行为型模式主要涉及算法和对象间的职责分配。通过使用对象组合,行为型模式可以描述一组对象应该如何协作来完成一个整体任务。
行为型模式有:
责任链
命令
解释器
迭代器
中介
备忘录
观察者
状态
策略
模板方法
访问者
使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
责任链模式(Chain of Responsibility)是一种处理请求的模式,它让多个处理器都有机会处理该请求,直到其中某个处理成功为止。责任链模式把多个处理器串成链,然后让请求在链上传递:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌─────────┐ │ Request │ └─────────┘ │ ┌ ─ ─ ─ ─ ┼ ─ ─ ─ ─ ┐ ▼ │ ┌─────────────┐ │ │ ProcessorA │ │ └─────────────┘ │ │ │ ▼ │ ┌─────────────┐ │ │ ProcessorB │ │ └─────────────┘ │ │ │ ▼ │ ┌─────────────┐ │ │ ProcessorC │ │ └─────────────┘ │ │ └ ─ ─ ─ ─ ┼ ─ ─ ─ ─ ┘ │ ▼
在实际场景中,财务审批就是一个责任链模式。假设某个员工需要报销一笔费用,审核者可以分为:
Manager:只能审核1000元以下的报销;
Director:只能审核10000元以下的报销;
CEO:可以审核任意额度。
用责任链模式设计此报销流程时,每个审核者只关心自己责任范围内的请求,并且处理它。对于超出自己责任范围的,扔给下一个审核者处理,这样,将来继续添加审核者的时候,不用改动现有逻辑。
我们来看看如何实现责任链模式。
首先,我们要抽象出请求对象,它将在责任链上传递:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class Request { private String name; private BigDecimal amount; public Request (String name, BigDecimal amount) { this .name = name; this .amount = amount; } public String getName () { return name; } public BigDecimal getAmount () { return amount; } }
其次,我们要抽象出处理器:
1 2 3 4 5 6 public interface Handler { Boolean process (Request request) ; }
并且做好约定:如果返回Boolean.TRUE,表示处理成功,如果返回Boolean.FALSE,表示处理失败(请求被拒绝),如果返回null,则交由下一个Handler处理。
然后,依次编写ManagerHandler、DirectorHandler和CEOHandler。以ManagerHandler为例:
1 2 3 4 5 6 7 8 9 10 public class ManagerHandler implements Handler { public Boolean process (Request request) { if (request.getAmount().compareTo(BigDecimal.valueOf(1000 )) > 0 ) { return null ; } return !request.getName().equalsIgnoreCase("bob" ); } }
有了不同的Handler后,我们还要把这些Handler组合起来,变成一个链,并通过一个统一入口处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class HandlerChain { private List<Handler> handlers = new ArrayList <>(); public void addHandler (Handler handler) { this .handlers.add(handler); } public boolean process (Request request) { for (Handler handler : handlers) { Boolean r = handler.process(request); if (r != null ) { System.out.println(request + " " + (r ? "Approved by " : "Denied by " ) + handler.getClass().getSimpleName()); return r; } } throw new RuntimeException ("Could not handle request: " + request); } }
现在,我们就可以在客户端组装出责任链,然后用责任链来处理请求:
1 2 3 4 5 6 7 8 9 10 HandlerChain chain = new HandlerChain ();chain.addHandler(new ManagerHandler ()); chain.addHandler(new DirectorHandler ()); chain.addHandler(new CEOHandler ()); chain.process(new Request ("Bob" , new BigDecimal ("123.45" ))); chain.process(new Request ("Alice" , new BigDecimal ("1234.56" ))); chain.process(new Request ("Bill" , new BigDecimal ("12345.67" ))); chain.process(new Request ("John" , new BigDecimal ("123456.78" )));
责任链模式本身很容易理解,需要注意的是,Handler添加的顺序很重要,如果顺序不对,处理的结果可能就不是符合要求的。
此外,责任链模式有很多变种。有些责任链的实现方式是通过某个Handler手动调用下一个Handler来传递Request,例如:
1 2 3 4 5 6 7 8 9 10 11 public class AHandler implements Handler { private Handler next; public void process (Request request) { if (!canProcess(request)) { next.process(request); } else { ... } } }
还有一些责任链模式,每个Handler都有机会处理Request,通常这种责任链被称为拦截器(Interceptor)或者过滤器(Filter),它的目的不是找到某个Handler处理掉Request,而是每个Handler都做一些工作,比如:
例如,JavaEE的Servlet规范定义的Filter就是一种责任链模式,它不但允许每个Filter都有机会处理请求,还允许每个Filter决定是否将请求“放行”给下一个Filter:
1 2 3 4 5 6 7 8 9 10 11 12 public class AuditFilter implements Filter { public void doFilter (ServletRequest req, ServletResponse resp, FilterChain chain) throws IOException, ServletException { log(req); if (check(req)) { chain.doFilter(req, resp); } else { sendError(resp); } } }
这种模式不但允许一个Filter自行决定处理ServletRequest和ServletResponse,还可以“伪造”ServletRequest和ServletResponse以便让下一个Filter处理,能实现非常复杂的功能。
练习
使用责任链模式实现审批。
下载练习
小结
责任链模式是一种把多个处理器组合在一起,依次处理请求的模式;
责任链模式的好处是添加新的处理器或者重新排列处理器非常容易;
责任链模式经常用在拦截、预处理请求等。
将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化,对请求排队或记录请求日志,以及支持可撤销的操作。
命令模式(Command)是指,把请求封装成一个命令,然后执行该命令。
在使用命令模式前,我们先以一个编辑器为例子,看看如何实现简单的编辑操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class TextEditor { private StringBuilder buffer = new StringBuilder (); public void copy () { ... } public void paste () { String text = getFromClipBoard(); add(text); } public void add (String s) { buffer.append(s); } public void delete () { if (buffer.length() > 0 ) { buffer.deleteCharAt(buffer.length() - 1 ); } } public String getState () { return buffer.toString(); } }
我们用一个StringBuilder模拟一个文本编辑器,它支持copy()、paste()、add()、delete()等方法。
正常情况,我们像这样调用TextEditor:
1 2 3 4 5 TextEditor editor = new TextEditor ();editor.add("Command pattern in text editor.\n" ); editor.copy(); editor.paste(); System.out.println(editor.getState());
这是直接调用方法,调用方需要了解TextEditor的所有接口信息。
如果改用命令模式,我们就要把调用方发送命令和执行方执行命令分开。怎么分?
解决方案是引入一个Command接口:
1 2 3 public interface Command { void execute () ; }
调用方创建一个对应的Command,然后执行,并不关心内部是如何具体执行的。
为了支持CopyCommand和PasteCommand这两个命令,我们从Command接口派生:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class CopyCommand implements Command { private TextEditor receiver; public CopyCommand (TextEditor receiver) { this .receiver = receiver; } public void execute () { receiver.copy(); } } public class PasteCommand implements Command { private TextEditor receiver; public PasteCommand (TextEditor receiver) { this .receiver = receiver; } public void execute () { receiver.paste(); } }
最后我们把Command和TextEditor组装一下,客户端这么写:
1 2 3 4 5 6 7 8 9 10 TextEditor editor = new TextEditor ();editor.add("Command pattern in text editor.\n" ); Command copy = new CopyCommand (editor);copy.execute(); editor.add("----\n" ); Command paste = new PasteCommand (editor);paste.execute(); System.out.println(editor.getState());
这就是命令模式的结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌──────┐ ┌───────┐ │Client│─ ─ ─▶│Command│ └──────┘ └───────┘ │ ┌──────────────┐ ├─▶│ CopyCommand │ │ ├──────────────┤ │ │editor.copy() │─ ┐ │ └──────────────┘ │ │ ┌────────────┐ │ ┌──────────────┐ ─▶│ TextEditor │ └─▶│ PasteCommand │ │ └────────────┘ ├──────────────┤ │editor.paste()│─ ┘ └──────────────┘
有的童鞋会有疑问:搞了一大堆Command,多了好几个类,还不如直接这么写简单:
1 2 3 4 TextEditor editor = new TextEditor ();editor.add("Command pattern in text editor.\n" ); editor.copy(); editor.paste();
实际上,使用命令模式,确实增加了系统的复杂度。如果需求很简单,那么直接调用显然更直观而且更简单。
那么我们还需要命令模式吗?
答案是视需求而定。如果TextEditor复杂到一定程度,并且需要支持Undo、Redo的功能时,就需要使用命令模式,因为我们可以给每个命令增加undo():
1 2 3 4 public interface Command { void execute () ; void undo () ; }
然后把执行的一系列命令用List保存起来,就既能支持Undo,又能支持Redo。这个时候,我们又需要一个Invoker对象,负责执行命令并保存历史命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌─────────────┐ │ Client │ └─────────────┘ │ │ ▼ ┌─────────────┐ │ Invoker │ ├─────────────┤ ┌───────┐ │List commands│─ ─▶│Command│ │invoke(c) │ └───────┘ │undo() │ │ ┌──────────────┐ └─────────────┘ ├─▶│ CopyCommand │ │ ├──────────────┤ │ │editor.copy() │─ ┐ │ └──────────────┘ │ │ ┌────────────┐ │ ┌──────────────┐ ─▶│ TextEditor │ └─▶│ PasteCommand │ │ └────────────┘ ├──────────────┤ │editor.paste()│─ ┘ └──────────────┘
可见,模式带来的设计复杂度的增加是随着需求而增加的,它减少的是系统各组件的耦合度。
练习
给命令模式新增Add和Delete命令并支持Undo、Redo操作。
下载练习
小结
命令模式的设计思想是把命令的创建和执行分离,使得调用者无需关心具体的执行过程。
通过封装Command对象,命令模式可以保存已执行的命令,从而支持撤销、重做等操作。
解释器
给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
解释器模式(Interpreter)是一种针对特定问题设计的一种解决方案。例如,匹配字符串的时候,由于匹配条件非常灵活,使得通过代码来实现非常不灵活。举个例子,针对以下的匹配条件:
以+开头的数字表示的区号和电话号码,如+861012345678;
以英文开头,后接英文和数字,并以.分隔的域名,如www.liaoxuefeng.com;
以/开头的文件路径,如/path/to/file.txt;
…
因此,需要一种通用的表示方法——正则表达式来进行匹配。正则表达式就是一个字符串,但要把正则表达式解析为语法树,然后再匹配指定的字符串,就需要一个解释器。
实现一个完整的正则表达式的解释器非常复杂,但是使用解释器模式却很简单:
1 2 String s = "+861012345678" ;System.out.println(s.matches("^\\+\\d+$" ));
类似的,当我们使用JDBC时,执行的SQL语句虽然是字符串,但最终需要数据库服务器的SQL解释器来把SQL“翻译”成数据库服务器能执行的代码,这个执行引擎也非常复杂,但对于使用者来说,仅仅需要写出SQL字符串即可。
练习
请实现一个简单的解释器,它可以以SLF4J的日志格式输出字符串:
1 2 log("[{}] start {} at {}..." , LocalTime.now().withNano(0 ), "engine" , LocalDate.now());
下载练习
小结
解释器模式通过抽象语法树实现对用户输入的解释执行。
解释器模式的实现通常非常复杂,且一般只能解决一类特定问题。
迭代器
提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。
迭代器模式(Iterator)实际上在Java的集合类中已经广泛使用了。我们以List为例,要遍历ArrayList,即使我们知道它的内部存储了一个Object[]数组,也不应该直接使用数组索引去遍历,因为这样需要了解集合内部的存储结构。如果使用Iterator遍历,那么,ArrayList和LinkedList都可以以一种统一的接口来遍历:
1 2 3 4 List<String> list = ... for (Iterator<String> it = list.iterator(); it.hasNext(); ) { String s = it.next(); }
实际上,因为Iterator模式十分有用,因此,Java允许我们直接把任何支持Iterator的集合对象用foreach循环写出来:
1 2 3 4 List<String> list = ... for (String s : list) {}
然后由Java编译器完成Iterator模式的所有循环代码。
虽然我们对如何使用Iterator有了一定了解,但如何实现一个Iterator模式呢?我们以一个自定义的集合为例,通过Iterator模式实现倒序遍历:
1 2 3 4 5 6 7 8 9 10 11 12 public class ReverseArrayCollection <T> implements Iterable <T> { private T[] array; public ReverseArrayCollection (T... objs) { this .array = Arrays.copyOfRange(objs, 0 , objs.length); } public Iterator<T> iterator () { return ???; } }
实现Iterator模式的关键是返回一个Iterator对象,该对象知道集合的内部结构,因为它可以实现倒序遍历。我们使用Java的内部类实现这个Iterator:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class ReverseArrayCollection <T> implements Iterable <T> { private T[] array; public ReverseArrayCollection (T... objs) { this .array = Arrays.copyOfRange(objs, 0 , objs.length); } public Iterator<T> iterator () { return new ReverseIterator (); } class ReverseIterator implements Iterator <T> { int index; public ReverseIterator () { this .index = ReverseArrayCollection.this .array.length; } public boolean hasNext () { return index > 0 ; } public T next () { index--; return array[index]; } } }
使用内部类的好处是内部类隐含地持有一个它所在对象的this引用,可以通过ReverseArrayCollection.this引用到它所在的集合。上述代码实现的逻辑非常简单,但是实际应用时,如果考虑到多线程访问,当一个线程正在迭代某个集合,而另一个线程修改了集合的内容时,是否能继续安全地迭代,还是抛出ConcurrentModificationException,就需要更仔细地设计。
练习
使用Iterator模式实现集合的倒序遍历。
下载练习
小结
Iterator模式常用于遍历集合,它允许集合提供一个统一的Iterator接口来遍历元素,同时保证调用者对集合内部的数据结构一无所知,从而使得调用者总是以相同的接口遍历各种不同类型的集合。
中介
用一个中介对象来封装一系列的对象交互。中介者使各个对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
中介模式(Mediator)又称调停者模式,它的目的是把多方会谈变成双方会谈,从而实现多方的松耦合。
有些童鞋听到中介立刻想到房产中介,立刻气不打一处来。这个中介模式与房产中介还真有点像,所以消消气,先看例子。
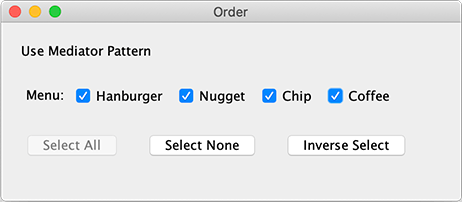
考虑一个简单的点餐输入:
这个小系统有4个参与对象:
多选框;
“选择全部”按钮;
“取消所有”按钮;
“反选”按钮。
它的复杂性在于,当多选框变化时,它会影响“选择全部”和“取消所有”按钮的状态(是否可点击),当用户点击某个按钮时,例如“反选”,除了会影响多选框的状态,它又可能影响“选择全部”和“取消所有”按钮的状态。
所以这是一个多方会谈,逻辑写起来很复杂:
1 2 3 4 5 6 7 8 9 ┌─────────────────┐ ┌─────────────────┐ │ CheckBox List │◀───▶│SelectAll Button │ └─────────────────┘ └─────────────────┘ ▲ ▲ ▲ │ └─────────────────────┤ ▼ │ ┌─────────────────┐ ┌────────┴────────┐ │SelectNone Button│◀────│ Inverse Button │ └─────────────────┘ └─────────────────┘
如果我们引入一个中介,把多方会谈变成多个双方会谈,虽然多了一个对象,但对象之间的关系就变简单了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌─────────────────┐ ┌─────▶│ CheckBox List │ │ └─────────────────┘ │ ┌─────────────────┐ │ ┌───▶│SelectAll Button │ ▼ ▼ └─────────────────┘ ┌─────────┐ │Mediator │ └─────────┘ ▲ ▲ ┌─────────────────┐ │ └───▶│SelectNone Button│ │ └─────────────────┘ │ ┌─────────────────┐ └─────▶│ Inverse Button │ └─────────────────┘
下面我们用中介模式来实现各个UI组件的交互。首先把UI组件给画出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Main { public static void main (String[] args) { new OrderFrame ("Hanburger" , "Nugget" , "Chip" , "Coffee" ); } } class OrderFrame extends JFrame { public OrderFrame (String... names) { setTitle("Order" ); setSize(460 , 200 ); setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE); Container c = getContentPane(); c.setLayout(new FlowLayout (FlowLayout.LEADING, 20 , 20 )); c.add(new JLabel ("Use Mediator Pattern" )); List<JCheckBox> checkboxList = addCheckBox(names); JButton selectAll = addButton("Select All" ); JButton selectNone = addButton("Select None" ); selectNone.setEnabled(false ); JButton selectInverse = addButton("Inverse Select" ); new Mediator (checkBoxList, selectAll, selectNone, selectInverse); setVisible(true ); } private List<JCheckBox> addCheckBox (String... names) { JPanel panel = new JPanel (); panel.add(new JLabel ("Menu:" )); List<JCheckBox> list = new ArrayList <>(); for (String name : names) { JCheckBox checkbox = new JCheckBox (name); list.add(checkbox); panel.add(checkbox); } getContentPane().add(panel); return list; } private JButton addButton (String label) { JButton button = new JButton (label); getContentPane().add(button); return button; } }
然后,我们设计一个Mediator类,它引用4个UI组件,并负责跟它们交互:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 public class Mediator { private List<JCheckBox> checkBoxList; private JButton selectAll; private JButton selectNone; private JButton selectInverse; public Mediator (List<JCheckBox> checkBoxList, JButton selectAll, JButton selectNone, JButton selectInverse) { this .checkBoxList = checkBoxList; this .selectAll = selectAll; this .selectNone = selectNone; this .selectInverse = selectInverse; this .checkBoxList.forEach(checkBox -> { checkBox.addChangeListener(this ::onCheckBoxChanged); }); this .selectAll.addActionListener(this ::onSelectAllClicked); this .selectNone.addActionListener(this ::onSelectNoneClicked); this .selectInverse.addActionListener(this ::onSelectInverseClicked); } public void onCheckBoxChanged (ChangeEvent event) { boolean allChecked = true ; boolean allUnchecked = true ; for (var checkBox : checkBoxList) { if (checkBox.isSelected()) { allUnchecked = false ; } else { allChecked = false ; } } selectAll.setEnabled(!allChecked); selectNone.setEnabled(!allUnchecked); } public void onSelectAllClicked (ActionEvent event) { checkBoxList.forEach(checkBox -> checkBox.setSelected(true )); selectAll.setEnabled(false ); selectNone.setEnabled(true ); } public void onSelectNoneClicked (ActionEvent event) { checkBoxList.forEach(checkBox -> checkBox.setSelected(false )); selectAll.setEnabled(true ); selectNone.setEnabled(false ); } public void onSelectInverseClicked (ActionEvent event) { checkBoxList.forEach(checkBox -> checkBox.setSelected(!checkBox.isSelected())); onCheckBoxChanged(null ); } }
运行一下看看效果:
使用Mediator模式后,我们得到了以下好处:
各个UI组件互不引用,这样就减少了组件之间的耦合关系;
Mediator用于当一个组件发生状态变化时,根据当前所有组件的状态决定更新某些组件;
如果新增一个UI组件,我们只需要修改Mediator更新状态的逻辑,现有的其他UI组件代码不变。
Mediator模式经常用在有众多交互组件的UI上。为了简化UI程序,MVC模式以及MVVM模式都可以看作是Mediator模式的扩展。
练习
使用Mediator模式。
下载练习
小结
中介模式是通过引入一个中介对象,把多边关系变成多个双边关系,从而简化系统组件的交互耦合度。
备忘录
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
备忘录模式(Memento),主要用于捕获一个对象的内部状态,以便在将来的某个时候恢复此状态。
其实我们使用的几乎所有软件都用到了备忘录模式。最简单的备忘录模式就是保存到文件,打开文件。对于文本编辑器来说,保存就是把TextEditor类的字符串存储到文件,打开就是恢复TextEditor类的状态。对于图像编辑器来说,原理是一样的,只是保存和恢复的数据格式比较复杂而已。Java的序列化也可以看作是备忘录模式。
在使用文本编辑器的时候,我们还经常使用Undo、Redo这些功能。这些其实也可以用备忘录模式实现,即不定期地把TextEditor类的字符串复制一份存起来,这样就可以Undo或Redo。
标准的备忘录模式有这么几种角色:
Memento:存储的内部状态;
Originator:创建一个备忘录并设置其状态;
Caretaker:负责保存备忘录。
实际上我们在使用备忘录模式的时候,不必设计得这么复杂,只需要对类似TextEditor的类,增加getState()和setState()就可以了。
我们以一个文本编辑器TextEditor为例,它内部使用StringBuilder允许用户增删字符:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class TextEditor { private StringBuilder buffer = new StringBuilder (); public void add (char ch) { buffer.append(ch); } public void add (String s) { buffer.append(s); } public void delete () { if (buffer.length() > 0 ) { buffer.deleteCharAt(buffer.length() - 1 ); } } }
为了支持这个TextEditor能保存和恢复状态,我们增加getState()和setState()两个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class TextEditor { ... public String getState () { return buffer.toString(); } public void setState (String state) { this .buffer.delete(0 , this .buffer.length()); this .buffer.append(state); } }
对这个简单的文本编辑器,用一个String就可以表示其状态,对于复杂的对象模型,通常我们会使用JSON、XML等复杂格式。
练习
给TextEditor添加备忘录模式。
下载练习
小结
备忘录模式是为了保存对象的内部状态,并在将来恢复,大多数软件提供的保存、打开,以及编辑过程中的Undo、Redo都是备忘录模式的应用。
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
观察者模式(Observer)又称发布-订阅模式(Publish-Subscribe:Pub/Sub)。它是一种通知机制,让发送通知的一方(被观察方)和接收通知的一方(观察者)能彼此分离,互不影响。
要理解观察者模式,我们还是看例子。
假设一个电商网站,有多种Product(商品),同时,Customer(消费者)和Admin(管理员)对商品上架、价格改变都感兴趣,希望能第一时间获得通知。于是,Store(商场)可以这么写:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class Store { Customer customer; Admin admin; private Map<String, Product> products = new HashMap <>(); public void addNewProduct (String name, double price) { Product p = new Product (name, price); products.put(p.getName(), p); customer.onPublished(p); admin.onPublished(p); } public void setProductPrice (String name, double price) { Product p = products.get(name); p.setPrice(price); customer.onPriceChanged(p); admin.onPriceChanged(p); } }
我们观察上述Store类的问题:它直接引用了Customer和Admin。先不考虑多个Customer或多个Admin的问题,上述Store类最大的问题是,如果要加一个新的观察者类型,例如工商局管理员,Store类就必须继续改动。
因此,上述问题的本质是Store希望发送通知给那些关心Product的对象,但Store并不想知道这些人是谁。观察者模式就是要分离被观察者和观察者之间的耦合关系。
要实现这一目标也很简单,Store不能直接引用Customer和Admin,相反,它引用一个ProductObserver接口,任何人想要观察Store,只要实现该接口,并且把自己注册到Store即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Store { private List<ProductObserver> observers = new ArrayList <>(); private Map<String, Product> products = new HashMap <>(); public void addObserver (ProductObserver observer) { this .observers.add(observer); } public void removeObserver (ProductObserver observer) { this .observers.remove(observer); } public void addNewProduct (String name, double price) { Product p = new Product (name, price); products.put(p.getName(), p); observers.forEach(o -> o.onPublished(p)); } public void setProductPrice (String name, double price) { Product p = products.get(name); p.setPrice(price); observers.forEach(o -> o.onPriceChanged(p)); } }
就是这么一个小小的改动,使得观察者类型就可以无限扩充,而且,观察者的定义可以放到客户端:
1 2 3 4 5 6 7 8 Admin a = new Admin ();Customer c = new Customer ();Store store = new Store ();store.addObserver(a); store.addObserver(c);
甚至可以注册匿名观察者:
1 2 3 4 5 6 7 8 9 store.addObserver(new ProductObserver () { public void onPublished (Product product) { System.out.println("[Log] on product published: " + product); } public void onPriceChanged (Product product) { System.out.println("[Log] on product price changed: " + product); } });
用一张图画出观察者模式:
1 2 3 4 5 6 7 8 9 10 ┌─────────┐ ┌───────────────┐ │ Store │─ ─ ─▶│ProductObserver│ └─────────┘ └───────────────┘ │ ▲ │ │ ┌─────┴─────┐ ▼ │ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ Product │ │ Admin │ │Customer │ ... └─────────┘ └─────────┘ └─────────┘
观察者模式也有很多变体形式。有的观察者模式把被观察者也抽象出接口:
1 2 3 4 public interface ProductObservable { void addObserver (ProductObserver observer) ; void removeObserver (ProductObserver observer) ; }
对应的实体被观察者就要实现该接口:
1 2 3 public class Store implements ProductObservable { ... }
有些观察者模式把通知变成一个Event对象,从而不再有多种方法通知,而是统一成一种:
1 2 3 public interface ProductObserver { void onEvent (ProductEvent event) ; }
让观察者自己从Event对象中读取通知类型和通知数据。
广义的观察者模式包括所有消息系统。所谓消息系统,就是把观察者和被观察者完全分离,通过消息系统本身来通知:
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐ Messaging System │ │ ┌──────────────────┐ ┌──┼─▶│Topic:newProduct │─┼─┐ ┌─────────┐ │ └──────────────────┘ ├──▶│ConsumerA│ ┌─────────┐ │ │ ┌──────────────────┐ │ │ └─────────┘ │Producer │───┼────▶│Topic:priceChanged│───┘ └─────────┘ │ │ └──────────────────┘ │ │ ┌──────────────────┐ ┌─────────┐ └──┼─▶│Topic:soldOut │─┼────▶│ConsumerB│ └──────────────────┘ └─────────┘ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┘
消息发送方称为Producer,消息接收方称为Consumer,Producer发送消息的时候,必须选择发送到哪个Topic。Consumer可以订阅自己感兴趣的Topic,从而只获得特定类型的消息。
使用消息系统实现观察者模式时,Producer和Consumer甚至经常不在同一台机器上,并且双方对对方完全一无所知,因为注册观察者这个动作本身都在消息系统中完成,而不是在Producer内部完成。
此外,注意到我们在编写观察者模式的时候,通知Observer是依靠语句:
1 observers.forEach(o -> o.onPublished(p));
这说明各个观察者是依次获得的同步通知,如果上一个观察者处理太慢,会导致下一个观察者不能及时获得通知。此外,如果观察者在处理通知的时候,发生了异常,还需要被观察者处理异常,才能保证继续通知下一个观察者。
思考:如何改成异步通知,使得所有观察者可以并发同时处理?
有的童鞋可能发现Java标准库有个java.util.Observable类和一个Observer接口,用来帮助我们实现观察者模式。但是,这个类非常不!好!用!实现观察者模式的时候,也不推荐借助这两个东东。
练习
给Store增加一种类型的观察者,并把通知改为异步。
下载练习
小结
观察者模式,又称发布-订阅模式,是一种一对多的通知机制,使得双方无需关心对方,只关心通知本身。
状态
允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。
状态模式(State)经常用在带有状态的对象中。
什么是状态?我们以QQ聊天为例,一个用户的QQ有几种状态:
离线状态(尚未登录);
正在登录状态;
在线状态;
忙状态(暂时离开)。
如何表示状态?我们定义一个enum就可以表示不同的状态。但不同的状态需要对应不同的行为,比如收到消息时:
1 2 3 4 5 if (state == ONLINE) { } else if (state == BUSY) { reply("现在忙,稍后回复" ); } else if ...
状态模式的目的是为了把上述一大串if...else...的逻辑给分拆到不同的状态类中,使得将来增加状态比较容易。
例如,我们设计一个聊天机器人,它有两个状态:
对于未连线状态,我们收到消息也不回复:
1 2 3 4 5 6 7 8 9 public class DisconnectedState implements State { public String init () { return "Bye!" ; } public String reply (String input) { return "" ; } }
对于已连线状态,我们回应收到的消息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ConnectedState implements State { public String init () { return "Hello, I'm Bob." ; } public String reply (String input) { if (input.endsWith("?" )) { return "Yes. " + input.substring(0 , input.length() - 1 ) + "!" ; } if (input.endsWith("." )) { return input.substring(0 , input.length() - 1 ) + "!" ; } return input.substring(0 , input.length() - 1 ) + "?" ; } }
状态模式的关键设计思想在于状态切换,我们引入一个BotContext完成状态切换:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class BotContext { private State state = new DisconnectedState (); public String chat (String input) { if ("hello" .equalsIgnoreCase(input)) { state = new ConnectedState (); return state.init(); } else if ("bye" .equalsIgnoreCase(input)) { / 收到bye切换到离线状态: state = new DisconnectedState (); return state.init(); } return state.reply(input); } }
这样,一个价值千万的AI聊天机器人就诞生了:
1 2 3 4 5 6 7 8 Scanner scanner = new Scanner (System.in);BotContext bot = new BotContext ();for (;;) { System.out.print("> " ); String input = scanner.nextLine(); String output = bot.chat(input); System.out.println(output.isEmpty() ? "(no reply)" : "< " + output); }
试试效果:
1 2 3 4 5 6 7 8 > hello < Hello, I'm Bob. > Nice to meet you. < Nice to meet you! > Today is cold? < Yes. Today is cold! > bye < Bye!
练习
新增BusyState状态表示忙碌。
下载练习
小结
状态模式的设计思想是把不同状态的逻辑分离到不同的状态类中,从而使得增加新状态更容易;
状态模式的实现关键在于状态转换。简单的状态转换可以直接由调用方指定,复杂的状态转换可以在内部根据条件触发完成。
定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。
策略模式:Strategy,是指,定义一组算法,并把其封装到一个对象中。然后在运行时,可以灵活的使用其中的一个算法。
策略模式在Java标准库中应用非常广泛,我们以排序为例,看看如何通过Arrays.sort()实现忽略大小写排序:
1 2 3 4 5 6 7 8 9 import java.util.Arrays;public class Main { public static void main (String[] args) throws InterruptedException { String[] array = { "apple" , "Pear" , "Banana" , "orange" }; Arrays.sort(array, String::compareToIgnoreCase); System.out.println(Arrays.toString(array)); } }
如果我们想忽略大小写排序,就传入String::compareToIgnoreCase,如果我们想倒序排序,就传入(s1, s2) -> -s1.compareTo(s2),这个比较两个元素大小的算法就是策略。
我们观察Arrays.sort(T[] a, Comparator<? super T> c)这个排序方法,它在内部实现了TimSort排序,但是,排序算法在比较两个元素大小的时候,需要借助我们传入的Comparator对象,才能完成比较。因此,这里的策略是指比较两个元素大小的策略,可以是忽略大小写比较,可以是倒序比较,也可以根据字符串长度比较。
因此,上述排序使用到了策略模式,它实际上指,在一个方法中,流程是确定的,但是,某些关键步骤的算法依赖调用方传入的策略,这样,传入不同的策略,即可获得不同的结果,大大增强了系统的灵活性。
如果我们自己实现策略模式的排序,用冒泡法编写如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import java.util.*;public class Main { public static void main (String[] args) throws InterruptedException { String[] array = { "apple" , "Pear" , "Banana" , "orange" }; sort(array, String::compareToIgnoreCase); System.out.println(Arrays.toString(array)); } static <T> void sort (T[] a, Comparator<? super T> c) { for (int i = 0 ; i < a.length - 1 ; i++) { for (int j = 0 ; j < a.length - 1 - i; j++) { if (c.compare(a[j], a[j + 1 ]) > 0 ) { T temp = a[j]; a[j] = a[j + 1 ]; a[j + 1 ] = temp; } } } } }
一个完整的策略模式要定义策略以及使用策略的上下文。我们以购物车结算为例,假设网站针对普通会员、Prime会员有不同的折扣,同时活动期间还有一个满100减20的活动,这些就可以作为策略实现。先定义打折策略接口:
1 2 3 4 public interface DiscountStrategy { BigDecimal getDiscount (BigDecimal total) ; }
接下来,就是实现各种策略。普通用户策略如下:
1 2 3 4 5 6 public class UserDiscountStrategy implements DiscountStrategy { public BigDecimal getDiscount (BigDecimal total) { return total.multiply(new BigDecimal ("0.1" )).setScale(2 , RoundingMode.DOWN); } }
满减策略如下:
1 2 3 4 5 6 public class OverDiscountStrategy implements DiscountStrategy { public BigDecimal getDiscount (BigDecimal total) { return total.compareTo(BigDecimal.valueOf(100 )) >= 0 ? BigDecimal.valueOf(20 ) : BigDecimal.ZERO; } }
最后,要应用策略,我们需要一个DiscountContext:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class DiscountContext { private DiscountStrategy strategy = new UserDiscountStrategy (); public void setStrategy (DiscountStrategy strategy) { this .strategy = strategy; } public BigDecimal calculatePrice (BigDecimal total) { return total.subtract(this .strategy.getDiscount(total)).setScale(2 ); } }
调用方必须首先创建一个DiscountContext,并指定一个策略(或者使用默认策略),即可获得折扣后的价格:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 DiscountContext ctx = new DiscountContext ();BigDecimal pay1 = ctx.calculatePrice(BigDecimal.valueOf(105 ));System.out.println(pay1); ctx.setStrategy(new OverDiscountStrategy ()); BigDecimal pay2 = ctx.calculatePrice(BigDecimal.valueOf(105 ));System.out.println(pay2); ctx.setStrategy(new PrimeDiscountStrategy ()); BigDecimal pay3 = ctx.calculatePrice(BigDecimal.valueOf(105 ));System.out.println(pay3);
上述完整的策略模式如下图所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 ┌───────────────┐ ┌─────────────────┐ │DiscountContext│─ ─ ─▶│DiscountStrategy │ └───────────────┘ └─────────────────┘ ▲ │ ┌─────────────────────┐ ├─│UserDiscountStrategy │ │ └─────────────────────┘ │ ┌─────────────────────┐ ├─│PrimeDiscountStrategy│ │ └─────────────────────┘ │ ┌─────────────────────┐ └─│OverDiscountStrategy │ └─────────────────────┘
策略模式的核心思想是在一个计算方法中把容易变化的算法抽出来作为“策略”参数传进去,从而使得新增策略不必修改原有逻辑。
练习
使用策略模式新增一种策略,允许在满100减20的基础上对Prime会员再打七折。
下载练习
小结
策略模式是为了允许调用方选择一个算法,从而通过不同策略实现不同的计算结果。
通过扩展策略,不必修改主逻辑,即可获得新策略的结果。
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
模板方法(Template Method)是一个比较简单的模式。它的主要思想是,定义一个操作的一系列步骤,对于某些暂时确定不下来的步骤,就留给子类去实现好了,这样不同的子类就可以定义出不同的步骤。
因此,模板方法的核心在于定义一个“骨架”。我们还是举例说明。
假设我们开发了一个从数据库读取设置的类:
1 2 3 4 5 6 7 8 9 10 public class Setting { public final String getSetting (String key) { String value = readFromDatabase(key); return value; } private String readFromDatabase (String key) { } }
由于从数据库读取数据较慢,我们可以考虑把读取的设置缓存起来,这样下一次读取同样的key就不必再访问数据库了。但是怎么实现缓存,暂时没想好,但不妨碍我们先写出使用缓存的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Setting { public final String getSetting (String key) { String value = lookupCache(key); if (value == null ) { value = readFromDatabase(key); System.out.println("[DEBUG] load from db: " + key + " = " + value); putIntoCache(key, value); } else { System.out.println("[DEBUG] load from cache: " + key + " = " + value); } return value; } }
整个流程没有问题,但是,lookupCache(key)和putIntoCache(key, value)这两个方法还根本没实现,怎么编译通过?这个不要紧,我们声明抽象方法就可以:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public abstract class AbstractSetting { public final String getSetting (String key) { String value = lookupCache(key); if (value == null ) { value = readFromDatabase(key); putIntoCache(key, value); } return value; } protected abstract String lookupCache (String key) ; protected abstract void putIntoCache (String key, String value) ; }
因为声明了抽象方法,自然整个类也必须是抽象类。如何实现lookupCache(key)和putIntoCache(key, value)这两个方法就交给子类了。子类其实并不关心核心代码getSetting(key)的逻辑,它只需要关心如何完成两个小小的子任务就可以了。
假设我们希望用一个Map做缓存,那么可以写一个LocalSetting:
1 2 3 4 5 6 7 8 9 10 11 public class LocalSetting extends AbstractSetting { private Map<String, String> cache = new HashMap <>(); protected String lookupCache (String key) { return cache.get(key); } protected void putIntoCache (String key, String value) { cache.put(key, value); } }
如果我们要使用Redis做缓存,那么可以再写一个RedisSetting:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class RedisSetting extends AbstractSetting { private RedisClient client = RedisClient.create("redis://localhost:6379" ); protected String lookupCache (String key) { try (StatefulRedisConnection<String, String> connection = client.connect()) { RedisCommands<String, String> commands = connection.sync(); return commands.get(key); } } protected void putIntoCache (String key, String value) { try (StatefulRedisConnection<String, String> connection = client.connect()) { RedisCommands<String, String> commands = connection.sync(); commands.set(key, value); } } }
客户端代码使用本地缓存的代码这么写:
1 2 3 AbstractSetting setting1 = new LocalSetting ();System.out.println("test = " + setting1.getSetting("test" )); System.out.println("test = " + setting1.getSetting("test" ));
要改成Redis缓存,只需要把LocalSetting替换为RedisSetting:
1 2 3 AbstractSetting setting2 = new RedisSetting ();System.out.println("autosave = " + setting2.getSetting("autosave" )); System.out.println("autosave = " + setting2.getSetting("autosave" ));
可见,模板方法的核心思想是:父类定义骨架,子类实现某些细节。
为了防止子类重写父类的骨架方法,可以在父类中对骨架方法使用final。对于需要子类实现的抽象方法,一般声明为protected,使得这些方法对外部客户端不可见。
Java标准库也有很多模板方法的应用。在集合类中,AbstractList和AbstractQueuedSynchronizer都定义了很多通用操作,子类只需要实现某些必要方法。
练习
使用模板方法增加一个使用Guava Cache的子类。
下载练习
思考:能否将readFromDatabase()作为模板方法,使得子类可以选择从数据库读取还是从文件读取。
再思考如果既可以扩展缓存,又可以扩展底层存储,会不会出现子类数量爆炸的情况?如何解决?
小结
模板方法是一种高层定义骨架,底层实现细节的设计模式,适用于流程固定,但某些步骤不确定或可替换的情况。
表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
访问者模式(Visitor)是一种操作一组对象的操作,它的目的是不改变对象的定义,但允许新增不同的访问者,来定义新的操作。
访问者模式的设计比较复杂,如果我们查看GoF原始的访问者模式,它是这么设计的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 ┌─────────┐ ┌───────────────────────┐ │ Client │─ ─ ─ ▶│ Visitor │ └─────────┘ ├───────────────────────┤ │ │visitElementA(ElementA)│ │visitElementB(ElementB)│ │ └───────────────────────┘ ▲ │ ┌───────┴───────┐ │ │ │ ┌─────────────┐ ┌─────────────┐ │ VisitorA │ │ VisitorB │ │ └─────────────┘ └─────────────┘ ▼ ┌───────────────┐ ┌───────────────┐ │ObjectStructure│─ ─ ─ ─▶│ Element │ ├───────────────┤ ├───────────────┤ │handle(Visitor)│ │accept(Visitor)│ └───────────────┘ └───────────────┘ ▲ ┌────────┴────────┐ │ │ ┌───────────────┐ ┌───────────────┐ │ ElementA │ │ ElementB │ ├───────────────┤ ├───────────────┤ │accept(Visitor)│ │accept(Visitor)│ │doA() │ │doB() │ └───────────────┘ └───────────────┘
上述模式的复杂之处在于上述访问者模式为了实现所谓的“双重分派”,设计了一个回调再回调的机制。因为Java只支持基于多态的单分派模式,这里强行模拟出“双重分派”反而加大了代码的复杂性。
这里我们只介绍简化的访问者模式。假设我们要递归遍历某个文件夹的所有子文件夹和文件,然后找出.java文件,正常的做法是写个递归:
1 2 3 4 5 6 7 8 9 10 void scan (File dir, List<File> collector) { for (File file : dir.listFiles()) { if (file.isFile() && file.getName().endsWith(".java" )) { collector.add(file); } else if (file.isDir()) { scan(file, collector); } } }
上述代码的问题在于,扫描目录的逻辑和处理.java文件的逻辑混在了一起。如果下次需要增加一个清理.class文件的功能,就必须再重复写扫描逻辑。
因此,访问者模式先把数据结构(这里是文件夹和文件构成的树型结构)和对其的操作(查找文件)分离开,以后如果要新增操作(例如清理.class文件),只需要新增访问者,不需要改变现有逻辑。
用访问者模式改写上述代码步骤如下:
首先,我们需要定义访问者接口,即该访问者能够干的事情:
1 2 3 4 5 6 public interface Visitor { void visitDir (File dir) ; void visitFile (File file) ; }
紧接着,我们要定义能持有文件夹和文件的数据结构FileStructure:
1 2 3 4 5 6 7 public class FileStructure { private File path; public FileStructure (File path) { this .path = path; } }
然后,我们给FileStructure增加一个handle()方法,传入一个访问者:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class FileStructure { ... public void handle (Visitor visitor) { scan(this .path, visitor); } private void scan (File file, Visitor visitor) { if (file.isDirectory()) { visitor.visitDir(file); for (File sub : file.listFiles()) { scan(sub, visitor); } } else if (file.isFile()) { visitor.visitFile(file); } } }
这样,我们就把访问者的行为抽象出来了。如果我们要实现一种操作,例如,查找.java文件,就传入JavaFileVisitor:
1 2 FileStructure fs = new FileStructure (new File ("." ));fs.handle(new JavaFileVisitor ());
这个JavaFileVisitor实现如下:
1 2 3 4 5 6 7 8 9 10 11 public class JavaFileVisitor implements Visitor { public void visitDir (File dir) { System.out.println("Visit dir: " + dir); } public void visitFile (File file) { if (file.getName().endsWith(".java" )) { System.out.println("Found java file: " + file); } } }
类似的,如果要清理.class文件,可以再写一个ClassFileClearnerVisitor:
1 2 3 4 5 6 7 8 9 10 public class ClassFileCleanerVisitor implements Visitor { public void visitDir (File dir) { } public void visitFile (File file) { if (file.getName().endsWith(".class" )) { System.out.println("Will clean class file: " + file); } } }
可见,访问者模式的核心思想是为了访问比较复杂的数据结构,不去改变数据结构,而是把对数据的操作抽象出来,在“访问”的过程中以回调形式在访问者中处理操作逻辑。如果要新增一组操作,那么只需要增加一个新的访问者。
实际上,Java标准库提供的Files.walkFileTree()已经实现了一个访问者模式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import java.io.*;import java.nio.file.*;import java.nio.file.attribute.*;public class Main { public static void main (String[] args) throws IOException { Files.walkFileTree(Paths.get("." ), new MyFileVisitor ()); } } class MyFileVisitor extends SimpleFileVisitor <Path> { public FileVisitResult preVisitDirectory (Path dir, BasicFileAttributes attrs) throws IOException { System.out.println("pre visit dir: " + dir); return FileVisitResult.CONTINUE; } public FileVisitResult visitFile (Path file, BasicFileAttributes attrs) throws IOException { System.out.println("visit file: " + file); return FileVisitResult.CONTINUE; } }
Files.walkFileTree()允许访问者返回FileVisitResult.CONTINUE以便继续访问,或者返回FileVisitResult.TERMINATE停止访问。
类似的,对XML的SAX处理也是一个访问者模式,我们需要提供一个SAX Handler作为访问者处理XML的各个节点。
练习
使用访问者模式递归遍历文件夹。
下载练习
小结
访问者模式是为了抽象出作用于一组复杂对象的操作,并且后续可以新增操作而不必对现有的对象结构做任何改动。