
22. 基本的图算法
22. 基本的图算法
本章介绍图的表示和搜索。
许多的图算法在一开始都会先通过搜索来获得图的结构,其他一些图算法则是对基本的搜索加以优化。
可以说,图的搜索技巧是整个图算法领域的核心。
图的表示
图G由结点的集合V 和 边的集合E 组成
可以用两种方法表示,一种是邻接链表(下图b),一种是邻接矩阵(下图c)。
邻接链表一般用于表示稀疏图(边数远小于),默认都使用邻接链表表示。在稠密图(接近)的情况下,倾向使用邻接矩阵。
无向图:
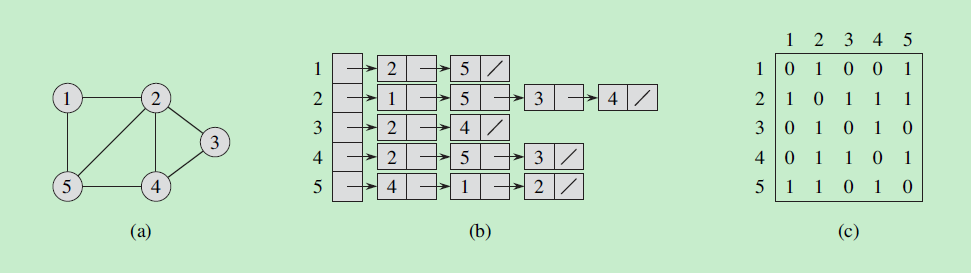
有向图:

邻接链表表示
由一个链表数组组成,数组大小为,链表存储了结点出发的边的终点。
比如上面无向图中,从结点1出发有两条边,边的终点分别是2和4,反应到邻接链表中就是存储了两个节点2和4。
邻接链表需要的存储空间为
邻接矩阵表示
由一个 的矩阵表示,并满足以下条件:
当边有权重时,可以存储权重值。
邻接矩阵需要的存储空间为
一些术语
一个结点的出度为,从这个结点触发的边的个数。
一个结点的入度为,到达这个结点的边的个数。
广度优先搜索
思路:利用一个队列,首先将头结点插入队列,循环的取出队列中的一个结点,并将于该结点相连的结点加入队列,直到队列变空,搜索结束。
辅助的给每个结点加入三个属性:
- color:白色表示还未被搜索,灰色表示加入队列,黑色表示从队列里出来
- d:该节点在第几轮被发现
- :该结点的前驱(结点第一次被发现时,正在查询的结点)
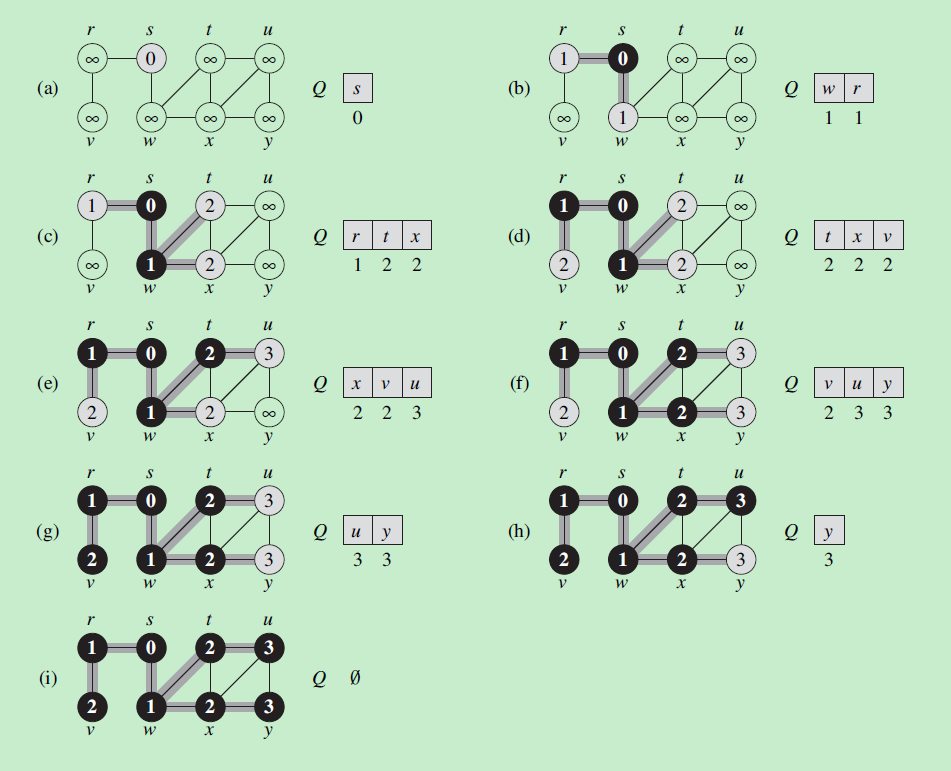
下面是广度优先搜索的伪代码和事例:
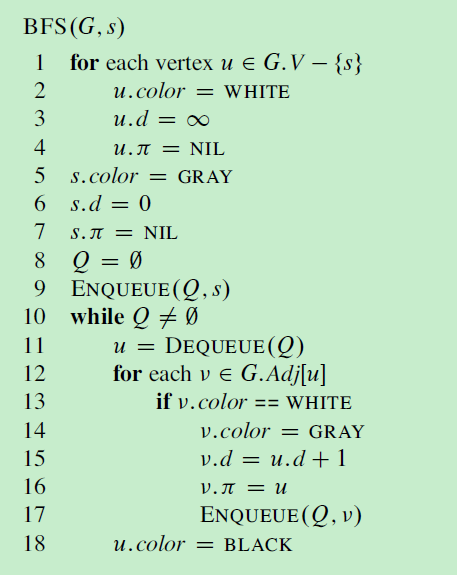
广度优先搜索的正确性
TODO
广度优先搜索的性质
最短路径
从某个结点u做广度优先搜索,可以找出这个结点到其他结点的最短路径。
结点v和结点u的最短路径距离为v.d
从结点v开始 循环列举前驱结点,就是结点v和结点u的最短路径中经过的结点。
广度优先树
广度优先搜算中,我们在属性中存储了每个结点的前驱结点,另前驱结点作为该结点的父节点,我们可以得到一个广度优先树。发现新结点的边为树边。
深度优先搜索
思路:尽可能的深入。总是对最近发现的结点v出发的边进行探索,直到结点v出发的边全部被发现时,回溯到v的前驱结点继续探索,直到从源节点出发所有可以到达的结点都被发现。这时如果还有未被搜索的结点,则再随机找一个未被搜索的结点作为源节点进行搜索。
因为可能从一个源节点出发不能搜索到所有结点,所以深度优先搜索会产生多个深度优先树组成深度优先深林。
辅助的给每个结点加入四个属性:
- color:白色表示还未被搜索,灰色表示已被发现但出发的边还没搜索完,黑色表示已被发现并且出发的边已被搜索完
- d:该节点的发现时间
- f:该结点出发搜索结束的时间
- :该结点的前驱(结点第一次被发现时,正在查询的结点)
下面是深度优先搜索的伪代码和事例:


结点中的x/y表示该结点的发现时间为x,完成时间为y
图中树边被标记为灰色,向前,横向,向前的边分别被标记为B, C, F
深度优先搜索的性质
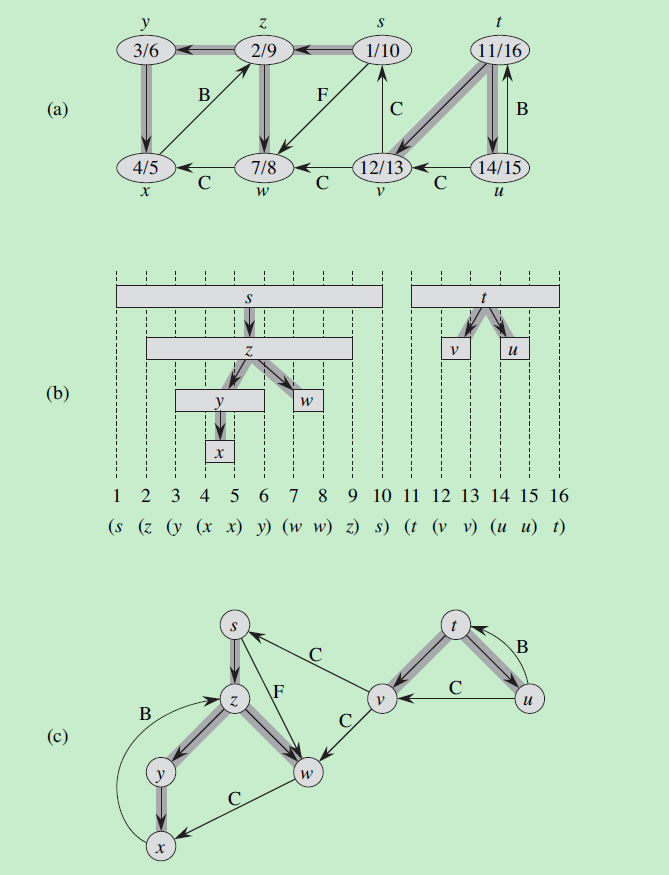
括号花定理
如上图b所示,每个结点的发现时间和完成时间组成一个括号花结构。
对于两个结点u和v,如果区间[u.d, u.f] 和 [v.d, v.f] 不相交,则u不是v的后代,v也不是u的后代;
如果[u.d, u.f] 包含在 [v.d, v.f] 内,则u是v后代,反之亦然。
白色路径定理
如果结点v是u的后代,当u.d时间时,存在一条从u到v全部由白色结点组成的路径。
拓扑排序
对于有向无环图,其拓扑排序是G种所有结点的一种线性次序,该次序满足如下条件:如果G包含边(u, v),则结点u在拓扑排序中处于结点v的前面。
许多实际应用都需要使用有向无环图来说明事件的优先次序。
下图是一个穿衣服的实例,图a中表示了穿戴某一件衣物的依赖关系,图b是图a拓扑排序的结果,按照图b相反的顺序穿衣服就是没问题的了。

拓扑排序的思想为:对图G做DFS,然后按照结点搜索的完成时间逆序排序。伪代码如下:

拓扑排序的正确性:在向无环图中,如果有变(u, v),那么v肯定比u先完成搜索。
强联通分量
有向图的强连通分量是一个最大结点集合,对于该集合的任意一对结点可以互相到达。
下图a的灰色覆盖区域就是图的强联通分量。

算法伪代码如下:
- 对G做DFS,并记下每个结点的完成时间u.f
- 转置G,得到,如上图b
- 按照u.f大小,从大到小对做DFS
- 第三步得到的深度优先深林中,每棵深度优先树的结点都组成为G的一个强联通分量

思想:
对于分量图,,图中的强联通分量集合代表分量图中的结点:如果有,且图中有边,则边,且图是有向无环图。
证明:
引理1:和是图的两个强连通分量。当, 若有,则不可能有。
可用反证法证明,若有且,则和将成为同一个强连通分量。
引理2:和是图的两个强连通分量。当且,则
当时,若为中最早被发现的结点,则和中的其它结点都是的子孙,也就是所有结点的完成时间都比早,所以
当时,根据引理1,没有从到的边,也就是完成之后不会到达任意中的结点,所以
引理3:和是图的两个强连通分量。当且,则
,由引理2可直接得知
证明:根据数学归纳法,假设算法第三行所生成的前棵树都是强连通分量,现在需要考虑第棵树是否为强连通分量:
设第棵树是,的根节点为,所在的强连通分量为。
若中从到其他强连通分量有边,那么根据引理3可知。
而算法对做DFS时,是按照大小逆序进行,所以从出来的变都是到前棵树的。
所以,也就是说第棵树为强连通分量。