什么是旅行商问题(TSP)?
旅行商问题 (TSP) 是理论计算机科学中的经典组合问题。该问题要求找到图中的最短路径,条件是仅访问所有节点一次并返回出发城市。
问题陈述给出了城市列表以及每个城市之间的距离。
目的: 从出发城市出发,只访问一次其他城市,然后返回出发城市。我们的目标是找到完成往返路线的最短路径。
表中的内容:
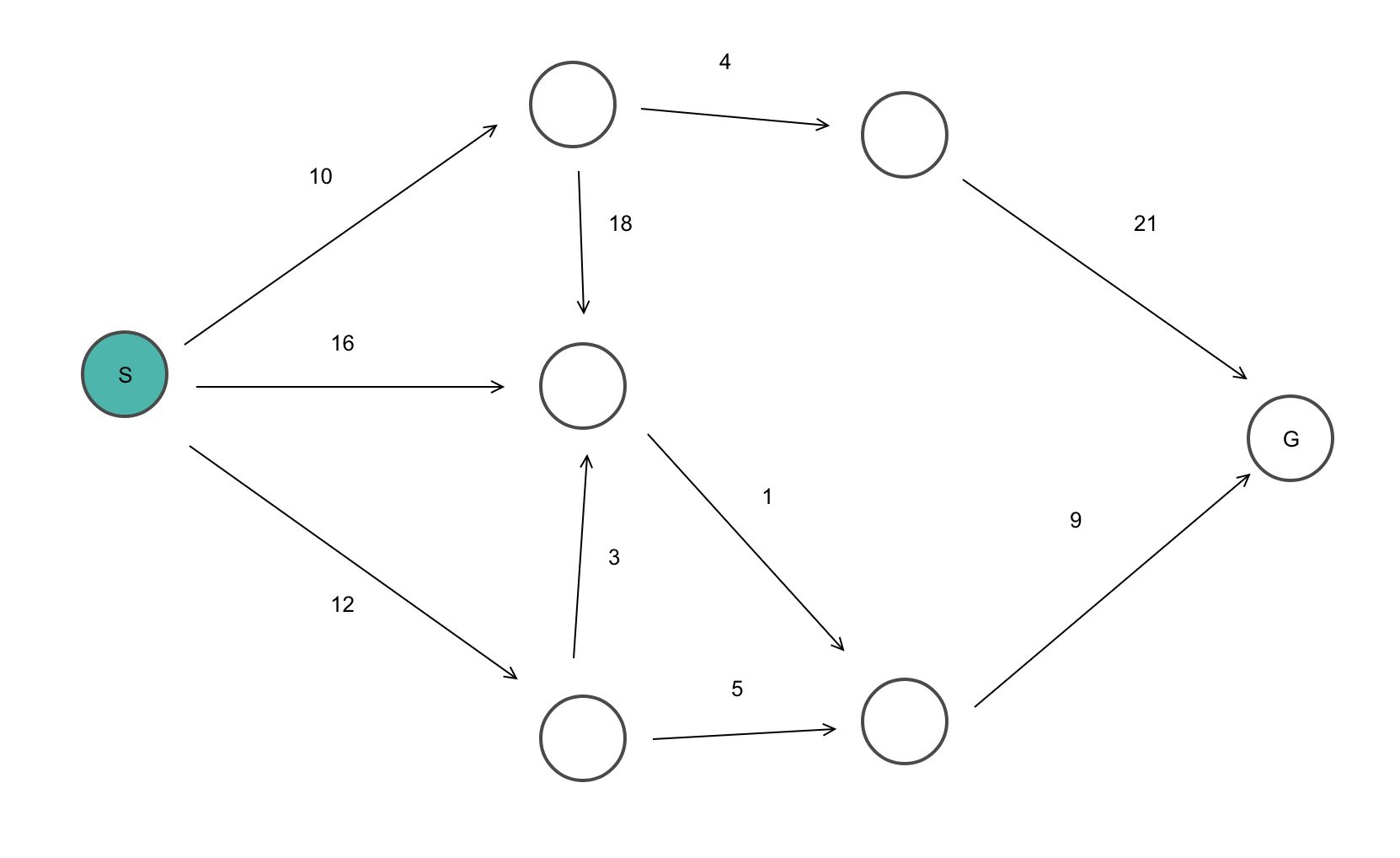
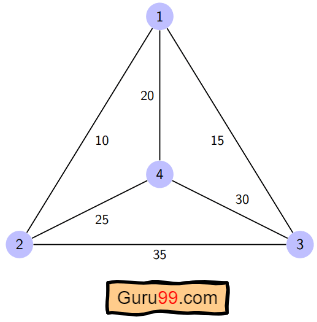
TSP 示例
这里给出了一个图表,其中 1、2、3 和 4 代表城市,与每条边相关的权重代表这些城市之间的距离。
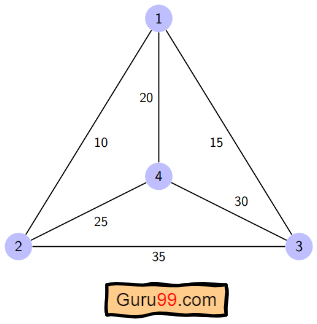
目标是找到从出发城市出发、遍历图表且仅访问其他城市或节点一次并返回出发城市的最短路径。
对于上图,最佳路线是遵循成本最低的路径: 1-2-4-3-1. 这条最短路线的费用为 10+25+30+15 =80
旅行商问题的不同解决方案

旅行商问题 (TSP) 被归类为 NP 难题,因为没有多项式时间算法。随着城市数量的增加,复杂性呈指数级增长。
有多种方法可以解决旅行商问题 (tsp)。一些流行的解决方案是:
蛮力法是一种幼稚的方法 解决旅行商问题的方法。在这种方法中,我们首先计算所有可能的路径,然后进行比较。由 n 个城市组成的图中的路径数为 n! 使用这种蛮力方法解决旅行商问题的计算成本非常高。
分支限界法: 这种方法将问题分解为子问题。解决这些单独的子问题将提供最佳解决方案。
本教程将演示一种动态规划方法,即分支定界法的递归版本,用于解决旅行商问题。
动态编程 是通过分析所有可能的路线来寻求最优解的一种方法。它是解决旅行商问题的精确解决方法之一,它比 贪婪方法 提供近乎最优的解决方案。
该方法的计算复杂度为 O(N^2 * 2^N) 本文后面会讨论这一点。
最近邻法 是一种基于启发式的贪婪方法,我们选择最近的邻居节点。这种方法在计算上比动态方法更便宜。但它不能保证最优解。此方法用于近似最优解。
旅行商问题的算法
我们将使用动态规划方法来解决旅行商问题(TSP)。
在开始算法之前,让我们先熟悉一些术语:
- 图G=(V,E),它是一组顶点和边的集合。
- V 是顶点集。
- E 是边集。
- 顶点通过边连接。
- Dist(i,j)表示两个顶点 i 和 j 之间的非负距离。
假设 S 是城市子集,属于 {1, 2, 3, …, n},其中 1、2、3…n 是城市,i、j 是该子集中的两个城市。现在 cost(i, S, j) 定义为访问 S 中节点的最短路径的长度,该路径恰好一次以 i 和 j 为起点和终点。
例如,cost (1, {2, 3, 4}, 1) 表示最短路径的长度,其中:
- 出发城市为 1
- 城市 2、3 和 4 仅访问过一次
- 终点是 1
动态规划算法如下:
- 设定 cost(i, , i) = 0,这意味着我们从 i 开始和结束,并且成本为 0。
- 当 |S| > 1 时,我们定义 cost(i, S, 1) = ∝ 其中 i !=1 。因为最初我们不知道从城市 i 经过其他城市到达城市 1 的确切成本。
- 现在,我们需要从 1 开始并完成游览。我们需要以这种方式选择下一个城市-
cost(i, S, j)=min cost (i, S−{i}, j)+dist(i,j),其中 i∈S 且 i≠j
对于给定的图,邻接矩阵如下:
| 距离(i,j) | 1 | 2 | 3 | 4 |
| 1 | 0 | 10 | 15 | 20 |
| 2 | 10 | 0 | 35 | 25 |
| 3 | 15 | 35 | 0 | 30 |
| 4 | 20 | 25 | 30 | 0 |
让我们看看我们的算法是如何工作的:
步骤1) 我们考虑从城市 1 开始我们的旅程,游览其他城市一次,然后返回城市 1。
步骤2) S 是城市的子集。根据我们的算法,对于所有 |S| > 1,我们将设置距离 cost(i, S, 1) = ∝。这里 cost(i, S, j) 表示我们从城市 i 出发,访问 S 的城市一次,现在我们到达城市 j。我们将此路径成本设置为无穷大,因为我们还不知道距离。因此值将如下所示:
Cost (2, {3, 4}, 1) = ∝ ;符号表示我们从城市 2 出发,经过城市 3、4,到达城市 1。路径成本为无穷大。类似地,
成本(3,{2,4},1)=∝
成本(4,{2,3},1)=∝
步骤3) 现在,对于 S 的所有子集,我们需要找到以下内容:
cost(i, S, j)=min cost (i, S−{i}, j)+dist(i,j),其中 j∈S 且 i≠j
这意味着从 i 出发,经过城市子集一次,然后返回城市 j 的最低成本路径。考虑到旅程从城市 1 开始,最佳路径成本将为 = cost(1, {其他城市}, 1)。
让我们看看如何实现这个目标:
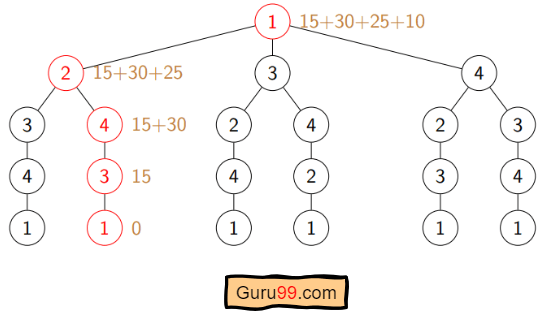
现在 S = {1, 2, 3, 4}。有四个元素。因此子集的数量将为 2^4 或 16。这些子集是: **1)|S| = 空:** {φ} **2)|S| = 1:** {{1}, {2}, {3}, {4}} **3)|S| = 2:** {{1, 2}, {1, 3}, {1, 4}, {2, 3}, {2, 4}, {3, 4}} **4)|S| = 3:** {{1, 2, 3}, {1, 2, 4}, {2, 3, 4}, {1, 3, 4}} **5)|S| = 4:** {{1, 2, 3, 4}}由于我们从 1 开始,因此我们可以丢弃包含城市 1 的子集。
算法计算:
1)|S| = Φ:
成本(2,Φ,1)=距离(2,1)= 10
成本(3,Φ,1)=距离(3,1)= 15
成本(4,Φ,1)=距离(4,1)= 20
2)|S| = 1:
成本(2,{3},1)= 距离(2,3)+ 成本(3,Φ,1)= 35+15 = 50
成本(2,{4},1)= 距离(2,4)+ 成本(4,Φ,1)= 25+20 = 45
成本(3,{2},1)= 距离(3,2)+ 成本(2,Φ,1)= 35+10 = 45
成本(3,{4},1)= 距离(3,4)+ 成本(4,Φ,1)= 30+20 = 50
成本(4,{2},1)= 距离(4,2)+ 成本(2,Φ,1)= 25+10 = 35
成本(4,{3},1)= 距离(4,3)+ 成本(3,Φ,1)= 30+15 = 45
3)|S| = 2:
成本(2,{3,4},1)=最小值[dist[2,3]+成本(3,{4},1)=35+50=85,
dist[2,4]+Cost(4,{3},1) = 25+45 = 70 ] = 70
成本(3,{2,4},1)=最小值[dist[3,2]+成本(2,{4},1)=35+45=80,
dist[3,4]+Cost(4,{2},1) = 30+35 = 65 ] = 65
成本(4,{2,3},1)=最小值[dist[4,2]+成本(2,{3},1)= 25+50 = 75
dist[4,3]+Cost(3,{2},1) = 30+45 = 75 ] = 75
4)|S| = 3:
成本(1,{2,3,4},1)=最小值[dist[1,2]+成本(2,{3,4},1)=10+70=80
dist[1,3]+Cost(3,{2,4},1) = 15+65 = 80
dist[1,4]+Cost(4,{2,3},1) = 20+75 = 95 ] = 80
所以最佳解决方案是 1-2-4-3-1
伪代码
1 | Algorithm: Traveling-Salesman-Problem |
在 C/ 中实现C++
以下是实现 C++:
1 | #include <bits/stdc++.h> |
输出:
1 | 80 |
在实施 Python
1 | from sys import maxsize |
输出:
1 | 80 |
TSP 的学术解决方案
计算机科学家花了数年时间寻找一种改进的多项式时间算法来解决旅行商问题。到目前为止,这个问题仍然是 NP 难题。
尽管近年来已经发表了以下一些解决方案,在一定程度上降低了复杂性:
- 经典的对称TSP问题采用零后缀法求解。
- 基于生物地理学的优化算法是基于迁移策略来解决可规划为TSP的优化问题。
- 多目标进化算法是基于NSGA-II设计用于解决多TSP问题的。
- 多智能体系统用固定的资源解决N个城市的TSP问题。
旅行商问题的应用
旅行商问题 (TSP) 以其最纯粹的形式和修改形式应用于现实世界。其中一些是:
- 规划、物流和制造微芯片:芯片插入问题自然出现在微芯片行业中。这些问题可以规划为旅行商问题。
- DNA测序:旅行商问题的轻微修改可用于 DNA 测序。这里,城市代表 DNA 片段,距离代表两个 DNA 片段之间的相似性度量。
- 天文学:天文学家利用旅行商问题是尽量减少观察各种来源所花费的时间。
- 最优控制问题:旅行商问题公式可应用于最优控制问题。可能还会添加其他一些约束。
TSP 的复杂性分析
-
时间复杂度: 共有2个N 每个节点有 子问题。因此子问题总数为 N*2N。每个子问题都需要线性时间来解决。如果未指定原节点,我们必须对 N 个节点运行循环。
因此,最佳解决方案的总时间复杂度将是节点数 * 子问题数 * 解决每个子问题的时间。时间复杂度可以定义为 O(N2 *2^N)。
-
空间复杂度: 动态规划方法使用内存来存储 C(S, i),其中 S 是顶点集的子集。总共有 2N 每个节点有 2 个子集。因此空间复杂度为 O(XNUMX^N)。
接下来,您将了解 埃拉托斯特尼筛法