
17.python访问数据库
程序运行的时候,数据都是在内存中的。当程序终止的时候,通常都需要将数据保存到磁盘上,无论是保存到本地磁盘,还是通过网络保存到服务器上,最终都会将数据写入磁盘文件。
而如何定义数据的存储格式就是一个大问题。如果我们自己来定义存储格式,比如保存一个班级所有学生的成绩单:
| 名字 | 成绩 |
|---|---|
| Michael | 99 |
| Bob | 85 |
| Bart | 59 |
| Lisa | 87 |
我们可以用一个文本文件保存,一行保存一个学生,用,隔开:
1 | Michael,99 |
还可以用JSON格式保存,也是文本文件:
1 | [ |
还可以定义各种保存格式,但是问题来了:
存储和读取需要自己实现,JSON还是标准,自己定义的格式就各式各样了;
不能做快速查询,只有把数据全部读到内存中才能自己遍历,但有时候数据的大小远远超过了内存,根本无法全部读入内存。
为了便于程序保存和读取数据,而且,能直接通过条件快速查询到指定的数据,就出现了数据库(Database)这种专门用于集中存储和查询的软件。
数据库软件诞生的历史非常久远,早在1950年数据库就诞生了。经历了网状数据库,层次数据库,我们现在广泛使用的关系数据库是20世纪70年代基于关系模型的基础上诞生的。
关系模型有一套复杂的数学理论,但是从概念上是十分容易理解的。举个学校的例子:
假设某个XX省YY市ZZ县第一实验小学有3个年级,要表示出这3个年级,可以在Excel中用一个表格画出来:

每个年级又有若干个班级,要把所有班级表示出来,可以在Excel中再画一个表格:
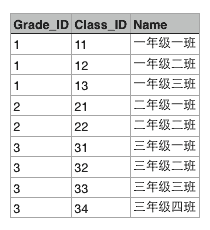
这两个表格有个映射关系,就是根据Grade_ID可以在班级表中查找到对应的所有班级:
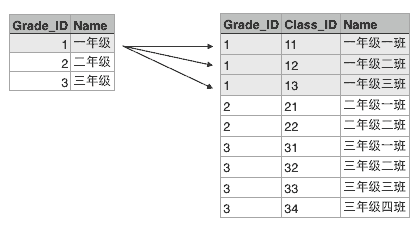
也就是Grade表的每一行对应Class表的多行,在关系数据库中,这种基于表(Table)的一对多的关系就是关系数据库的基础。
根据某个年级的ID就可以查找所有班级的行,这种查询语句在关系数据库中称为SQL语句,可以写成:
1 | SELECT * FROM classes WHERE grade_id = '1'; |
结果也是一个表:
| grade_id | class_id | name |
|---|---|---|
| 1 | 11 | 一年级一班 |
| 1 | 12 | 一年级二班 |
| 1 | 13 | 一年级三班 |
类似的,Class表的一行记录又可以关联到Student表的多行记录:
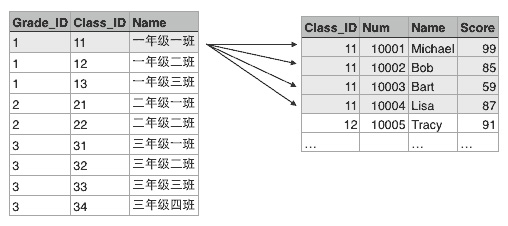
由于本教程不涉及到关系数据库的详细内容,如果你想从零学习关系数据库和基本的SQL语句,请参考SQL教程。
NoSQL
你也许还听说过NoSQL数据库,很多NoSQL宣传其速度和规模远远超过关系数据库,所以很多同学觉得有了NoSQL是否就不需要SQL了呢?千万不要被他们忽悠了,连SQL都不明白怎么可能搞明白NoSQL呢?
数据库类别
既然我们要使用关系数据库,就必须选择一个关系数据库。目前广泛使用的关系数据库也就这么几种:
付费的商用数据库:
- Oracle,典型的高富帅;
- SQL Server,微软自家产品,Windows定制专款;
- DB2,IBM的产品,听起来挺高端;
- Sybase,曾经跟微软是好基友,后来关系破裂,现在家境惨淡。
这些数据库都是不开源而且付费的,最大的好处是花了钱出了问题可以找厂家解决,不过在Web的世界里,常常需要部署成千上万的数据库服务器,当然不能把大把大把的银子扔给厂家,所以,无论是Google、Facebook,还是国内的BAT,无一例外都选择了免费的开源数据库:
- MySQL,大家都在用,一般错不了;
- PostgreSQL,学术气息有点重,其实挺不错,但知名度没有MySQL高;
- SQLite,嵌入式数据库,适合桌面和移动应用。
作为一个Python工程师,选择哪个免费数据库呢?这里我们会介绍SQLite和MySQL,SQLite适合作为嵌入式数据库,优点是不用安装任何软件,直接能用。生产环境下,应当选择MySQL或者PostgreSQL。
SQLite是一种嵌入式数据库,它的数据库就是一个文件。由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成。
Python就内置了SQLite3,所以,在Python中使用SQLite,不需要安装任何东西,直接使用。
在使用SQLite前,我们先要搞清楚几个概念:
表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,比如学生的表,班级的表,学校的表,等等。表和表之间通过外键关联。
要操作关系数据库,首先需要连接到数据库,一个数据库连接称为Connection;
连接到数据库后,需要打开游标,称之为Cursor,通过Cursor执行SQL语句,然后,获得执行结果。
Python定义了一套操作数据库的API接口,任何数据库要连接到Python,只需要提供符合Python标准的数据库驱动即可。
由于SQLite的驱动内置在Python标准库中,所以我们可以直接来操作SQLite数据库。
我们在Python交互式命令行实践一下:
1 | # 导入SQLite驱动: |
我们再试试查询记录:
1 | >>> conn = sqlite3.connect('test.db') |
使用Python的DB-API时,只要搞清楚Connection和Cursor对象,打开后一定记得关闭,就可以放心地使用。
使用Cursor对象执行insert,update,delete语句时,执行结果由rowcount返回影响的行数,就可以拿到执行结果。
使用Cursor对象执行select语句时,通过fetchall()可以拿到结果集。结果集是一个list,每个元素都是一个tuple,对应一行记录。
如果SQL语句带有参数,那么需要把参数按照位置传递给execute()方法,有几个?占位符就必须对应几个参数,例如:
1 | cursor.execute('select * from user where name=? and pwd=?', ('abc', 'password')) |
SQLite支持常见的标准SQL语句以及几种常见的数据类型。具体文档请参阅SQLite官方网站。
小结
在Python中操作数据库时,要先导入数据库对应的驱动,然后,通过Connection对象和Cursor对象操作数据。
要确保打开的Connection对象和Cursor对象都正确地被关闭,否则,资源就会泄露。
如何才能确保出错的情况下也关闭掉Connection对象和Cursor对象呢?请回忆try:...except:...finally:...的用法。
练习
请编写函数,在Sqlite中根据分数段查找指定的名字:
1 | import os, sqlite3 |
参考源码
MySQL是Web世界中使用最广泛的数据库服务器。SQLite的特点是轻量级、可嵌入,但不能承受高并发访问,适合桌面和移动应用。而MySQL是为服务器端设计的数据库,能承受高并发访问,同时占用的内存也远远大于SQLite。
此外,MySQL内部有多种数据库引擎,最常用的引擎是支持数据库事务的InnoDB。
安装MySQL
可以直接从MySQL官方网站下载最新的Community Server 8.x版本。MySQL是跨平台的,选择对应的平台下载安装文件,安装即可。
安装时,MySQL会提示输入root用户的口令,请务必记清楚。如果怕记不住,就把口令设置为password。
在Windows上,安装时请选择UTF-8编码,以便正确地处理中文。
在Mac或Linux上,需要编辑MySQL的配置文件,把数据库默认的编码全部改为UTF-8。MySQL的配置文件默认存放在/etc/my.cnf或者/etc/mysql/my.cnf:
1 | [client] |
重启MySQL后,可以通过MySQL的客户端命令行检查编码:
1 | $ mysql -u root -p |
看到utf8mb4字样就表示编码设置正确。
注意
如果MySQL的版本<5.5.3,则只能把编码设置为utf8,utf8mb4支持最新的Unicode标准,可以显示emoji字符,但utf8无法显示emoji字符。
用Docker启动MySQL
如果不想安装MySQL,还可以以Docker的方式快速启动MySQL。
首先安装Docker Desktop,然后在命令行输入:
1 | $ docker run -e MYSQL_ROOT_PASSWORD=password -p 3306:3306 --name mysql-8.4 -v ./mysql-data:/var/lib/mysql mysql:8.4 --mysql-native-password=ON --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci |
上述命令详细参数如下:
-e MYSQL_ROOT_PASSWORD=password:传入root用户口令的环境变量,密码是password;-p 3306:3306:在本机3306端口监听;--name mysql-8.4:启动后容器的名称为mysql-8.4,可任意设置;-v ./mysql-data:/var/lib/mysql:把当前目录./mysql-data映射到容器目录/var/lib/mysql,此目录存放MySQL数据库文件,避免容器停止后数据丢失;mysql:8.4:启动镜像名称为mysql:8.4;--mysql-native-password=ON:表示启用明文口令;--character-set-server=utf8mb4:表示启用utf8mb4作为字符集;--collation-server=utf8mb4_unicode_ci:表示启用utf8mb4作为排序规则。
运行命令后可看到如下输出:
1 | 2024-07-11 02:44:05+00:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.4.1-1.el9 started. |
看到最后一行ready for connections表示启动成功。
安装MySQL驱动
由于MySQL服务器以独立的进程运行,并通过网络对外服务,所以,需要支持Python的MySQL驱动来连接到MySQL服务器。MySQL官方提供了mysql-connector-python驱动:
1 | $ pip install mysql-connector-python |
我们演示如何连接到MySQL服务器的test数据库:
1 | # 导入MySQL驱动: |
由于Python的DB-API定义都是通用的,所以,操作MySQL的数据库代码和SQLite类似。
小结
- 执行INSERT等操作后要调用
commit()提交事务; - MySQL的SQL占位符是
%s。
参考源码
数据库表是一个二维表,包含多行多列。把一个表的内容用Python的数据结构表示出来的话,可以用一个list表示多行,list的每一个元素是tuple,表示一行记录,比如,包含id和name的user表:
1 | [ |
Python的DB-API返回的数据结构就是像上面这样表示的。
但是用tuple表示一行很难看出表的结构。如果把一个tuple用class实例来表示,就可以更容易地看出表的结构来:
1 | class User(object): |
这就是传说中的ORM技术:Object-Relational Mapping,把关系数据库的表结构映射到对象上。是不是很简单?
但是由谁来做这个转换呢?所以ORM框架应运而生。
在Python中,最有名的ORM框架是SQLAlchemy。我们来看看SQLAlchemy的用法。
首先通过pip安装SQLAlchemy:
1 | $ pip install sqlalchemy |
然后,利用上次我们在MySQL的test数据库中创建的user表,用SQLAlchemy来试试:
第一步,导入SQLAlchemy,并初始化DBSession:
1 | # 导入: |
以上代码完成SQLAlchemy的初始化和具体每个表的class定义。如果有多个表,就继续定义其他class,例如School:
1 | class School(Base): |
create_engine()用来初始化数据库连接。SQLAlchemy用一个字符串表示连接信息:
1 | '数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名' |
你只需要根据需要替换掉用户名、口令等信息即可。
下面,我们看看如何向数据库表中添加一行记录。
由于有了ORM,我们向数据库表中添加一行记录,可以视为添加一个User对象:
1 | # 创建session对象: |
可见,关键是获取session,然后把对象添加到session,最后提交并关闭。DBSession对象可视为当前数据库连接。
如何从数据库表中查询数据呢?有了ORM,查询出来的可以不再是tuple,而是User对象。SQLAlchemy提供的查询接口如下:
1 | # 创建Session: |
运行结果如下:
1 | type: <class '__main__.User'> |
可见,ORM就是把数据库表的行与相应的对象建立关联,互相转换。
由于关系数据库的多个表还可以用外键实现一对多、多对多等关联,相应地,ORM框架也可以提供两个对象之间的一对多、多对多等功能。
例如,如果一个User拥有多个Book,就可以定义一对多关系如下:
1 | class User(Base): |
当我们查询一个User对象时,该对象的books属性将返回一个包含若干个Book对象的list。
小结
ORM框架的作用就是把数据库表的一行记录与一个对象互相做自动转换。
正确使用ORM的前提是了解关系数据库的原理。