7. 快速排序
快速排序是一种最坏情况时间复杂度为的排序算法,虽然最坏情况的时间复杂度很差,但是快速排序通常是实际排序应用中最好的选择,因为它的平均性能非常好,它的期望时间复杂度是,而且中隐含的常数因子非常小。另外它是原址排序。
快速排序
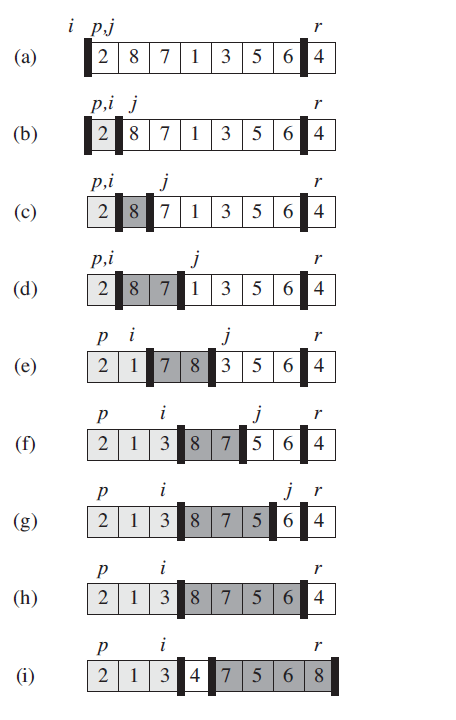
快速排序也用了分治的思想。对子数组A[p…r]进行快速排序的过程如下:
分解 将A[p…r]划分为两个数组A[p…q-1]和A[q+1…r],使得A[p…q-1]的每一个元素小于等于A[q],而A[q+1…r]的每一个元素大于等于A[q]。
解决 递归调用快速排序,对子数组A[p…q-1]和A[q+1…r]进行排序。
合并 因为是原址操作,所以无需合并,这时A[p…r]已经有序。
伪代码和分解过程如下:


性能
最坏情况
若每次分解时,都分解为一个空数组和一个n-1大小的数组,则为最坏情况。
递归式为
的解为
最好情况
若每次分解时,都分解为两个一样大的子问题,这时为最好情况。
递归式为
的解为
平衡的划分
若每次分解时,都按照一定比例分割,比如按照9:1划分。
递归式为
的解为
可用代入法证明按照任何比例划分,的解都为
平均情况
若每次分解时,最好情况和最坏情况交替出现。
的解为
可以将最好情况和最坏情况合并,时间复杂度并没变
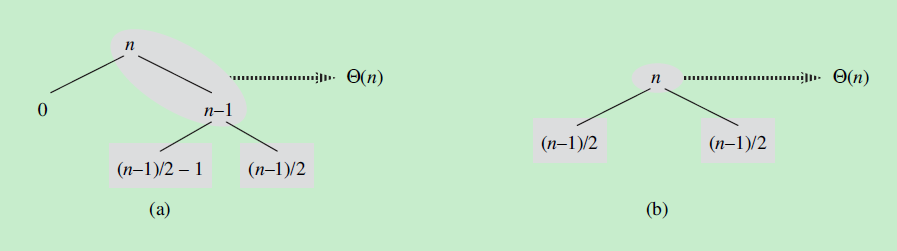
随机快速排序
随机快速排序可以避免特定输入(已排序的队列或逆序列)时运行时间较长的情况。
分解时,随机的挑选数组中的一个元素来分解。
TODO: 证明随机快速排序的期望运行时间
涉及算法
点击查看实现