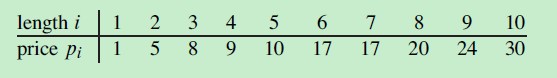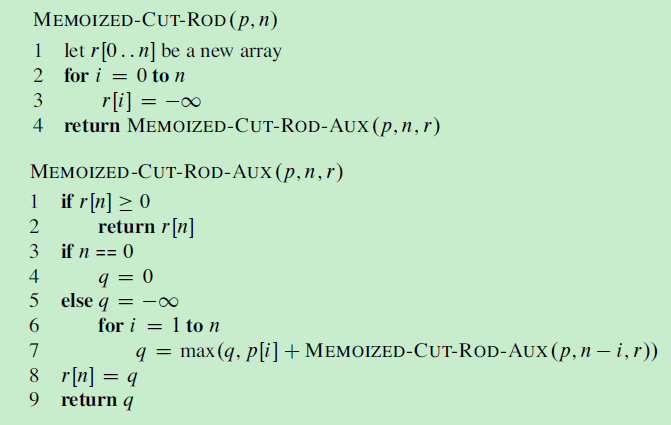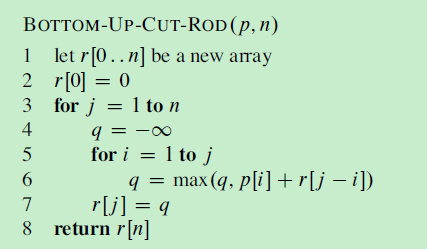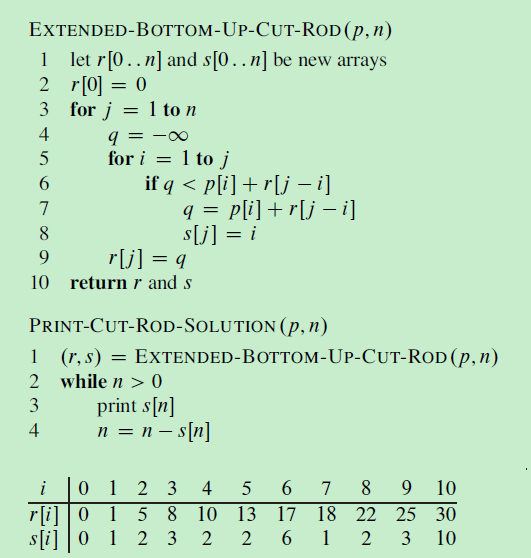16. 贪心算法
求解最优化问题的算法通常需要经过一系列的步骤,在每个步骤都面临多种选择。对于许多最优化问题,使用动态规划算法来求最优解有些杀鸡用牛刀了,可以使用更简单、更高效的算法.贪心算法就是这样的算法,它在每一步都做出当时看起来最佳的选择。也就是说,它总是做出局部最优的选择,寄希望这样的选择能导致全局最优解。
活动选择问题
我们的第一个例子是一个调度竞争共享资源的多个活动的问题,目标是选出一个最大的互相兼容的活动集合。假定有一个 n 个活动的集合S=a1,a2,...,an,这些活动使用同一个资源(例如一个阶梯教室),而这个资源在某个时刻只能供一个活动使用。每个活动ai都有一个开始时间si和一个结束时间fi ,其中0≤si<fi<∞。如果被选中,任务ai发生在半开时间区间[si,fi)期间.如果两个活动ai和aj满足[si,fi)和[sj,fj)不重叠,则称它们是兼容的.也就是说,若si≥fj或sj≥fi,则ai和aj是兼容的.在活动选择问题中,我们希望选出一个最大兼容活动集。假定活动已按结束时间的单调递增顺序排序:
f1≤f2≤f3≤...≤fn−1≤fn
例如下面的活动集合S:
| i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
| si |
1 |
3 |
0 |
5 |
3 |
5 |
6 |
8 |
8 |
2 |
12 |
| fi |
4 |
5 |
6 |
7 |
9 |
9 |
10 |
11 |
12 |
14 |
16 |
对于这个例子,子集S=a3,a9,a11由相互兼容的活动组成。但它不是一个最大集,因为子集S=a1,a4,a8,a11更大。实际上S=a1,a4,a8,a11是一个最大兼容活动子集,另一个最大子集是
S=a2,a4,a9,a11。
最优子结构
假定集合Sij(ai结束之后,aj开始之前的活动)的一个最大相互兼容的活动子集为Aij,而且Aij包含了活动ak。 由于最优解包含了活动ak,我们得到两个子问题:Sik(ak开始之前的活动)的兼容活动 和 Skj(ak结束之后的活动)的兼容活动。由剪切-粘贴法可以证明Sij的最优解为Sik的最优解、ak、 Skj的最优解组成。即Aij=Aik∪ak∪Akj。
所以这时我们可以用动态规划方法求出所有k的取值情况对应的解,然后找出一个最大的作为最优解。
如果用c[i,j]表示Sij的最优解的大小,递归式为:
c[i,j]={0ak∈Sijmax{c[i,k]+c[k,j]+1}ifSij=∅,ifSij≠∅,
贪心选择
动态规划需要考虑每种子问题,比较之后得出哪种选择是最优解。假如我们无需求解每种子问题,直接就可以找出一个最优选择。那么将大大减少计算过程。对于活动选择问题,我们可以只考虑一个选择:贪心选择。
直观上,我们应该选择一个活动,使得选择它后剩下的资源可以尽可能多的被其他活动利用。直觉告诉我们选择S中最早结束的活动,因为他可以剩下尽可能多的资源。由于我们活动时按照结束时间排序的,也就是说贪心选择就是a1。
当做出贪心选择后,只剩下一个子问题需要求解,因为不会有在a1开始前结束的活动。加上前面的最优子结构性质,所以S的最优解就是a1⋃A1n。
证明贪心选择——最早结束的活动总是最优解的一部分:
定理: 考虑任意非空子问题Sk,另am是Sk种最早结束的活动,则am在Sk的某个最大兼容活动子集中。
证明: Ak是Sk的某个最大兼容活动子集,aj是Ak种最早结束的活动。如果aj=am,则已经证明am在Sk的某个最大兼容活动子集中;如果aj≠am,那么用am替换Ak中的aj产生Ak′,由于fm≤fj而且Ak中的活动都是不相交的,所以Ak′也是Sk的最大兼容活动子集,得证。
递归贪心算法
为了方便算法初始化,添加一个虚拟活动a0,其结束时间f0=0,这样子问题S0就是完整的活动集S。求解原问题即可调用 RECURSIVE-ACTIVITY-SELECTOR(s, f, 0, n)。

2,3行是为了找到第一个,与ak不相交的最先结束的活动am。
迭代贪心算法
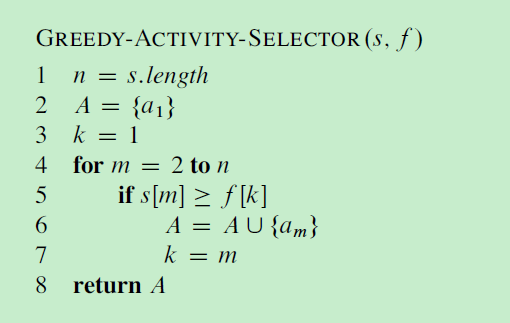
贪心算法原理
前面我们讨论活动选择问题的贪心算法的过程比通常的过程繁琐一些,我们当时经过了如下几个步骤:
- 确定问题的最优子结构.
- 设计一个递归算法(动态规划)。
- 证明如果我们做出一个贪心选择,则只剩下一个子问题。
- 证明贪心选择总是安全的(步骤 3 、 4 的顺序可以调换)。
- 设计一个递归算法实现贪心策略。
- 将递归算法转换为迭代算法。
这个过程详细的看到贪心算法是如何以动态规划为基础的。
更一般地,我们可以简单按如下步骤设计贪心算法:
- 将最优化问题转化为这样的形式:对其做出一次选择后,只剩下一个子问题需要求解。
- 证明做出贪心选择后,原问题总是存在最优解,即贪心选择总是安全的。
- 证明做出贪心选择后,剩余的子问题满足性质:其最优解与贪心选择组合即可得到原问题的最优解,这样就得到了最优子结构。
在本章剩余部分中,我们将使用这种更直接的设计方法.但我们应该知道,在每个贪心算法之下,几乎总有一个更繁琐的动态规划算法。
在证明一个问题可以用贪心算法解决过程中,证明一个问题的贪心选择性质 和 最优子结构性质 是非常重要的。
赫夫曼编码
赫夫曼编码k而已有效的压缩数据:通常可以节省20%~90%的空间,具体压缩率依赖于数据的特型。我们将待压缩数据看做字符序列。根据每个字符出现的频率,赫夫曼贪心算法构造出字符的最优二进制表示。
下面给出一个例子,待压缩文件有10万个字符数据。文件中出现了6种不同的字符,出现的次数见表格:
|
a |
b |
c |
d |
e |
f |
| 频率(千次) |
45 |
13 |
12 |
16 |
9 |
5 |
| 定长编码 |
000 |
001 |
010 |
011 |
100 |
101 |
| 变长编码 |
0 |
101 |
100 |
111 |
1101 |
1100 |
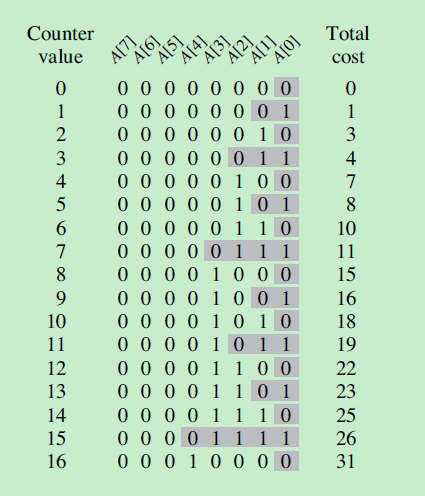
如果用定长编码来存储信息,那么需要用3位来表示z和6个字符。这种方法总共需要300000个二进制位来存储。
但如果用变长编码来存储信息,如表格中所示,出现频率较高字符的使用短一点的二进制编码表示。这种方法需要(45×1+13×3+12×3+16×3+9×4+5×4)×1000=224000位。与定长编码相比节约了25%的空间。
我们这里只考虑前缀码,即没有任何码字是其他码字的前缀。只考虑前缀码的原因是,前缀码与任何其他编码方式比都可以保证最优的压缩率,但此处不予证明。
前缀码的作用是简化解码过程,由于没有任何码字是其他码字的前缀,所以文件开头的码字是无歧义的。我们可以简单的识别出开始码字,将其转换为对应的字符,然后对文件剩余部分重复的做这种解码过程。
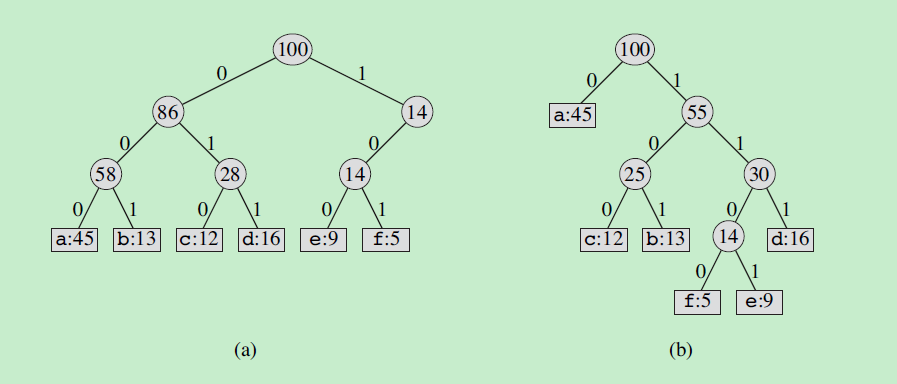
编码方案可以用一个二叉树表示——编码树。下图a表示了定长编码的编码树,图b表示了变长编码的编码树。叶子结点为字符,并存储字符的出现频率,字符的二进制编码是从根节点到叶子节点的路径,向左表示0,向右表示1。内部结点不存储字符,存储子节点的频率和。
给定一棵对应前缀码的树T,我们可以容易地计算出编码一个文件需要多少个二进制位。对于字母表C中的每个字符c,令属性c.freq表示c在文件中出现的频率,令dT(c)表示c的叶结点在树中的深度。注意,dT(c)也是字符c的码字的长度。则编码文件需要习:
B(T)=c∈C∑c.freq⋅dT(c)
个二进制位,我们将B(T)定义为T的代价。
构造赫夫曼编码
赫夫曼设计了一个贪心算法得到最优前缀码,被称为赫夫曼编码。
下面是哈夫曼算法的伪代码,输入一个字母表C,输出一个最优前缀码对应的编码树。

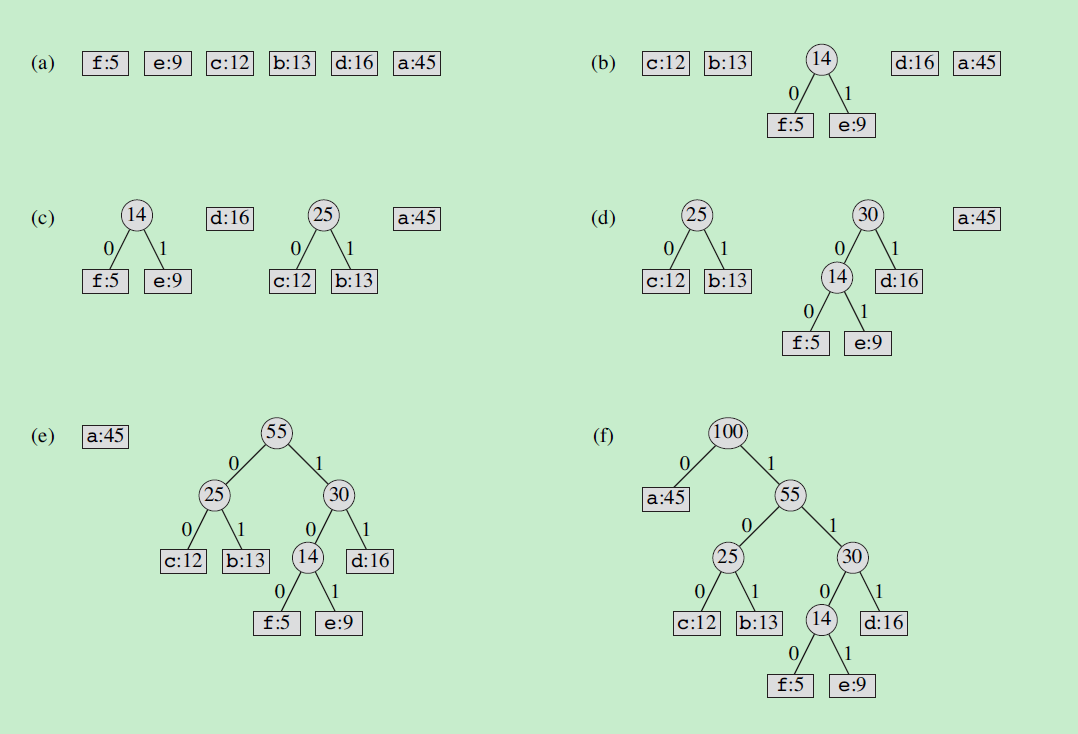
构造编码树的过程如下:
算法中使用一个优先队列Q,初始化时将字母表C全部插入Q。每次循环时,创造一个结点z,从优先队列取出两个最小值作为结点z的孩子,并使得z.freq为两个孩子的freq之和,然后将z结点重新插入优先队列Q中。直到优先队列中只剩下一个元素,这时这个元素为编码树的root结点,并且所有字符都已加入编码树。
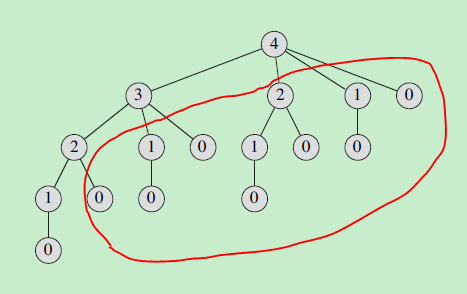
下面是一个例子:
证明赫夫曼算法的正确性
贪心选择
贪心选择性质:若x,y是C中频率最低的两个字符。那么C存在一个最优前缀码,x,y的码字长度相等,且只有最后一个二进制位不同。
证明思路,假设有一个最优前缀码的编码树T,把x,y与编码树中深度最深的两个兄弟节点进行交换产生T′。通过计算得出B(T′)≤B(T)。
最优子结构
最优子结构性质:若x,y是C中频率最低的两个字符。令C′为C去除x和y,然后加入字符z,且z.freq=x.freq+y.freq。T′为C′的一个最优前缀码的编码树,将T′中的叶子节点z替换为一个以x,y为子节点的内部节点得到树T。则T为C的一个最优前缀码的编码树。
证明思路,反证法,假设C存在一个T′′比T更优,由贪心选择性质可知x,y为兄弟节点(不一定吧?书中用不失一般性,不太理解),将T′′中的x,y替换为z得到T′′′,结果得到B(T′′′)<B(T′),与T′为C′的一个最优前缀码的编码树的假设相悖。
涉及算法
点击查看实现
留言與分享