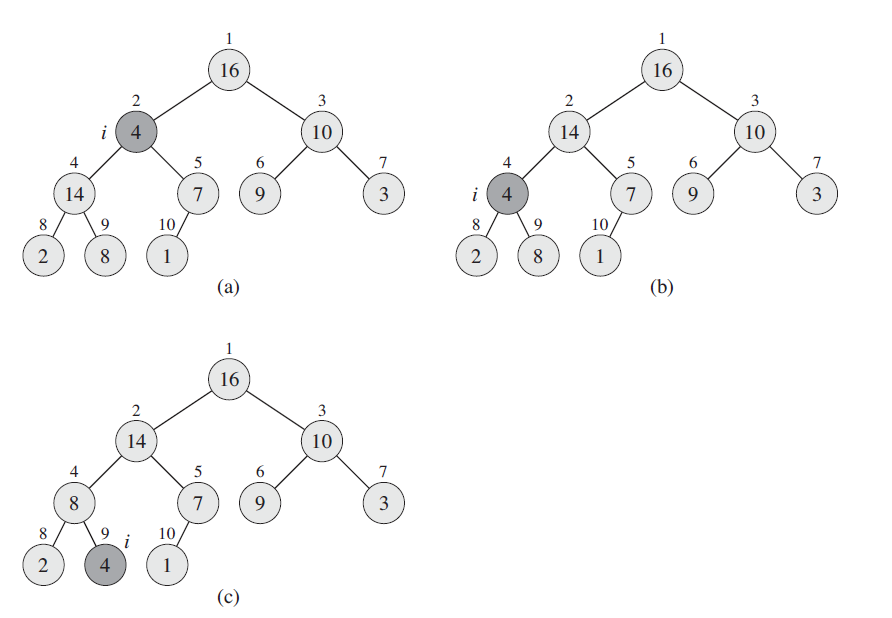
上图插入4之后的处理过程。下面我们详细讨论下三种情况的处理方式:
-
Case 1
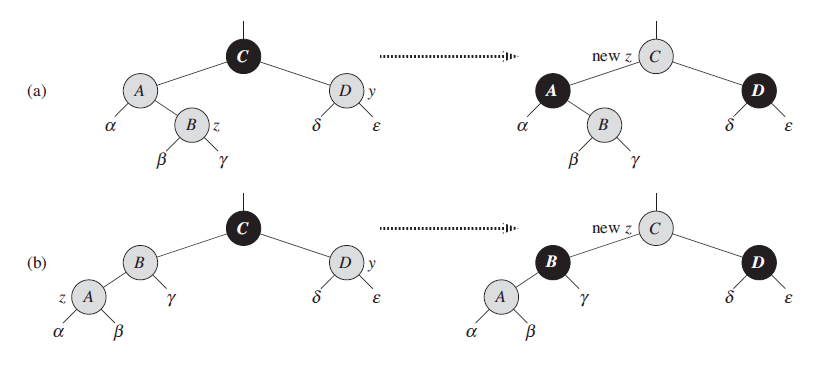
这种情况只需改变着色,将父节点和叔结点染成黑色,爷结点染成红色。
因为爷结点以前是黑色,却染成了红色,如果爷结点的父结点为红色,这时仍会触犯性质4,所以我们将爷结点赋给z,下次循环时再修正它。
如果z的爷结点为root结点,我们修正后root结点变成了红色,并且让z指向root结点然后跳出了循环。在循环外边我们会将z重新染成黑色,所以保持了性质1。
-
Case 2/3
当z是父结点的左孩子时,符合Case 3,这时我们只需把爷结点做右旋,然后交换之前父结点和爷结点的颜色。这时局部的根节点颜色没有改变,仍然是黑色,所以整个树都满足了红黑树的特性,无需继续循环。
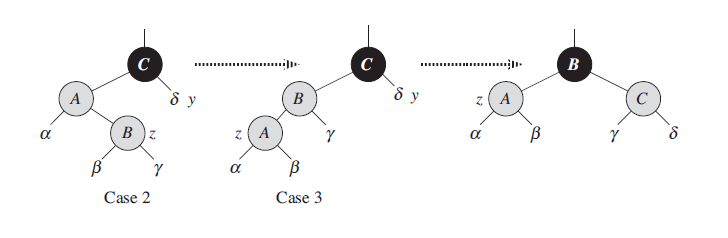
当z是父结点的右孩子时,符合Case 2,这时只需要对父结点做左旋,使其变为Case 3的情况。
由上可知,一旦循环进入Case 2或者Case 3,就会结束循环。所以一次插入操作最多只会有两次旋转操作。尽量少的循环操作是非常有益的,因为改变结点颜色并不会影响查找功能,当多线程处理时我们只需给旋转操作加锁。
红黑树 Delete
删除操作比插入操作略微复杂,当删除一个黑色结点,或者删除过程中移动了一个黑色结点时,都有可能破坏红黑树的性质(2,4,5)。
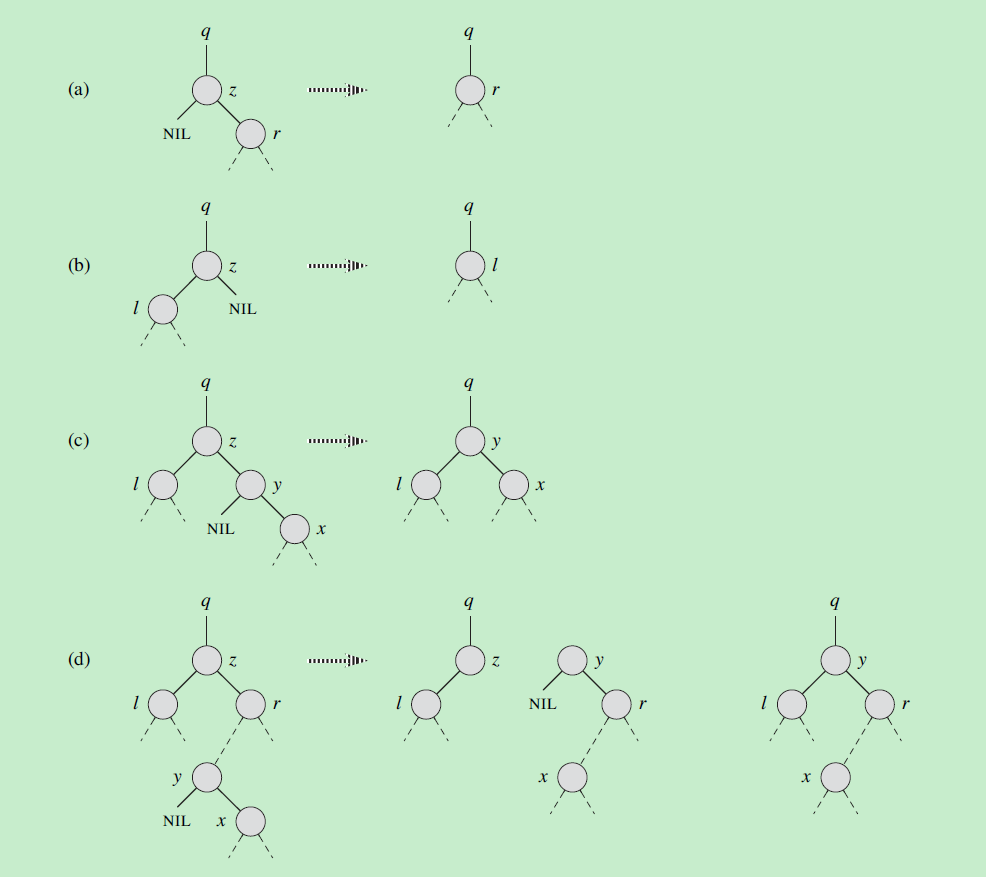
当被删除的结点只有一个孩子,或者没有孩子,这时我们只需关心被删除结点的颜色,如果被删除的结点为红色,则无需修正,如果被删除结点为黑色,则需要从被删除结点的孩子开始修正。
当被删除的结点有两个孩子时,我们会找右子树的最小结点来替代被删除结点的位置和颜色,所以这是我们需要关注这个最小结点的颜色,如果最小结点的颜色为红色,则无需修整,如果这个最小结点为黑色,则需要从最小结点的右孩子开始修正。


从x开始修正时,有五种情况:
- Case 0. x为红色
- 这时23行会将其设为黑色,可直接满足所有红黑树性质
- Case 1. x的兄弟结点w为红色
- Case 2. x的兄弟节点w为黑色,且w的两个孩子都是黑色
- Case 3. x的兄弟节点w为黑色,且w的右孩子为黑色,左孩子有红色
- Case 4. x的兄弟节点w为黑色,且w的右孩子为红色
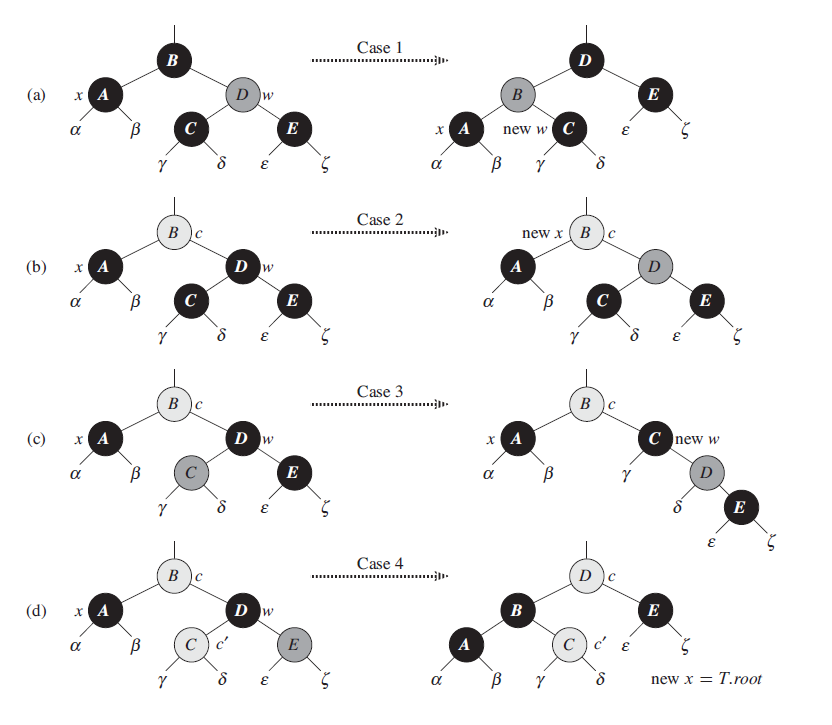
-
Case 1
这种情况我们将其转换为Case2/3/4- 设置兄弟节点w为黑色,父结点为红色
- 左旋父结点
- 重新设置w为x的兄弟结点
-
Case 2
这种情况将兄弟结点w设置为红色,并且x=x.p,继续循环。
我们会发现,如果是从Case 1转换到Case 2,那么x.p一定是红色,所以会直接退出循环。 -
Case 3
这种情况我们将其转换为Case4- 设置兄弟节点w为红色,w的左孩子为黑色
- 右旋w结点
- 重新设置w为x的兄弟结点
-
Case 4
这种情况可以做一些修改,然后结束修正- 设置w的颜色为x父结点的颜色
- x父结点的颜色设置为黑色
- w右孩子的颜色设置为黑色
- 左旋x的父结点
- 使x指向root结点,从而结束修正
由上可知,一旦循环进入Case 1, Case 3,Case 4,就会结束循环。所以一次插入操作最多只会有三次旋转操作(Case 1 -> Case 3 -> Case 4)。
性质维护:
插入过程中维护性质的分析:
1 | Case1 转换后,局部的黑高与之前相同 |
1 | Case2/3 转换后,局部的黑高与之前相同 |
删除过程中维护性质的分析:
需要修正时,被修正结点x以前的父节点肯定为黑色,x替代了x以前父节点的位置
所以这时这个子树(x为根节点)的黑高减少了1
1 | Case1 转换后,ABCDE的黑高都没有变 |
1 | Case2 转换后,以x的父节点c为根节点的子树已经满足红黑树的性质 |
1 | Case3 转换后,ABCDE的黑高都没有变 |
1 | Case4 转换后,以c为根节点子树满足红黑树性质 |
涉及数据结构
点击查看实现