Java最早是由SUN公司(已被Oracle收购)的詹姆斯·高斯林 (高司令,人称Java之父)在上个世纪90年代初开发的一种编程语言,最初被命名为Oak,目标是针对小型家电设备的嵌入式应用,结果市场没啥反响。谁料到互联网的崛起,让Oak重新焕发了生机,于是SUN公司改造了Oak,在1995年以Java的名称正式发布,原因是Oak已经被人注册了,因此SUN注册了Java这个商标。随着互联网的高速发展,Java逐渐成为最重要的网络编程语言。
Java介于编译型语言和解释型语言之间。编译型语言如C、C++,代码是直接编译成机器码执行,但是不同的平台(x86、ARM等)CPU的指令集不同,因此,需要编译出每一种平台的对应机器码。解释型语言如Python、Ruby没有这个问题,可以由解释器直接加载源码然后运行,代价是运行效率太低。而Java是将代码编译成一种“字节码”,它类似于抽象的CPU指令,然后,针对不同平台编写虚拟机,不同平台的虚拟机负责加载字节码并执行,这样就实现了“一次编写,到处运行”的效果。当然,这是针对Java开发者而言。对于虚拟机,需要为每个平台分别开发。为了保证不同平台、不同公司开发的虚拟机都能正确执行Java字节码,SUN公司制定了一系列的Java虚拟机规范。从实践的角度看,JVM的兼容性做得非常好,低版本的Java字节码完全可以正常运行在高版本的JVM上。
随着Java的发展,SUN给Java又分出了三个不同版本:
Java SE:Standard Edition
Java EE:Enterprise Edition
Java ME:Micro Edition
这三者之间有啥关系呢?
1 2 3 4 5 6 7 8 9 ┌───────────────────────────┐ │Java EE │ │ ┌────────────────────┐ │ │ │Java SE │ │ │ │ ┌─────────────┐ │ │ │ │ │ Java ME │ │ │ │ │ └─────────────┘ │ │ │ └────────────────────┘ │ └───────────────────────────┘
简单来说,Java SE就是标准版,包含标准的JVM和标准库,而Java EE是企业版,它只是在Java SE的基础上加上了大量的API和库,以便方便开发Web应用、数据库、消息服务等,Java EE的应用使用的虚拟机和Java SE完全相同。
Java ME就和Java SE不同,它是一个针对嵌入式设备的“瘦身版”,Java SE的标准库无法在Java ME上使用,Java ME的虚拟机也是“瘦身版”。
毫无疑问,Java SE是整个Java平台的核心,而Java EE是进一步学习Web应用所必须的。我们熟悉的Spring等框架都是Java EE开源生态系统的一部分。不幸的是,Java ME从来没有真正流行起来,反而是Android开发成为了移动平台的标准之一,因此,没有特殊需求,不建议学习Java ME。
因此我们推荐的Java学习路线图如下:
首先要学习Java SE,掌握Java语言本身、Java核心开发技术以及Java标准库的使用;
如果继续学习Java EE,那么Spring框架、数据库开发、分布式架构就是需要学习的;
如果要学习大数据开发,那么Hadoop、Spark、Flink这些大数据平台就是需要学习的,他们都基于Java或Scala开发;
如果想要学习移动开发,那么就深入Android平台,掌握Android App开发。
无论怎么选择,Java SE的核心技术是基础,这个教程的目的就是让你完全精通Java SE并掌握Java EE!
Java版本
从1996年发布1.0版本开始,到目前为止,最新的Java版本是Java 21:
时间
版本
1996
1.0
1997
1.1
1998
1.2
2000
1.3
2002
1.4
2004
1.5 / 5.0
2005
1.6 / 6.0
2011
1.7 / 7.0
2014
1.8 / 8.0
2017/9
1.9 / 9.0
2018/3
10
2018/9
11
2019/3
12
2019/9
13
2020/3
14
2020/9
15
2021/3
16
2021/9
17
2022/3
18
2022/9
19
2023/3
20
2023/9
21
2024/3
22
2024/9
23
本教程使用的Java版本是最新版的Java 23 。
名词解释
初学者学Java,经常听到JDK、JRE这些名词,它们到底是啥?
JDK:Java Development Kit
JRE:Java Runtime Environment
简单地说,JRE就是运行Java字节码的虚拟机。但是,如果只有Java源码,要编译成Java字节码,就需要JDK,因为JDK除了包含JRE,还提供了编译器、调试器等开发工具。
二者关系如下:
1 2 3 4 5 6 7 8 9 10 11 ┌─ ┌──────────────────────────────────┐ │ │ Compiler, debugger, etc. │ │ └──────────────────────────────────┘ JDK ┌─ ┌──────────────────────────────────┐ │ │ │ │ │ JRE │ JVM + Runtime Library │ │ │ │ │ └─ └─ └──────────────────────────────────┘ ┌───────┐┌───────┐┌───────┐┌───────┐ │Windows││ Linux ││ macOS ││others │ └───────┘└───────┘└───────┘└───────┘
要学习Java开发,当然需要安装JDK了。
那JSR、JCP……又是啥?
JSR规范:Java Specification Request
JCP组织:Java Community Process
为了保证Java语言的规范性,SUN公司搞了一个JSR规范,凡是想给Java平台加一个功能,比如说访问数据库的功能,大家要先创建一个JSR规范,定义好接口,这样,各个数据库厂商都按照规范写出Java驱动程序,开发者就不用担心自己写的数据库代码在MySQL上能跑,却不能跑在PostgreSQL上。
所以JSR是一系列的规范,从JVM的内存模型到Web程序接口,全部都标准化了。而负责审核JSR的组织就是JCP。
一个JSR规范发布时,为了让大家有个参考,还要同时发布一个“参考实现”,以及一个“兼容性测试套件”:
RI:Reference Implementation
TCK:Technology Compatibility Kit
比如有人提议要搞一个基于Java开发的消息服务器,这个提议很好啊,但是光有提议还不行,得贴出真正能跑的代码,这就是RI。如果有其他人也想开发这样一个消息服务器,如何保证这些消息服务器对开发者来说接口、功能都是相同的?所以还得提供TCK。
通常来说,RI只是一个“能跑”的正确的代码,它不追求速度,所以,如果真正要选择一个Java的消息服务器,一般是没人用RI的,大家都会选择一个有竞争力的商用或开源产品。
参考:Java消息服务JMS的JSR:https://jcp.org/en/jsr/detail?id=914
要开始学习Java编程,我们需要首先搭建开发环境。
本节我们介绍如何安装JDK,在命令行编译Java程序,以及如何使用IDE来开发Java。
安装JDK
因为Java程序必须运行在JVM之上,所以,我们第一件事情就是安装JDK。
搜索JDK 23,确保从Oracle的官网 下载最新的稳定版JDK:
1 2 3 4 5 6 7 8 Java SE Development Kit 23 downloads Linux macOS Windows ------- x64 Compressed Archive Download x64 Installer Download x64 MSI Installer Download
选择合适的操作系统与安装包,找到Java SE 23的下载链接Download,下载安装即可。Windows优先选x64 MSI Installer,Linux和macOS要根据自己电脑的CPU是ARM还是x86来选择合适的安装包。
设置环境变量
安装完JDK后,需要设置一个JAVA_HOME的环境变量,它指向JDK的安装目录。在Windows下,它是安装目录,类似:
1 C:\Program Files\Java\jdk-23
在macOS下,它在~/.bash_profile或~/.zprofile里,它是:
1 export JAVA_HOME=`/usr/libexec/java_home -v 23`
然后,把JAVA_HOME的bin目录附加到系统环境变量PATH上。在Windows下,它长这样:
1 Path=%JAVA_HOME%\bin;<现有的其他路径>
在macOS下,它在~/.bash_profile或~/.zprofile里,长这样:
1 export PATH=$JAVA_HOME/bin:$PATH
把JAVA_HOME的bin目录添加到PATH中是为了在任意文件夹下都可以运行java。打开PowerShell窗口,输入命令java -version,如果一切正常,你会看到如下输出:
1 2 3 4 5 6 7 8 9 10 11 12 ┌─────────────────────────────────────────────────────────┐ │Windows PowerShell - □ x │ ├─────────────────────────────────────────────────────────┤ │Windows PowerShell │ │Copyright (C) Microsoft Corporation. All rights reserved.│ │ │ │PS C:\Users\liaoxuefeng> java -version │ │java version "23" ... │ │Java(TM) SE Runtime Environment │ │Java HotSpot(TM) 64-Bit Server VM │ │ │ └─────────────────────────────────────────────────────────┘
如果你看到的版本号不是23,而是15、1.8之类,说明系统存在多个JDK,且默认JDK不是JDK 23,需要把JDK 23提到PATH前面。
如果你得到一个错误输出:“无法将“java”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。”:
1 2 3 4 5 6 7 8 9 10 11 12 ┌─────────────────────────────────────────────────────────┐ │Windows PowerShell - □ x │ ├─────────────────────────────────────────────────────────┤ │Windows PowerShell │ │Copyright (C) Microsoft Corporation. All rights reserved.│ │ │ │PS C:\Users\liaoxuefeng> java -version │ │java : The term 'java' is not recognized as ... │ │... │ │ + FullyQualifiedErrorId : CommandNotFoundException │ │ │ └─────────────────────────────────────────────────────────┘
这是因为系统无法找到Java虚拟机的程序java.exe,需要检查JAVA_HOME和PATH的配置。
可以参考如何设置或更改PATH系统变量 。
JDK
细心的童鞋还可以在JAVA_HOME的bin目录下找到很多可执行文件:
java:这个可执行程序其实就是JVM,运行Java程序,就是启动JVM,然后让JVM执行指定的编译后的代码;
javac:这是Java的编译器,它用于把Java源码文件(以.java后缀结尾)编译为Java字节码文件(以.class后缀结尾);
jar:用于把一组.class文件打包成一个.jar文件,便于发布;
javadoc:用于从Java源码中自动提取注释并生成文档;
jdb:Java调试器,用于开发阶段的运行调试。
我们来编写第一个Java程序。
打开文本编辑器,输入以下代码:
1 2 3 4 5 public class Hello { public static void main (String[] args) { System.out.println("Hello, world!" ); } }
在一个Java程序中,你总能找到一个类似:
1 2 3 public class Hello { ... }
的定义,这个定义被称为class(类),这里的类名是Hello,大小写敏感,class用来定义一个类,public表示这个类是公开的,public、class都是Java的关键字,必须小写,Hello是类的名字,按照习惯,首字母H要大写。而花括号{}中间则是类的定义。
注意到类的定义中,我们定义了一个名为main的方法:
1 2 3 public static void main (String[] args) { ... }
方法是可执行的代码块,一个方法除了方法名main,还有用()括起来的方法参数,这里的main方法有一个参数,参数类型是String[],参数名是args,public、static用来修饰方法,这里表示它是一个公开的静态方法,void是方法的返回类型,而花括号{}中间的就是方法的代码。
方法的代码每一行用;结束,这里只有一行代码,就是:
1 System.out.println("Hello, world!" );
它用来打印一个字符串到屏幕上。
Java规定,某个类定义的public static void main(String[] args)是Java程序的固定入口方法,因此,Java程序总是从main方法开始执行。
注意到Java源码的缩进不是必须的,但是用缩进后,格式好看,很容易看出代码块的开始和结束,缩进一般是4个空格或者一个tab。
最后,当我们把代码保存为文件时,文件名必须是Hello.java,而且文件名也要注意大小写,因为要和我们定义的类名Hello完全保持一致。
如何运行Java程序
Java源码本质上是一个文本文件,我们需要先用javac把Hello.java编译成字节码文件Hello.class,然后,用java命令执行这个字节码文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌──────────────────┐ │ Hello.java │◀── source code └──────────────────┘ │ compile ▼ ┌──────────────────┐ │ Hello.class │◀── byte code └──────────────────┘ │ execute ▼ ┌──────────────────┐ │ Run on JVM │ └──────────────────┘
因此,可执行文件javac是编译器,而可执行文件java就是虚拟机。
第一步,在保存Hello.java的目录下执行命令javac Hello.java:
如果源代码无误,上述命令不会有任何输出,而当前目录下会产生一个Hello.class文件:
1 2 $ ls Hello.class Hello.java
第二步,执行Hello.class,使用命令java Hello(注意不是java Hello.class):
1 2 $ java Hello Hello, world!
注意:给虚拟机传递的参数Hello是我们定义的类名,虚拟机自动查找对应的class文件并执行。
如果执行java Hello报错:
1 2 3 $ java Hello Error: Could not find or load main class Hello Caused by: java.lang.ClassNotFoundException: Hello
出现ClassNotFoundException信息,说明在当前目录下并没有Hello.class这个文件,请切换到Hello.class的目录,然后执行java Hello。
有一些童鞋可能知道,直接运行java Hello.java也是可以的:
1 2 $ java Hello.java Hello, world!
这是从Java 11开始新增的一个功能,它可以直接运行一个单文件源码!
需要注意的是,在实际项目中,单个不依赖第三方库的Java源码是非常罕见的,所以,绝大多数情况下,我们无法直接运行一个Java源码文件,原因是它需要依赖其他的库。
小结
一个Java源码只能定义一个public类型的class,并且class名称和文件名要完全一致;
使用javac可以将.java源码编译成.class字节码;
使用java可以运行一个已编译的Java程序,参数是类名。
IDE是集成开发环境:Integrated Development Environment的缩写。
使用IDE的好处在于,可以把编写代码、组织项目、编译、运行、调试等放到一个环境中运行,能极大地提高开发效率。
IDE提升开发效率主要靠以下几点:
编辑器的自动提示,可以大大提高敲代码的速度;
代码修改后可以自动重新编译,并直接运行;
可以方便地进行断点调试。
目前,流行的用于Java开发的IDE有:
Eclipse
Eclipse 是由IBM开发并捐赠给开源社区的一个IDE,也是目前应用最广泛的IDE。Eclipse的特点是它本身是Java开发的,并且基于插件结构,即使是对Java开发的支持也是通过插件JDT实现的。
除了用于Java开发,Eclipse配合插件也可以作为C/C++开发环境、PHP开发环境、Rust开发环境等。
IntelliJ Idea
IntelliJ Idea 是由JetBrains公司开发的一个功能强大的IDE,分为免费版和商用付费版。JetBrains公司的IDE平台也是基于IDE平台+语言插件的模式,支持Python开发环境、Ruby开发环境、PHP开发环境等,这些开发环境也分为免费版和付费版。
NetBeans
NetBeans 是最早由SUN开发的开源IDE,由于使用人数较少,目前已不再流行。
使用Eclipse
你可以使用任何IDE进行Java学习和开发。我们不讨论任何关于IDE的优劣,本教程使用Eclipse作为开发演示环境,原因在于:
完全免费使用;
所有功能完全满足Java开发需求。
安装Eclipse
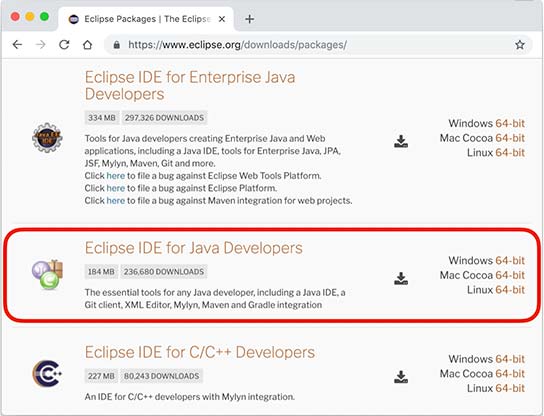
Eclipse的发行版提供了预打包的开发环境,包括Java、JavaEE、C++、PHP、Rust等。从这里 下载:
我们需要下载的版本是Eclipse IDE for Java Developers:
根据操作系统是Windows、Mac还是Linux,从右边选择对应的下载链接。
注意
教程从头到尾并不需要用到Enterprise Java的功能,所以不需要下载Eclipse IDE for Enterprise Java Developers
设置Eclipse
下载并安装完成后,我们启动Eclipse,对IDE环境做一个基本设置:
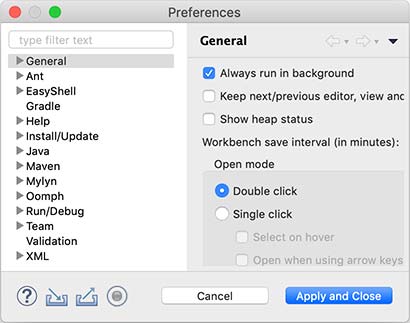
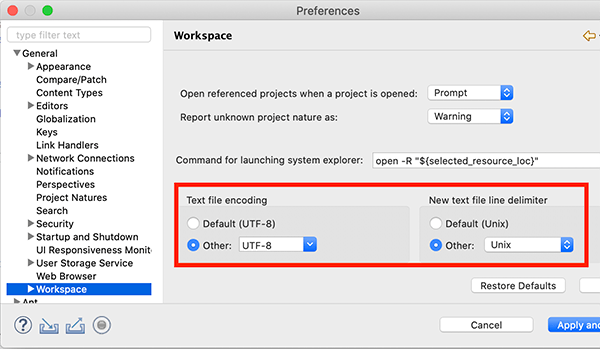
选择菜单“Eclipse/Window”-“Preferences”,打开配置对话框:
我们需要调整以下设置项:
General > Editors > Text Editors
钩上“Show line numbers”,这样编辑器会显示行号;
General > Workspace
钩上“Refresh using native hooks or polling”,这样Eclipse会自动刷新文件夹的改动;
对于“Text file encoding”,如果Default不是UTF-8,一定要改为“Other:UTF-8”,所有文本文件均使用UTF-8编码;
对于“New text file line delimiter”,建议使用Unix,即换行符使用\n而不是Windows的\r\n。
Java > Compiler
将“Compiler compliance level”设置为20,本教程的所有代码均使用Java 20的语法,并且编译到Java 20的版本。
去掉“Use default compliance settings”并钩上“Enable preview features for Java 20”,这样我们就可以使用Java 20的预览功能。
注意
如果Compiler compliance level没有22这个选项,请更新到最新版Eclipse。如果更新后还是没有22,打开Help - Eclipse Marketplace,搜索Java 22 Support安装后重启即可。
Java > Installed JREs
在Installed JREs中应该看到Java SE 20,如果还有其他的JRE,可以删除,以确保Java SE 20是默认的JRE。
Eclipse IDE结构
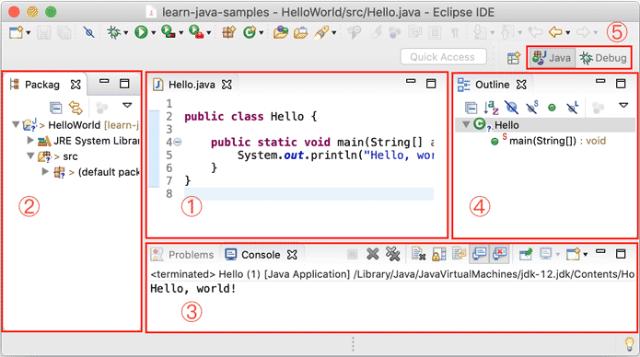
打开Eclipse后,整个IDE由若干个区域组成:
中间可编辑的文本区(见1)是编辑器,用于编辑源码;
分布在左右和下方的是视图:
Package Exploroer(见2)是Java项目的视图
Console(见3)是命令行输出视图
Outline(见4)是当前正在编辑的Java源码的结构视图
视图可以任意组合,然后把一组视图定义成一个Perspective(见5),Eclipse预定义了Java、Debug等几个Perspective,用于快速切换。
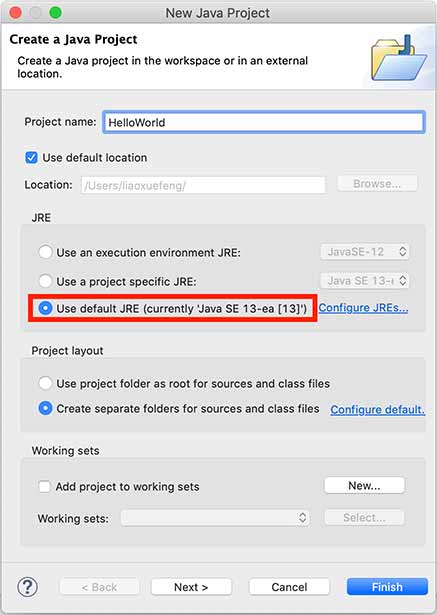
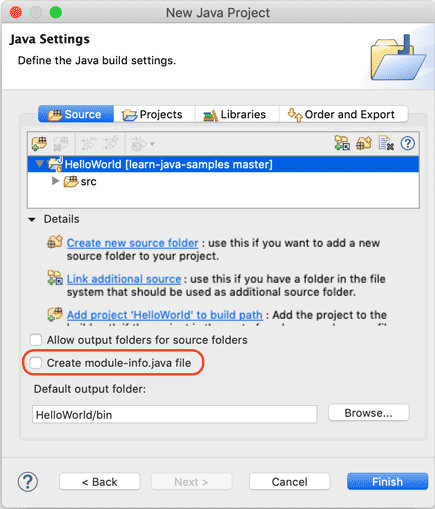
新建Java项目
在Eclipse菜单选择“File”-“New”-“Java Project”,填入HelloWorld,JRE选择Java SE 22:
暂时不要勾选“Create module-info.java file”,因为模块化机制我们后面才会讲到:
点击“Finish”就成功创建了一个名为HelloWorld的Java工程。
新建Java文件并运行
展开HelloWorld工程,选中源码目录src,点击右键,在弹出菜单中选择“New”-“Class”:
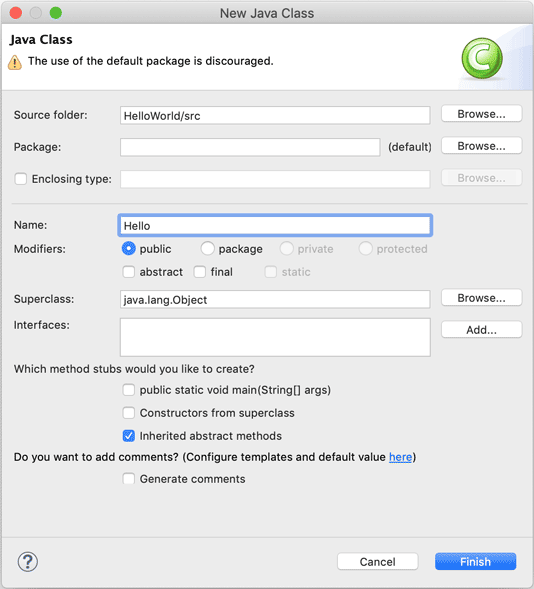
在弹出的对话框中,Name一栏填入Hello:
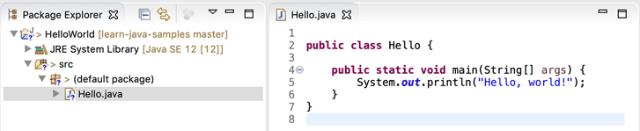
点击”Finish“,就自动在src目录下创建了一个名为Hello.java的源文件。我们双击打开这个源文件,填上代码:
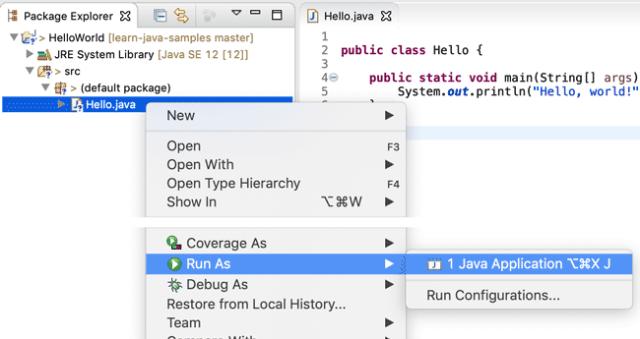
保存,然后选中文件Hello.java,点击右键,在弹出的菜单中选中“Run As…”-“Java Application”:
在Console窗口中就可以看到运行结果:
如果没有在主界面中看到Console窗口,请选中菜单“Window”-“Show View”-“Console”,即可显示。
我们先剖析一个完整的Java程序,它的基本结构是什么:
1 2 3 4 5 6 7 8 9 10 11 12 public class Hello { public static void main (String[] args) { System.out.println("Hello, world!" ); } }
因为Java是面向对象的语言,一个程序的基本单位就是class,class是关键字,这里定义的class名字就是Hello:
1 2 3 public class Hello { }
类名要求:
类名必须以英文字母开头,后接字母,数字和下划线的组合
习惯以大写字母开头
要注意遵守命名习惯,好的类命名:
不好的类命名:
hello
Good123
Note_Book
_World
注意到public是访问修饰符,表示该class是公开的。
不写public,也能正确编译,但是这个类将无法从命令行执行。
在class内部,可以定义若干方法(method):
1 2 3 4 5 public class Hello { public static void main (String[] args) { } }
方法定义了一组执行语句,方法内部的代码将会被依次顺序执行。
这里的方法名是main,返回值是void,表示没有任何返回值。
我们注意到public除了可以修饰class外,也可以修饰方法。而关键字static是另一个修饰符,它表示静态方法,后面我们会讲解方法的类型,目前,我们只需要知道,Java入口程序规定的方法必须是静态方法,方法名必须为main,括号内的参数必须是String数组。
方法名也有命名规则,命名和class一样,但是首字母小写:
好的方法命名:
不好的方法命名:
Main
good123
good_morning
_playVR
在方法内部,语句才是真正的执行代码。Java的每一行语句必须以分号结束:
1 2 3 4 5 public class Hello { public static void main (String[] args) { System.out.println("Hello, world!" ); } }
在Java程序中,注释是一种给人阅读的文本,不是程序的一部分,所以编译器会自动忽略注释。
Java有3种注释,第一种是单行注释,以双斜线开头,直到这一行的结尾结束:
而多行注释以/*星号开头,以*/结束,可以有多行:
还有一种特殊的多行注释,以/**开头,以*/结束,如果有多行,每行通常以星号开头:
1 2 3 4 5 6 7 8 9 10 public class Hello { public static void main (String[] args) { System.out.println("Hello, world!" ); } }
这种特殊的多行注释需要写在类和方法的定义处,可以用于自动创建文档。
Java程序对格式没有明确的要求,多几个空格或者回车不影响程序的正确性,但是我们要养成良好的编程习惯,注意遵守Java社区约定的编码格式。
那约定的编码格式有哪些要求呢?其实我们在前面介绍的Eclipse IDE提供了快捷键Ctrl+Shift+F(macOS是⌘+⇧+F)帮助我们快速格式化代码的功能,Eclipse就是按照约定的编码格式对代码进行格式化的,所以只需要看看格式化后的代码长啥样就行了。具体的代码格式要求可以在Eclipse的设置中Java-Code Style查看。
变量
什么是变量?
变量就是初中数学的代数的概念,例如一个简单的方程,x,y都是变量:
在Java中,变量分为两种:基本类型的变量和引用类型的变量。
我们先讨论基本类型的变量。
在Java中,变量必须先定义后使用,在定义变量的时候,可以给它一个初始值。例如:
上述语句定义了一个整型int类型的变量,名称为x,初始值为1。
不写初始值,就相当于给它指定了默认值。默认值总是0。
来看一个完整的定义变量,然后打印变量值的例子:
1 2 3 4 5 6 7 public class Main { public static void main (String[] args) { int x = 100 ; System.out.println(x); } }
变量的一个重要特点是可以重新赋值。例如,对变量x,先赋值100,再赋值200,观察两次打印的结果:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int x = 100 ; System.out.println(x); x = 200 ; System.out.println(x); } }
注意到第一次定义变量x的时候,需要指定变量类型int,因此使用语句int x = 100;。而第二次重新赋值的时候,变量x已经存在了,不能再重复定义,因此不能指定变量类型int,必须使用语句x = 200;。
变量不但可以重新赋值,还可以赋值给其他变量。让我们来看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Main { public static void main (String[] args) { int n = 100 ; System.out.println("n = " + n); n = 200 ; System.out.println("n = " + n); int x = n; System.out.println("x = " + x); x = x + 100 ; System.out.println("x = " + x); System.out.println("n = " + n); } }
我们一行一行地分析代码执行流程:
执行int n = 100;,该语句定义了变量n,同时赋值为100,因此,JVM在内存中为变量n分配一个“存储单元”,填入值100:
1 2 3 4 5 6 n │ ▼ ┌───┬───┬───┬───┬───┬───┬───┐ │ │100│ │ │ │ │ │ └───┴───┴───┴───┴───┴───┴───┘
执行n = 200;时,JVM把200写入变量n的存储单元,因此,原有的值被覆盖,现在n的值为200:
1 2 3 4 5 6 n │ ▼ ┌───┬───┬───┬───┬───┬───┬───┐ │ │200│ │ │ │ │ │ └───┴───┴───┴───┴───┴───┴───┘
执行int x = n;时,定义了一个新的变量x,同时对x赋值,因此,JVM需要新分配 一个存储单元给变量x,并写入和变量n一样的值,结果是变量x的值也变为200:
1 2 3 4 5 6 n x │ │ ▼ ▼ ┌───┬───┬───┬───┬───┬───┬───┐ │ │200│ │ │200│ │ │ └───┴───┴───┴───┴───┴───┴───┘
执行x = x + 100;时,JVM首先计算等式右边的值x + 100,结果为300(因为此刻x的值为200),然后,将结果300写入x的存储单元,因此,变量x最终的值变为300:
1 2 3 4 5 6 n x │ │ ▼ ▼ ┌───┬───┬───┬───┬───┬───┬───┐ │ │200│ │ │300│ │ │ └───┴───┴───┴───┴───┴───┴───┘
可见,变量可以反复赋值。注意,等号=是赋值语句,不是数学意义上的相等,否则无法解释x = x + 100。
基本数据类型
基本数据类型是CPU可以直接进行运算的类型。Java定义了以下几种基本数据类型:
整数类型:byte,short,int,long
浮点数类型:float,double
字符类型:char
布尔类型:boolean
Java定义的这些基本数据类型有什么区别呢?要了解这些区别,我们就必须简单了解一下计算机内存的基本结构。
计算机内存的最小存储单元是字节(byte),一个字节就是一个8位二进制数,即8个bit。它的二进制表示范围从00000000~11111111,换算成十进制是0~255,换算成十六进制是00~ff。
内存单元从0开始编号,称为内存地址。每个内存单元可以看作一间房间,内存地址就是门牌号。
1 2 3 4 0 1 2 3 4 5 6 ... ┌───┬───┬───┬───┬───┬───┬───┐ │ │ │ │ │ │ │ │... └───┴───┴───┴───┴───┴───┴───┘
一个字节是1byte,1024字节是1K,1024K是1M,1024M是1G,1024G是1T。一个拥有4T内存的计算机的字节数量就是:
1 2 3 4 5 4T = 4 x 1024G = 4 x 1024 x 1024M = 4 x 1024 x 1024 x 1024K = 4 x 1024 x 1024 x 1024 x 1024 = 4398046511104
不同的数据类型占用的字节数不一样。我们看一下Java基本数据类型占用的字节数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ┌───┐ byte │ │ └───┘ ┌───┬───┐ short │ │ │ └───┴───┘ ┌───┬───┬───┬───┐ int │ │ │ │ │ └───┴───┴───┴───┘ ┌───┬───┬───┬───┬───┬───┬───┬───┐ long │ │ │ │ │ │ │ │ │ └───┴───┴───┴───┴───┴───┴───┴───┘ ┌───┬───┬───┬───┐ float │ │ │ │ │ └───┴───┴───┴───┘ ┌───┬───┬───┬───┬───┬───┬───┬───┐ double │ │ │ │ │ │ │ │ │ └───┴───┴───┴───┴───┴───┴───┴───┘ ┌───┬───┐ char │ │ │ └───┴───┘
byte恰好就是一个字节,而long和double需要8个字节。
整型
对于整型类型,Java只定义了带符号的整型,因此,最高位的bit表示符号位(0表示正数,1表示负数)。各种整型能表示的最大范围如下:
byte:-128 ~ 127
short: -32768 ~ 32767
int: -2147483648 ~ 2147483647
long: -9223372036854775808 ~ 9223372036854775807
我们来看定义整型的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Main { public static void main (String[] args) { int i = 2147483647 ; int i2 = -2147483648 ; int i3 = 2_000_000_000 ; int i4 = 0xff0000 ; int i5 = 0b1000000000 ; long n1 = 9000000000000000000L ; long n2 = 900 ; int i6 = 900L ; } }
特别注意:同一个数的不同进制的表示是完全相同的,例如15=0xf=0b1111。
浮点型
浮点类型的数就是小数,因为小数用科学计数法表示的时候,小数点是可以“浮动”的,如1234.5可以表示成12.345x102,也可以表示成1.2345x103,所以称为浮点数。
下面是定义浮点数的例子:
1 2 3 4 5 6 7 float f1 = 3.14f ;float f2 = 3.14e38f ; float f3 = 1.0 ; double d = 1.79e308 ;double d2 = -1.79e308 ;double d3 = 4.9e-324 ;
对于float类型,需要加上f后缀。
浮点数可表示的范围非常大,float类型可最大表示3.4x1038,而double类型可最大表示1.79x10308。
布尔类型
布尔类型boolean只有true和false两个值,布尔类型总是关系运算的计算结果:
1 2 3 4 5 boolean b1 = true ;boolean b2 = false ;boolean isGreater = 5 > 3 ; int age = 12 ;boolean isAdult = age >= 18 ;
Java语言对布尔类型的存储并没有做规定,因为理论上存储布尔类型只需要1 bit,但是通常JVM内部会把boolean表示为4字节整数。
字符类型
字符类型char表示一个字符。Java的char类型除了可表示标准的ASCII外,还可以表示一个Unicode字符:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { char a = 'A' ; char zh = '中' ; System.out.println(a); System.out.println(zh); } }
注意char类型使用单引号',且仅有一个字符,要和双引号"的字符串类型区分开。
引用类型
除了上述基本类型的变量,剩下的都是引用类型。例如,引用类型最常用的就是String字符串:
引用类型的变量类似于C语言的指针,它内部存储一个“地址”,指向某个对象在内存的位置,后续我们介绍类的概念时会详细讨论。
常量
定义变量的时候,如果加上final修饰符,这个变量就变成了常量:
1 2 3 4 final double PI = 3.14 ; double r = 5.0 ;double area = PI * r * r;PI = 300 ;
常量在定义时进行初始化后就不可再次赋值,再次赋值会导致编译错误。
常量的作用是用有意义的变量名来避免魔术数字(Magic number),例如,不要在代码中到处写3.14,而是定义一个常量。如果将来需要提高计算精度,我们只需要在常量的定义处修改,例如,改成3.1416,而不必在所有地方替换3.14。
为了和变量区分开来,根据习惯,常量名通常全部大写 。
var关键字
有些时候,类型的名字太长,写起来比较麻烦。例如:
1 StringBuilder sb = new StringBuilder ();
这个时候,如果想省略变量类型,可以使用var关键字:
1 var sb = new StringBuilder ();
编译器会根据赋值语句自动推断出变量sb的类型是StringBuilder。对编译器来说,语句:
1 var sb = new StringBuilder ();
实际上会自动变成:
1 StringBuilder sb = new StringBuilder ();
因此,使用var定义变量,仅仅是少写了变量类型而已。
变量的作用范围
在Java中,多行语句用{ ... }括起来。很多控制语句,例如条件判断和循环,都以{ ... }作为它们自身的范围,例如:
1 2 3 4 5 6 7 8 9 10 11 if (...) { ... while (...) { ... if (...) { ... } ... } ... }
只要正确地嵌套这些{ ... },编译器就能识别出语句块的开始和结束。而在语句块中定义的变量,它有一个作用域,就是从定义处开始,到语句块结束。超出了作用域引用这些变量,编译器会报错。举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 { ... int i = 0 ; ... { ... int x = 1 ; ... { ... String s = "hello" ; ... } ... String s = "hi" ; ... } ... }
定义变量时,要遵循作用域最小化原则,尽量将变量定义在尽可能小的作用域,并且,不要重复使用变量名。
小结
Java提供了两种变量类型:基本类型和引用类型
基本类型包括整型,浮点型,布尔型,字符型。
变量可重新赋值,等号是赋值语句,不是数学意义的等号。
常量在初始化后不可重新赋值,使用常量便于理解程序意图。
Java的整数运算遵循四则运算规则,可以使用任意嵌套的小括号。四则运算规则和初等数学一致。例如:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int i = (100 + 200 ) * (99 - 88 ); int n = 7 * (5 + (i - 9 )); System.out.println(i); System.out.println(n); } }
整数的数值表示不但是精确的,而且整数运算永远是精确的,即使是除法也是精确的,因为两个整数相除只能得到结果的整数部分:
求余运算使用%:
特别注意:整数的除法对于除数为0时运行时将报错,但编译不会报错。
溢出
要特别注意,整数由于存在范围限制,如果计算结果超出了范围,就会产生溢出,而溢出不会出错 ,却会得到一个奇怪的结果:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int x = 2147483640 ; int y = 15 ; int sum = x + y; System.out.println(sum); } }
要解释上述结果,我们把整数2147483640和15换成二进制做加法:
1 2 3 4 0111 1111 1111 1111 1111 1111 1111 1000 + 0000 0000 0000 0000 0000 0000 0000 1111 ----------------------------------------- 1000 0000 0000 0000 0000 0000 0000 0111
由于最高位计算结果为1,因此,加法结果变成了一个负数。
要解决上面的问题,可以把int换成long类型,由于long可表示的整型范围更大,所以结果就不会溢出:
1 2 3 4 long x = 2147483640 ;long y = 15 ;long sum = x + y;System.out.println(sum);
还有一种简写的运算符,即+=,-=,*=,/=,它们的使用方法如下:
自增/自减
Java还提供了++运算和--运算,它们可以对一个整数进行加1和减1的操作:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int n = 3300 ; n++; n--; int y = 100 + (++n); System.out.println(y); } }
注意++写在前面和后面计算结果是不同的,++n表示先加1再引用n,n++表示先引用n再加1。不建议把++运算混入到常规运算中,容易自己把自己搞懵了。
移位运算
在计算机中,整数总是以二进制的形式表示。例如,int类型的整数7使用4字节表示的二进制如下:
1 00000000 0000000 0000000 00000111
可以对整数进行移位运算。对整数7左移1位将得到整数14,左移两位将得到整数28:
1 2 3 4 5 int n = 7 ; int a = n << 1 ; int b = n << 2 ; int c = n << 28 ; int d = n << 29 ;
左移29位时,由于最高位变成1,因此结果变成了负数。
类似的,对整数28进行右移,结果如下:
1 2 3 4 int n = 7 ; int a = n >> 1 ; int b = n >> 2 ; int c = n >> 3 ;
如果对一个负数进行右移,最高位的1不动,结果仍然是一个负数:
1 2 3 4 5 int n = -536870912 ;int a = n >> 1 ; int b = n >> 2 ; int c = n >> 28 ; int d = n >> 29 ;
还有一种无符号的右移运算,使用>>>,它的特点是不管符号位,右移后高位总是补0,因此,对一个负数进行>>>右移,它会变成正数,原因是最高位的1变成了0:
1 2 3 4 5 int n = -536870912 ;int a = n >>> 1 ; int b = n >>> 2 ; int c = n >>> 29 ; int d = n >>> 31 ;
对byte和short类型进行移位时,会首先转换为int再进行位移。
仔细观察可发现,左移实际上就是不断地×2,右移实际上就是不断地÷2。
位运算
位运算是按位进行与、或、非和异或的运算。我们先来看看针对单个bit的位运算。
与运算的规则是,必须两个数同时为1,结果才为1:
1 2 3 4 n = 0 & 0 ; n = 0 & 1 ; n = 1 & 0 ; n = 1 & 1 ;
或运算的规则是,只要任意一个为1,结果就为1:
1 2 3 4 n = 0 | 0 ; n = 0 | 1 ; n = 1 | 0 ; n = 1 | 1 ;
非运算的规则是,0和1互换:
异或运算的规则是,如果两个数不同,结果为1,否则为0:
1 2 3 4 n = 0 ^ 0 ; n = 0 ^ 1 ; n = 1 ^ 0 ; n = 1 ^ 1 ;
Java没有单个bit的数据类型。在Java中,对两个整数进行位运算,实际上就是按位对齐,然后依次对每一位进行运算。例如:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int i = 167776589 ; int n = 167776512 ; System.out.println(i & n); } }
上述按位与运算实际上可以看作两个整数表示的IP地址10.0.17.77和10.0.17.0,通过与运算,可以快速判断一个IP是否在给定的网段内。
运算优先级
在Java的计算表达式中,运算优先级从高到低依次是:
()! ~ ++ --* / %+ -<< >> >>>&|+= -= *= /=
记不住也没关系,只需要加括号就可以保证运算的优先级正确。
类型自动提升与强制转型
在运算过程中,如果参与运算的两个数类型不一致,那么计算结果为较大类型的整型。例如,short和int计算,结果总是int,原因是short首先自动被转型为int:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { short s = 1234 ; int i = 123456 ; int x = s + i; short y = s + i; } }
也可以将结果强制转型,即将大范围的整数转型为小范围的整数。强制转型使用(类型),例如,将int强制转型为short:
1 2 int i = 12345 ;short s = (short ) i;
要注意,超出范围的强制转型会得到错误的结果,原因是转型时,int的两个高位字节直接被扔掉,仅保留了低位的两个字节:
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { int i1 = 1234567 ; short s1 = (short ) i1; System.out.println(s1); int i2 = 12345678 ; short s2 = (short ) i2; System.out.println(s2); } }
因此,强制转型的结果很可能是错的。
练习
计算前N个自然数的和可以根据公式:
请根据公式计算前N个自然数的和:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int n = 100 ; int sum = ???; System.out.println(sum); System.out.println(sum == 5050 ? "测试通过" : "测试失败" ); } }
下载练习
小结
整数运算的结果永远是精确的;
运算结果会自动提升;
可以强制转型,但超出范围的强制转型会得到错误的结果;
应该选择合适范围的整型(int或long),没有必要为了节省内存而使用byte和short进行整数运算。
浮点数运算和整数运算相比,只能进行加减乘除这些数值计算,不能做位运算和移位运算。
在计算机中,浮点数虽然表示的范围大,但是,浮点数有个非常重要的特点,就是浮点数常常无法精确表示。
举个例子:
浮点数0.1在计算机中就无法精确表示,因为十进制的0.1换算成二进制是一个无限循环小数,很显然,无论使用float还是double,都只能存储一个0.1的近似值。但是,0.5这个浮点数又可以精确地表示。
因为浮点数常常无法精确表示,因此,浮点数运算会产生误差:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { double x = 1.0 / 10 ; double y = 1 - 9.0 / 10 ; System.out.println(x); System.out.println(y); } }
由于浮点数存在运算误差,所以比较两个浮点数是否相等常常会出现错误的结果。正确的比较方法是判断两个浮点数之差的绝对值是否小于一个很小的数:
1 2 3 4 5 6 7 8 double r = Math.abs(x - y);if (r < 0.00001 ) { } else { }
浮点数在内存的表示方法和整数比更加复杂。Java的浮点数完全遵循IEEE-754 标准,这也是绝大多数计算机平台都支持的浮点数标准表示方法。
类型提升
如果参与运算的两个数其中一个是整型,那么整型可以自动提升到浮点型:
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { int n = 5 ; double d = 1.2 + 24.0 / n; System.out.println(d); } }
需要特别注意,在一个复杂的四则运算中,两个整数的运算不会出现自动提升的情况。例如:
1 double d = 1.2 + 24 / 5 ;
计算结果为5.2,原因是编译器计算24 / 5这个子表达式时,按两个整数进行运算,结果仍为整数4。
要修复这个计算结果,可以将24 / 5改为24.0 / 5。由于24.0是浮点数,因此,计算除法时自动将5提升为浮点数。
溢出
整数运算在除数为0时会报错,而浮点数运算在除数为0时,不会报错,但会返回几个特殊值:
NaN表示Not a NumberInfinity表示无穷大-Infinity表示负无穷大
例如:
1 2 3 double d1 = 0.0 / 0 ; double d2 = 1.0 / 0 ; double d3 = -1.0 / 0 ;
这三种特殊值在实际运算中很少碰到,我们只需要了解即可。
强制转型
可以将浮点数强制转型为整数。在转型时,浮点数的小数部分会被丢掉。如果转型后超过了整型能表示的最大范围,将返回整型的最大值。例如:
1 2 3 4 5 int n1 = (int ) 12.3 ; int n2 = (int ) 12.7 ; int n3 = (int ) -12.7 ; int n4 = (int ) (12.7 + 0.5 ); int n5 = (int ) 1.2e20 ;
如果要进行四舍五入,可以对浮点数加上0.5再强制转型:
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { double d = 2.6 ; int n = (int ) (d + 0.5 ); System.out.println(n); } }
练习
根据一元二次方程 ax2+bx+c=0ax^2+bx+c=0 的求根公式:
计算出一元二次方程的两个解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Main { public static void main (String[] args) { double a = 1.0 ; double b = 3.0 ; double c = -4.0 ; double r1 = 0 ; double r2 = 0 ; System.out.println(r1); System.out.println(r2); System.out.println(r1 == 1 && r2 == -4 ? "测试通过" : "测试失败" ); } }
下载练习
小结
浮点数常常无法精确表示,并且浮点数的运算结果可能有误差;
比较两个浮点数通常比较它们的差的绝对值是否小于一个特定值;
整型和浮点型运算时,整型会自动提升为浮点型;
可以将浮点型强制转为整型,但超出范围后将始终返回整型的最大值。
布尔运算
对于布尔类型boolean,永远只有true和false两个值。
布尔运算是一种关系运算,包括以下几类:
比较运算符:>,>=,<,<=,==,!=
与运算 &&
或运算 ||
非运算 !
下面是一些示例:
1 2 3 4 5 6 boolean isGreater = 5 > 3 ; int age = 12 ;boolean isZero = age == 0 ; boolean isNonZero = !isZero; boolean isAdult = age >= 18 ; boolean isTeenager = age >6 && age <18 ;
关系运算符的优先级从高到低依次是:
短路运算
布尔运算的一个重要特点是短路运算。如果一个布尔运算的表达式能提前确定结果,则后续的计算不再执行,直接返回结果。
因为false && x的结果总是false,无论x是true还是false,因此,与运算在确定第一个值为false后,不再继续计算,而是直接返回false。
我们考察以下代码:
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { boolean b = 5 < 3 ; boolean result = b && (5 / 0 > 0 ); System.out.println(result); } }
如果没有短路运算,&&后面的表达式会由于除数为0而报错,但实际上该语句并未报错,原因在于与运算是短路运算符,提前计算出了结果false。
如果变量b的值为true,则表达式变为true && (5 / 0 > 0)。因为无法进行短路运算,该表达式必定会由于除数为0而报错,可以自行测试。
类似的,对于||运算,只要能确定第一个值为true,后续计算也不再进行,而是直接返回true:
1 boolean result = true || (5 / 0 > 0 );
三元运算符
Java还提供一个三元运算符b ? x : y,它根据第一个布尔表达式的结果,分别返回后续两个表达式之一的计算结果。示例:
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { int n = -100 ; int x = n >= 0 ? n : -n; System.out.println(x); } }
上述语句的意思是,判断n >= 0是否成立,如果为true,则返回n,否则返回-n。这实际上是一个求绝对值的表达式。
注意到三元运算b ? x : y会首先计算b,如果b为true,则只计算x,否则,只计算y。此外,x和y的类型必须相同,因为返回值不是boolean,而是x和y之一。
练习
判断指定年龄是否是小学生(6~12岁):
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int age = 7 ; boolean isPrimaryStudent = ???; System.out.println(isPrimaryStudent ? "Yes" : "No" ); } }
下载练习
小结
与运算和或运算是短路运算;
三元运算b ? x : y后面的类型必须相同,三元运算也是“短路运算”,只计算x或y。
在Java中,字符和字符串是两个不同的类型。
字符类型
字符类型char是基本数据类型,它是character的缩写。一个char保存一个Unicode字符:
1 2 char c1 = 'A' ;char c2 = '中' ;
因为Java在内存中总是使用Unicode表示字符,所以,一个英文字符和一个中文字符都用一个char类型表示,它们都占用两个字节。要显示一个字符的Unicode编码,只需将char类型直接赋值给int类型即可:
1 2 int n1 = 'A' ; int n2 = '中' ;
还可以直接用转义字符\u+Unicode编码来表示一个字符:
1 2 3 char c3 = '\u0041' ; char c4 = '\u4e2d' ;
字符串类型
和char类型不同,字符串类型String是引用类型,我们用双引号"..."表示字符串。一个字符串可以存储0个到任意个字符:
1 2 3 4 String s = "" ; String s1 = "A" ; String s2 = "ABC" ; String s3 = "中文 ABC" ;
因为字符串使用双引号"..."表示开始和结束,那如果字符串本身恰好包含一个"字符怎么表示?例如,"abc"xyz",编译器就无法判断中间的引号究竟是字符串的一部分还是表示字符串结束。这个时候,我们需要借助转义字符\:
因为\是转义字符,所以,两个\\表示一个\字符:
常见的转义字符包括:
\" 表示字符"\' 表示字符'\\ 表示字符\\n 表示换行符\r 表示回车符\t 表示Tab\u#### 表示一个Unicode编码的字符
例如:
1 String s = "ABC\n\u4e2d\u6587" ;
字符串连接
Java的编译器对字符串做了特殊照顾,可以使用+连接任意字符串和其他数据类型,这样极大地方便了字符串的处理。例如:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { String s1 = "Hello" ; String s2 = "world" ; String s = s1 + " " + s2 + "!" ; System.out.println(s); } }
如果用+连接字符串和其他数据类型,会将其他数据类型先自动转型为字符串,再连接:
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { int age = 25 ; String s = "age is " + age; System.out.println(s); } }
多行字符串
如果我们要表示多行字符串,使用+号连接会非常不方便:
1 2 3 String s = "first line \n" + "second line \n" + "end" ;
从Java 13开始,字符串可以用"""..."""表示多行字符串(Text Blocks)了。举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { String s = """ SELECT * FROM users WHERE id > 100 ORDER BY name DESC """ ; System.out.println(s); } }
上述多行字符串实际上是5行,在最后一个DESC后面还有一个\n。如果我们不想在字符串末尾加一个\n,就需要这么写:
1 2 3 4 5 String s = """ SELECT * FROM users WHERE id > 100 ORDER BY name DESC""" ;
还需要注意到,多行字符串前面共同的空格会被去掉,即:
1 2 3 4 5 6 String s = """ ...........SELECT * FROM ........... users ...........WHERE id > 100 ...........ORDER BY name DESC ...........""" ;
用.标注的空格都会被去掉。
如果多行字符串的排版不规则,那么,去掉的空格就会变成这样:
1 2 3 4 5 6 String s = """ ......... SELECT * FROM ......... users .........WHERE id > 100 ......... ORDER BY name DESC ......... """ ;
即总是以最短的行首空格为基准。
不可变特性
Java的字符串除了是一个引用类型外,还有个重要特点,就是字符串不可变。考察以下代码:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { String s = "hello" ; System.out.println(s); s = "world" ; System.out.println(s); } }
观察执行结果,难道字符串s变了吗?其实变的不是字符串,而是变量s的“指向”。
执行String s = "hello";时,JVM虚拟机先创建字符串"hello",然后,把字符串变量s指向它:
1 2 3 4 5 6 s │ ▼ ┌───┬───────────┬───┐ │ │ "hello" │ │ └───┴───────────┴───┘
紧接着,执行s = "world";时,JVM虚拟机先创建字符串"world",然后,把字符串变量s指向它:
1 2 3 4 5 6 s ──────────────┐ │ ▼ ┌───┬───────────┬───┬───────────┬───┐ │ │ "hello" │ │ "world" │ │ └───┴───────────┴───┴───────────┴───┘
原来的字符串"hello"还在,只是我们无法通过变量s访问它而已。因此,字符串的不可变是指字符串内容不可变。至于变量,可以一会指向字符串"hello",一会指向字符串"world"。
理解了引用类型的“指向”后,试解释下面的代码输出:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { String s = "hello" ; String t = s; s = "world" ; System.out.println(t); } }
空值null
引用类型的变量可以指向一个空值null,它表示不存在,即该变量不指向任何对象。例如:
1 2 3 String s1 = null ; String s2 = s1; String s3 = "" ;
注意要区分空值null和空字符串"",空字符串是一个有效的字符串对象,它不等于null。
练习
请将一组int值视为字符的Unicode编码,然后将它们拼成一个字符串:
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { int a = 72 ; int b = 105 ; int c = 65281 ; String s = a + b + c; System.out.println(s); } }
下载练习
小结
Java的字符类型char是基本类型,字符串类型String是引用类型;
基本类型的变量是“持有”某个数值,引用类型的变量是“指向”某个对象;
引用类型的变量可以是空值null;
要区分空值null和空字符串""。
如果我们有一组类型相同的变量,例如,5位同学的成绩,可以这么写:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int n1 = 68 ; int n2 = 79 ; int n3 = 91 ; int n4 = 85 ; int n5 = 62 ; } }
但其实没有必要定义5个int变量。可以使用数组来表示“一组”int类型。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int [] ns = new int [5 ]; ns[0 ] = 68 ; ns[1 ] = 79 ; ns[2 ] = 91 ; ns[3 ] = 85 ; ns[4 ] = 62 ; } }
定义一个数组类型的变量,使用数组类型“类型[]”,例如,int[]。和单个基本类型变量不同,数组变量初始化必须使用new int[5]表示创建一个可容纳5个int元素的数组。
Java的数组有几个特点:
数组所有元素初始化为默认值,整型都是0,浮点型是0.0,布尔型是false;
数组一旦创建后,大小就不可改变。
要访问数组中的某一个元素,需要使用索引。数组索引从0开始,例如,5个元素的数组,索引范围是0~4。
可以修改数组中的某一个元素,使用赋值语句,例如,ns[1] = 79;。
可以用数组变量.length获取数组大小:
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { int [] ns = new int [5 ]; System.out.println(ns.length); } }
数组是引用类型,在使用索引访问数组元素时,如果索引超出范围,运行时将报错:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int [] ns = new int [5 ]; int n = 5 ; System.out.println(ns[n]); } }
也可以在定义数组时直接指定初始化的元素,这样就不必写出数组大小,而是由编译器自动推算数组大小。例如:
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { int [] ns = new int [] { 68 , 79 , 91 , 85 , 62 }; System.out.println(ns.length); } }
还可以进一步简写为:
1 int [] ns = { 68 , 79 , 91 , 85 , 62 };
注意数组是引用类型,并且数组大小不可变。我们观察下面的代码:
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { int [] ns; ns = new int [] { 68 , 79 , 91 , 85 , 62 }; System.out.println(ns.length); ns = new int [] { 1 , 2 , 3 }; System.out.println(ns.length); } }
数组大小变了吗?看上去好像是变了,但其实根本没变。
对于数组ns来说,执行ns = new int[] { 68, 79, 91, 85, 62 };时,它指向一个5个元素的数组:
1 2 3 4 5 6 ns │ ▼ ┌───┬───┬───┬───┬───┬───┬───┐ │ │68 │79 │91 │85 │62 │ │ └───┴───┴───┴───┴───┴───┴───┘
执行ns = new int[] { 1, 2, 3 };时,它指向一个新的 3个元素的数组:
1 2 3 4 5 6 ns ──────────────────────┐ │ ▼ ┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐ │ │68 │79 │91 │85 │62 │ │ 1 │ 2 │ 3 │ │ └───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
但是,原有的5个元素的数组并没有改变,只是无法通过变量ns引用到它们而已。
字符串数组
如果数组元素不是基本类型,而是一个引用类型,那么,修改数组元素会有哪些不同?
字符串是引用类型,因此我们先定义一个字符串数组:
1 2 3 String[] names = { "ABC" , "XYZ" , "zoo" };
对于String[]类型的数组变量names,它实际上包含3个元素,但每个元素都指向某个字符串对象:
1 2 3 4 5 6 7 8 9 ┌─────────────────────────┐ names │ ┌─────────────────────┼───────────┐ │ │ │ │ │ ▼ │ │ ▼ ▼ ┌───┬───┬─┴─┬─┴─┬───┬───────┬───┬───────┬───┬───────┬───┐ │ │░░░│░░░│░░░│ │ "ABC" │ │ "XYZ" │ │ "zoo" │ │ └───┴─┬─┴───┴───┴───┴───────┴───┴───────┴───┴───────┴───┘ │ ▲ └─────────────────┘
对names[1]进行赋值,例如names[1] = "cat";,效果如下:
1 2 3 4 5 6 7 8 9 ┌─────────────────────────────────────────────────┐ names │ ┌─────────────────────────────────┐ │ │ │ │ │ │ ▼ │ │ ▼ ▼ ┌───┬───┬─┴─┬─┴─┬───┬───────┬───┬───────┬───┬───────┬───┬───────┬───┐ │ │░░░│░░░│░░░│ │ "ABC" │ │ "XYZ" │ │ "zoo" │ │ "cat" │ │ └───┴─┬─┴───┴───┴───┴───────┴───┴───────┴───┴───────┴───┴───────┴───┘ │ ▲ └─────────────────┘
这里注意到原来names[1]指向的字符串"XYZ"并没有改变,仅仅是将names[1]的引用从指向"XYZ"改成了指向"cat",其结果是字符串"XYZ"再也无法通过names[1]访问到了。
对“指向”有了更深入的理解后,试解释如下代码:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { String[] names = {"ABC" , "XYZ" , "zoo" }; String s = names[1 ]; names[1 ] = "cat" ; System.out.println(s); } }
小结
数组是同一数据类型的集合,数组一旦创建后,大小就不可变;
可以通过索引访问数组元素,但索引超出范围将报错;
数组元素可以是值类型(如int)或引用类型(如String),但数组本身是引用类型;
输出
在前面的代码中,我们总是使用System.out.println()来向屏幕输出一些内容。
println是print line的缩写,表示输出并换行。因此,如果输出后不想换行,可以用print():
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { System.out.print("A," ); System.out.print("B," ); System.out.print("C." ); System.out.println(); System.out.println("END" ); } }
注意观察上述代码的执行效果。
格式化输出
Java还提供了格式化输出的功能。为什么要格式化输出?因为计算机表示的数据不一定适合人来阅读:
1 2 3 4 5 6 7 public class Main { public static void main (String[] args) { double d = 12900000 ; System.out.println(d); } }
如果要把数据显示成我们期望的格式,就需要使用格式化输出的功能。格式化输出使用System.out.printf(),通过使用占位符%?,printf()可以把后面的参数格式化成指定格式:
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { double d = 3.1415926 ; System.out.printf("%.2f\n" , d); System.out.printf("%.4f\n" , d); } }
Java的格式化功能提供了多种占位符,可以把各种数据类型“格式化”成指定的字符串:
占位符
说明
%d
格式化输出整数
%x
格式化输出十六进制整数
%f
格式化输出浮点数
%e
格式化输出科学计数法表示的浮点数
%s
格式化字符串
注意,由于%表示占位符,因此,连续两个%%表示一个%字符本身。
占位符本身还可以有更详细的格式化参数。下面的例子把一个整数格式化成十六进制,并用0补足8位:
1 2 3 4 5 6 7 public class Main { public static void main (String[] args) { int n = 12345000 ; System.out.printf("n=%d, hex=%08x" , n, n); } }
详细的格式化参数请参考JDK文档java.util.Formatter
输入
和输出相比,Java的输入就要复杂得多。
我们先看一个从控制台读取一个字符串和一个整数的例子:
1 2 3 4 5 6 7 8 9 10 11 12 import java.util.Scanner;public class Main { public static void main (String[] args) { Scanner scanner = new Scanner (System.in); System.out.print("Input your name: " ); String name = scanner.nextLine(); System.out.print("Input your age: " ); int age = scanner.nextInt(); System.out.printf("Hi, %s, you are %d\n" , name, age); } }
首先,我们通过import语句导入java.util.Scanner,import是导入某个类的语句,必须放到Java源代码的开头,后面我们在Java的package中会详细讲解如何使用import。
然后,创建Scanner对象并传入System.in。System.out代表标准输出流,而System.in代表标准输入流。直接使用System.in读取用户输入虽然是可以的,但需要更复杂的代码,而通过Scanner就可以简化后续的代码。
有了Scanner对象后,要读取用户输入的字符串,使用scanner.nextLine(),要读取用户输入的整数,使用scanner.nextInt()。Scanner会自动转换数据类型,因此不必手动转换。
要测试输入,必须从命令行读取用户输入,因此,需要走编译、执行的流程:
这个程序编译时如果有警告,可以暂时忽略它,在后面学习IO的时候再详细解释。编译成功后,执行:
1 2 3 4 $ java Main Input your name: Bob ◀── 输入 Bob Input your age: 12 ◀── 输入 12 Hi, Bob, you are 12 ◀── 输出
根据提示分别输入一个字符串和整数后,我们得到了格式化的输出。
练习
请帮小明同学设计一个程序,输入上次考试成绩(int)和本次考试成绩(int),然后输出成绩提高的百分比,保留两位小数位(例如,21.75%)。
下载练习
小结
Java提供的输出包括:System.out.println() / print() / printf(),其中printf()可以格式化输出;
Java提供Scanner对象来方便输入,读取对应的类型可以使用:scanner.nextLine() / nextInt() / nextDouble() / …
在Java程序中,如果要根据条件来决定是否执行某一段代码,就需要if语句。
if语句的基本语法是:
根据if的计算结果(true还是false),JVM决定是否执行if语句块(即花括号{}包含的所有语句)。
让我们来看一个例子:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int n = 70 ; if (n >= 60 ) { System.out.println("及格了" ); } System.out.println("END" ); } }
当条件n >= 60计算结果为true时,if语句块被执行,将打印"及格了",否则,if语句块将被跳过。修改n的值可以看到执行效果。
注意到if语句包含的块可以包含多条语句:
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { int n = 70 ; if (n >= 60 ) { System.out.println("及格了" ); System.out.println("恭喜你" ); } System.out.println("END" ); } }
当if语句块只有一行语句时,可以省略花括号{}:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int n = 70 ; if (n >= 60 ) System.out.println("及格了" ); System.out.println("END" ); } }
但是,省略花括号并不总是一个好主意。假设某个时候,突然想给if语句块增加一条语句时:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int n = 50 ; if (n >= 60 ) System.out.println("及格了" ); System.out.println("恭喜你" ); System.out.println("END" ); } }
由于使用缩进格式,很容易把两行语句都看成if语句的执行块,但实际上只有第一行语句是if的执行块。在使用git这些版本控制系统自动合并时更容易出问题,所以不推荐忽略花括号的写法。
else
if语句还可以编写一个else { ... },当条件判断为false时,将执行else的语句块:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int n = 70 ; if (n >= 60 ) { System.out.println("及格了" ); } else { System.out.println("挂科了" ); } System.out.println("END" ); } }
修改上述代码n的值,观察if条件为true或false时,程序执行的语句块。
注意,else不是必须的。
还可以用多个if ... else if ...串联。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Main { public static void main (String[] args) { int n = 70 ; if (n >= 90 ) { System.out.println("优秀" ); } else if (n >= 60 ) { System.out.println("及格了" ); } else { System.out.println("挂科了" ); } System.out.println("END" ); } }
串联的效果其实相当于:
1 2 3 4 5 6 7 8 9 10 11 12 13 if (n >= 90 ) { System.out.println("优秀" ); } else { if (n >= 60 ) { System.out.println("及格了" ); } else { System.out.println("挂科了" ); } }
在串联使用多个if时,要特别注意 判断顺序。观察下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Main { public static void main (String[] args) { int n = 100 ; if (n >= 60 ) { System.out.println("及格了" ); } else if (n >= 90 ) { System.out.println("优秀" ); } else { System.out.println("挂科了" ); } } }
执行发现,n = 100时,满足条件n >= 90,但输出的不是"优秀",而是"及格了",原因是if语句从上到下执行时,先判断n >= 60成功后,后续else不再执行,因此,if (n >= 90)没有机会执行了。
正确的方式是按照判断范围从大到小依次判断:
1 2 3 4 5 6 7 8 if (n >= 90 ) { } else if (n >= 60 ) { } else { }
或者改写成从小到大依次判断:
1 2 3 4 5 6 7 8 if (n < 60 ) { } else if (n < 90 ) { } else { }
使用if时,还要特别注意边界条件。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Main { public static void main (String[] args) { int n = 90 ; if (n > 90 ) { System.out.println("优秀" ); } else if (n >= 60 ) { System.out.println("及格了" ); } else { System.out.println("挂科了" ); } } }
假设我们期望90分或更高为“优秀”,上述代码输出的却是“及格”,原因是>和>=效果是不同的。
前面讲过了浮点数在计算机中常常无法精确表示,并且计算可能出现误差,因此,判断浮点数相等用==判断不靠谱:
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { double x = 1 - 9.0 / 10 ; if (x == 0.1 ) { System.out.println("x is 0.1" ); } else { System.out.println("x is NOT 0.1" ); } } }
正确的方法是利用差值小于某个临界值来判断:
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { double x = 1 - 9.0 / 10 ; if (Math.abs(x - 0.1 ) < 0.00001 ) { System.out.println("x is 0.1" ); } else { System.out.println("x is NOT 0.1" ); } } }
判断引用类型相等
在Java中,判断值类型的变量是否相等,可以使用==运算符。但是,判断引用类型的变量是否相等,==表示“引用是否相等”,或者说,是否指向同一个对象。例如,下面的两个String类型,它们的内容是相同的,但是,分别指向不同的对象,用==判断,结果为false:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Main { public static void main (String[] args) { String s1 = "hello" ; String s2 = "HELLO" .toLowerCase(); System.out.println(s1); System.out.println(s2); if (s1 == s2) { System.out.println("s1 == s2" ); } else { System.out.println("s1 != s2" ); } } }
要判断引用类型的变量内容是否相等,必须使用equals()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Main { public static void main (String[] args) { String s1 = "hello" ; String s2 = "HELLO" .toLowerCase(); System.out.println(s1); System.out.println(s2); if (s1.equals(s2)) { System.out.println("s1 equals s2" ); } else { System.out.println("s1 not equals s2" ); } } }
注意:执行语句s1.equals(s2)时,如果变量s1为null,会报NullPointerException:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { String s1 = null ; if (s1.equals("hello" )) { System.out.println("hello" ); } } }
要避免NullPointerException错误,可以利用短路运算符&&:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { String s1 = null ; if (s1 != null && s1.equals("hello" )) { System.out.println("hello" ); } } }
还可以把一定不是null的对象"hello"放到前面:例如:if ("hello".equals(s)) { ... }。
练习
请用if ... else编写一个程序,用于计算体质指数BMI,并打印结果。
BMI结果:
过轻:低于18.5
正常:18.5 ~ 25
过重:25 ~ 28
肥胖:28 ~ 32
非常肥胖:高于32
下载练习
小结
if ... else可以做条件判断,else是可选的;
不推荐省略花括号{};
多个if ... else串联要特别注意判断顺序;
要注意if的边界条件;
要注意浮点数判断相等不能直接用==运算符;
引用类型判断内容相等要使用equals(),注意避免NullPointerException。
除了if语句外,还有一种条件判断,是根据某个表达式的结果,分别去执行不同的分支。
例如,在游戏中,让用户选择选项:
单人模式
多人模式
退出游戏
这时,switch语句就派上用场了。
switch语句根据switch (表达式)计算的结果,跳转到匹配的case结果,然后继续执行后续语句,直到遇到break结束执行。
我们看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Main { public static void main (String[] args) { int option = 1 ; switch (option) { case 1 : System.out.println("Selected 1" ); break ; case 2 : System.out.println("Selected 2" ); break ; case 3 : System.out.println("Selected 3" ); break ; } } }
修改option的值分别为1、2、3,观察执行结果。
如果option的值没有匹配到任何case,例如option = 99,那么,switch语句不会执行任何语句。这时,可以给switch语句加一个default,当没有匹配到任何case时,执行default:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class Main { public static void main (String[] args) { int option = 99 ; switch (option) { case 1 : System.out.println("Selected 1" ); break ; case 2 : System.out.println("Selected 2" ); break ; case 3 : System.out.println("Selected 3" ); break ; default : System.out.println("Selected other" ); break ; } } }
如果把switch语句翻译成if语句,那么上述的代码相当于:
1 2 3 4 5 6 7 8 9 if (option == 1 ) { System.out.println("Selected 1" ); } else if (option == 2 ) { System.out.println("Selected 2" ); } else if (option == 3 ) { System.out.println("Selected 3" ); } else { System.out.println("Selected other" ); }
对比if ... else if语句,对于多个==判断的情况,使用switch结构更加清晰。
同时注意,上述“翻译”只有在switch语句中对每个case正确编写了break语句才能对应得上。
使用switch时,注意case语句并没有花括号{},而且,case语句具有“穿透性 ”,漏写break将导致意想不到的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Main { public static void main (String[] args) { int option = 2 ; switch (option) { case 1 : System.out.println("Selected 1" ); case 2 : System.out.println("Selected 2" ); case 3 : System.out.println("Selected 3" ); default : System.out.println("Selected other" ); } } }
当option = 2时,将依次输出"Selected 2"、"Selected 3"、"Selected other",原因是从匹配到case 2开始,后续语句将全部执行,直到遇到break语句。因此,任何时候都不要忘记写break。
如果有几个case语句执行的是同一组语句块,可以这么写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Main { public static void main (String[] args) { int option = 2 ; switch (option) { case 1 : System.out.println("Selected 1" ); break ; case 2 : case 3 : System.out.println("Selected 2, 3" ); break ; default : System.out.println("Selected other" ); break ; } } }
使用switch语句时,只要保证有break,case的顺序不影响程序逻辑:
1 2 3 4 5 6 7 8 9 10 11 switch (option) {case 3 : ... break ; case 2 : ... break ; case 1 : ... break ; }
但是仍然建议按照自然顺序排列,便于阅读。
switch语句还可以匹配字符串。字符串匹配时,是比较“内容相等”。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class Main { public static void main (String[] args) { String fruit = "apple" ; switch (fruit) { case "apple" : System.out.println("Selected apple" ); break ; case "pear" : System.out.println("Selected pear" ); break ; case "mango" : System.out.println("Selected mango" ); break ; default : System.out.println("No fruit selected" ); break ; } } }
switch语句还可以使用枚举类型,枚举类型我们在后面讲解。
编译检查
使用IDE时,可以自动检查是否漏写了break语句和default语句,方法是打开IDE的编译检查。
在Eclipse中,选择Preferences - Java - Compiler - Errors/Warnings - Potential programming problems,将以下检查标记为Warning:
‘switch’ is missing ‘default’ case:缺少default语句时警告;
‘switch’ case fall-through:某个case缺少break时警告。
在Idea中,选择Preferences - Editor - Inspections - Java - Control flow issues,将以下检查标记为Warning:
‘switch’ statement without ‘default’ branch:缺少default语句时警告;
Fallthrough in ‘switch’ statement:某个case缺少break时警告。
当switch语句存在问题时,即可在IDE中获得警告提示。
switch表达式
使用switch时,如果遗漏了break,就会造成严重的逻辑错误,而且不易在源代码中发现错误。从Java 12开始,switch语句升级为更简洁的表达式语法,使用类似模式匹配(Pattern Matching)的方法,保证只有一种路径会被执行,并且不需要break语句:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Main { public static void main (String[] args) { String fruit = "apple" ; switch (fruit) { case "apple" -> System.out.println("Selected apple" ); case "pear" -> System.out.println("Selected pear" ); case "mango" -> { System.out.println("Selected mango" ); System.out.println("Good choice!" ); } default -> System.out.println("No fruit selected" ); } } }
注意新语法使用->,如果有多条语句,需要用{}括起来。不要写break语句,因为新语法只会执行匹配的语句,没有 穿透效应。
很多时候,我们还可能用switch语句给某个变量赋值。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 int opt;switch (fruit) {case "apple" : opt = 1 ; break ; case "pear" :case "mango" : opt = 2 ; break ; default : opt = 0 ; break ; }
使用新的switch语法,不但不需要break,还可以直接返回值。把上面的代码改写如下:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { String fruit = "apple" ; int opt = switch (fruit) { case "apple" -> 1 ; case "pear" , "mango" -> 2 ; default -> 0 ; }; System.out.println("opt = " + opt); } }
这样可以获得更简洁的代码。
yield
大多数时候,在switch表达式内部,我们会返回简单的值。
但是,如果需要复杂的语句,我们也可以写很多语句,放到{...}里,然后,用yield返回一个值作为switch语句的返回值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Main { public static void main (String[] args) { String fruit = "orange" ; int opt = switch (fruit) { case "apple" -> 1 ; case "pear" , "mango" -> 2 ; default -> { int code = fruit.hashCode(); yield code; } }; System.out.println("opt = " + opt); } }
练习
使用switch实现一个简单的石头、剪子、布游戏。
下载练习
小结
switch语句可以做多重选择,然后执行匹配的case语句后续代码;
switch的计算结果必须是整型、字符串或枚举类型;
注意千万不要漏写break,建议打开fall-through警告;
总是写上default,建议打开missing default警告;
从Java 14开始,switch语句正式升级为表达式,不再需要break,并且允许使用yield返回值。
while循环
循环语句就是让计算机根据条件做循环计算,在条件满足时继续循环,条件不满足时退出循环。
例如,计算从1到100的和:
1 1 + 2 + 3 + 4 + … + 100 = ?
除了用数列公式外,完全可以让计算机做100次循环累加。因为计算机的特点是计算速度非常快,我们让计算机循环一亿次也用不到1秒,所以很多计算的任务,人去算是算不了的,但是计算机算,使用循环这种简单粗暴的方法就可以快速得到结果。
我们先看Java提供的while条件循环。它的基本用法是:
1 2 3 4 while (条件表达式) { 循环语句 }
while循环在每次循环开始前,首先判断条件是否成立。如果计算结果为true,就把循环体内的语句执行一遍,如果计算结果为false,那就直接跳到while循环的末尾,继续往下执行。
我们用while循环来累加1到100,可以这么写:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int sum = 0 ; int n = 1 ; while (n <= 100 ) { sum = sum + n; n ++; } System.out.println(sum); } }
注意到while循环是先判断循环条件,再循环,因此,有可能一次循环都不做。
对于循环条件判断,以及自增变量的处理,要特别注意边界条件。思考一下下面的代码为何没有获得正确结果:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int sum = 0 ; int n = 0 ; while (n <= 100 ) { n ++; sum = sum + n; } System.out.println(sum); } }
如果循环条件永远满足,那这个循环就变成了死循环。死循环将导致100%的CPU占用,用户会感觉电脑运行缓慢,所以要避免编写死循环代码。
如果循环条件的逻辑写得有问题,也会造成意料之外的结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Main { public static void main (String[] args) { int sum = 0 ; int n = 1 ; while (n > 0 ) { sum = sum + n; n ++; } System.out.println(n); System.out.println(sum); } }
表面上看,上面的while循环是一个死循环,但是,Java的int类型有最大值,达到最大值后,再加1会变成负数,结果,意外退出了while循环。
练习
使用while计算从m到n的和:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int sum = 0 ; int m = 20 ; int n = 100 ; while (false ) { } System.out.println(sum); } }
下载练习
小结
while循环先判断循环条件是否满足,再执行循环语句;
while循环可能一次都不执行;
编写循环时要注意循环条件,并避免死循环。
在Java中,while循环是先判断循环条件,再执行循环。而另一种do while循环则是先执行循环,再判断条件,条件满足时继续循环,条件不满足时退出。它的用法是:
1 2 3 do { 执行循环语句 } while (条件表达式);
可见,do while循环会至少循环一次。
我们把对1到100的求和用do while循环改写一下:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int sum = 0 ; int n = 1 ; do { sum = sum + n; n ++; } while (n <= 100 ); System.out.println(sum); } }
使用do while循环时,同样要注意循环条件的判断。
练习
使用do while循环计算从m到n的和。
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int sum = 0 ; int m = 20 ; int n = 100 ; do { } while (false ); System.out.println(sum); } }
下载练习
小结
do while先执行循环,再判断条件;
do while循环会至少执行一次。
除了while和do while循环,Java使用最广泛的是for循环。
for循环的功能非常强大,它使用计数器实现循环。for循环会先初始化计数器,然后,在每次循环前检测循环条件,在每次循环后更新计数器。计数器变量通常命名为i。
我们把1到100求和用for循环改写一下:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int sum = 0 ; for (int i=1 ; i<=100 ; i++) { sum = sum + i; } System.out.println(sum); } }
在for循环执行前,会先执行初始化语句int i=1,它定义了计数器变量i并赋初始值为1,然后,循环前先检查循环条件i<=100,循环后自动执行i++,因此,和while循环相比,for循环把更新计数器的代码统一放到了一起。在for循环的循环体内部,不需要去更新变量i。
因此,for循环的用法是:
1 2 3 for (初始条件; 循环检测条件; 循环后更新计数器) { }
如果我们要对一个整型数组的所有元素求和,可以用for循环实现:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int [] ns = { 1 , 4 , 9 , 16 , 25 }; int sum = 0 ; for (int i=0 ; i<ns.length; i++) { System.out.println("i = " + i + ", ns[i] = " + ns[i]); sum = sum + ns[i]; } System.out.println("sum = " + sum); } }
上面代码的循环条件是i<ns.length。因为ns数组的长度是5,因此,当循环5次后,i的值被更新为5,就不满足循环条件,因此for循环结束。
思考
如果把循环条件改为i<=ns.length,会出现什么问题?
注意for循环的初始化计数器总是会被执行,并且for循环也可能循环0次。
使用for循环时,千万不要在循环体内修改计数器!在循环体中修改计数器常常导致莫名其妙的逻辑错误。对于下面的代码:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int [] ns = { 1 , 4 , 9 , 16 , 25 }; for (int i=0 ; i<ns.length; i++) { System.out.println(ns[i]); i = i + 1 ; } } }
虽然不会报错,但是,数组元素只打印了一半,原因是循环内部的i = i + 1导致了计数器变量每次循环实际上加了2(因为for循环还会自动执行i++)。因此,在for循环中,不要修改计数器的值。计数器的初始化、判断条件、每次循环后的更新条件统一放到for()语句中可以一目了然。
如果希望只访问索引号为偶数的数组元素,应该把for循环改写为:
1 2 3 4 int [] ns = { 1 , 4 , 9 , 16 , 25 };for (int i=0 ; i<ns.length; i=i+2 ) { System.out.println(ns[i]); }
通过更新计数器的语句i=i+2就达到了这个效果,从而避免了在循环体内去修改变量i。
使用for循环时,计数器变量i要尽量定义在for循环中:
1 2 3 4 5 6 int [] ns = { 1 , 4 , 9 , 16 , 25 };for (int i=0 ; i<ns.length; i++) { System.out.println(ns[i]); } int n = i;
如果变量i定义在for循环外:
1 2 3 4 5 6 7 int [] ns = { 1 , 4 , 9 , 16 , 25 };int i;for (i=0 ; i<ns.length; i++) { System.out.println(ns[i]); } int n = i;
那么,退出for循环后,变量i仍然可以被访问,这就破坏了变量应该把访问范围缩到最小的原则。
灵活使用for循环
for循环还可以缺少初始化语句、循环条件和每次循环更新语句,例如:
1 2 3 4 for (int i=0 ; ; i++) { ... }
1 2 3 4 for (int i=0 ; ;) { ... }
通常不推荐这样写,但是,某些情况下,是可以省略for循环的某些语句的。
for each循环
for循环经常用来遍历数组,因为通过计数器可以根据索引来访问数组的每个元素:
1 2 3 4 int [] ns = { 1 , 4 , 9 , 16 , 25 };for (int i=0 ; i<ns.length; i++) { System.out.println(ns[i]); }
但是,很多时候,我们实际上真正想要访问的是数组每个元素的值。Java还提供了另一种for each循环,它可以更简单地遍历数组:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int [] ns = { 1 , 4 , 9 , 16 , 25 }; for (int n : ns) { System.out.println(n); } } }
和for循环相比,for each循环的变量n不再是计数器,而是直接对应到数组的每个元素。for each循环的写法也更简洁。但是,for each循环无法指定遍历顺序,也无法获取数组的索引。
除了数组外,for each循环能够遍历所有“可迭代”的数据类型,包括后面会介绍的List、Map等。
练习1
给定一个数组,请用for循环倒序输出每一个元素:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int [] ns = { 1 , 4 , 9 , 16 , 25 }; for (int i=?; ???; ???) { System.out.println(ns[i]); } } }
练习2
利用for each循环对数组每个元素求和:
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { int [] ns = { 1 , 4 , 9 , 16 , 25 }; int sum = 0 ; for (???) { } System.out.println(sum); } }
练习3
圆周率π可以使用公式计算:
请利用for循环计算π:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { double pi = 0 ; for (???) { } System.out.println(pi); } }
下载练习
小结
for循环通过计数器可以实现复杂循环;
for each循环可以直接遍历数组的每个元素;
最佳实践:计数器变量定义在for循环内部,循环体内部不修改计数器;
break和continue
无论是while循环还是for循环,有两个特别的语句可以使用,就是break语句和continue语句。
break
在循环过程中,可以使用break语句跳出当前循环。我们来看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Main { public static void main (String[] args) { int sum = 0 ; for (int i=1 ; ; i++) { sum = sum + i; if (i == 100 ) { break ; } } System.out.println(sum); } }
使用for循环计算从1到100时,我们并没有在for()中设置循环退出的检测条件。但是,在循环内部,我们用if判断,如果i==100,就通过break退出循环。
因此,break语句通常都是配合if语句使用。要特别注意,break语句总是跳出自己所在的那一层循环。例如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Main { public static void main (String[] args) { for (int i=1 ; i<=10 ; i++) { System.out.println("i = " + i); for (int j=1 ; j<=10 ; j++) { System.out.println("j = " + j); if (j >= i) { break ; } } System.out.println("breaked" ); } } }
上面的代码是两个for循环嵌套。因为break语句位于内层的for循环,因此,它会跳出内层for循环,但不会跳出外层for循环。
continue
break会跳出当前循环,也就是整个循环都不会执行了。而continue则是提前结束本次循环,直接继续执行下次循环。我们看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Main { public static void main (String[] args) { int sum = 0 ; for (int i=1 ; i<=10 ; i++) { System.out.println("begin i = " + i); if (i % 2 == 0 ) { continue ; } sum = sum + i; System.out.println("end i = " + i); } System.out.println(sum); } }
注意观察continue语句的效果。当i为奇数时,完整地执行了整个循环,因此,会打印begin i=1和end i=1。在i为偶数时,continue语句会提前结束本次循环,因此,会打印begin i=2但不会打印end i=2。
在多层嵌套的循环中,continue语句同样是结束本次自己所在的循环。
小结
break语句可以跳出当前循环;
break语句通常配合if,在满足条件时提前结束整个循环;
break语句总是跳出最近的一层循环;
continue语句可以提前结束本次循环;
continue语句通常配合if,在满足条件时提前结束本次循环。
我们在Java程序基础里介绍了数组这种数据类型。有了数组,我们还需要来操作它。而数组最常见的一个操作就是遍历。
通过for循环就可以遍历数组。因为数组的每个元素都可以通过索引来访问,因此,使用标准的for循环可以完成一个数组的遍历:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { int [] ns = { 1 , 4 , 9 , 16 , 25 }; for (int i=0 ; i<ns.length; i++) { int n = ns[i]; System.out.println(n); } } }
为了实现for循环遍历,初始条件为i=0,因为索引总是从0开始,继续循环的条件为i<ns.length,因为当i=ns.length时,i已经超出了索引范围(索引范围是0 ~ ns.length-1),每次循环后,i++。
第二种方式是使用for each循环,直接迭代数组的每个元素:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int [] ns = { 1 , 4 , 9 , 16 , 25 }; for (int n : ns) { System.out.println(n); } } }
注意:在for (int n : ns)循环中,变量n直接拿到ns数组的元素,而不是索引。
显然for each循环更加简洁。但是,for each循环无法拿到数组的索引,因此,到底用哪一种for循环,取决于我们的需要。
打印数组内容
直接打印数组变量,得到的是数组在JVM中的引用地址:
1 2 int [] ns = { 1 , 1 , 2 , 3 , 5 , 8 };System.out.println(ns);
这并没有什么意义,因为我们希望打印的数组的元素内容。因此,使用for each循环来打印它:
1 2 3 4 int [] ns = { 1 , 1 , 2 , 3 , 5 , 8 };for (int n : ns) { System.out.print(n + ", " ); }
使用for each循环打印也很麻烦。幸好Java标准库提供了Arrays.toString(),可以快速打印数组内容:
1 2 3 4 5 6 7 8 9 import java.util.Arrays;public class Main { public static void main (String[] args) { int [] ns = { 1 , 1 , 2 , 3 , 5 , 8 }; System.out.println(Arrays.toString(ns)); } }
练习
请按倒序遍历数组并打印每个元素:
1 2 3 4 5 6 7 8 9 public class Main { public static void main (String[] args) { int [] ns = { 1 , 4 , 9 , 16 , 25 }; for (???) { System.out.println(???); } } }
下载练习
小结
遍历数组可以使用for循环,for循环可以访问数组索引,for each循环直接迭代每个数组元素,但无法获取索引;
使用Arrays.toString()可以快速获取数组内容。
对数组进行排序是程序中非常基本的需求。常用的排序算法有冒泡排序、插入排序和快速排序等。
我们来看一下如何使用冒泡排序算法对一个整型数组从小到大进行排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import java.util.Arrays;public class Main { public static void main (String[] args) { int [] ns = { 28 , 12 , 89 , 73 , 65 , 18 , 96 , 50 , 8 , 36 }; System.out.println(Arrays.toString(ns)); for (int i = 0 ; i < ns.length - 1 ; i++) { for (int j = 0 ; j < ns.length - i - 1 ; j++) { if (ns[j] > ns[j+1 ]) { int tmp = ns[j]; ns[j] = ns[j+1 ]; ns[j+1 ] = tmp; } } } System.out.println(Arrays.toString(ns)); } }
冒泡排序的特点是,每一轮循环后,最大的一个数被交换到末尾,因此,下一轮循环就可以“刨除”最后的数,每一轮循环都比上一轮循环的结束位置靠前一位。
另外,注意到交换两个变量的值必须借助一个临时变量。像这么写是错误的:
1 2 3 4 5 int x = 1 ;int y = 2 ;x = y; y = x;
正确的写法是:
1 2 3 4 5 6 int x = 1 ;int y = 2 ;int t = x; x = y; y = t;
实际上,Java的标准库已经内置了排序功能,我们只需要调用JDK提供的Arrays.sort()就可以排序:
1 2 3 4 5 6 7 8 9 10 import java.util.Arrays;public class Main { public static void main (String[] args) { int [] ns = { 28 , 12 , 89 , 73 , 65 , 18 , 96 , 50 , 8 , 36 }; Arrays.sort(ns); System.out.println(Arrays.toString(ns)); } }
必须注意,对数组排序实际上修改了数组本身。例如,排序前的数组是:
1 int [] ns = { 9 , 3 , 6 , 5 };
在内存中,这个整型数组表示如下:
1 2 3 ┌───┬───┬───┬───┐ ns───▶│ 9 │ 3 │ 6 │ 5 │ └───┴───┴───┴───┘
当我们调用Arrays.sort(ns);后,这个整型数组在内存中变为:
1 2 3 ┌───┬───┬───┬───┐ ns───▶│ 3 │ 5 │ 6 │ 9 │ └───┴───┴───┴───┘
即变量ns指向的数组内容已经被改变了。
如果对一个字符串数组进行排序,例如:
1 String[] ns = { "banana" , "apple" , "pear" };
排序前,这个数组在内存中表示如下:
1 2 3 4 5 6 7 8 ┌──────────────────────────────────┐ ┌───┼──────────────────────┐ │ │ │ ▼ ▼ ┌───┬─┴─┬─┴─┬───┬────────┬───┬───────┬───┬──────┬───┐ ns ─────▶│░░░│░░░│░░░│ │"banana"│ │"apple"│ │"pear"│ │ └─┬─┴───┴───┴───┴────────┴───┴───────┴───┴──────┴───┘ │ ▲ └─────────────────┘
调用Arrays.sort(ns);排序后,这个数组在内存中表示如下:
1 2 3 4 5 6 7 8 ┌──────────────────────────────────┐ ┌───┼──────────┐ │ │ │ ▼ ▼ ┌───┬─┴─┬─┴─┬───┬────────┬───┬───────┬───┬──────┬───┐ ns ─────▶│░░░│░░░│░░░│ │"banana"│ │"apple"│ │"pear"│ │ └─┬─┴───┴───┴───┴────────┴───┴───────┴───┴──────┴───┘ │ ▲ └──────────────────────────────┘
原来的3个字符串在内存中均没有任何变化,但是ns数组的每个元素指向变化了。
练习
请思考如何实现对数组进行降序排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import java.util.Arrays;public class Main { public static void main (String[] args) { int [] ns = { 28 , 12 , 89 , 73 , 65 , 18 , 96 , 50 , 8 , 36 }; System.out.println(Arrays.toString(ns)); System.out.println(Arrays.toString(ns)); if (Arrays.toString(ns).equals("[96, 89, 73, 65, 50, 36, 28, 18, 12, 8]" )) { System.out.println("测试成功" ); } else { System.out.println("测试失败" ); } } }
下载练习
小结
常用的排序算法有冒泡排序、插入排序和快速排序等;
冒泡排序使用两层for循环实现排序;
交换两个变量的值需要借助一个临时变量;
可以直接使用Java标准库提供的Arrays.sort()进行排序;
对数组排序会直接修改数组本身。
二维数组
二维数组就是数组的数组。定义一个二维数组如下:
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { int [][] ns = { { 1 , 2 , 3 , 4 }, { 5 , 6 , 7 , 8 }, { 9 , 10 , 11 , 12 } }; System.out.println(ns.length); } }
因为ns包含3个数组,因此,ns.length为3。实际上ns在内存中的结构如下:
1 2 3 4 5 6 7 8 9 ┌───┬───┬───┬───┐ ┌───┐ ┌──▶│ 1 │ 2 │ 3 │ 4 │ ns ─────▶│░░░│──┘ └───┴───┴───┴───┘ ├───┤ ┌───┬───┬───┬───┐ │░░░│─────▶│ 5 │ 6 │ 7 │ 8 │ ├───┤ └───┴───┴───┴───┘ │░░░│──┐ ┌───┬───┬───┬───┐ └───┘ └──▶│ 9 │10 │11 │12 │ └───┴───┴───┴───┘
如果我们定义一个普通数组arr0,然后把ns[0]赋值给它:
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { int [][] ns = { { 1 , 2 , 3 , 4 }, { 5 , 6 , 7 , 8 }, { 9 , 10 , 11 , 12 } }; int [] arr0 = ns[0 ]; System.out.println(arr0.length); } }
实际上arr0就获取了ns数组的第0个元素。因为ns数组的每个元素也是一个数组,因此,arr0指向的数组就是{ 1, 2, 3, 4 }。在内存中,结构如下:
1 2 3 4 5 6 7 8 9 10 11 arr0 ─────┐ ▼ ┌───┬───┬───┬───┐ ┌───┐ ┌──▶│ 1 │ 2 │ 3 │ 4 │ ns ─────▶│░░░│──┘ └───┴───┴───┴───┘ ├───┤ ┌───┬───┬───┬───┐ │░░░│─────▶│ 5 │ 6 │ 7 │ 8 │ ├───┤ └───┴───┴───┴───┘ │░░░│──┐ ┌───┬───┬───┬───┐ └───┘ └──▶│ 9 │10 │11 │12 │ └───┴───┴───┴───┘
访问二维数组的某个元素需要使用array[row][col],例如:
1 System.out.println(ns[1 ][2 ]);
二维数组的每个数组元素的长度并不要求相同,例如,可以这么定义ns数组:
1 2 3 4 5 int [][] ns = { { 1 , 2 , 3 , 4 }, { 5 , 6 }, { 7 , 8 , 9 } };
这个二维数组在内存中的结构如下:
1 2 3 4 5 6 7 8 9 ┌───┬───┬───┬───┐ ┌───┐ ┌──▶│ 1 │ 2 │ 3 │ 4 │ ns ─────▶│░░░│──┘ └───┴───┴───┴───┘ ├───┤ ┌───┬───┐ │░░░│─────▶│ 5 │ 6 │ ├───┤ └───┴───┘ │░░░│──┐ ┌───┬───┬───┐ └───┘ └──▶│ 7 │ 8 │ 9 │ └───┴───┴───┘
要打印一个二维数组,可以使用两层嵌套的for循环:
1 2 3 4 5 6 7 for (int [] arr : ns) { for (int n : arr) { System.out.print(n); System.out.print(', ' ); } System.out.println(); }
或者使用Java标准库的Arrays.deepToString():
1 2 3 4 5 6 7 8 9 10 11 12 13 import java.util.Arrays;public class Main { public static void main (String[] args) { int [][] ns = { { 1 , 2 , 3 , 4 }, { 5 , 6 }, { 7 , 8 , 9 } }; System.out.println(Arrays.deepToString(ns)); } }
三维数组
三维数组就是二维数组的数组。可以这么定义一个三维数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int [][][] ns = { { {1 , 2 , 3 }, {4 , 5 , 6 }, {7 , 8 , 9 } }, { {10 , 11 }, {12 , 13 } }, { {14 , 15 , 16 }, {17 , 18 } } };
它在内存中的结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ┌───┬───┬───┐ ┌───┐ ┌──▶│ 1 │ 2 │ 3 │ ┌──▶│░░░│──┘ └───┴───┴───┘ │ ├───┤ ┌───┬───┬───┐ │ │░░░│─────▶│ 4 │ 5 │ 6 │ │ ├───┤ └───┴───┴───┘ │ │░░░│──┐ ┌───┬───┬───┐ ┌───┐ │ └───┘ └──▶│ 7 │ 8 │ 9 │ ns ────▶│░░░│──┘ └───┴───┴───┘ ├───┤ ┌───┐ ┌───┬───┐ │░░░│─────▶│░░░│─────▶│10 │11 │ ├───┤ ├───┤ └───┴───┘ │░░░│──┐ │░░░│──┐ ┌───┬───┐ └───┘ │ └───┘ └──▶│12 │13 │ │ └───┴───┘ │ ┌───┐ ┌───┬───┬───┐ └──▶│░░░│─────▶│14 │15 │16 │ ├───┤ └───┴───┴───┘ │░░░│──┐ ┌───┬───┐ └───┘ └──▶│17 │18 │ └───┴───┘
如果我们要访问三维数组的某个元素,例如,ns[2][0][1],只需要顺着定位找到对应的最终元素15即可。
理论上,我们可以定义任意的N维数组。但在实际应用中,除了二维数组在某些时候还能用得上,更高维度的数组很少使用。
练习
使用二维数组可以表示一组学生的各科成绩,请计算所有学生的平均分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class Main { public static void main (String[] args) { int [][] scores = { { 82 , 90 , 91 }, { 68 , 72 , 64 }, { 95 , 91 , 89 }, { 67 , 52 , 60 }, { 79 , 81 , 85 }, }; double average = 0 ; System.out.println(average); if (Math.abs(average - 77.733333 ) < 0.000001 ) { System.out.println("测试成功" ); } else { System.out.println("测试失败" ); } } }
下载练习
小结
二维数组就是数组的数组,三维数组就是二维数组的数组;
多维数组的每个数组元素长度都不要求相同;
打印多维数组可以使用Arrays.deepToString();
最常见的多维数组是二维数组,访问二维数组的一个元素使用array[row][col]。
Java程序的入口是main方法,而main方法可以接受一个命令行参数,它是一个String[]数组。
这个命令行参数由JVM接收用户输入并传给main方法:
1 2 3 4 5 6 7 public class Main { public static void main (String[] args) { for (String arg : args) { System.out.println(arg); } } }
我们可以利用接收到的命令行参数,根据不同的参数执行不同的代码。例如,实现一个-version参数,打印程序版本号:
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { for (String arg : args) { if ("-version" .equals(arg)) { System.out.println("v 1.0" ); break ; } } } }
上面这个程序必须在命令行执行,我们先编译它:
然后,执行的时候,给它传递一个-version参数:
1 2 $ java Main -version v 1.0
这样,程序就可以根据传入的命令行参数,作出不同的响应。
小结
命令行参数类型是String[]数组;
命令行参数由JVM接收用户输入并传给main方法;
如何解析命令行参数需要由程序自己实现。
留言與分享