R CSV 文件
R 作为统计学专业工具,如果只能人工的导入和导出数据将使其功能变得没有意义,所以 R 支持批量的从主流的表格存储格式文件(例如 CSV、Excel、XML 等)中获取数据。
CSV 表格交互
CSV(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号) 是一种非常流行的表格存储文件格式,这种格式适合储存中型或小型数据规模的数据。
由于大多数软件支持这个文件格式,所以常用于数据的储存与交互。
CSV 本质是文本,它的文件格式极度简单:数据一行一行的用文本保存起来而已,每条记录被分隔符分隔为字段,每条记录都有同样的字段序列。
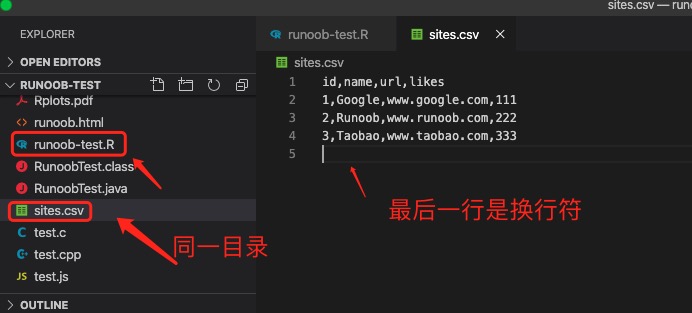
以下是一个简单的 sites.csv 文件(存储在测试程序的相同目录下):
1 2 3 4 5 id,name,url,likes 1,Google,www.google.com,111 2,Runoob,www.runoob.com,222 3,Taobao,www.taobao.com,333
CSV 用逗号来分割列,如果数据中含有逗号,就要用双引号将整个数据块包括起来。
**注意:**包含非英文字符的文本要注意保存的编码,由于很多计算机普遍使用 UTF-8 编码,所以我是用 UTF-8 进行保存的。
注意: CSV 文件最后一行需要保留一个空行,不然执行程序会有警告信息。
1 2 3 Warning message: In read.table(file = file, header = header, sep = sep, quote = quote, : incomplete final line found by readTableHeader on 'sites.csv'
读取 CSV 文件
接下来我们就可以使用 read.csv() 函数来读取 CSV 文件的数据:
实例
1 2 data <- read.csv("sites.csv", encoding\="UTF-8") print(data)
如果不设置 encoding 属性,read.csv 函数将默认以操作系统默认的文字编码进行读取,如果你使用的是 Windows 中文版系统且没有设置过系统的默认编码,那系统的默认编码应该是 GBK。所以大家请尽可能地统一文字编码以防出错。
执行以上代码输出结果为:
1 2 3 4 id name url likes 1 1 Google www.google.com 111 2 2 Runoob www.runoob.com 222 3 3 Taobao www.taobao.com 333
read.csv() 函数返回的是数据框,我们可以很方便的对数据进行统计处理,以下实例我们查看行数和列数:
实例
1 2 3 4 5 data <- read.csv("sites.csv", encoding\="UTF-8") print(is.data.frame(data)) \# 查看是否是数据框 print(ncol(data)) \# 列数 print(nrow(data)) \# 行数
执行以上代码输出结果为:
以下统计数据框中 likes 字段最大对数据:
实例
1 2 3 4 5 data <- read.csv("sites.csv", encoding\="UTF-8") \# likes 最大的数据 like <- max(data$likes) print(like)
执行以上代码输出结果为:
我们也可以指定查找条件,类似 SQL where 子句一样查询数据,需要用到到函数是 subset() 。
以下实例查找 likes 为 222 到数据:
实例
1 2 3 4 5 data <- read.csv("sites.csv", encoding\="UTF-8") \# likes 为 222 的数据 retval <- subset(data, likes \== 222) print(retval)
执行以上代码输出结果为:
1 2 id name url likes 2 2 Runoob www.runoob.com 222
注意 :条件语句等于使用 ==。
多个条件使用 & 分隔符,以下实例查找 likes 大于 1 name 为 Runoob 的数据:
实例
1 2 3 4 5 data <- read.csv("sites.csv", encoding\="UTF-8") \# likes 大于 1 name 为 Runoob 的数据 retval <- subset(data, likes \> 1 & name\=="Runoob") print(retval)
执行以上代码输出结果为:
1 2 id name url likes 2 2 Runoob www.runoob.com 222
保存为 CSV 文件
R 语言可以使用 write.csv() 函数将数据保存为 CSV 文件。
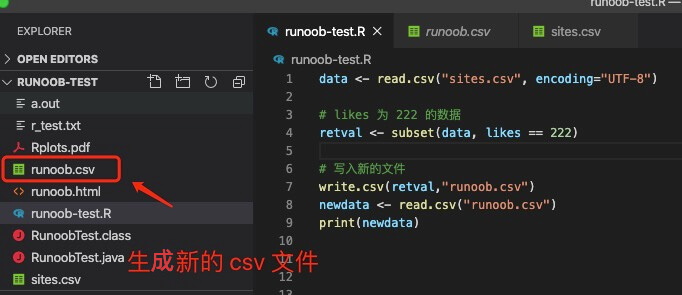
接着以上实例,我们将 likes 为 222 的数据 保存到 runoob.csv 文件:
实例
1 2 3 4 5 6 7 8 9 data <- read.csv("sites.csv", encoding\="UTF-8") \# likes 为 222 的数据 retval <- subset(data, likes \== 222) \# 写入新的文件 write.csv(retval,"runoob.csv") newdata <- read.csv("runoob.csv") print(newdata)
执行以上代码输出结果为:
1 2 X id name url likes 1 2 2 Runoob www.runoob.com 222
X 来自数据集 newper,可以通过参数 row.names = FALSE 来删除它:
实例
1 2 3 4 5 6 7 8 9 data <- read.csv("sites.csv", encoding\="UTF-8") \# likes 为 222 的数据 retval <- subset(data, likes \== 222) \# 写入新的文件 write.csv(retval,"runoob.csv", row.names \= FALSE) newdata <- read.csv("runoob.csv") print(newdata)
执行以上代码输出结果为:
1 2 id name url likes 1 2 Runoob www.runoob.com 222
执行完后,我们就可以看到 runoob.csv 文件生存:
R Excel 文件
Excel 格式的文件主要是 xls 或 xlsx,这两种文件可以在 R 语言中导入 xlsx 库来实现直接的读取。
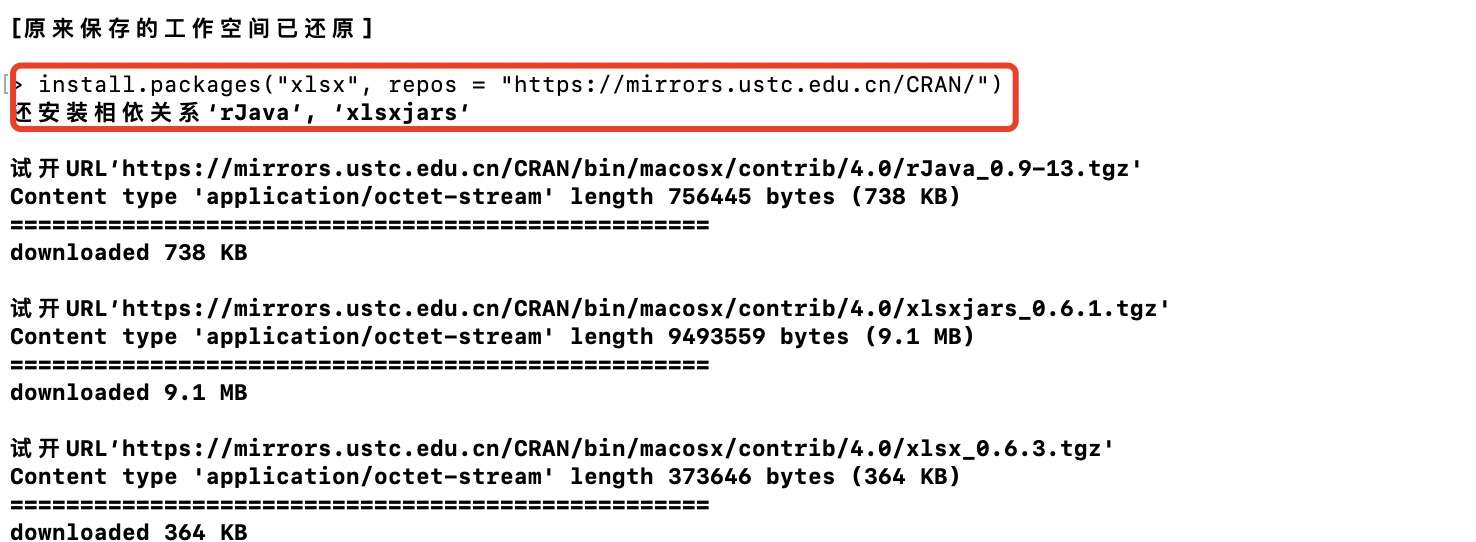
R 语言读写 Excel 文件需要安装扩展包,我们可以在 R 到控制台输入以下命令来安装:
1 install.packages("xlsx", repos = "https://mirrors.ustc.edu.cn/CRAN/")
安装过程如下:
事实上,几乎所有的 Excel 软件与大多数表格软件一样支持 CSV 格式的数据,所以完全可以通过 CSV 与 R 交互,没必要再使用 Excel。
查看 xlsx 是否安装成功:
实例
1 2 3 4 5 \# 验证包是否安装 any(grepl("xlsx",installed.packages())) \# 载入包 library("xlsx") library("xlsx")
执行以上代码输出结果为:
1 2 3 4 [1] TRUE Loading required package: rJava Loading required package: methods Loading required package: xlsxjars
Excel 文件数据:
点击链接下载 Excel 测试数据:https://static.jyshare.com/download/sites.xlsx
接下来,我们可以使用 read.xlsx() 函数来读取 Excel 数据:
实例
1 2 3 \# 读取 sites.xlsx 第一个工作表数据 data <- read.xlsx("sites.xlsx", sheetIndex \= 1) print(data)
R XML 文件
XML 指的是可扩展标记语言(eXtensible Markup Language),XML 被设计用来传输和存储数据。
如果你对 XML 还不了解,可以先查阅:XML 教程
R 语言读写 XML 文件需要安装扩展包,我们可以在 R 到控制台输入以下命令来安装:
1 install.packages("XML", repos = "https://mirrors.ustc.edu.cn/CRAN/")
查看是否安装成功:
1 2 > any(grepl("XML",installed.packages())) [1] TRUE
创建 sites.xml 文件,xml 文件与测试脚本同一目录下,代码如下:
实例
1 <sites\> <site\> <id\>1</id\> <name\>Google</name\> <url\>www.google.com</url\> <likes\>111</likes\> </site\> <site\> <id\>2</id\> <name\>Runoob</name\> <url\>www.runoob.com</url\> <likes\>222</likes\> </site\> <site\> <id\>3</id\> <name\>Taobao</name\> <url\>www.taobao.com</url\> <likes\>333</likes\> </site\> </sites\>
接下来我们可以使用 XML 包来载入 xml 文件的数据:
实例
1 2 3 4 5 6 7 8 \# 载入 XML 包 library("XML") \# 设置文件名 result <- xmlParse(file \= "sites.xml") \# 输出结果 print(result)
统计 xml 数据量:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 \# 载入 XML 包 library("XML") \# 设置文件名 result <- xmlParse(file \= "sites.xml") \# 提取根节点 rootnode <- xmlRoot(result) \# 统计数据量 rootsize <- xmlSize(rootnode) \# 输出结果 print(rootsize)
执行以上代码输出结果为:
查看节点数据,某一行使用 [ ], 指定的行和列使用 [[ ]]:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \# 载入 XML 包 library("XML") \# 设置文件名 result <- xmlParse(file \= "sites.xml") \# 提取根节点 rootnode <- xmlRoot(result) \# 查看第 2 个节点数据 print(rootnode\[2\]) \# 查看第 2 个节点的第 1 个数据 print(rootnode\[\[2\]\]\[\[1\]\]) \# 查看第 2 个节点的第 3 个数据 print(rootnode\[\[2\]\]\[\[3\]\])
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 $site <site> <id>2</id> <name>Runoob</name> <url>www.runoob.com</url> <likes>222</likes> </site> attr(,"class") [1] "XMLInternalNodeList" "XMLNodeList" <id>2</id> <url>www.runoob.com</url>
XML 转为数据列表
以上代码对输出都是 xml 格式,我们使用 xmlToList() 函数可以将文件对数据转为列表格式,更方便读取:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 \# 载入 XML 包 library("XML") \# 设置文件名 result <- xmlParse(file \= "sites.xml") \# 转为列表 xml\_data <- xmlToList(result) print(xml\_data) print("============================") \# 输出第一行第二列的数据 print(xml\_data\[\[1\]\]\[\[2\]\])
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 $site $site$id [1] "1" $site$name [1] "Google" $site$url [1] "www.google.com" $site$likes [1] "111" $site $site$id [1] "2" $site$name [1] "Runoob" $site$url [1] "www.runoob.com" $site$likes [1] "222" $site $site$id [1] "3" $site$name [1] "Taobao" $site$url [1] "www.taobao.com" $site$likes [1] "333" [1] "============================" [1] "Google"
XML 转为数据框
XML 文件数据可以转为数据框类型,这样我们就更方便对数据进行操作:
实例
1 2 3 4 5 6 \# 载入 XML 包 library("XML") \# xml 文件数据转为数据框 xmldataframe <- xmlToDataFrame("sites.xml") print(xmldataframe)
执行以上代码输出结果为:
1 2 3 4 id name url likes 1 1 Google www.google.com 111 2 2 Runoob www.runoob.com 222 3 3 Taobao www.taobao.com 333
R JSON 文件
JSON: J avaS cript O bject N otation(JavaScript 对象表示法)。
JSON 是存储和交换文本信息的语法。
JSON 类似 XML,但比 XML 更小、更快,更易解析。
如果你对 JSON 还不了解,可以先查阅:JSON 教程
R 语言读写 JSON 文件需要安装扩展包,我们可以在 R 到控制台输入以下命令来安装:
1 install.packages("rjson", repos = "https://mirrors.ustc.edu.cn/CRAN/")
查看是否安装成功:
1 2 > any(grepl("rjson",installed.packages())) [1] TRUE
创建 sites.json 文件,json 文件与测试脚本同一目录下,代码如下:
实例
1 { "id":\["1","2","3"\], "name":\["Google","Runoob","Taobao"\], "url":\["www.google.com","www.runoob.com","www.taobao.com"\], "likes":\[ 111,222,333\] }
接下来我们可以使用 rjson 包来载入 json 文件的数据。
查看数据,某一行使用 [ ], 指定的行和列使用 [[ ]]:
实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 \# 载入 rjson 包 library("rjson") \# 获取 json 数据 result <- fromJSON(file \= "sites.json") \# 输出结果 print(result) print("===============") \# 输出第 1 列的结果 print(result\[1\]) print("===============") \# 输出第 2 行第 2 列的结果 print(result\[\[2\]\]\[\[2\]\])
执行以上代码输出结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 $id [1] "1" "2" "3" $name [1] "Google" "Runoob" "Taobao" $url [1] "www.google.com" "www.runoob.com" "www.taobao.com" $likes [1] 111 222 333 [1] "===============" $id [1] "1" "2" "3" [1] "===============" [1] "Runoob"
我们也可以使用 as.data.frame() 函数将 json 文件数据可以转为数据框类型,这样我们就更方便对数据进行操作:
实例
1 2 3 4 5 6 7 8 9 10 \# 载入 rjson 包 library("rjson") \# 获取 json 数据 result <- fromJSON(file \= "sites.json") \# 转为数据框 json\_data\_frame <- as.data.frame(result) print(json\_data\_frame)
执行以上代码输出结果为:
1 2 3 4 id name url likes 1 1 Google www.google.com 111 2 2 Runoob www.runoob.com 222 3 3 Taobao www.taobao.com 333
R MySQL 连接
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
如果你对 MySQL 还不了解,可以先查阅:MySQL 教程
R 语言读写 MySQL 文件需要安装扩展包,我们可以在 R 到控制台输入以下命令来安装:
1 install.packages("RMySQL", repos = "https://mirrors.ustc.edu.cn/CRAN/")
查看是否安装成功:
1 2 > any(grepl("RMySQL",installed.packages())) [1] TRUE
MySQL 目前被甲骨文收购,所以很多人使用来它的复制版本 MariaDB,MariaDB 在 GNU GPL下开源,MariaDB 的开发是由 MySQL 的一些原始开发者领导的,所以语法操作都差不多:
1 install.packages("RMariaDB", repos = "https://mirrors.ustc.edu.cn/CRAN/")
在 test 数据库中创建数据表 runoob,表结构及数据代码如下:
实例
1 \-- -- 表的结构 \`runoob\` \-- CREATE TABLE \`runoob\` ( \`id\` int(11) NOT NULL, \`name\` char(20) NOT NULL, \`url\` varchar(255) NOT NULL, \`likes\` int(11) NOT NULL ) ENGINE\=InnoDB DEFAULT CHARSET\=utf8mb4; \-- -- 转存表中的数据 \`runoob\` \-- INSERT INTO \`runoob\` (\`id\`, \`name\`, \`url\`, \`likes\`) VALUES (1, 'Google', 'www.google.com', 111), (2, 'Runoob', 'www.runoob.com', 222), (3, 'Taobao', 'www.taobao.com', 333);
接下来我们可以使用 RMySQL 包来读取数据:
实例
1 2 3 4 5 6 7 library(RMySQL) \# dbname 为数据库名,这边的参数请根据自己实际情况填写 mysqlconnection \= dbConnect(MySQL(), user \= 'root', password \= '', dbname \= 'test',host \= 'localhost') \# 查看数据 dbListTables(mysqlconnection)
接下来我们可以使用 dbSendQuery 来读取数据库的表,结果集通过 fetch() 函数来获取:
实例
1 2 3 4 5 6 7 library(RMySQL) \# 查询 sites 表,增删改查操作可以通过第二个参数的 SQL 语句来实现 result \= dbSendQuery(mysqlconnection, "select \* from sites") \# 获取前面两行数据 data.frame \= fetch(result, n \= 2) print(data.frame)
留言與分享

 R 语言实例
R 语言实例