
Terraform-模块
1.6.1. Terraform模块
到目前为止我们介绍了一些代码书写的知识,但我们创建的所有资源和数据源的代码都是我们在代码文件中编写出来的。我们有没有办法不通过复制粘贴代码从而直接使用别人编写好的 Terraform 代码来创建一组资源呢?
Terraform 对此给出的答案就是模块 (Module)。简单来讲模块就是包含一组 Terraform 代码的文件夹,我们之前篇章中编写的代码实际上也是在模块中。要想真正理解模块的功能,我们需要去体验一下模块的使用。
Terraform 模块是编写高质量 Terraform 代码,提升代码复用性的重要手段,可以说,一个成熟的生产环境应该是由数个可信成熟的模块组装而成的。我们将在本章介绍关于模块的知识。
1.6.1.1. 创建模块
实际上所有包含 Terraform 代码文件的文件夹都是一个 Terraform 模块。我们如果直接在一个文件夹内执行 terraform apply 或者 terraform plan 命令,那么当前所在的文件夹就被称为根模块(root module)。我们也可以在执行 Terraform 命令时通过命令行参数指定根模块的路径。
1.6.1.1.1. 模块结构
旨在被重用的模块与我们编写的根模块使用的是相同的 Terraform 代码和代码风格规范。一般来讲,在一个模块中,会有:
- 一个
README文件,用来描述模块的用途。文件名可以是README或者README.md,后者应采用 Markdown 语法编写。可以考虑在README中用可视化的图形来描绘创建的基础设施资源以及它们之间的关系。README中不需要描述模块的输入输出,因为工具会自动收集相关信息。如果在README中引用了外部文件或图片,请确保使用的是带有特定版本号的绝对 URL 路径以防止未来指向错误的版本 - 一个
LICENSE描述模块使用的许可协议。如果你想要公开发布一个模块,最好考虑包含一个明确的许可证协议文件,许多组织不会使用没有明确许可证协议的模块 - 一个 examples 文件夹用来给出一个调用样例(可选)
- 一个
variables.tf文件,包含模块所有的输入变量。输入变量应该有明确的描述说明用途 - 一个
outputs.tf文件,包含模块所有的输出值。输出值应该有明确的描述说明用途 - 嵌入模块文件夹,出于封装复杂性或是复用代码的目的,我们可以在 modules 子目录下建立一些嵌入模块。所有包含 README 文件的嵌入模块都可以被外部用户使用;不含
README文件的模块被认为是仅在当前模块内使用的(可选) - 一个
main.tf,它是模块主要的入口点。对于一个简单的模块来说,可以把所有资源都定义在里面;如果是一个比较复杂的模块,我们可以把创建的资源分布到不同的代码文件中,但引用嵌入模块的代码还是应保留在main.tf里 - 其他定义了各种基础设施对象的代码文件(可选)
如果模块含有多个嵌入模块,那么应避免它们彼此之间的引用,由根模块负责组合它们。
由于 examples/ 的代码经常会被拷贝到其他项目中进行修改,所有在 examples/ 代码中引用本模块时使用的引用路径应使用外部调用者可以使用的路径,而非相对路径。
一个最小化模块推荐的结构是这样的:
1 | $ tree minimal-module/ |
一个更完整一些的模块结构可以是这样的:
1 | $ tree complete-module/ |
1.6.1.1.2. 避免过深的模块结构
我们刚才提到可以在 modules/ 子目录下创建嵌入模块。Terraform 倡导"扁平"的模块结构,只应保持一层嵌入模块,防止在嵌入模块中继续创建嵌入模块。应将嵌入模块设计成易于组合的结构,使得在根模块中可以通过组合各个嵌入模块创建复杂的基础设施。
1.6.2.1. 引用模块
在 Terraform 代码中引用一个模块,使用的是 module 块。
每当在代码中新增、删除或者修改一个 module 块之后,都要执行 terraform init 或是 terraform get 命令来获取模块代码并安装到本地磁盘上。
1.6.2.1.1. 模块源
module 块定义了一个 source 参数,指定了模块的源;Terraform 目前支持如下模块源:
- 本地路径
- Terraform Registry
- GitHub
- Bitbucket
- 通用Git、Mercurial仓库
- HTTP地址
- S3 buckets
- GCS buckets
我们后面会一一讲解这些模块源的使用。source 使用的是 URL 风格的参数,但某些源支持在 source 参数中通过额外参数指定模块版本。
出于消除重复代码的目的我们可以重构我们的根模块代码,将一些拥有重复模式的代码重构为可反复调用的嵌入模块,通过本地路径来引用。
许多的模块源类型都支持从当前系统环境中读取认证信息,例如环境变量或系统配置文件。我们在介绍模块源的时候会介绍到这方面的信息。
我们建议每个模块把期待被重用的基础设施声明在各自的根模块位置上,但是直接引用其他模块的嵌入模块也是可行的。
1.6.2.1.1.1. 本地路径
使用本地路径可以使我们引用同一项目内定义的子模块:
1 | module "consul" { |
一个本地路径必须以 ./ 或者 ../ 为前缀来标明要使用的本地路径,以区别于使用 Terraform Registry 路径。
本地路径引用模块和其他源类型有一个区别,本地路径引用的模块不需要下载相关源代码,代码已经存在于本地相关路径的磁盘上了。
1.6.2.1.1.2. Terraform Registry
Registry 目前是 Terraform 官方力推的模块仓库方案,采用了 Terraform 定制的协议,支持版本化管理和使用模块。
官方提供的公共仓库保存和索引了大量公共模块,在这里可以很容易地搜索到各种官方和社区提供的高质量模块。
读者也可以通过 Terraform Cloud 服务维护一个私有模块仓库,或是通过实现 Terraform 模块注册协议来实现一个私有仓库。
公共仓库的的模块可以用 <NAMESPACE>/<NAME>/<PROVIDER> 形式的源地址来引用,在公共仓库上的模块介绍页面上都包含了确切的源地址,例如:
1 | module "consul" { |
对于那些托管在其他仓库的模块,在源地址头部添加 <HOSTNAME>/ 部分,指定私有仓库的主机名:
1 | module "consul" { |
如果你使用的是 SaaS 版本的 Terraform Cloud,那么托管在上面的私有仓库的主机名是 app.terraform.io。如果使用的是私有部署的 Terraform 企业版,那么托管在上面的私有仓库的主机名就是 Terraform 企业版服务的主机名。
模块仓库支持版本化。你可以在 module 块中指定模块的版本约束。
如果要引用私有仓库的模块,你需要首先通过配置命令行工具配置文件来设置访问凭证。
1.6.2.1.1.3. GitHub
Terraform 发现 source 参数的值如果是以 github.com 为前缀时,会将其自动识别为一个 GitHub 源:
1 | module "consul" { |
上面的例子里会自动使用 HTTPS 协议克隆仓库。如果要使用 SSH 协议,那么请使用如下的地址:
1 | module "consul" { |
GitHub 源的处理与后面要介绍的通用 Git 仓库是一样的,所以他们获取 git 凭证和通过 ref 参数引用特定版本的方式都是一样的。如果要访问私有仓库,你需要额外配置 git 凭证。
1.6.2.1.1.4. Bitbucket
Terraform 发现 source 参数的值如果是以 bitbucket.org 为前缀时,会将其自动识别为一个 Bitbucket 源:
1 | module "consul" { |
这种捷径方法只针对公共仓库有效,因为 Terraform 必须访问 ButBucket API 来了解仓库使用的是 Git 还是 Mercurial 协议。
Terraform 根据仓库的类型来决定将它作为一个 Git 仓库还是 Mercurial 仓库来处理。后面的章节会介绍如何为访问仓库配置访问凭证以及指定要使用的版本号。
1.6.2.1.1.5. 通用 Git 仓库
可以通过在地址开头加上特殊的 git:: 前缀来指定使用任意的 Git 仓库。在前缀后跟随的是一个合法的 Git URL。
使用 HTTPS 和 SSH 协议的例子:
1 | module "vpc" { |
Terraform 使用 git clone 命令安装模块代码,所以 Terraform 会使用本地 Git 系统配置,包括访问凭证。要访问私有 Git 仓库,必须先配置相应的凭证。
如果使用了 SSH 协议,那么会自动使用系统配置的 SSH 证书。通常情况下我们通过这种方法访问私有仓库,因为这样可以不需要交互式提示就可以访问私有仓库。
如果使用 HTTP/HTTPS 协议,或是其他需要用户名、密码作为凭据,你需要配置 Git 凭据存储来选择一个合适的凭据源。
默认情况下,Terraform 会克隆默认分支。可以通过 ref 参数来指定版本:
1 | module "vpc" { |
ref 参数会被用作 git checkout 命令的参数,可以是分支名或是 tag 名。
使用 SSH 协议时,我们更推荐 ssh:// 的地址。你也可以选择 scp 风格的语法,故意忽略 ssh:// 的部分,只留 git::,例如:
1 | module "storage" { |
1.6.2.1.1.6. 通用 Mercurial 仓库
可以通过在地址开头加上特殊的 hg:: 前缀来指定使用任意的 Mercurial 仓库。在前缀后跟随的是一个合法的 Mercurial URL:
1 | module "vpc" { |
Terraform 会通过运行 hg clone 命令从 Mercurial 仓库安装模块代码,所以 Terraform 会使用本地 Mercurial 系统配置,包括访问凭证。要访问私有 Mercurial 仓库,必须先配置相应的凭证。
如果使用了 SSH 协议,那么会自动使用系统配置的 SSH 证书。通常情况下我们通过这种方法访问私有仓库,因为这样可以不需要交互式提示就可以访问私有仓库。
类似 Git 源,我们可以通过 ref 参数指定非默认的分支或者标签来选择特定版本:
1 | module "vpc" { |
1.6.2.1.1.7. HTTP 地址
当我们使用 HTTP 或 HTTPS 地址时,Terraform 会向指定 URL 发送一个 GET 请求,期待返回另一个源地址。这种间接的方法使得 HTTP 可以成为一个更复杂的模块源地址的指示器。
然后 Terraform 会再发送一个 GET 请求到之前响应的地址上,并附加一个查询参数 terraform-get=1,这样服务器可以选择当 Terraform 来查询时可以返回一个不一样的地址。
如果相应的状态码是成功的(200 范围的成功状态码),Terraform 就会通过以下位置来获取下一个访问地址:
- 响应头部的
X-Terraform-Get值 - 如果响应内容是一个 HTML 页面,那么会检查名为
terraform-get的 html meta 元素:
1 | <meta name="terraform-get" |
不管用哪种方式返回的地址,Terraform 都会像本章提到的其他的源地址那样处理它。
如果 HTTP/HTTPS 地址需要认证凭证,可以在 HOME 文件夹下配置一个 .netrc 文件,详见相关文档
也有一种特殊情况,如果 Terraform 发现地址有着一个常见的存档文件的后缀名,那么 Terraform 会跳过 terraform-get=1 重定向的步骤,直接将响应内容作为模块代码使用。
1 | module "vpc" { |
目前支持的后缀名有:
ziptar.bz2和tbz2tar.gz和tgztar.xz和txz
如果 HTTP 地址不以这些文件名结尾,但又的确指向模块存档文件,那么可以使用 archive 参数来强制按照这种行为处理地址:
1 | module "vpc" { |
1.6.2.1.1.8. S3 Bucket
你可以把模块存档保存在 AWS S3 桶里,使用 s3:: 作为地址前缀,后面跟随一个 S3 对象访问地址
1 | module "consul" { |
Terraform 识别到 s3:: 前缀后会使用 AWS 风格的认证机制访问给定地址。这使得这种源地址也可以搭配其他提供了 S3 协议兼容的对象存储服务使用,只要他们的认证方式与 AWS 相同即可。
保存在 S3 桶内的模块存档文件格式必须与上面 HTTP 源提到的支持的格式相同,Terraform 会下载并解压缩模块代码。
模块安装器会从以下位置寻找AWS凭证,按照优先级顺序排列:
AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY环境变量- HOME 目录下
.aws/credentials文件内的默认 profile - 如果是在 AWS EC2 主机内运行的,那么会尝试使用搭载的 IAM 主机实例配置。
1.6.2.1.1.9. GCS Bucket
你可以把模块存档保存在谷歌云 GCS 储桶里,使用 gcs:: 作为地址前缀,后面跟随一个 GCS 对象访问地址:
1 | module "consul" { |
模块安装器会使用谷歌云 SDK 的凭据来访问 GCS。要设置凭据,你可以:
- 通过
GOOGLE_APPLICATION_CREDENTIALS环境变量配置服务账号的密钥文件 - 如果是在谷歌云主机上运行的 Terraform,可以使用默认凭据。访问相关文档获取完整信息
- 可以使用命令行
gcloud auth application-default login设置
1.6.2.1.2. 直接引用子文件夹中的模块
引用版本控制系统或是对象存储服务中的模块时,模块本身可能存在于存档文件的一个子文件夹内。我们可以使用特殊的 // 语法来指定 Terraform 使用存档内特定路径作为模块代码所在位置,例如:
hashicorp/consul/aws//modules/consul-clustergit::https://example.com/network.git//modules/vpchttps://example.com/network-module.zip//modules/vpcs3::https://s3-eu-west-1.amazonaws.com/examplecorp-terraform-modules/network.zip//modules/vpc
如果源地址中包含又参数,例如指定特定版本号的 ref 参数,那么把子文件夹路径放在参数之前:
git::https://example.com/network.git//modules/vpc?ref=v1.2.0
Terraform 会解压缩整个存档文件后,读取特定子文件夹。所以,对于一个存在于子文件夹中的模块来说,通过本地路径引用同一个存档内的另一个模块是安全的。
1.6.2.1.3. 使用模块
我们刚才介绍了如何用 source 指定模块源,下面我们继续讲解如何在代码中使用一个模块。
我们可以把模块理解成类似函数,如同函数有输入参数表和输出值一样,我们之前介绍过 Terraform 代码有输入变量和输出值。我们在 module 块的块体内除了 source 参数,还可以对该模块的输入变量赋值:
1 | module "servers" { |
在这个例子里,我们将会创建 ./app-cluster 文件夹下 Terraform 声明的一系列资源,该模块的 servers 输入变量的值被我们设定成了5。
在代码中新增、删除或是修改一个某块的 source,都需要重新运行 terraform init 命令。默认情况下,该命令不会升级已安装的模块(例如 source 未指定版本,过去安装了旧版本模块代码,那么执行 terraform init 不会自动更新到新版本);可以执行 terraform init -upgrade 来强制更新到最新版本模块。
1.6.2.1.4. 访问模块输出值
在模块中定义的资源和数据源都是被封装的,所以模块调用者无法直接访问它们的输出属性。然而,模块可以声明一系列输出值,来选择性地输出特定的数据供模块调用者使用。
举例来说,如果 ./app-cluster 模块定义了名为 instance_ids 的输出值,那么模块的调用者可以像这样引用它:
1 | resource "aws_elb" "example" { |
1.6.2.1.5. 其他的模块元参数
除了 source 以外,目前 Terraform 还支持在 module 块上声明其他一些可选元参数:
version:指定引用的模块版本,在后面的部分会详细介绍count和for_each:这是 Terraform 0.13 开始支持的特性,类似resource与data,我们可以创建多个module实例providers:通过传入一个map我们可以指定模块中的 Provider 配置,我们将在后面详细介绍depends_on:创建整个模块和其他资源之间的显式依赖。直到依赖项创建完毕,否则声明了依赖的模块内部所有的资源及内嵌的模块资源都会被推迟处理。模块的依赖行为与资源的依赖行为相同
除了上述元参数以外,lifecycle 参数目前还不能被用于模块,但关键字被保留以便将来实现。
1.6.2.1.6. 模块版本约束
使用 registry 作为模块源时,可以使用 version 元参数约束使用的模块版本:
1 | module "consul" { |
version 元参数的格式与 Provider 版本约束的格式一致。在满足版本约束的前提下,Terraform 会使用当前已安装的最新版本的模块实例。如果当前没有满足约束的版本被安装过,那么会下载符合约束的最新的版本。
version 元参数只能配合 registry 使用,公共的或者私有的模块仓库都可以。其他类型的模块源可能支持版本化,也可能不支持。本地路径模块不支持版本化。
1.6.2.1.7. 多实例模块
可以通过在 module 块上声明 for_each 或者 count 来创造多实例模块。在使用上 module 上的 for_each 和 count 与资源、数据源块上的使用是一样的。
1 | # my_buckets.tf |
1 | # publish_bucket/bucket-and-cloudfront.tf |
这个例子定义了一个位于 ./publish_bucket 目录下的本地子模块,模块创建了一个 S3 存储桶,封装了桶的信息以及其他实现细节。
我们通过 for_each 参数声明了模块的多个实例,传入一个 map 或是 set 作为参数值。另外,因为我们使用了 for_each,所以在 module 块里可以使用 each 对象,例子里我们使用了 each.key。如果我们使用的是 count 参数,那么我们可以使用 count.index。
子模块里创建的资源在执行计划或UI中的名称会以 module.module_name[module index] 作为前缀。如果一个模块没有声明 count 或者 for_each,那么资源地址将不包含 module index。
在上面的例子里,./publish_bucket 模块包含了 aws_s3_bucket.example 资源,所以两个 S3 桶实例的名字分别是module.bucket["assets"].aws_s3_bucket.example 以及 module.bucket["media"].aws_s3_bucket.example。
1.6.2.1.8. 模块内的 Provider
当代码中声明了多个模块时,资源如何与 Provider 实例关联就需要特殊考虑。
每一个资源都必须关联一个 Provider 配置。不像 Terraform 其他的概念,Provider 配置在 Terraform 项目中是全局的,可以跨模块共享。Provider 配置声明只能放在根模块中。
Provider 有两种方式传递给子模块:隐式继承,或是显式通过 module 块的 providers 参数传递。
一个旨在被复用的模块不允许声明任何 provider 块,只有使用"代理 Provider"模式的情况除外,我们后面会介绍这种模式。
出于向前兼容 Terraform 0.10 及更早版本的考虑,Terraform 目前在模块代码中只用到了 Terraform 0.10 及更早版本的功能时,不会针对模块代码中声明 provider 块报错,但这是一个不被推荐的遗留模式。一个含有自己的 provider 块定义的遗留模块与 for_each、count 和 depends_on 等 0.13 引入的新特性是不兼容的。
Provider 配置被用于相关资源的所有操作,包括销毁远程资源对象以及更新状态信息等。Terraform 会在状态文件中保存针对最近用来执行所有资源变更的 Provider 配置的引用。当一个 resource 块被删除时,状态文件中的相关记录会被用来定位到相应的配置,因为原来包含 provider 参数(如果声明了的话)的 resource 块已经不存在了。
这导致了,你必须确保删除所有相关的资源配置定义以后才能删除一个 Provider 配置。如果 Terraform 发现状态文件中记录的某个资源对应的 Provider 配置已经不存在了会报错,要求你重新给出相关的 Provider 配置。
1.6.2.1.9. 模块内的 Provider 版本限制
虽然 Provider 配置信息在模块间共享,每个模块还是得声明各自的模块需求,这样 Terraform 才能决定一个适用于所有模块配置的 Provider 版本。
为了定义这样的版本约束要求,可以在 terraform 块中使用 required_providers 块:
1 | terraform { |
有关 Provider 的 source 和版本约束的信息我们已经在前文中有所记述,在此不再赘述。
1.6.2.1.10. 隐式 Provider 继承
为了方便,在一些简单的代码中,一个子模块会从调用者那里自动地继承默认的 Provider 配置。这意味着显式 provider 块声明仅位于根模块中,并且下游子模块可以简单地声明使用该类型 Provider 的资源,这些资源会自动关联到根模块的 Provider 配置上。
例如,根模块可能只含有一个 provider 块和一个 module 块:
1 | provider "aws" { |
子模块可以声明任意关联 aws 类型 Provider 的资源而无需额外声明 Provider 配置:
1 | resource "aws_s3_bucket" "example" { |
当每种类型的 Provider 都只有一个实例时我们推荐使用这种方式。
要注意的是,只有 Provider 配置会被子模块继承,Provider 的 source 或是版本约束条件则不会被继承。每一个模块都必须声明各自的 Provider 需求条件,这在使用非 HashiCorp 的 Provider 时尤其重要。
1.6.2.1.11. 显式传递 Provider
当不同的子模块需要不同的 Provider 实例,或者子模块需要的 Provider 实例与调用者自己使用的不同时,我们需要在 module 块上声明 providers 参数来传递子模块要使用的 Provider 实例。例如:
1 | # The default "aws" configuration is used for AWS resources in the root |
module 块里的 providers 参数类似 resource 块里的 provider 参数,区别是前者接收的是一个 map 而不是单个 string,因为一个模块可能含有多个不同的 Provider。
providers 的 map 的键就是子模块中声明的 Provider 需求中的名字,值就是在当前模块中对应的 Provider 配置的名字。
如果 module 块内声明了 providers 参数,那么它将重载所有默认的继承行为,所以你需要确保给定的 map 覆盖了子模块所需要的所有 Provider。这避免了显式赋值与隐式继承混用时带来的混乱和意外。
额外的 Provider 配置(使用 alias 参数的)将永远不会被子模块隐式继承,所以必须显式通过 providers 传递。比如,一个模块配置了两个 AWS 区域之间的网络打通,所以需要配置一个源区域 Provider 和目标区域 Provider。这种情况下,根模块代码看起来是这样的:
1 | provider "aws" { |
子目录 ./tunnel 必须包含像下面的例子那样声明"Provider 代理",声明模块调用者必须用这些名字传递的 Provider 配置:
1 | provider "aws" { |
./tunnel 模块中的每一种资源都应该通过 provider 参数声明它使用的是 aws.src 还是 aws.dst。
1.6.2.1.12. Provider 代理配置块
一个 Provider 代理配置只包含 alias 参数,它就是一个模块间传递 Provider 配置的占位符,声明了模块期待显式传递的额外(带有 alias 的)Provider 配置。
需要注意的是,一个完全为空的 Provider 配置块也是合法的,但没有必要。只有在模块内需要带 alias 的 Provider 时才需要代理配置块。如果模块中只是用默认 Provider 时请不要声明代理配置块,也不要仅为了声明 Provider 版本约束而使用代理配置块。
模块元参数
1.6.3.1. 模块元参数
在 Terraform 0.13 之前,模块在使用上存在一些限制。例如我们通过模块来创建 EC2 主机,可以这样:
1 | module "ec2_instance" { |
如果我们要创建两台这样的主机怎么办?在 Terraform 0.13 之前的版本中,由于 Module 不支持元参数,所以我们只能手动拷贝模块代码:
1 | module "ec2_instance_0" { |
自从 Terraform 0.13 开始,模块也像资源一样,支持count、for_each、depends_on三种元参数。比如我们可以这样:
1 | module "ec2_instance" { |
要注意的是 Terraform 0.13 之后在模块上声明depends_on,列表中也可以传入另一个模块。声明depends_on的模块中的所有资源的创建都会发生在被依赖的模块中所有资源创建完成之后。
1.6.4.1. 重构
请注意,本节介绍的通过 moved 块进行模块重构的功能是从 Terraform v1.1 开始被引入的。如果要在之前的版本进行这样的操作,必须通过 terraform state mv 命令来完成。
对于一些旨在被人复用的老模块来说,最初的模块结构和资源名称可能会逐渐变得不再合适。例如,我们可能发现将以前的一个子模块分割成两个单独的模块会更合理,这需要将现有资源的一个子集移动到新的模块中。
Terraform 将以前的状态与新代码进行比较,资源与每个模块或资源的唯一地址相关联。因此,默认情况下,移动或重命名对象会被 Terraform 理解为销毁旧地址的对象并在新地址创建新的对象。
当我们在代码中添加 moved 块以记录我们移动或重命名对象过去的地址时,Terraform 会将旧地址的现有对象视为现在属于新地址。
1.6.4.1.1. moved 块语法
moved 块只包含 from 和 to 参数,没有名称:
1 | moved { |
上面的例子演示了模块先前版本中的 aws_instance.a 如今以 aws_instance.b 的名字存在。
在为 aws_instance.b 创建新的变更计划之前,Terraform 会首先检查当前状态中是否存在地址为 aws_instance.a 的记录。如果存在该记录,Terraform 会将之重命名为 aws_instance.b 然后继续创建变更计划。最终生成的变更计划中该对象就好像一开始就是以 aws_instance.b 的名字被创建的,防止它在执行变更时被删除。
from 和 to 的地址使用一种特殊的地址语法,该语法允许选定模块、资源以及子模块中的资源。下面是几种不同的重构场景中所需要的地址语法:
1.6.4.1.2. 重命名一个资源
考虑模块代码中这样一个资源:
1 | resource "aws_instance" "a" { |
第一次应用该代码时 Terraform 会创建 aws_instance.a[0] 以及 aws_instance.a[1]。
如果随后我们修改了该资源的名称,并且把旧名字记录在一个 moved 块里:
1 | resource "aws_instance" "b" { |
当下一次应用使用了该模块的代码时,Terraform 会把所有地址为 aws_instance.a 的对象看作是一开始就以 aws_instance.b 的名字创建的:aws_instance.a[0] 会被看作是 aws_instance.b[0],aws_instance.a[1] 会被看作是 aws_instance.b[1]。
新创建的模块实例中,因为从来就不存在 aws_instance.a,于是会忽略 moved 块而像通常那样直接创建 aws_instance.b[0] 以及 aws_instance.b[1]。
1.6.4.1.3. 为资源添加 count 或 for_each 声明
一开始代码中有这样一个单实例资源:
1 | resource "aws_instance" "a" { |
应用该代码会使得 Terraform 创建了一个地址为 aws_instance.a 的资源对象。
随后我们想要在该资源上添加 for_each 来创建多个实例。为了保持先前关联到 aws_instance.a 的资源对象不受影响,我们必须添加一个 moved 块来指定新代码中原先的对象实例所关联的键是什么:
1 | locals { |
上面的代码会防止 Terraform 在变更计划中销毁已经存在的 aws_instance.a 对象,并且将其看作是以 aws_instance.a["small"] 的地址创建的。
当 moved 块的两个地址中的至少一个包含实例键时,如上例中的 ["small"],Terraform 将这两个地址理解为引用资源的特定实例而不是整个资源。这意味着您可以使用 moved 在键之间切换以及在 count、for_each 之间切换时添加和删除键。
下面的例子演示了几种其他类似的记录了资源实例键变更的合法 moved 块:
1 | # Both old and new configuration used "for_each", but the |
注意:当我们在原先没有声明 count 的资源上添加 count 时,Terraform 会自动将原先的对象移动到第 0 个位置,除非我们通过一个 moved 块显式声明该资源。然而,我们建议使用 moved 块显式声明资源的移动,使得读者在未来阅读模块的代码时能够更清楚地了解到这些变更。
1.6.4.1.4. 重命名对模块的调用
我们可以用类似重命名资源的方式来重命名对模块的调用。假设我们开始用以下代码调用一个模块:
1 | module "a" { |
当应用该代码时,Terraform 会在模块内声明的资源路径前面加上一个模块路径前缀 module.a。比方说,模块内的 aws_instance.example 的完整地址为 module.a.aws_instance.example。
如果我们随后打算修改模块名称,我们可以直接修改 module 块的标签,并且在一个 moved 块内部记录该变更:
1 | module "b" { |
当下一次应用包含该模块调用的代码时,Terraform 会将所有路径前缀为 module.a 的对象看作从一开始就是以 module.b 为前缀创建的。module.a.aws_instance.example 会被看作是 module.b.aws_instance.example。
该例子中的 moved 块中的两个地址都代表对模块的调用,而 Terraform 识别出将原模块地址中所有的资源移动到新的模块地址中。如果该模块声明时使用了 count 或是 for_each,那么该移动也将被应用于所有的实例上,不需要逐个指定。
1.6.4.1.5. 为模块调用添加 count 或 for_each 声明
考虑一下单实例的模块:
1 | module "a" { |
应用该段代码会导致 Terraform 创建的资源地址都拥有 module.a 的前缀。
随后如果我们可能需要再通过添加 count 来创建多个资源实例。为了保留先前的 aws_instance.a 实例不受影响,我们可以添加一个 moved 块来设置在新代码中该实例的对应的键。
1 | module "a" { |
上面的代码引导 Terraform 将所有 module.a 中的资源看作是从一开始就是以 module.a[2] 的前缀被创建的。结果就就是,Terraform 生成的变更计划中只会创建 module.a[0] 以及 module.a[1]。
当 moved 块的两个地址中的至少一个包含实例键时,例如上面例子中的 [2]那样,Terraform 会理解将这两个地址理解为对模块的特定实例的调用而非对模块所有实例的调用。这意味着我们可以使用 moved 块在不同键之间切换来添加或是删除键,该机制可用于 count 和 for_each,或删除模块上的这种声明。
1.6.4.1.6. 将一个模块分割成多个模块
随着模块提供的功能越来越多,最终模块可能变得过大而不得不将之拆分成两个独立的模块。
我们看一下下面的这个例子:
1 | resource "aws_instance" "a" { |
我们可以将该模块分割为三个部分:
aws_instance.a现在归属于模块 “x”。aws_instance.b也属于模块 “x”。aws_instance.c现在归属于模块 “y”。
要在不替换绑定到旧资源地址的现有对象的情况下实现此重构,我们需要:
- 编写模块 “x”,将属于它的两个资源拷贝过去。
- 编写模块 “y”,将属于它的一个资源拷贝过去。
- 编辑原有模块代码,删除这些资源,只包含有关迁移现有资源的非常简单的配置代码。
新的模块 “x” 和 “y” 应该只包含 resource 块:
1 | # module "x" |
1 | # module "y" |
而原有模块则被修改成只包含有向下兼容逻辑的垫片,调用两个新模块,并使用 moved 块定义哪些资源被移动到新模块中去了:
1 | module "x" { |
当一个原模块的调用者升级模块版本到这个“垫片”版本时,Terraform 会注意到这些 moved 块,并将那些关联到老地址的资源对象看作是从一开始就是由新模块创建的那样。
该模块的新用户可以选择使用这个垫片模块,或是独立调用两个新模块。我们需要通知老模块的现有用户老模块已被废弃,他们将来的开发中需要独立使用这两个新模块。
多模块重构的场景是不多见的,因为它违反了父模块将其子模块视为黑盒的典型规则,不知道在其中声明了哪些资源。这种妥协的前提是假设所有这三个模块都由同一个人维护并分布在一个模块包中。
为避免独立模块之间的耦合,Terraform 只允许声明在同一个目录下的模块间的移动。换句话讲,Terraform 不允许将资源移动到一个 source 地址不是本地路径的模块中去。
Terraform 使用定义 moved 块的模块实例的地址的地址来解析 moved 块中的相对地址。例如,如果上面的原模块已经是名为 module.original 的子模块,则原模块中对 module.x.aws_instance.a 的引用在根模块中将被解析为 module.original.module.x.aws_instance.a。一个模块只能针对它自身或是它的子模块中的资源声明 moved 块。
如果需要引用带有 count 或 for_each 元参数的模块中的资源,则必须指定要使用的特定实例键以匹配资源配置的新位置:
1 | moved { |
1.6.4.1.7. 删除 moved 块
随着时间的推移,一些老模块可能会积累大量 moved 块。
删除 moved 块通常是一种破坏性变更,因为删除后所有使用旧地址引用的对象都将被删除而不是被移动。我们强烈建议保留历史上所有的 moved 块来保存用户从任意版本升级到当前版本的升级路径信息。
如果我们决定要删除 moved 块,需要谨慎行事。对于组织内部的私有模块来说删除 moved 块可能是安全的,因为我们可以确认所有用户都已经使用新版本模块代码运行过 terraform apply 了。
如果我们需要多次重命名或是移动一个对象,我们建议使用串联的 moved 块来记录完整的变更信息,新的块引用已有的块:
1 | moved { |
像这样记录下移动的序列可以使 aws_instance.a 以及 aws_instance.b 两种地址的资源都得到成功更新,Terraform 会将他们视作从一开始就是以 aws_instance.c 的地址创建的。
1.6.4.1.8. 删除模块
注意:removed 块是在 Terraform v1.7 引入的功能。对于早期的 Terraform 版本,您可以使用 terraform state rm 命令来处理。
要从 Terraform 中删除模块,只需从 Terraform 代码中删除模块调用即可。
默认情况下,删除模块块后,Terraform 将计划销毁由该模块中声明的所有资源。这是因为当您删除模块调用时,该模块的代码将不再包含在我们当前的 Terraform 代码中。
有时我们可能希望从 Terraform 代码中删除模块而不破坏它管理的实际基础设施对象。在这种情况下,资源将从 Terraform 状态中删除,但真正的基础设施对象不会被销毁。
要声明模块已从 Terraform 配置中删除,但不应销毁其托管对象,请从配置中删除 module 块并将其替换为 removed 块:
1 | removed { |
from 参数是要删除的模块的地址,不带任何实例键(例如 module.example[1])。
lifecycle 块是必需的。 destroy 参数确定 Terraform 是否会尝试销毁模块管理的对象。 false 值表示 Terraform 将从状态中删除资源而不破坏它们。
1.6.5.1. 设计新模块的模式
Terraform 模块是独立的基础设施即代码片段,抽象了基础设施部署的底层复杂性。Terraform 用户通过使用预置的配置代码加速采用 IaC,并降低了使用门槛。所以,模块的作者应尽量遵循诸如清晰的代码结构以及 DRY(“Dont’t Repeat Yourself”)原则的代码最佳实践。
本篇指导讨论了模块架构的原则,用以帮助读者编写易于组合、易于分享及重用的基础设施模块。这些架构建议对使用任意版本 Terraform 的企业都有助益,某些诸如“私有模块注册表(Registry)”的模式仅在 Terraform Cloud 以及企业版中才能使用。(本文不对相关内容进行翻译)
本文是对 Terraform 模块文档的补充和扩展。
通过阅读文本,读者可以:
- 学习有关 Terraform 模块创建的典型工作流程和基本原则。
- 探索遵循这些原则的示例场景。
- 学习如何通过协作改进 Terraform 模块
- 了解如何创建一套使用模块的工作流程。
1.6.5.1.1. 模块创建的工作流
要创建一个新模块,第一步是寻找一个早期采纳者团队,收集他们的需求。
与这支早期采纳团队一起工作使我们可以通过使用输入变量以及输出值来确保模块足够灵活,从而打磨模块的功能。此外,还可以用最小的代码变更代价吸纳其他有类似需求的团队加入进来。这消除了代码重复,并缩短了交付时间。
完成以上任务后,需要谨记两点:
- 将需求范围划分成合适的模块。
- 创建模块的最小可行产品(Minimum Viable Product, MVP)
1.6.5.1.1.1. 将需求范围划分成合适的模块
创建新 Terraform 模块时最具挑战的方面之一是决定要包含哪些基础设施资源。
模块设计应该是有主见的,并且被设计成能很好地完成一个目标。如果一个模块的功能或目的很难解释,那么这个模块可能太复杂了。在最初确定模块的范围时,目标应当足够小且简单,易于开始编写。
当构建一个模块时,需要考虑以下三个方面:
- 封装:一组始终被一起部署的基础设施资源 在模块中包含更多的基础设施资源简化了终端用户部署基础设施的工作,但会使得模块的目的与需求变得更难理解。
- 职责:限制模块职责的边界 如果模块中的基础设施资源由多个组来负责,使用该模块可能会意外违反职责分离原则。模块中仅包含职责边界内的一组资源可以提升基础设施资源的隔离性,并保护我们的基础设施。
- 变化频率:隔离长短生命周期基础设施资源 举例来说,数据库基础设施资源相对来说较为静态,而团队可能在一天内多次部署更新应用程序服务器。在同一个模块中同时管理数据库与应用程序服务器使得保存状态数据的重要基础设施没有必要地暴露在数据丢失的风险之中。
1.6.5.1.1.2. 创建模块的最小可行产品
如同所有类型的代码一样,模块的开发永远不会完成,永远会有新的模块需求以及变更。拥抱变化,最初的模块版本应致力于满足最小可行产品(MVP)的标准。以下是在设计最小可行产品时需要谨记的指导清单:
- 永远致力于交付至少可以满足 80% 场景的模块
- 模块中永远不要处理边缘场景。边缘场景是很少见的。一个模块应该是一组可重用的代码。
- 在最小可行产品中避免使用条件表达式。最小可行产品应缩小范围,不应该同时完成多种任务。
- 模块应该只将最常被修改的参数公开为输入变量。一开始时,模块应该只提供最可能需要的输入变量。
尽可能多输出
在最小可行产品中输出尽可能多的信息,哪怕目前没有用户需要这些信息。这使得那些通常使用多个模块的终端用户在使用该模块时更加轻松,可以使用一个模块的输出作为下一个模块的输入。
请记住在模块的 README 文档中记录输出值的文档。
1.6.5.1.2. 探索遵循这些原则的一个示例场景
某团队想要通过 Terraform 创建一套包含 Web 层应用、App 层应用的基础设施。
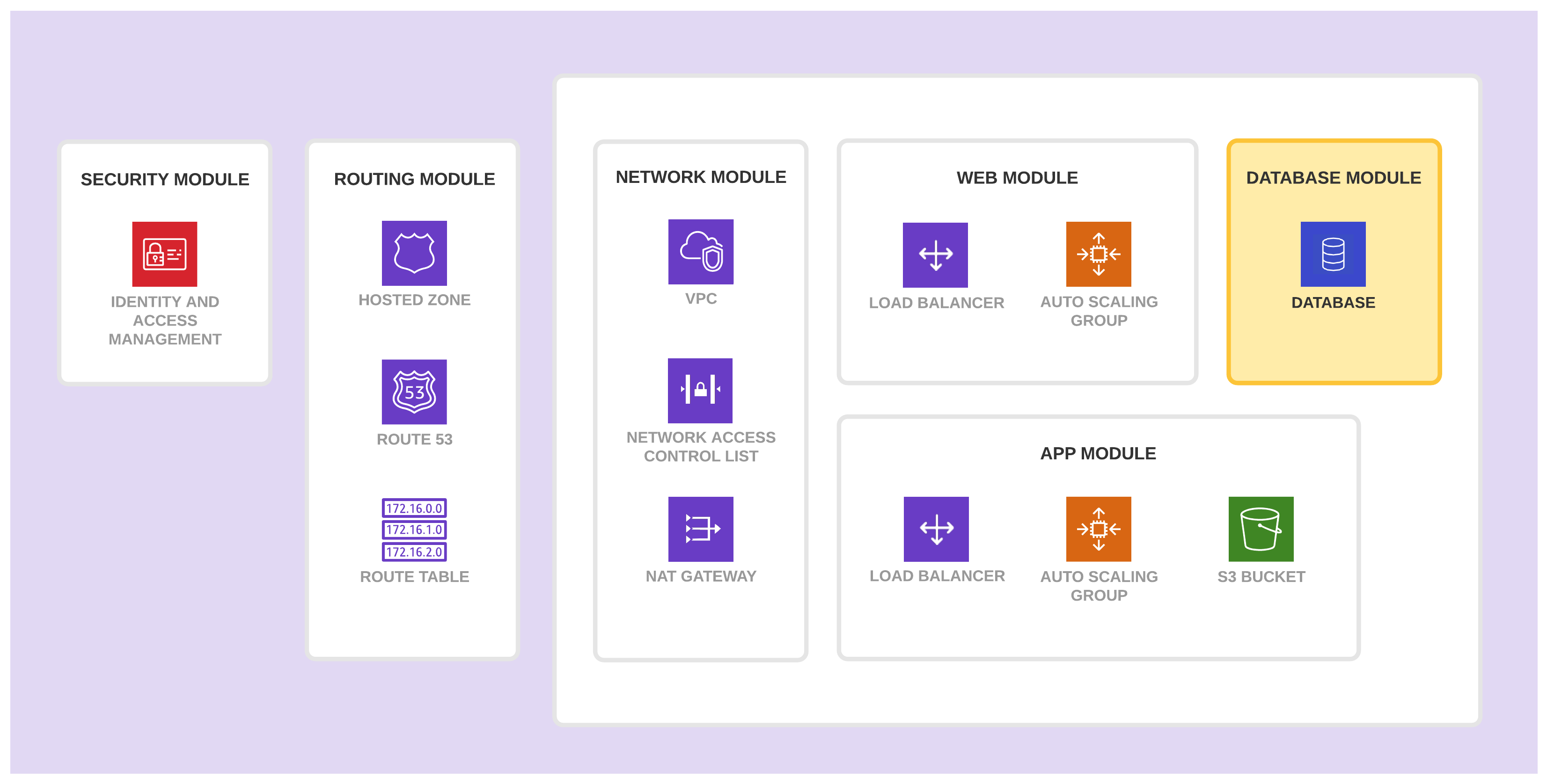
他们想要使用一个专用的 VPC,并遵循传统的三层架构设计。他们的 Web 层应用需要一个自动伸缩组(AutoScaling Group)。他们的 App 层服务需要一个自动伸缩组,一个 S3 存储桶以及一个数据库。下面的架构图描述了期望的结果:
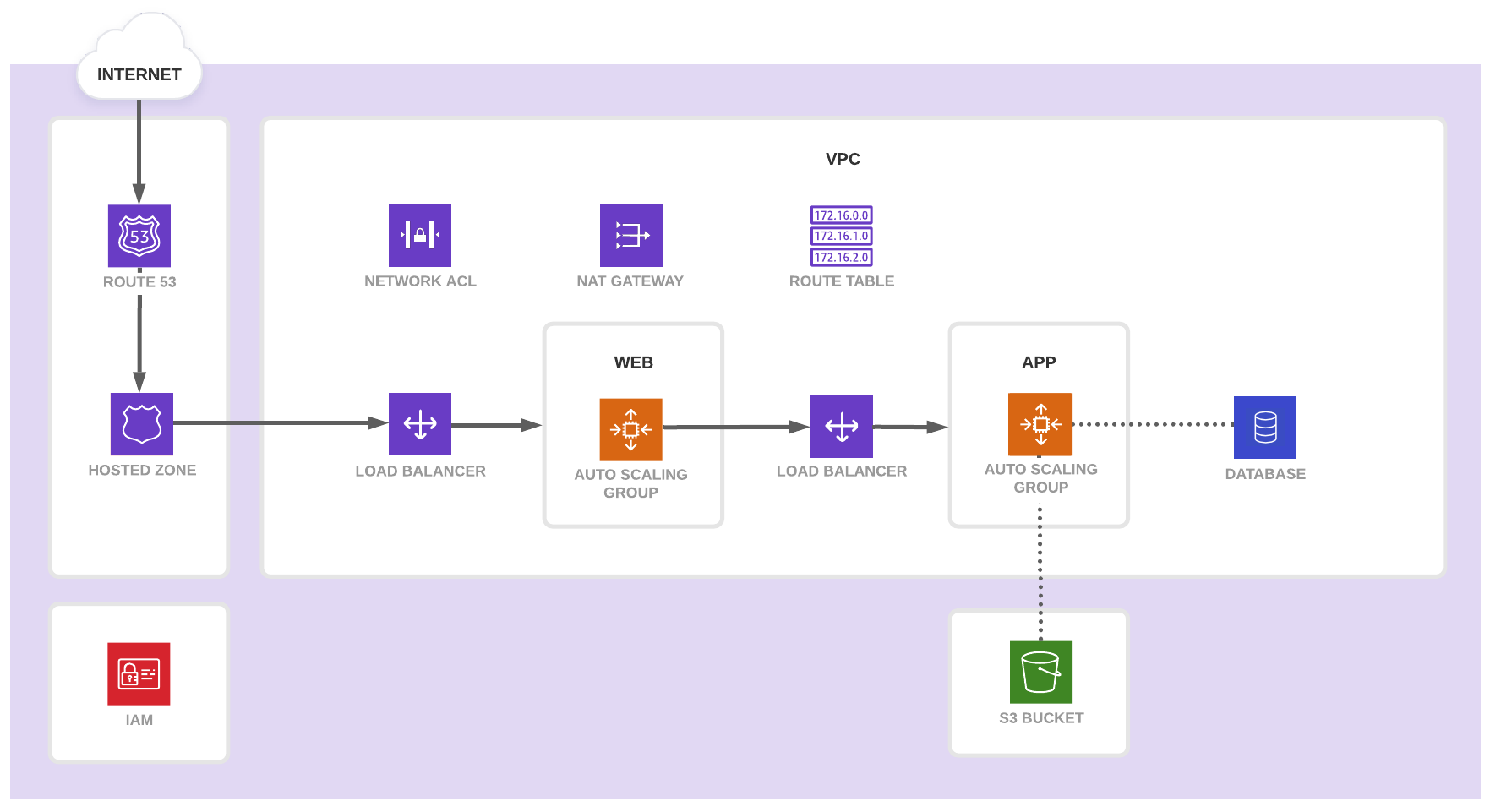
该场景中,一个负责从零开始撰写 Terraform 代码的团队,负责编写一组用以配置基础设施及应用的模块。负责应用程序的团队成员将使用这些模块来配置他们需要的基础设施。
请注意,虽然该示例使用了 AWS 命名,但所描述的模式适用于所有云平台。
经过对应用程序团队的需求进行审核,模块团队将该应用基础设施分割成如下模块:网络、Web、App、数据库、路由,以及安全。
当 Terraform 模块团队完成模块开发后,他们应该将模块导入到私有模块注册表中,并且向对应的团队成员宣传模块的使用方法。举例来说,负责网络的团队成员将会使用开发的网络模块来部署和配置相应的应用程序网络。
1.6.5.1.2.1. 网络模块
网络模块负责网络基础设施。它包含了网络访问控制列表(ACL)以及 NAT 网关。它也可以包含应用程序所需的 VPC、子网、对等连接以及 Direct Connect 等。
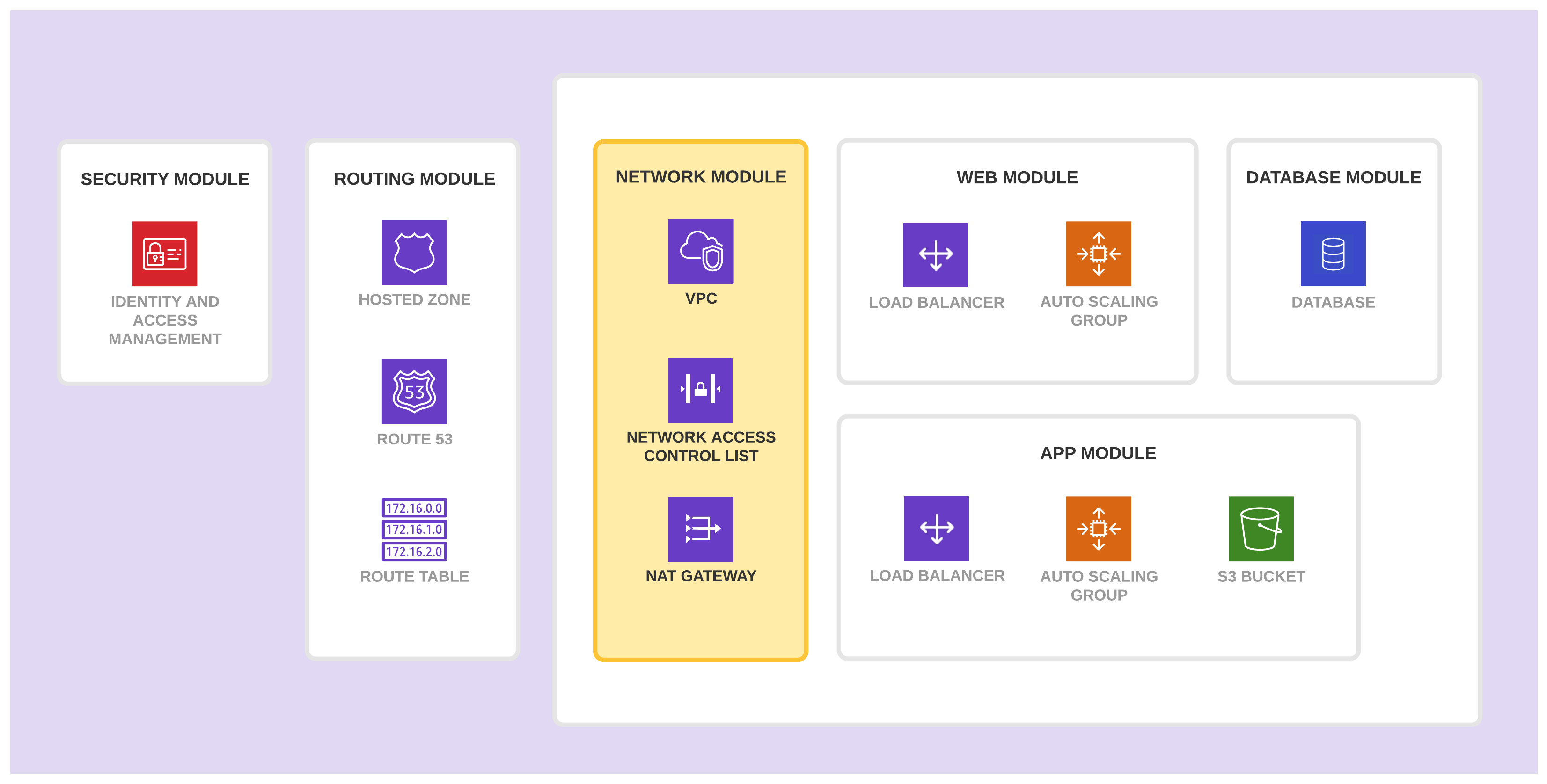
该模块包含这些资源是因为它们需要特定权限并且变化频率较低。
- 只有应用程序团队中有权创建或修改网络资源的成员可以使用该模块。
- 该模块的资源不会经常变更。将它们组合在单独的模块中可以保护它们免于暴露在没有必要的数据丢失的风险之中。
网络模块返回一组其他工作区(Workspace)以及模块可以使用的输出值。如果 VPC 的创建过程是由多个方面组成的,我们可能最终会需要将该模块进一步切割成拥有不同功能的不同模块。
1.6.5.1.2.2. 应用程序模块
本场景中有两个应用程序模块 —— 一个是 Web 层模块,另一个是 App 层模块。
Terraform 模块团队完成这两个模块的开发后,它们应被分发给对应的团队成员来部署他们的应用。随着应用程序团队的成员变得越来越熟悉 Terraform 代码,它们可以提出基础设施方面的增强建议,或是通过 Pull Request 配合他们自己的应用代码发布提交对基础设施的变更请求。
Web 模块
Web 模块创建和管理运行 Web 应用程序所需的基础设施。它包含了负载均衡器和自动伸缩组,同时也可以包含应用程序中使用的 EC2 虚拟机实例、S3 存储桶、安全组,以及日志系统。该模块接收一个通过 Packer 预构建的包含最新 Web 层应用发布版本代码的虚拟机镜像的 AMI ID 作为输入。
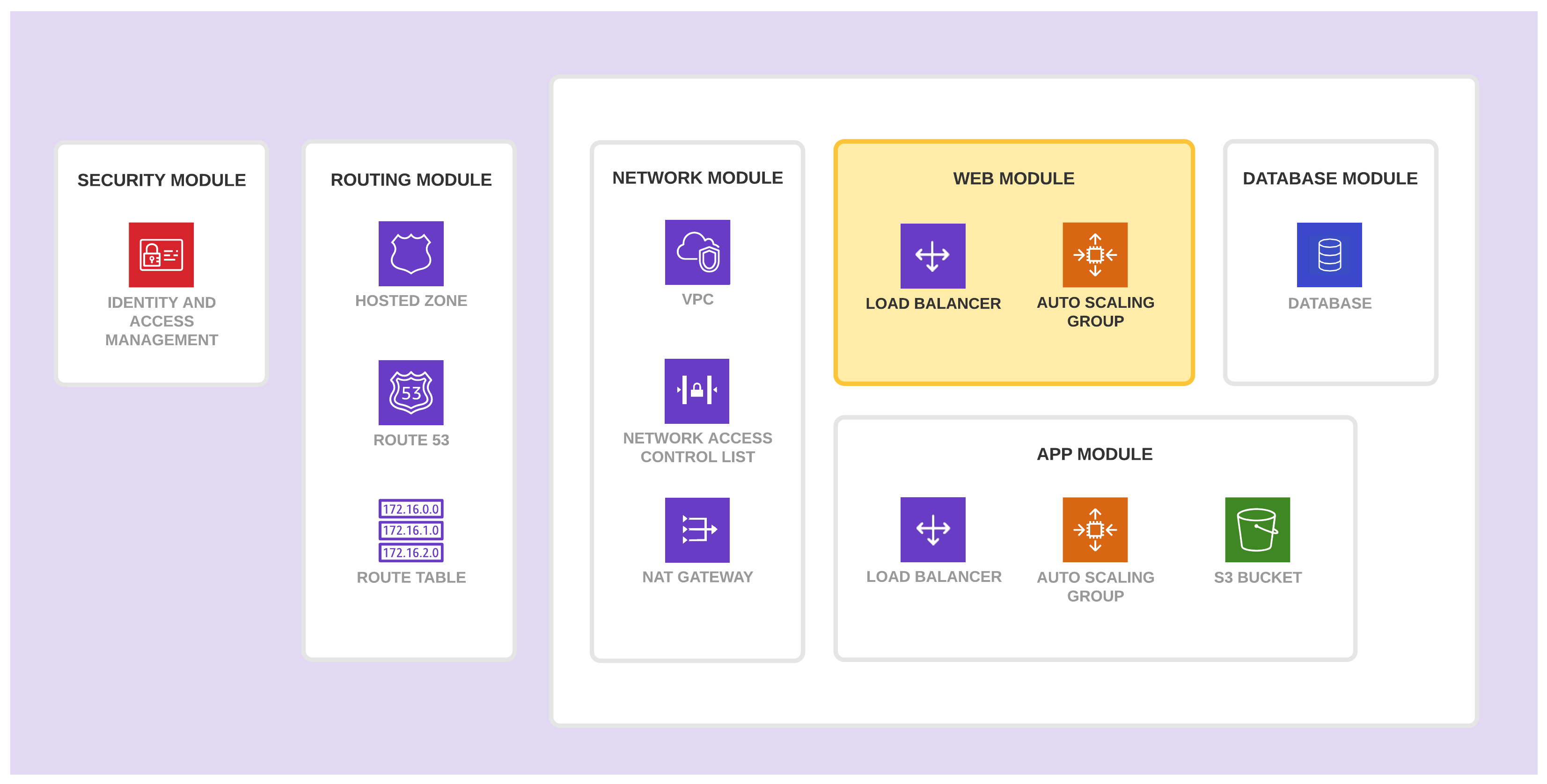
该模块包含这些资源是因为它们是高度封装的,并且它们变化频率较高。
- 此模块中的资源高度内聚,并且与 Web 应用程序紧密相关(例如,此模块需要一个包含最新 Web 层应用程序代码版本的 AMI)。结果就是它们被编制进同一个模块,这样 Web 应用团队的成员们就可以轻松地部署它们。
- 该模块的资源变更频率较高(每次发布更新版本都需要更新对应基础设施资源)。通过将它们组合在单独的模块中,我们降低了将其他模块的资源暴露在没有必要的数据丢失的风险中的可能性。
App 模块
App 模块创建和管理运行 App 层应用所需的基础设施。它包含了负载均衡器和自动伸缩组,同时也包含了应用程序中使用的 EC2 虚拟机实例、S3 存储桶、安全组,以及日志系统。该模块接收一个通过 Packer 预构建的包含最新 App 层应用发布版本代码的虚拟机镜像的 AMI ID 作为输入。
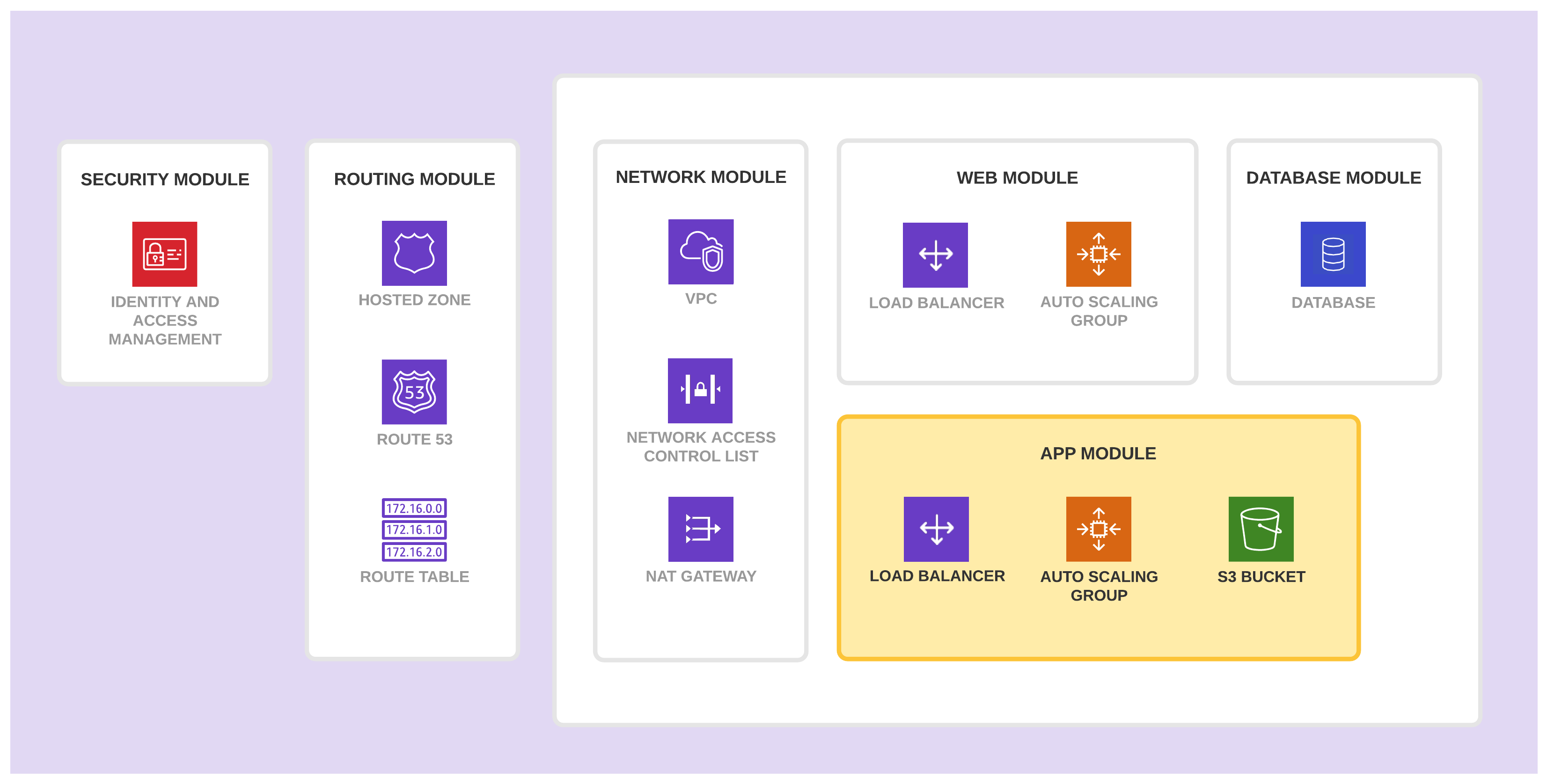
该模块包含这些资源是因为它们是高度封装的,并且它们变化频率较高。
- 此模块中的资源高度内聚,并且与 App 应用程序紧密相关。结果就是它们被编制进同一个模块,这样 App 层应用团队的成员们就可以轻松地部署它们。
- 该模块的资源变更频率较高(每次发布更新版本都需要更新对应基础设施资源)。通过将它们组合在单独的模块中,我们降低了将其他模块的资源暴露在没有必要的数据丢失的风险中的可能性。
数据库模块
数据库模块创建并管理了运行数据库所需的基础设施资源。它包含了应用程序所需的 RDS 实例,也包含了所有关联的存储、备份以及日志资源。
该模块包含这些资源是因为它们需要特定权限并且变化频率较低。
- 只有应用程序团队中有权创建或修改数据库资源的成员可以使用该模块。
- 该模块的资源不会经常变更。将它们组合在单独的模块中可以保护它们免于暴露在没有必要的数据丢失的风险之中。
路由模块
路由模块创建并管理网络路由所需的基础设施资源。它包含了公共托管区域(Hosted Zone)、Route 53 以及路由表,也可以包含私有托管区域。
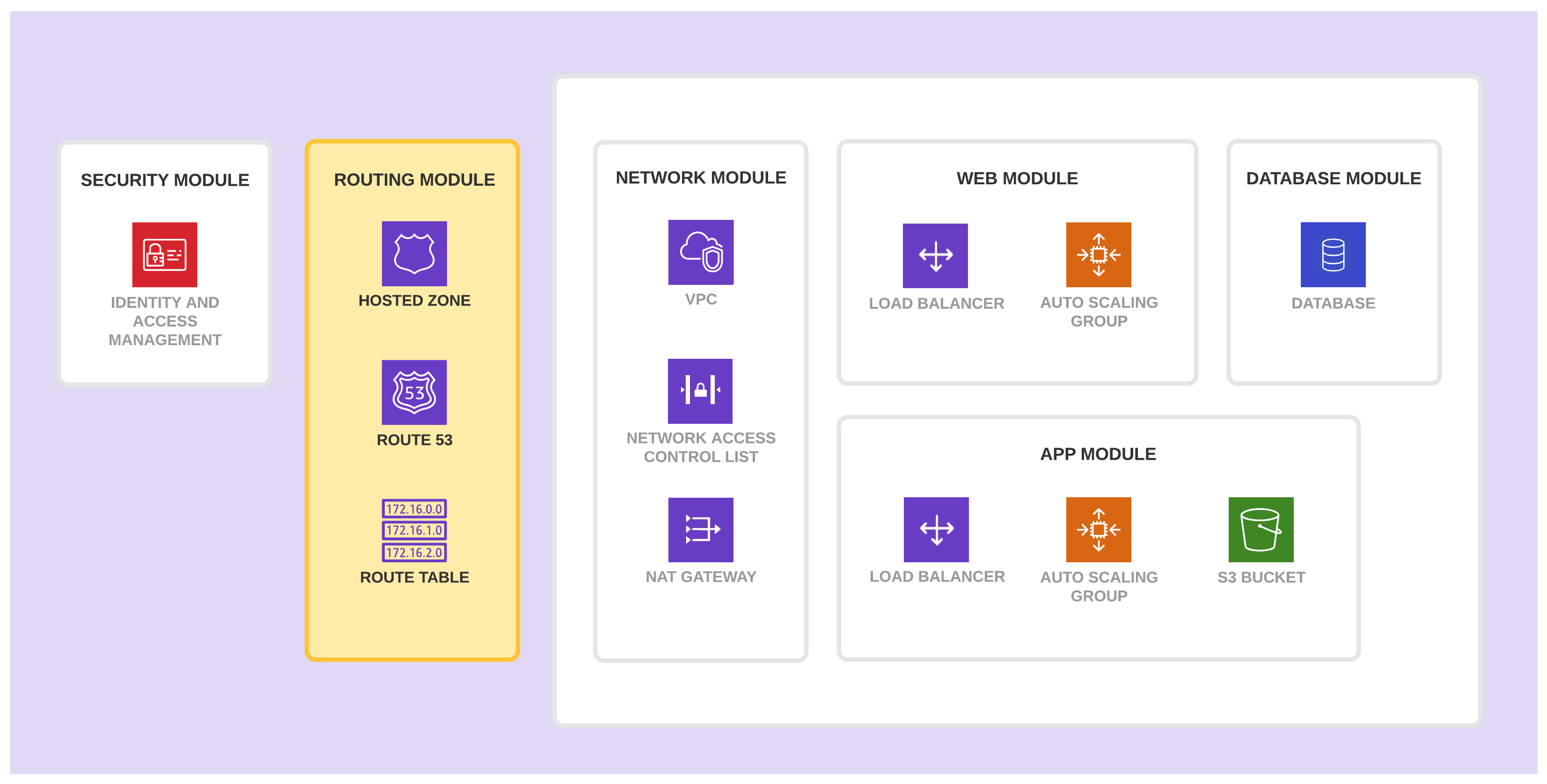
该模块包含这些资源是因为它们需要特定权限并且变化频率较低。
- 只有应用程序团队中有权创建或修改路由资源的成员可以使用该模块。
- 该模块的资源不会经常变更。将它们组合在单独的模块中可以保护它们免于暴露在没有必要的数据丢失的风险之中。
安全模块
安全模块创建并管理所有安全所需的基础设施资源。它包含一组 IAM 资源,也可以包含安全组(Security Group)及多因素认证(MFA)。
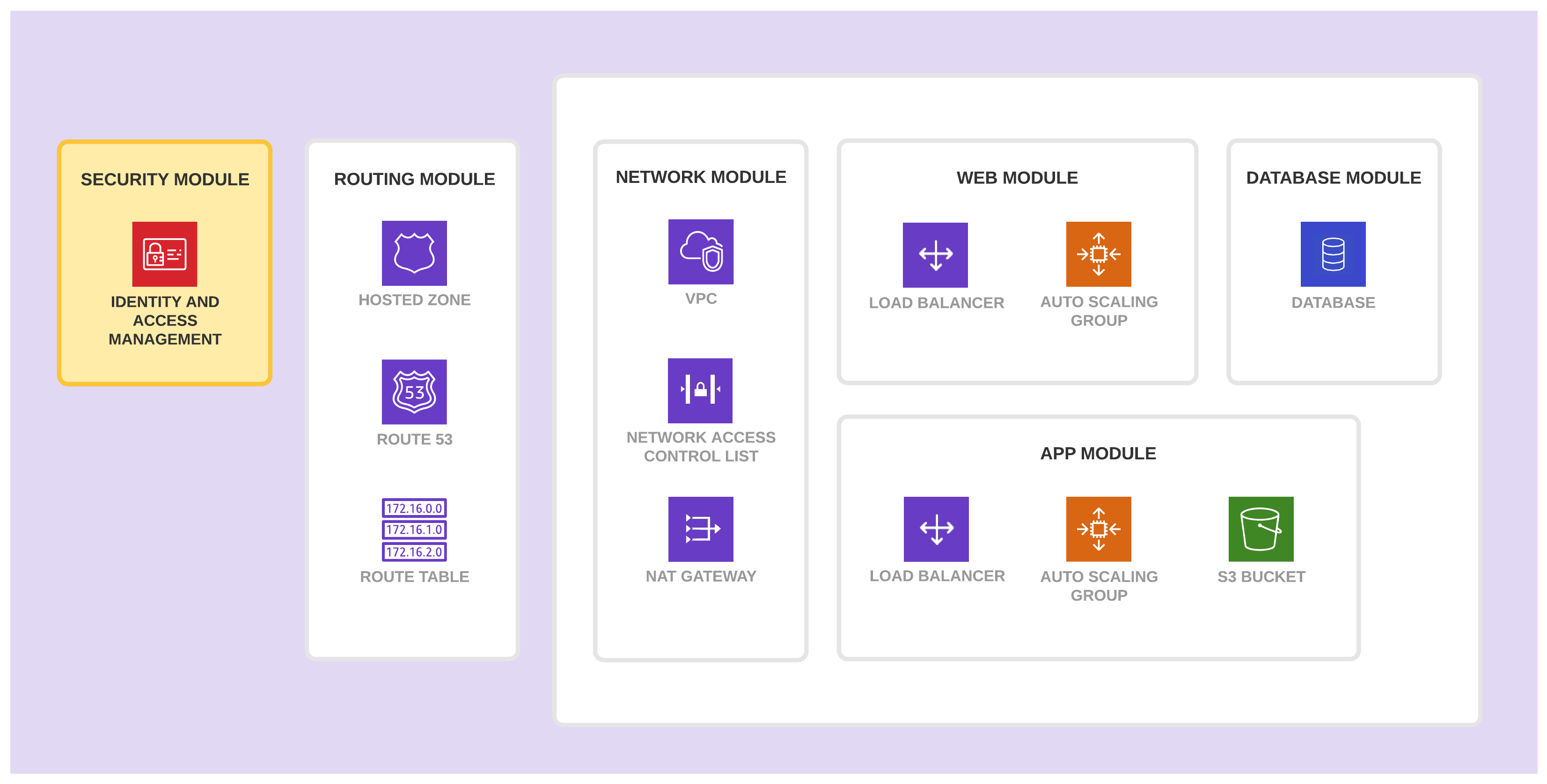
该模块包含这些资源是因为它们需要特定权限并且变化频率较低。
- 只有应用程序团队中有权创建或修改 IAM 或是安全资源的成员可以使用该模块。
- 该模块的资源不会经常变更。将它们组合在单独的模块中可以保护它们免于暴露在没有必要的数据丢失的风险之中。
1.6.5.1.3. 创建模块的提示
除了范围界定之外,我们在创建模块时还应牢记以下几点:
1.6.5.1.3.1. 嵌套模块
嵌套模块是指在当前模块中对另一个模块的引用。嵌套模块可以是外部的,也可以是当前工作空间内的。使用嵌套模块是一项强大的功能;然而我们必须谨慎实践以避免引入错误。
对于所有类型的嵌套模块,请考虑以下事项:
- 嵌套模块可以加速开发速度,但可能会引发未知以及意料之外的结果。请在文档中清晰地记录输入变量、模块行为以及输出值。
- 通常来说,不要让主模块的嵌套深度超过两层。常用且简单的工具模块,例如专门用来定义 Tag 的模块,则不受此限制制约。
- 嵌套模块必须包含必要的用来创建指定的资源配置的输入参数以及输出值。
- 输入参数以及输出值的命名应遵循一致的命名约定,以使得模块可以更容易地被分享,以及将一个模块的的输出值作为另一个模块的输入参数。
- 嵌套模块可能会导致代码冗余。必须同时在父模块与嵌套模块中声明输入参数和输出值。
嵌套的外部模块
当我们需要使用那些定义了被多个应用程序堆栈、应用程序和团队复用的标准化资源的通用模块时,嵌套的外部模块会很有用。外部模块通被集中管理和版本化控制,以使得消费者在使用新版本之前可以对其进行验证。当我们依赖或希望使用位于外部的子模块时,请注意以下几点:
- 外部模块必须被独立维护,并可供任何需要调用它的模块使用。使用模块注册表可以确保这一点。
- 根据模块注册要求,嵌套模块将拥有自己的版本控制代码仓库,独立于调用模块进行版本控制。
- 对嵌套模块的变更可能会影响调用模块,即使调用模块的调用代码及版本没有发生变化,这会破坏调用代码的信任。
- 对调用模块如何使用外部模块在文档中进行记录,使得模块行为以及调用关系可以被轻松理解。
- 对外部模块的变更应该是向后兼容的。如果向后兼容是不可能的,则应清楚地记录需要对任何调用模块进行的更改,并将之分发给所有模块使用者以避免意外。
嵌套的嵌入模块
在当前工作空间中嵌入一个模块使得我们能够清晰地分离模块的逻辑组件,或是创建可在调用模块执行期间多次调用的可重用代码块。在下面的例子中,ec2-instance 是一个嵌入模块,根模块的 main.tf 引用了该模块:
1 | root-module-directory |
如果我们需要或者倾向于使用嵌入模块,需要考虑以下几点:
- 在“根模块”中添加嵌入模块意味着子模块与根模块被放在一起进行版本控制。
- 任何影响两个模块间兼容性的变更都会被快速发现,因为它们必须被一同测试和发布。
- (嵌入的)子模块不能被代码树之外的其他模块调用,所以可能会增加重复的代码。举例来说,如果嵌入的
ec2-instance模块是用来创建一台被用在多个地方的标准化的计算实例,该模块无法以这种形式被分享。
标签化模块名并记录在文档中
为我们的模块创建并遵循一个命名约定将使得模块易于理解与使用。这将促进模块的采用和贡献。以下是一个用以提升模块元素一致性的建议列表:
- 使用一个对人类来说一致且易于理解的模块命名约定。举例来说:
| terraform | cloud provider | function | full name |
|---|---|---|---|
| terraform | aws | consul cluster | terraform-aws-consul_cluser |
| terraform | aws | security module | terraform-aws-security |
| terraform | azure | database | terraform-azure-database |
- 使用人类可以理解的输入变量命名约定。模块是编写一次并多次使用的代码,因此请完整命名所有内容以提升可读性,并在编写代码时在文档中进行记录。
- 对所有模块进行文档记录。确保文档中包含有:
- 必填的输入变量:这些输入变量应该是经过深思熟虑后的选择。如果这些输入变量值未定义,模块运行将失败。只在必要时为这些输入变量设置默认值。例如
var.vpc_id永远不应该有默认值,因为每次使用模块时值都会不同。 - 可选的输入变量:这些输入变量应该有一个合理的,适用于大多数场景的默认值,同时又可以根据需求进行调整。公告输入变量的默认值。例如
var.elb_idle_timeout会有一个合理的默认值,但调用者也可以根据需求修改它的值。 - 输出值:列出模块的所有输出值,并将重要的输出和信息性的输出包装在对用户友好的输出模板中。
- 必填的输入变量:这些输入变量应该是经过深思熟虑后的选择。如果这些输入变量值未定义,模块运行将失败。只在必要时为这些输入变量设置默认值。例如
定义并使用一个一致的模块结构
虽然模块结构是一个品味问题,我们应当将模块的结构记录在文档中,并且在我们的所有模块之间保持统一的结构。为了要维持模块结构的一致:
- 定义一组模块必须包含的
.tf文件,定义它们应包含哪些内容 - 为模块定义一个
.gitignore(或类似作用的)文件 - 创建供样例代码所使用的输入变量值的标准方式(例如一个
terraform.tfvars.example文件) - 使用具有固定子目录的一致的目录结构,即使它们可能是空的
- 所有模块目录都必须包含一个
README文件详细记述目录存在的目的以及如何使用其中的文件
1.6.5.1.4. 模块的协作
随着团队模块的开发工作,简化我们的协作。
- 为每个模块创建路线图
- 从用户处收集需求信息,并按受欢迎程度进行优先级排序。
- 不使用模块的最常见原因是“它不符合我的要求”。收集这些需求并将它们添加到路线图或对用户的工作流程提出建议。
- 检查每一项需求以确认它引用的用例是否正确。
- 公布和维护需求列表。分享该列表并让用户参与列表管理过程。
- 不要为边缘用例排期。
- 将每一个决策记录进文档。
- 在公司内部采用开源社区原则。一些用户希望尽可能高效地使用这些模块,而另一些用户则希望帮助创建这些模块。
- 创建一个社区
- 维护一份清晰和公开的贡献指引
- 最终,我们将允许可信的社区成员获得某些模块的所有权
1.6.5.1.5. 使用源代码控制系统追踪模块
一个 Terraform 模块应遵守所有良好的代码实践:
- 将模块置于源代码控制中以管理版本发布、协作、变更的审计跟踪。
- 为所有
main分支的发布版本建立版本标签,记录文档(最起码在CHANGELOG及README中记录)。 - 对
main分支的所有变更进行代码审查 - 鼓励模块的用户通过版本标签引用模块
- 为每一个模块指派一位负责人
- 一个代码仓库只负责一个模块
- 这对于模块的幂等性和作为库的功能至关重要。
- 我们应该对模块打上版本标签或是版本化控制。打上版本标签或是版本化的模块应该是不可变的。
- 发布到私有模块注册表的模块必须要有版本标签。
1.6.5.1.6. 开发一套模块消费工作流
定义和宣传一套消费者团队使用模块时应遵循的可重复工作流程。这个工作流程,就像模块本身一样,应该考虑到用户的需求。
1.6.5.1.6.1. 阐明团队应该如何使用模块
- 分散的安全性:如果每个模块都在自己的存储库中进行版本控制,则可以使用存储库 RBAC 来管理谁拥有写访问权限,从而允许相关团队管理相关的基础设施(例如网络团队拥有对网络模块的写访问权限)。
- 培育代码社区:鉴于上述建议,模块开发的最佳实践是允许对存储在私有模块存储库中的模块的所有模块存储库提出 Pull Request。这促进了组织内的代码社区,保持模块内容的相关性和最大的灵活性,并有助于保持模块注册表的长期有效性。