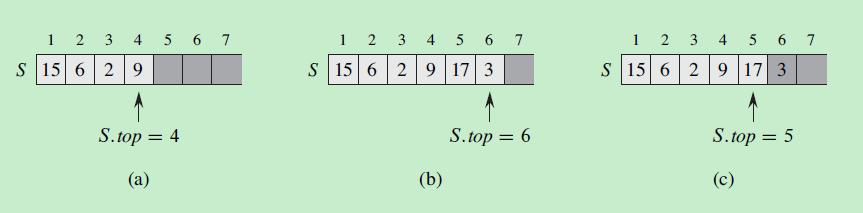
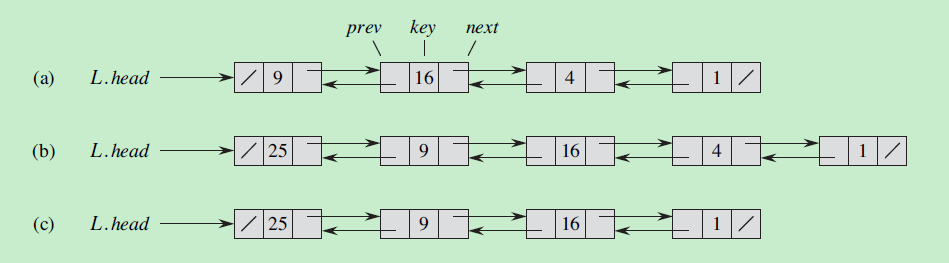
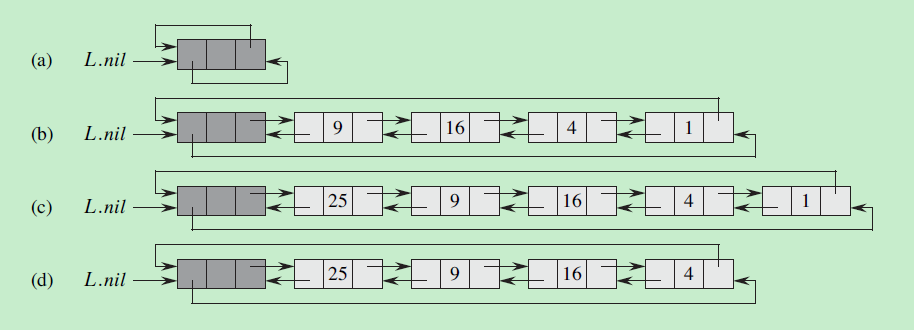
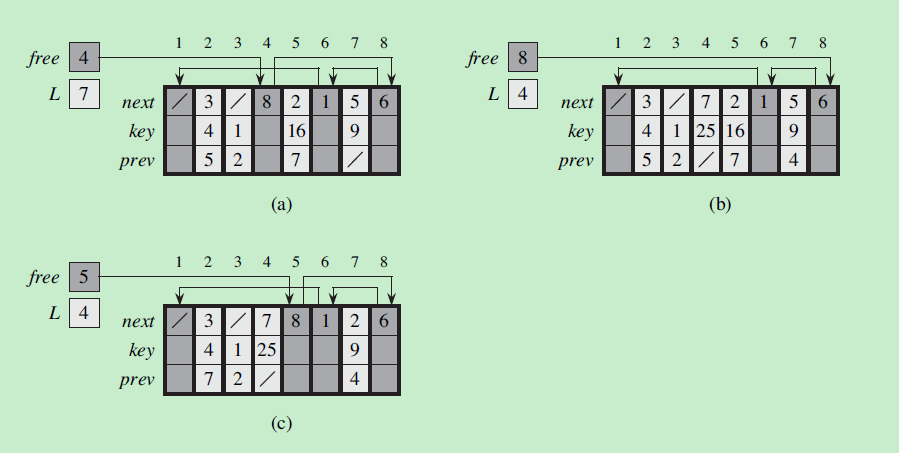
11. 散列表(哈希表)
许多应用都需要一种动态集合,至少支持Insert,Search和Delete的字典操作。
散列表(Hash Table)是实现字典操作的一种有效数据结构。尽管最坏情况下散列表查询一个元素的时间和链表的查询时间相同,为Θ(n)。但是在实际应用中,散列表的查询性能是极好的。在一些合理的假设下,散列表中扎寻一个元素的平均时间能为Ο(1)。
假设某应用需要用到一个动态集合,其中每个元素的KEY都是取自全域U={0, 1, …, m-1}。本章讨论方法都是基于这样的动态集合。
直接寻址表
当KEY的全域U较小时,直接寻址表是一种简单而有效的技术。
为了表示这个动态集合,我们用一个数组作为直接寻址表,记为T[0…m-1],其中数组的每个位置称为槽,与全域U中的KEY一一对应。
K集合表示实际存在的元素的KEY集合。
槽k指向KEY为k的元素,如果K集合中没有k,那么T[k] = nil。

散列表
直接寻址表的缺点很明显:
- 如果全域U非常大,则计算机无法存储
- 如果K集合相对于全域U非常小,那么将非常浪费空间
如果直接寻址表占用的存储空间为,那么散列表能将存储需求降至,同时散列表中查找一个元素的时间为,不过是平均时间。
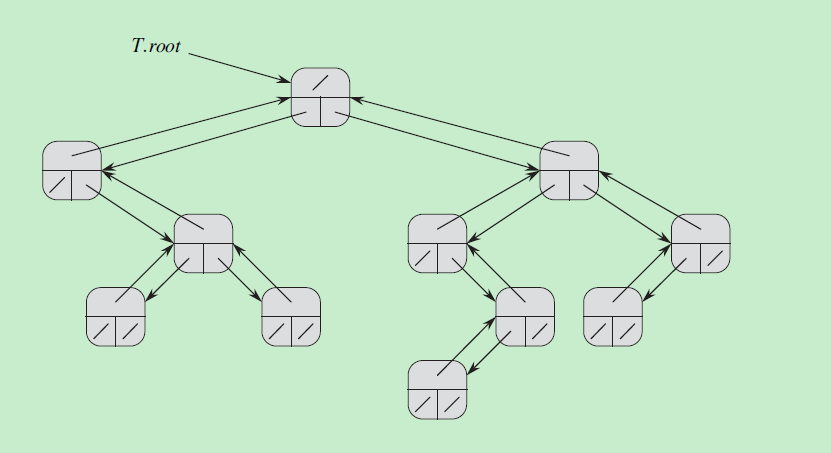
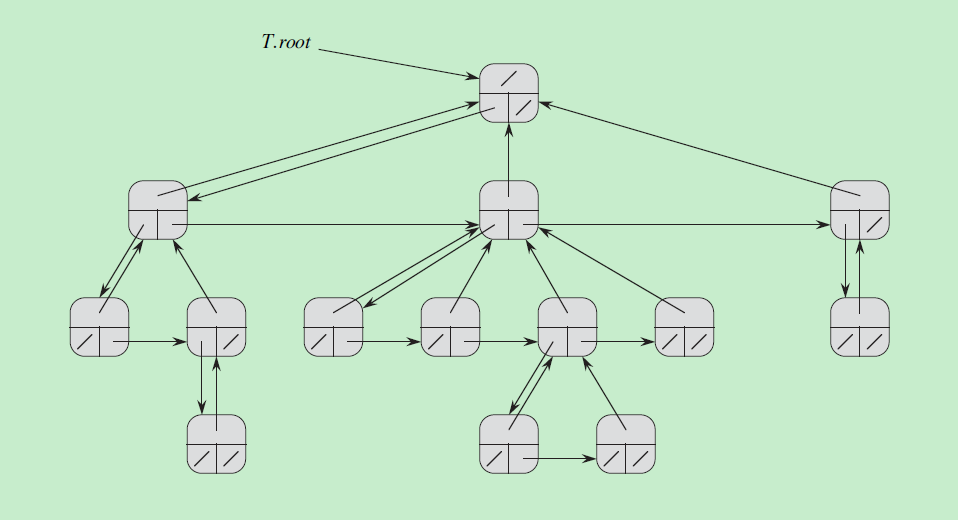
散列方式不同于直接寻址表的地方是,元素存储在散列表中的位置由散列函数决定,即k元素存储在散列表的h(k)位置。h(k)叫做k的散列值。
散列表T的大小比|U|小很多,所以肯定会有冲突的情况。

冲突最简单的解决方式是使用链接法,后面还介绍一种开放寻址法。
下图是链接法的图示,当有两个k值映射到了同一个散列值时,将它们保存在一个链表内。

链接法散列分析
如果要将n个数据存储在m大小的散列表中,我们称α = n/m为装载因子,即散列表的每个槽平均存放的数据。
假设散列函数能等可能的把数据散列到m个槽中,我们称这个假设为简单均匀散列。
这时每个槽存放元素个数的期望值为α。
所以,一次不成功查找的平均时间为。(1 表示散列函数消耗的时间)
1 | 因为每个槽的期望为α,而不成功的情况下,查找的期望时间就是从槽链表的头遍历到链表尾,所以期望时间就是槽链表的长度α。 |
一次成功查找的平均时间为。
1 | 具体证明参考公开课中老师的推理,或者书中推理。 |
散列函数
最好的散列函数便是能达到简单均匀散列。
下面介绍一些的散列函数。其中全域散列能够达到这样的要求。
除法散列
1 | h(k) = k mod m |
m最好是一个素数,并且不能太接近2或者10的乘方。
乘法散列
1 | h(k) = [(a * k) mod 2^w] >> (w − r) |
k是w bits的数
m = 2^r
a最好是一个奇数,并且不能太接近2或者10的乘方。

全域散列
随机的选择散列函数,称为全域散列
Example:
1 | h(k) = [(ak+b) mod p] mod m |
证明全域散列为简单均匀散列的过程,参考公开课中老师的推理,或者书中推理。
开放寻址法
- 无链表,所有的元素都保存在table中
- 每个槽存储一个元素,m>=n
- 散列函数为h(k, i),i从0开始,当有冲突后i++,直到找到一个空的位置,所以散列函数需要有如下性质:
1 | 对同一个KEY做m次探查,能把散列表填满 |
删除时,不能直接删除!删除后需要标记此位为删除位。
线性探查
1 | h(k, i) = (h1(k) +i) mod m |
双重探查
1 | h(k, i) =(h1(k) + i·h2(k)) mod m |
开放寻址法分析
给定一个装载因子α = n/m < 1的开放寻址散列表,并假设是均匀散列的:
对于一次不成功的查找,期望的探查次数至多为1/(1-α)
对于一次成功的查找,期望的探查次数至多为\frac{1}{α}\ln(1/(1-α))
完全散列
基于全域散列,完全没看。。。
涉及数据结构
点击查看实现